Encyclopedia:
From Scholars for Scholars
Trending Entry
Top Viewed Entry
News and Events
More >>

Announcement
09 Dec 2024
The Encyclopedia platform has launched a new feature that allows you to add source DOI/URLs for your contributions to enhance the impact of your publications.
When you create a new entry (including topic review and biography), video, or image, you can enhance the credibility and referencing of your work by adding a source DOI/URL. Once published, the DOI/URL link will appear below the title of the entry/video/image, providing readers with direct access to your sources.
How to add DOI/URL when creating an entry/video/image?
Click the “Submit” button, choose “Entry/Video/Image”, and locate the DOI/URL field on the content generation page. Refer to the illustrations below for specific placement.
(1) Topic Review
(2) Biography
(3) Video
(4) Image
Note:
The source DOI/URL should not exceed 255 characters.
Use semicolons to separate multiple DOIs/URLs. If your entry/video/image comes from several papers, you can use a semicolon to list the links.
If you want to update the source DOI/URL after the entry, video, or image is published, please contact the Encyclopedia office at office@encyclopedia.pub. The source DOI/URL can only be added by the author when creating a new entry, video, or image.
Any links that serve commercial advertising purposes or are entirely unrelated to the scientific content will be removed.

Ongoing
21 Nov 2024
Encyclopedia Academic Video Service now offers specialized video production services designed for scholars, allowing them to present their research and insights in a dynamic and impactful manner. Research indicates that a well-crafted video abstract can boost an academic paper's views by 120%, citations by 20%, ranking by 33%, and Altmetrics score by 80%. Additionally, all videos on Encyclopedia will be linked to the original paper's DOI, further increasing your research's visibility.
Currently in the trial phase and offered free of charge, we warmly invite scholars from various fields to collaborate with us and contribute to enhancing our service. We primarily provide two types of videos:
Video Abstract
Video Abstract is a short video that summarizes the key points of a research paper, typically within 5 minutes. A video abstract highlights the most critical information, making it easier for viewers to grasp the essence of the research quickly.
Short Take
A short take uses original animations to vividly showcase a key aspect of the article, such as explaining principles or detailing experimental processes, within a 1 minute timeframe. Short Takes are an effective way to communicate important information efficiently in today's fast-paced digital environment.
Video Production Service
If you want to see our video examples, please visit: https://encyclopedia.pub/video.
If you would like to apply for video service, please click on https://encyclopedia.pub/video_material.
Others
If you have any other questions, please contact office@encyclopedia.pub.

Announcement
26 Feb 2025
In today's visually-driven digital landscape, a featured image is crucial for capturing attention, boosting user engagement, and enhancing the overall appeal of your content. Each image is thoughtfully curated to clarify complex scientific concepts and showcase groundbreaking achievements across various fields.
1. Key Benefits of Featured Images
Enhanced Visibility
Featured Images are prominently displayed alongside your research in search results, journal platforms, and social media, increasing its discoverability and appeal.
Improved Comprehension
Complex ideas are distilled into clear, visually appealing graphics, making your research more accessible to a broader audience.
Increased Engagement
Eye-catching visuals attract more readers, encouraging clicks, shares, and citations, thereby amplifying the reach and impact of your work.
2. Image Types Included
The following image types are included:
Digrams of an experiment, laboratory setup, graphical abstract, or other areas of interest relevant to your research.
A certain scientific research topic, a record of an experiment or surgical operation, and other interesting simulation images.
A theory or social phenomenon.
A scientific or informative object.
A scientific inforgraphic.
3. Acceptable Video Format
Supported file formats include JPG, JPEG, and
The suggested size is 100k–6 M.
The minimum dimension is 300*300 pixels.
4. How to Upload
You can upload original images directly through the image page (https://encyclopedia.pub/user/image/upload). If you have multiple images to upload from the same category, consider creating your own image gallery to showcase them.
5. Image Check
Upon submission, the image will not be displayed online directly until it has undergone approval by the Editorial Office. To safeguard your intellectual contributions, the image content will be securely locked during this process.
6. About Copyright
Please ensure that all uploaded images are free from copyright issues. We encourage users to submit unpublished and original images. It is essential to obtain permission to reproduce any published material which does not fall into the public domain, or for which the uploader does not hold the copyright. Permission should be requested by the uploader from the copyright holder, typically the publisher.
7. Others
If you have any questions, please feel free to contact office@encyclopedia.pub.
Announcement
09 Dec 2024
The Encyclopedia platform has launched a new feature that allows you to add source DOI/URLs for your contributions to enhance the impact of your publications.
When you create a new entry (including topic review and biography), video, or image, you can enhance the credibility and referencing of your work by adding a source DOI/URL. Once published, the DOI/URL link will appear below the title of the entry/video/image, providing readers with direct access to your sources.
How to add DOI/URL when creating an entry/video/image?
Click the “Submit” button, choose “Entry/Video/Image”, and locate the DOI/URL field on the content generation page. Refer to the illustrations below for specific placement.
(1) Topic Review
(2) Biography
(3) Video
(4) Image
Note:
The source DOI/URL should not exceed 255 characters.
Use semicolons to separate multiple DOIs/URLs. If your entry/video/image comes from several papers, you can use a semicolon to list the links.
If you want to update the source DOI/URL after the entry, video, or image is published, please contact the Encyclopedia office at office@encyclopedia.pub. The source DOI/URL can only be added by the author when creating a new entry, video, or image.
Any links that serve commercial advertising purposes or are entirely unrelated to the scientific content will be removed.
Ongoing
21 Nov 2024
Encyclopedia Academic Video Service now offers specialized video production services designed for scholars, allowing them to present their research and insights in a dynamic and impactful manner. Research indicates that a well-crafted video abstract can boost an academic paper's views by 120%, citations by 20%, ranking by 33%, and Altmetrics score by 80%. Additionally, all videos on Encyclopedia will be linked to the original paper's DOI, further increasing your research's visibility.
Currently in the trial phase and offered free of charge, we warmly invite scholars from various fields to collaborate with us and contribute to enhancing our service. We primarily provide two types of videos:
Video Abstract
Video Abstract is a short video that summarizes the key points of a research paper, typically within 5 minutes. A video abstract highlights the most critical information, making it easier for viewers to grasp the essence of the research quickly.
Short Take
A short take uses original animations to vividly showcase a key aspect of the article, such as explaining principles or detailing experimental processes, within a 1 minute timeframe. Short Takes are an effective way to communicate important information efficiently in today's fast-paced digital environment.
Video Production Service
If you want to see our video examples, please visit: https://encyclopedia.pub/video.
If you would like to apply for video service, please click on https://encyclopedia.pub/video_material.
Others
If you have any other questions, please contact office@encyclopedia.pub.
Announcement
26 Feb 2025
In today's visually-driven digital landscape, a featured image is crucial for capturing attention, boosting user engagement, and enhancing the overall appeal of your content. Each image is thoughtfully curated to clarify complex scientific concepts and showcase groundbreaking achievements across various fields.
1. Key Benefits of Featured Images
Enhanced Visibility
Featured Images are prominently displayed alongside your research in search results, journal platforms, and social media, increasing its discoverability and appeal.
Improved Comprehension
Complex ideas are distilled into clear, visually appealing graphics, making your research more accessible to a broader audience.
Increased Engagement
Eye-catching visuals attract more readers, encouraging clicks, shares, and citations, thereby amplifying the reach and impact of your work.
2. Image Types Included
The following image types are included:
Digrams of an experiment, laboratory setup, graphical abstract, or other areas of interest relevant to your research.
A certain scientific research topic, a record of an experiment or surgical operation, and other interesting simulation images.
A theory or social phenomenon.
A scientific or informative object.
A scientific inforgraphic.
3. Acceptable Video Format
Supported file formats include JPG, JPEG, and
The suggested size is 100k–6 M.
The minimum dimension is 300*300 pixels.
4. How to Upload
You can upload original images directly through the image page (https://encyclopedia.pub/user/image/upload). If you have multiple images to upload from the same category, consider creating your own image gallery to showcase them.
5. Image Check
Upon submission, the image will not be displayed online directly until it has undergone approval by the Editorial Office. To safeguard your intellectual contributions, the image content will be securely locked during this process.
6. About Copyright
Please ensure that all uploaded images are free from copyright issues. We encourage users to submit unpublished and original images. It is essential to obtain permission to reproduce any published material which does not fall into the public domain, or for which the uploader does not hold the copyright. Permission should be requested by the uploader from the copyright holder, typically the publisher.
7. Others
If you have any questions, please feel free to contact office@encyclopedia.pub.
Announcement
09 Dec 2024
The Encyclopedia platform has launched a new feature that allows you to add source DOI/URLs for your contributions to enhance the impact of your publications.
When you create a new entry (including topic review and biography), video, or image, you can enhance the credibility and referencing of your work by adding a source DOI/URL. Once published, the DOI/URL link will appear below the title of the entry/video/image, providing readers with direct access to your sources.
How to add DOI/URL when creating an entry/video/image?
Click the “Submit” button, choose “Entry/Video/Image”, and locate the DOI/URL field on the content generation page. Refer to the illustrations below for specific placement.
(1) Topic Review
(2) Biography
(3) Video
(4) Image
Note:
The source DOI/URL should not exceed 255 characters.
Use semicolons to separate multiple DOIs/URLs. If your entry/video/image comes from several papers, you can use a semicolon to list the links.
If you want to update the source DOI/URL after the entry, video, or image is published, please contact the Encyclopedia office at office@encyclopedia.pub. The source DOI/URL can only be added by the author when creating a new entry, video, or image.
Any links that serve commercial advertising purposes or are entirely unrelated to the scientific content will be removed.
Featured Images
More >>
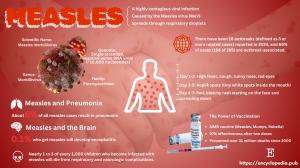



Journal Encyclopedia - Peer-Reviewed Content
More >>
Encyclopedia 2025, 5(1), 24; https://doi.org/10.3390/encyclopedia5010024
Peer Reviewed
Encyclopedia 2025, 5(1), 19; https://doi.org/10.3390/encyclopedia5010019
Peer Reviewed
Encyclopedia 2025, 5(1), 32; https://doi.org/10.3390/encyclopedia5010032
Encyclopedia 2025, 5(1), 24; https://doi.org/10.3390/encyclopedia5010024
Peer Reviewed
Encyclopedia 2025, 5(1), 19; https://doi.org/10.3390/encyclopedia5010019
Peer Reviewed
Encyclopedia 2025, 5(1), 32; https://doi.org/10.3390/encyclopedia5010032
Encyclopedia 2025, 5(1), 24; https://doi.org/10.3390/encyclopedia5010024
Peer Reviewed
Encyclopedia 2025, 5(1), 19; https://doi.org/10.3390/encyclopedia5010019
See what people are saying about us
Sandro Serpa
With the precious and indispensable active participation of scholars from all over the world, in articulation with the Editorial Office Team, will certainly continue to give a positive response to the new challenges emerging.
Department of Sociology, Faculty of Social and Human Sciences, University of the Azores, Portugal
Hsiang-Ning Luk
I received a feedback from a particular reader and now we intend to collaborate on a paper together. I appreciate the MDPI provides such a good platform to make it happen.
Department of Anesthesia, Hualien Tzu-Chi Hospital, Hualien, Taiwan
Melvin R. Pete Hayden
Thank the video production crew for making such a wonderful video. The narrations have been significantly added to the video! Congratulations on such an outstanding job of Encyclopedia Video team.
University of Missouri School of Medicine, United States
Shlomi Agmon
Encyclopedia Video provides potential readers with a tool to quickly understand what the work is about. That is important for casualreaders, whose time is thus spared, and for investedreaders, for whom it makes the decision to say "yes, I want to read the paper" much simpler.
School of Computer Science and Engineering, The Hebrew University of Jerusalem, Jerusalem 9190401, Israel
Ignacio Cea
For the video abstracts, the papers and authors could gain more visibility and increase citations. Also, it means a more diverse and interesting way of communicating research, which is something valuable in itself.
Center for Research, Innovation and Creation, and Faculty of Religious Sciences and Philosophy, Temuco Catholic University
Patricia Jovičević-Klug
I am really impressed by the final video (produced by Encyclopedia Video team). I was a little bit worried about what the final video would be like, because of the topic, but you made the magic come true again with this video.
Department of Interface Chemistry and Surface Engineering, Max-Planck-Institute for Iron Research, Max-Planck-Str. 1, 40237 Düsseldorf, Germany
Bjørn Grinde
I believe research should be brought to the public and that videos are important for getting there. A warm thanks to Encyclopedia for making it happen and to the video crew for doing an excellent job.
Division of Physical and Mental Health, Norwegian Institute of Public Health, Oslo, Norway
Patricia Takako Endo
I have followed up the Encyclopedia initiative and I think it is a good alternative where researchers can share their works and results with the community.
Programa de Pós-Graduação em Engenharia da Computação Pernambuco, Universidade de Pernambuco, Brazil
Sandro Serpa
With the precious and indispensable active participation of scholars from all over the world, in articulation with the Editorial Office Team, will certainly continue to give a positive response to the new challenges emerging.
Department of Sociology, Faculty of Social and Human Sciences, University of the Azores, Portugal
Hsiang-Ning Luk
I received a feedback from a particular reader and now we intend to collaborate on a paper together. I appreciate the MDPI provides such a good platform to make it happen.
Department of Anesthesia, Hualien Tzu-Chi Hospital, Hualien, Taiwan
Melvin R. Pete Hayden
Thank the video production crew for making such a wonderful video. The narrations have been significantly added to the video! Congratulations on such an outstanding job of Encyclopedia Video team.
University of Missouri School of Medicine, United States
Shlomi Agmon
Encyclopedia Video provides potential readers with a tool to quickly understand what the work is about. That is important for casualreaders, whose time is thus spared, and for investedreaders, for whom it makes the decision to say "yes, I want to read the paper" much simpler.
School of Computer Science and Engineering, The Hebrew University of Jerusalem, Jerusalem 9190401, Israel
Ignacio Cea
For the video abstracts, the papers and authors could gain more visibility and increase citations. Also, it means a more diverse and interesting way of communicating research, which is something valuable in itself.
Center for Research, Innovation and Creation, and Faculty of Religious Sciences and Philosophy, Temuco Catholic University
Patricia Jovičević-Klug
I am really impressed by the final video (produced by Encyclopedia Video team). I was a little bit worried about what the final video would be like, because of the topic, but you made the magic come true again with this video.
Department of Interface Chemistry and Surface Engineering, Max-Planck-Institute for Iron Research, Max-Planck-Str. 1, 40237 Düsseldorf, Germany
Bjørn Grinde
I believe research should be brought to the public and that videos are important for getting there. A warm thanks to Encyclopedia for making it happen and to the video crew for doing an excellent job.
Division of Physical and Mental Health, Norwegian Institute of Public Health, Oslo, Norway
Patricia Takako Endo
I have followed up the Encyclopedia initiative and I think it is a good alternative where researchers can share their works and results with the community.
Programa de Pós-Graduação em Engenharia da Computação Pernambuco, Universidade de Pernambuco, Brazil
Sandro Serpa
With the precious and indispensable active participation of scholars from all over the world, in articulation with the Editorial Office Team, will certainly continue to give a positive response to the new challenges emerging.
Department of Sociology, Faculty of Social and Human Sciences, University of the Azores, Portugal
Hsiang-Ning Luk
I received a feedback from a particular reader and now we intend to collaborate on a paper together. I appreciate the MDPI provides such a good platform to make it happen.
Department of Anesthesia, Hualien Tzu-Chi Hospital, Hualien, Taiwan
Melvin R. Pete Hayden
Thank the video production crew for making such a wonderful video. The narrations have been significantly added to the video! Congratulations on such an outstanding job of Encyclopedia Video team.
University of Missouri School of Medicine, United States
