 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Shichang Wang | -- | 1091 | 2022-11-17 02:33:46 | | | |
| 2 | Shichang Wang | + 1097 word(s) | 2188 | 2022-11-21 08:09:07 | | | | |
| 3 | Sirius Huang | -9 word(s) | 2179 | 2022-11-22 02:12:11 | | | | |
| 4 | Sirius Huang | Meta information modification | 2179 | 2022-11-22 02:13:51 | | |
Video Upload Options
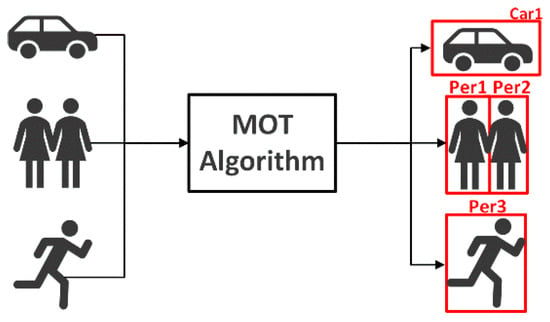
Multi-target tracking is an advanced visual work in computer vision, which is essential for understanding the autonomous driving environment. Due to the excellent performance of deep learning in visual object tracking, many state-of-the-art multi-target tracking algorithms have been developed.
1. Introduction
2. Overview of Deep Learning-Based Visual Multi-Object Tracking
2.1. Visual Multi-Object Tracking Algorithm Based on Deep Learning
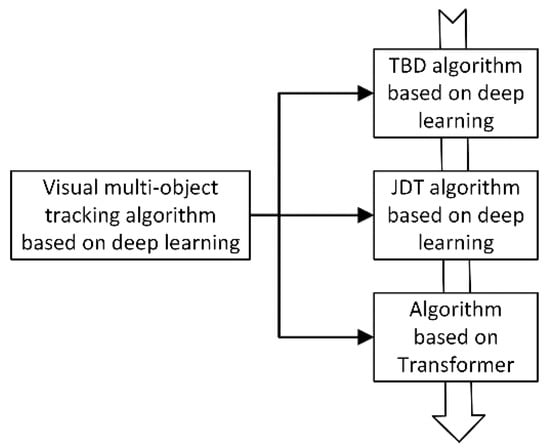
| Tracking Algorithm Framework |
Principle | Advantage | Disadvantage |
|---|---|---|---|
| TBD | All objects of interest are detected in each frame of the video, and then they are associated with the detected objects in the previous frame to achieve the effect of tracking | Simple structure and strong interpretability | Over-reliance on object detector performance; bloated algorithm design |
| JDT | End-to-end trainable detection box paradigm to jointly learn detection and appearance features | Multi-module joint learning, weight sharing | Local receptive field, when the object is occluded, the tracking effect is not good |
| Tranformer-based | Transformer encode-decoder architecture to obtain global and rich contextual interdependcies for tracking | Paraller coputing; rich global and contextual information; the tracking accuracy and accuracy have been greatly improved,with great potential in the filed of computer vision | The parameters are too large and the computational overhead is high; the Transformer-based network has not been fully adapted to the filed of computer vision |
2.2. MOT Datasets
To perform visual multi‐object tracking tasks, the datasets are listed in Table 2. Most detection and tracking elements in data collection are related to autos and pedestrians, which helps enhance autonomous driving.
| Ref. | Datasets | Year | Feature | DOI/URL |
|---|---|---|---|---|
| [20][21][27] | MOT15, 16,17,20 | 2016–2020 | Sub datasets containing multiple different camera angles and scenes | https://doi.org/10.48550/arXiv.1504.01942 https://motchallenge.net/ |
| [22][23] | KITTI-Tracking | 2012 | Provides annotations for cars and pedestrians, scene objects are sparse | https://doi.org/10.1177/0278364913491297 https://www.cvlibs.net/datasets/kitti/eval_tracking.php |
| [24] | NuScenes | 2019 | Dense traffic and challenging driving conditions | https://doi.org/10.48550/arXiv.1903.11027 https://www.nuscenes.org/ |
| [25] | Waymo | 2020 | Diversified driving environment, dense label information | https://doi.org/10.48550/arXiv.1912.04838 https://waymo.com/open/data/motion/tfexample |
Setting realistic and accurate evaluation metrics is essential for comparing the effectiveness of visual multi-object tracking algorithms in an unbiased and fair manner. The three criteria that make up the multi-object tracking assessment indicators are if the object detection is real-time, whether the predicted position matches the actual position, and whether each object maintains a distinct ID [28]. MOT Challenge offers recognized MOT evaluation metrics.
MOTA (Multi‐Object‐Tracking Accuracy): the accuracy of multi‐object tracking is used to count the accumulation of errors in tracking, including the number of tracking objects and whether they match:
where FN (False Negative) is the number of detection frames that do not match the prediction frame; FP (False positive) is the number of prediction frames that do not match the detection frame; IDSW (ID Switch) is the object ID change the number of times; GT(Ground Truth) is the number of tracking objects.
MOTP (Multi‐Object‐Tracking Precision): the accuracy of multi‐object tracking, which is used to evaluate whether the object position is accurately positioned.
where Ct is the number of matches between the object and the predicted object in the t‐th frame; Bt(i) is the distance between the corresponding position of the object in the t‐th frame and the predicted position, also known as the matching error.
AMOTA (Average Multiple Object Tracking Accuracy): summarize MOTA overall object confidence thresholds instead of using a single threshold. Similar to mAP for object detection, it is used to evaluate the overall accurate performance of the tracking algorithm under all thresholds to improve algorithm robustness. AMOTA can be calculated by integrating MOTA under the recall curve, using interpolation to approximate the integral in order to simplify the calculation.
where L represents the number of recall values (integration confidence threshold), the higher the L, the more accurate the approximate integral. AMOTA represents the multi‐object tracking accuracy at a specific recall value r.
AMOTP (Average Multi‐object Tracking Precision): The same calculation method as AMOTA, with recall as the abscissa and MOTP as the ordinate, use the interpolation method to obtain AMOTP.
IDF1 (ID F1 score): measures the difference between the predicted ID and the correct ID.
MT (Mostly Tracked): the number of objects that are successfully tracked 80% of the time as a percentage of all tracked objects.
ML (Mostly Lost): the percentage of the number of objects that satisfy the tracking success 20% of the time out of all the objects tracked.
FM (Fragmentation): evaluate tracking integrity, defined as FM, counted whenever a trajectory changes its state from tracked to untracked, and the same trajectory is tracked at a later point in time.
HOTA (Higher Order Metric): A higher order metric for evaluating MOT proposed by [29]. Previous metrics overemphasized the importance of detection or association. This evaluation metric explicitly balances the effects of performing accurate detection, association, and localization into a unified metric for comparing trackers. HOTA scores are more consistent with human visual evaluations.
where α is the IoU threshold, and c is the number of positive sample trajectories. In the object tracking experiment, there are predicted detection trajectories and ground truth trajectories. The intersection between the two trajectories is called true positive association(TPA), and the trajectory outside the intersection in the predicted trajectory is called false positive association (FPA). Detections outside the intersection in ground truth trajectories are false negative associations (FNA).
References
- Fagnant, D.J.; Kockelman, K. Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations. Transp. Res. Part A Policy Pract. 2015, 77, 167–181.
- Hussain, R.; Zeadally, S. Autonomous cars: Research results, issues, and future challenges. IEEE Commun. Surv. Tutor. 2018, 21, 1275–1313.
- Leon, F.; Gavrilescu, M. A Review of Tracking, Prediction and Decision Making Methods for Autonomous Driving. arXiv 2019, arXiv:1909.07707v1.
- Fan, L.; Wang, Z.; Cail, B.; Tao, C.; Feng, Z. A survey on multiple object tracking algorithm. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016.
- Sun, Z.; Chen, J.; Chao, L.; Ruan, W.; Mukherjee, M. A Survey of Multiple Pedestrian Tracking Based on Tracking-by-Detection Framework. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1819–1833.
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to track and track to detect. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2017, Venice, Italy, 22–29 October 2017; pp. 3038–3046.
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929v2.
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017.
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020.
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the NIPS 2014, Montreal, QC, Canada, 8–13 December 2014.
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 4696–4704.
- Davey, S.J.; Rutten, M.G.; Gordon, N.J. Track-before-detect techniques. In Integrated Tracking, Classification, and Sensor Management; Wiley Online Library: Hoboken, NJ, USA, 2013; pp. 311–362.
- Wang, N.; Zhou, W.; Li, H. Reliable re-detection for long-term tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 730–743.
- Pang, B.; Li, Y.; Zhang, Y.; Li, M.; Lu, C. Tubetk: Adopting tubes to track multi-object in a one-step training model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 6308–6318.
- Ke, B.; Zheng, H.; Chen, L.; Yan, Z.; Li, Y. Multi-object tracking by joint detection and identification learning. Neural Process. Lett. 2019, 50, 283–296.
- Fortin, B.; Lherbier, R.; Noyer, J.-C. A model-based joint detection and tracking approach for multi-vehicle tracking with lidar sensor. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1883–1895.
- Zeng, F.; Dong, B.; Wang, T.; Zhang, X.; Wei, Y. Motr: End-to-end multiple-object tracking with transformer. arXiv 2021, arXiv:2105.03247.
- Yu, E.; Li, Z.; Han, S.; Wang, H. Relationtrack: Relation-aware multiple object tracking with decoupled representation. IEEE Trans. Multimed. 2022.
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831v2.
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003v1.
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237.
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631.
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454.
- Ertler, C.; Mislej, J.; Ollmann, T.; Porzi, L.; Neuhold, G.; Kuang, Y. The mapillary traffic sign dataset for detection and classification on a global scale. In Proceedings of the ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 68–84.
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942.
- Keni, B.; Rainer, S. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 246309.
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. Hota: A higher order metric for evaluating multi-object tracking. Int. J. Comput. Vis. 2021, 129, 548–578.

