多目标跟踪是计算机视觉中的高级视觉工作,对于理解自动驾驶环境至关重要。由于深度学习在视觉对象跟踪领域的出色表现,许多一流的多目标跟踪算法已经发展起来。Multi-target tracking is an advanced visual work in computer vision, which is essential for understanding the autonomous driving environment. Due to the excellent performance of deep learning in visual object tracking, many state-of-the-art multi-target tracking algorithms have been developed.
- autonomous driving
- deep learning
- visual multi-object tracking
- transformer
1. Introduction
2. Overview of Deep Learning-Based Visual Multi-Object Tracking
Deep learning-based visual multi-object tracking systems have several overview techniques from various angles. The methods for visual multi-object tracking based on deep learning are outlined here in terms of algorithm classification, related data sets, and algorithm assessment.2.1. Visual Multi-Object Tracking Algorithm Based on Deep Learning
The tracking algorithm based on detection results has evolved and has quickly taken over as the standard framework for multi-object tracking due to the rapid advancement of object detection algorithm performance [7]. The TBD sub-modules, such as feature extraction, can be included in the object detection network, though, from the standpoint of the deep neural network’s structure. Joint detection and tracking, or JDT, using a deep network framework to perform visual multi-object tracking, has emerged as a new development trend based on TBD neutron module fusion [11,12]. The attention mechanism has been incorporated into computer vision systems recently because it has the benefit of efficiently capturing the region of interest in the image, enhancing the performance of the entire network [13,14,15,16]. It is used to solve various vision problems, including multi-object tracking. The specific classification structure for the three types of tracking frameworks is shown in Figure 3.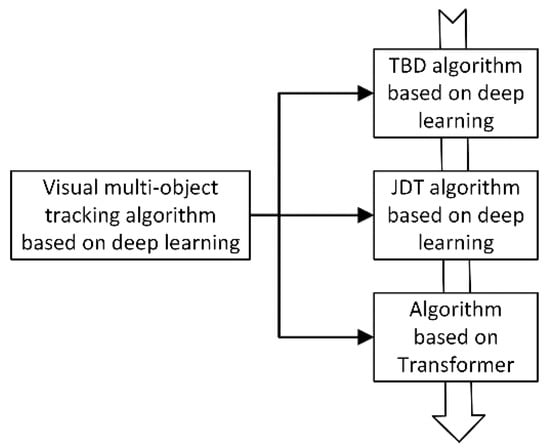
| Tracking Algorithm Framework |
Principle | Advantage | Disadvantage |
|---|---|---|---|
| TBD | All objects of interest are detected in each frame of the video, and then they are associated with the detected objects in the previous frame to achieve the effect of tracking | Simple structure and strong interpretability | Over-reliance on object detector performance; bloated algorithm design |
| JDT | End-to-end trainable detection box paradigm to jointly learn detection and appearance features | Multi-module joint learning, weight sharing | Local receptive field, when the object is occluded, the tracking effect is not good |
| 基于变压器Tranformer-based | 变压器编码器Transformer encode-解码器架构,用于跟踪全局和丰富的上下文相互依赖关系decoder architecture to obtain global and rich contextual interdependcies for tracking | 并行计算Paraller coputing;丰富的全局和上下文信息;跟踪精度和准确性大幅提升,在计算机视觉领域潜力巨大 rich global and contextual information; the tracking accuracy and accuracy have been greatly improved,with great potential in the filed of computer vision | 参数过大,计算开销高;基于变压器的网络尚未完全适应计算机视觉领域The parameters are too large and the computational overhead is high; the Transformer-based network has not been fully adapted to the filed of computer vision |
2.2. MOT 数据集Datasets
与传统的机器学习技术相比,深度学习的优势在于它可以自动识别与特定任务相关的数据属性。对于基于深度学习的计算机视觉算法,数据集至关重要。下面概述了自动驾驶跟踪领域经常使用的数据集和特征。由于MOT数据集[Deep learning has the benefit over more conventional machine learning techniques in that it can automatically identify data attributes that are pertinent to a specific task. For deep learning‐based computer vision algorithms, data sets are crucial. The datasets and traits that are frequently utilized in the field of automatic driving tracking are outlined in the following. Due to their frequent updates and closer resemblance to the actual scene, the MOT datasets [
25,
26]经常更新并且与实际场景更加相似,因此在视觉多目标跟踪领域引起了最大的关注。在MO]raise the most concerns in the field of visual multi‐object track‐ing. On the MOT dataset, other cutting‐edge tracking methods are also tested.
The MOT16 Dataset[25] is used exclusively for tracking pedestrians. There are a total of 14 videos, 7 practice sets, and 7 test sets. These videos were created using a variety of techniques, including fixed and moving cameras, as well as various shooting perspectives. Additionally, the shooting circumstances vary, depending on whether it is day or night and the weather. The MOT16 detector, called DPM, performs better in the area of detecting pedestrians.
T数据集上,还测试了其他尖端跟踪方法。 he MOT16数据集7 Dataset[25]专门用于跟踪行人。共有is the 14 个视频、7 个练习集和 7 个测试集。这些视频是使用各种技术创建的,包括固定和移动相机,以及各种拍摄视角。此外,拍摄环境会有所不同,具体取决于是白天还是黑夜以及天气。MOT16探测器称为DPM,在检测行人方面表现更好。 MOT17数据集[25]的视频内容与MOT16相同,但它也提供了两个探测器检测结果,即same as that of MOT16, but it also provides two detector detection results, namely SDP和 and Faster R-CNN,它们具有更准确的地面真相注释。‐CNN, which have more accurate ground‐truth annotations. The MOT20数据集[26]有8个视频序列、4个训练集和4个测试集,行人密度进一步提高,平均每帧246个行人。 KITTI数据集[27,28]是目前用于评估自动驾驶场景中计算机视觉算法的最大数据集。这些数据用于评估 Dataset[26] has 8 3Dvideo 物体检测和跟踪、视觉里程计、立体图像评估和光流图像。 NsequSencenes数据集[29]为自动驾驶汽车提供了一个完整的传感器数据的大型数据集,包括六个摄像头,一个激光雷达,五个雷达,以及GPS和IMU。与KITTI数据集相比,它包含的对象注释多了七倍以上。对于每个场景,选择其关键帧进行注释,注释速率为s, 4 training sets and 24 Hz。但是,值得注意的是,由于标记了23种类型的对象,因此类不平衡问题将更加严重。 Waymo数据集[30]是用五个LtestiDAR和五个高分辨率针孔摄像头收集的。整个数据集包含ng 1150 个场景,分为 1000 个训练集和 150 个测试集,共有约 1200 万个 LiDAR 标注框和约 1200 万个图像标注框。 Masets, and the pedestrian density is further increased, with an average of 246 pedestrillary交通标志数据集[ans per frame.The KITTI dataset[27,28]is currently the largest dataset for evaluating computer vision algorithms in autonomous driving scenarios. These data are used to evaluate 3D object detection and tracking, visual odometry, evaluation of stereo images, and optical flow images.
The NuScenes dataset[29] provides a large dataset of full sensor data for autonomous vehicles, including six cameras, one lidar, five radars, as well as GPS and IMU. Compared with the KITTI dataset, it includes more than seven times more object annotations. For each scene, its key frames are selected for annotation, and the annotation rate is 2 Hz. However, it is worth noting that since 23 types of objects are marked, the class‐ The imbalance problem will be more serious
The Waymo dataset[30] is collected with five LiDAR and five high‐resolution pinhole cameras. The entire dataset contains 1150 scenes, which are divided into 1000 training sets and 150 test sets, with a total of about 12 million LiDAR annotation boxes and approx. 12 million image annotation boxes.
The Mapillary Traffic sign dataset[
31]是世界上最大、最多样化的交通标志数据集,可用于自动驾驶中交通标志的自动检测和分类研究。] is the largest and most diverse traffic sign dataset in the world, which can be used for research on the automatic detection and classification of traffic signs in autonomous driving.
To perform visual multi‐object tracking tasks, we gather and introduce the datasets listed in Table 3. Most detection and tracking elements in data collection are related to autos and pedestrians, which helps enhance autonomous driving.
为了执行视觉多对象跟踪任务,研究人员收集并介绍了表3中列出的数据集。数据收集中的检测和跟踪元素大多与汽车和行人有关,这有助于增强自动驾驶。| 裁判。Ref. | 数据Datasets | 年Year | 特征Feature | 数字对象标识符DOI/网址URL |
|---|---|---|---|---|
| [25,26,32 ] | MOT15, 16,17,20 | 2016–2020 | 包含多个不同相机角度和场景的子数据集Sub datasets containing multiple different camera angles and scenes | https://doi.org/10.48550/arXiv.1504.01942 https://motchallenge.net/ |
| [27,28 ] | 基蒂跟踪KITTI-Tracking | 2012 | 为汽车和行人提供注释,场景对象稀疏Provide annotations for cars and pedestrians, scene objects are sparse | https://doi.org/10.1177/0278364913491297 https://www.cvlibs.net/datasets/kitti/eval_tracking.php |
| [29] | 新场景NuScenes | 2019 | 交通繁忙,驾驶条件恶劣Dense traffic challenging driving conditions | https://doi.org/10.48550/arXiv.1903.11027 https://www.nuscenes.org/ |
| [30] | 韦莫Waymo | 2020 | 多元化的驾驶环境,密集的标签信息Diversified driving environment, dense label information | https://doi.org/10.48550/arXiv.1912.04838 https://waymo.com/open/data/motion/tfexample |
2.3. MOT Evaluating 评估指标Indicator
设置真实准确的评估指标对于以公正和公平的方式比较视觉多目标跟踪算法的有效性至关重要。构成多目标跟踪评估指标的三个标准是,目标检测是否实时,预测位置是否与实际位置匹配,以及每个对象是否保持不同的ID[Setting realistic and accurate evaluation metrics is essential for comparing the effectiveness of visual multi‐object tracking algorithms in an unbiased and fair manner. The three criteria that make up the multi‐object tracking assessment indicators are if the object detection is real‐time, whether the predicted position matches the actual position, and whether each object maintains a distinct ID[
33]。MOT 挑战赛提供公认的 MOT 评估指标。]. MOT Challenge offers recognized MOT evaluation metrics.
MOTA(多目标跟踪精度):多目标跟踪的精度用于计算跟踪中累积的误差,包括跟踪对象的数量以及它们是否匹配:MOTA (Multi‐Object‐Tracking Accuracy): the accuracy of multi‐object tracking is used to count the accumulation of errors in tracking, including the number of tracking objects and whether they match:
where FN (False Negative) is the number of detection frames that do not match the prediction frame; FP (False positive) is the number of prediction frames that do not match the detection frame; IDSW (ID Switch) is the object ID change the number of times; GT(Ground Truth) is the number of tracking objects.
MOTP (Multi‐Object‐Tracking Precision): the accuracy of multi‐object tracking, which is used to evaluate whether the object position is accurately positioned.
MOTP(多目标跟踪精度):多目标跟踪的精度,用于评估目标位置是否准确定位。where Ct is the number of matches between the object and the predicted object in the t‐th frame; Bt(i) is the distance between the corresponding position of the object in the t‐th frame and the predicted position, also known as the matching error.
AMOTA (Average Multiple Object Tracking Accuracy): summarize MOTA over all object confidence thresholds instead of using a single threshold. Similar to mAP for object detection, it is used to evaluate the overall accurate performance of the tracking algorithm under all thresholds to improve algorithm robustness. AMOTA can be calculated by integrating MOTA under the recall curve, using interpolation to approximate the integral in order to simplify the calculation.
where L represents the number of recall values (integration confidence threshold), the higher the L, the more accurate the approximate integral. AMOTA represents the multi‐object tracking accuracy at a specific recall value r.
AMOTP (Average Multi‐object Tracking Precision): The same calculation method as AMOTA, with recall as the abscissa and MOTP as the ordinate, use the interpolation method to obtain AMOTP.
AMOTP(平均多目标跟踪精度):与AMOTA相同的计算方法,以召回为横坐标,MOTP为纵坐标,采用插值法得到AMOTP。IDF1 (ID F1 score): measures the difference between the predicted ID and the correct ID.
MT(大部分跟踪):在 80% 的时间内成功跟踪的对象数占所有跟踪对象的百分比。MT (Mostly Tracked): the number of objects that are successfully tracked 80% of the time as a percentage of all tracked objects.
ML(大部分丢失):满足跟踪成功的对象数量的百分比 20% 的时间在所有跟踪的对象中。ML (Mostly Lost): the percentage of the number of objects that satisfy the tracking success 20% of the time out of all the objects tracked.
FM(分段):评估跟踪完整性,定义为 FM,每当轨迹将其状态从跟踪更改为未跟踪时计数,并在以后的时间点跟踪相同的轨迹。FM (Fragmentation): evaluate tracking integrity, defined as FM, counted whenever a trajectory changes its state from tracked to untracked, and the same trajectory is tracked at a later point in time.
HOTA(高阶度量):由 [HOTA (Higher Order Metric): A higher order metric for evaluating MOT proposed by[
34] 提出的用于评估 MOT 的高阶度量。以前的指标过分强调了检测或关联的重要性。此评估指标明确地平衡了执行准确检测、关联和定位的效果,以比较跟踪器。HOTA评分与人类视觉评估更一致。]. Previous metrics overemphasized the importance of detection or association. This evaluation metric explicitly balances the effects of performing accurate detection, association, and localization into a unified metric for comparing trackers. HOTA scores are more consistent with human visual evaluations.
where is the IoU threshold, and c is the number of positive sample trajectories. In the object tracking experiment, there are predicted detection trajectories and ground truth trajectories. The intersection between the two trajectories is called true positive association(TPA), and the trajectory outside the intersection in the predicted trajectory is called false positive association (FPA). Detections outside the intersection in ground truth trajectories are false negative associations (FNA).