Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
多目标跟踪是计算机视觉中的高级视觉工作,对于理解自动驾驶环境至关重要。由于深度学习在视觉对象跟踪领域的出色表现,许多一流的多目标跟踪算法已经发展起来。
- autonomous driving
- deep learning
- visual multi-object tracking
- transformer
1. Introduction
The primary area of intelligent and networked development in the vehicle and transportation industries is autonomous driving. AVs have the potential to fundamentally alter transportation systems by averting deadly crashes, providing critical mobility to the elderly and disabled, increasing road capacity, saving fuel, and lowering emissions [1,2]. The vehicle perception system’s accurate perception of the environment is essential for safe autonomous driving. The perception of autonomous driving settings depends heavily on object tracking, a high-level vision job in the discipline of computer vision. As a result, the development of an object tracking algorithm ensures the development of an automatic driving system that is both safer and more effective.
This text focuses on multi-object tracking in autonomous driving systems. Multi-object tracking is crucial to ensuring the effectiveness and safety of autonomous driving because it is the fundamental component of the technology. Rarely do objects in traffic situations appear alone. Autonomous driving frequently involves recognizing and tracking many things at once, some of which may be moving in relation to the vehicle or to one another. The majority of techniques in the related literature therefore deal with many objects and attempt to address the multi-object tracking issue. In essence, the MOT algorithm can be summarized as: given the data collected by one or more sensors, how to identify multiple objects in each frame of data and assign an identity to each object, and match those IDs in subsequent data frames [3]. An example of the output of the MOT algorithm is shown in Figure 1 below.
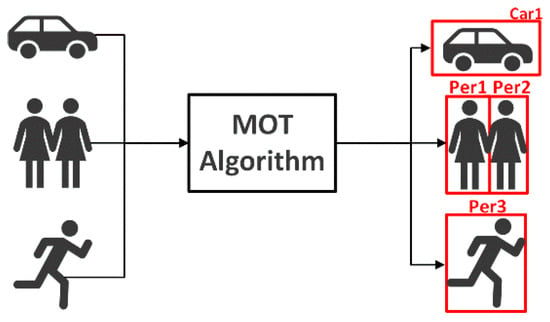
Figure 1. An illustration of the output of an MOT algorithm. Each output bounding box has a number that identifies a specific object in the video.
The research on multi-object tracking for autonomous driving has advanced significantly in recent years, but it is still challenging to use the current multi-object tracking techniques for autonomous driving to their full potential because of issues including the varied shapes of cars and pedestrians in traffic scenes, motion blur, and background interference. There are still several difficulties with the existing visual multi-object tracking technology. Visual multi-object tracking must first address more challenging problems such as: an unpredictable number of objects, frequent object occlusion, challenging object differentiation, etc. In particular, the frequent entry and exit of objects from the field of view is a typical and expected behavior in autonomous driving applications, which results in the uncertainty of the number of objects faced by multi-object tracking and necessitates real-time detection of multi-object tracking algorithms. The method must extract robust object features and keep the object-specific ID after occlusion in complicated situations, since the occlusion of an object by other objects or backgrounds will lead to object ID switches (IDs). The high degree of similarity in object appearance also adds to the difficulty of maintaining the right object ID over the long term. The algorithm must be able to extract the characteristics of comparable items that make them separable. Finally, the challenges that multi-object tracking in autonomous vehicles face can be broken down into two categories: the tracking object factor and the backdrop factor. Shape change, scale change, motion blur, etc. are some of the issues brought on by the object’s factors. The impact of backdrop elements is also substantial, particularly the blurring of background interference, occlusion and disappearance of objects, changes in weather, comparable background interference, etc. [4].
2. Overview of Deep Learning-Based Visual Multi-Object Tracking
Deep learning-based visual multi-object tracking systems have several overview techniques from various angles. The methods for visual multi-object tracking based on deep learning are outlined here in terms of algorithm classification, related data sets, and algorithm assessment.
2.1. Visual Multi-Object Tracking Algorithm Based on Deep Learning
The tracking algorithm based on detection results has evolved and has quickly taken over as the standard framework for multi-object tracking due to the rapid advancement of object detection algorithm performance [7]. The TBD sub-modules, such as feature extraction, can be included in the object detection network, though, from the standpoint of the deep neural network’s structure. Joint detection and tracking, or JDT, using a deep network framework to perform visual multi-object tracking, has emerged as a new development trend based on TBD neutron module fusion [11,12]. The attention mechanism has been incorporated into computer vision systems recently because it has the benefit of efficiently capturing the region of interest in the image, enhancing the performance of the entire network [13,14,15,16]. It is used to solve various vision problems, including multi-object tracking. The specific classification structure for the three types of tracking frameworks is shown in Figure 3.
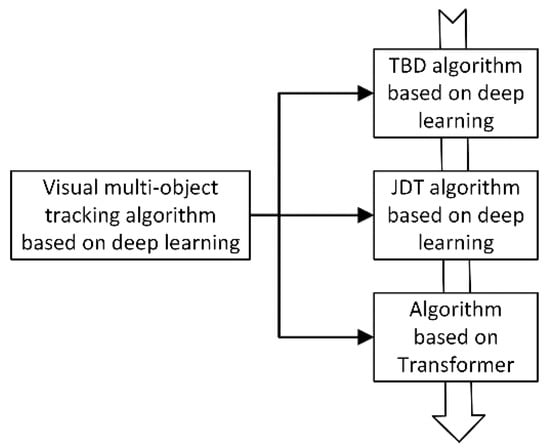
Figure 3. Classification and algorithm of visual multi-object tracking based on deep learning. Overall, the development trend of visual multi-object tracking algorithm is from TBD, to JDT, to Transformer-based tracking algorithm.
At the same time, the characteristics, advantages, and disadvantages of the tracking algorithms of the three types of frameworks are organized as shown in Table 2 [17,18,19,20,21,22,23,24].
Table 2. Comparison of characteristics of three types of visual multi-object tracking algorithms.
| Tracking Algorithm Framework |
Principle | Advantage | Disadvantage |
|---|---|---|---|
| TBD | All objects of interest are detected in each frame of the video, and then they are associated with the detected objects in the previous frame to achieve the effect of tracking | Simple structure and strong interpretability | Over-reliance on object detector performance; bloated algorithm design |
| JDT | End-to-end trainable detection box paradigm to jointly learn detection and appearance features | Multi-module joint learning, weight sharing | Local receptive field, when the object is occluded, the tracking effect is not good |
| 基于变压器 | 变压器编码器-解码器架构,用于跟踪全局和丰富的上下文相互依赖关系 | 并行计算;丰富的全局和上下文信息;跟踪精度和准确性大幅提升,在计算机视觉领域潜力巨大 | 参数过大,计算开销高;基于变压器的网络尚未完全适应计算机视觉领域 |
2.2. MOT 数据集
与传统的机器学习技术相比,深度学习的优势在于它可以自动识别与特定任务相关的数据属性。对于基于深度学习的计算机视觉算法,数据集至关重要。下面概述了自动驾驶跟踪领域经常使用的数据集和特征。由于MOT数据集[25,26]经常更新并且与实际场景更加相似,因此在视觉多目标跟踪领域引起了最大的关注。在MOT数据集上,还测试了其他尖端跟踪方法。
MOT16数据集[25]专门用于跟踪行人。共有 14 个视频、7 个练习集和 7 个测试集。这些视频是使用各种技术创建的,包括固定和移动相机,以及各种拍摄视角。此外,拍摄环境会有所不同,具体取决于是白天还是黑夜以及天气。MOT16探测器称为DPM,在检测行人方面表现更好。
MOT17数据集[25]的视频内容与MOT16相同,但它也提供了两个探测器检测结果,即SDP和Faster R-CNN,它们具有更准确的地面真相注释。
MOT20数据集[26]有8个视频序列、4个训练集和4个测试集,行人密度进一步提高,平均每帧246个行人。
NuScenes数据集[29]为自动驾驶汽车提供了一个完整的传感器数据的大型数据集,包括六个摄像头,一个激光雷达,五个雷达,以及GPS和IMU。与KITTI数据集相比,它包含的对象注释多了七倍以上。对于每个场景,选择其关键帧进行注释,注释速率为 2 Hz。但是,值得注意的是,由于标记了23种类型的对象,因此类不平衡问题将更加严重。
Waymo数据集[30]是用五个LiDAR和五个高分辨率针孔摄像头收集的。整个数据集包含 1150 个场景,分为 1000 个训练集和 150 个测试集,共有约 1200 万个 LiDAR 标注框和约 1200 万个图像标注框。
Mapillary交通标志数据集[31]是世界上最大、最多样化的交通标志数据集,可用于自动驾驶中交通标志的自动检测和分类研究。
为了执行视觉多对象跟踪任务,研究人员收集并介绍了表3中列出的数据集。数据收集中的检测和跟踪元素大多与汽车和行人有关,这有助于增强自动驾驶。
表 3.可视化多对象跟踪数据集摘要。
| 裁判。 | 数据 | 年 | 特征 | 数字对象标识符/网址 |
|---|---|---|---|---|
| [25,26,32 ] | MOT15, 16,17,20 | 2016–2020 | 包含多个不同相机角度和场景的子数据集 | https://doi.org/10.48550/arXiv.1504.01942 https://motchallenge.net/ |
| [27,28 ] | 基蒂跟踪 | 2012 | 为汽车和行人提供注释,场景对象稀疏 | https://doi.org/10.1177/0278364913491297 https://www.cvlibs.net/datasets/kitti/eval_tracking.php |
| [29] | 新场景 | 2019 | 交通繁忙,驾驶条件恶劣 | https://doi.org/10.48550/arXiv.1903.11027 https://www.nuscenes.org/ |
| [30] | 韦莫 | 2020 | 多元化的驾驶环境,密集的标签信息 | https://doi.org/10.48550/arXiv.1912.04838 https://waymo.com/open/data/motion/tfexample |
2.3. MOT 评估指标
设置真实准确的评估指标对于以公正和公平的方式比较视觉多目标跟踪算法的有效性至关重要。构成多目标跟踪评估指标的三个标准是,目标检测是否实时,预测位置是否与实际位置匹配,以及每个对象是否保持不同的ID[33]。MOT 挑战赛提供公认的 MOT 评估指标。
MOTA(多目标跟踪精度):多目标跟踪的精度用于计算跟踪中累积的误差,包括跟踪对象的数量以及它们是否匹配:
其中 FN(假阴性)是与预测帧不匹配的检测帧数;FP(误报)是与检测帧不匹配的预测帧数;IDSW(ID开关)是对象ID变化的次数;GT(地面实况)是跟踪对象的数量。
MOTP(多目标跟踪精度):多目标跟踪的精度,用于评估目标位置是否准确定位。
其中 C t 是第t帧中对象与预测对象之间的匹配数;Bt(i) 是物体在第 t 帧中的相应位置与预测位置之间的距离,也称为匹配误差。
AMOTA(平均多对象跟踪精度):汇总所有对象置信度阈值的 MOTA,而不是使用单个阈值。与用于目标检测的mAP类似,它用于评估跟踪算法在所有阈值下的整体准确性能,以提高算法的鲁棒性。AMOTA可以通过在召回率曲线下积分MOTA来计算,使用插值来近似积分以简化计算。
其中 L 表示召回率值的数量(积分置信阈值),L 越高,近似积分越准确。AMOTA 表示特定召回值 r 下的多目标跟踪精度。
AMOTP(平均多目标跟踪精度):与AMOTA相同的计算方法,以召回为横坐标,MOTP为纵坐标,采用插值法得到AMOTP。
IDF1(ID F1 分数):衡量预测 ID 与正确 ID 之间的差异。
MT(大部分跟踪):在 80% 的时间内成功跟踪的对象数占所有跟踪对象的百分比。
ML(大部分丢失):满足跟踪成功的对象数量的百分比 20% 的时间在所有跟踪的对象中。
FM(分段):评估跟踪完整性,定义为 FM,每当轨迹将其状态从跟踪更改为未跟踪时计数,并在以后的时间点跟踪相同的轨迹。
HOTA(高阶度量):由 [34] 提出的用于评估 MOT 的高阶度量。以前的指标过分强调了检测或关联的重要性。此评估指标明确地平衡了执行准确检测、关联和定位的效果,以比较跟踪器。HOTA评分与人类视觉评估更一致。
其中α是 IoU 阈值,c是正样本轨迹的数量。在目标跟踪实验中,有预测的检测轨迹和地面真实轨迹。两条轨迹之间的交点称为真阳性关联(TPA),预测轨迹中交点外的轨迹称为假阳性关联(FPA)。地面真实轨迹中交叉点外的检测是假阴性关联 (FNA)。
This entry is adapted from the peer-reviewed paper 10.3390/app122110741
This entry is offline, you can click here to edit this entry!