Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Jayme Barbedo | -- | 3168 | 2022-04-06 22:27:04 | | | |
| 2 | Conner Chen | -36 word(s) | 3132 | 2022-04-07 05:28:45 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Barbedo, J. Data Fusion in Agriculture. Encyclopedia. Available online: https://encyclopedia.pub/entry/21433 (accessed on 22 July 2026).
Barbedo J. Data Fusion in Agriculture. Encyclopedia. Available at: https://encyclopedia.pub/entry/21433. Accessed July 22, 2026.
Barbedo, Jayme. "Data Fusion in Agriculture" Encyclopedia, https://encyclopedia.pub/entry/21433 (accessed July 22, 2026).
Barbedo, J. (2022, April 06). Data Fusion in Agriculture. In Encyclopedia. https://encyclopedia.pub/entry/21433
Barbedo, Jayme. "Data Fusion in Agriculture." Encyclopedia. Web. 06 April, 2022.
Copy Citation
The term “data fusion” can be defined as “the process of combining data from multiple sources to produce more accurate, consistent, and concise information than that provided by any individual data source”. Other stricter definitions do exist to better fit narrower contexts. This type of approach has been applied to agricultural problems since the first half of the 1990s, and there has been an increase in the use of this approach. Arguably, the main challenge involved in the use of data fusion techniques involves finding the best approach to fully explore the synergy and complementarities that potentially exist between different types of data and data sources.
data fusion
sensors
digital images
agriculture
crops
1. Introduction
The number (and quality) of sensors used to collect data in different contexts have been steadily growing. Even complex environments, such as agricultural areas, are now being “sensed” via a wide variety of equipment, generating vast amounts of data that can be explored to provide useful information about the area being observed. As a result, the number of studies attempting to explore the wealth of information contained in the sensed data have increased[1][2][3]. However, it is often challenging to translate the advancements achieved in experiments to the conditions found in practice. There are two main reasons for this. First, the studies described in scientific texts are usually limited in scope, because the data used in these experiments usually do not cover all of the variabilities associated with the problem at hand. As a result, while the results reported in those articles may seem encouraging, they often reveal nothing about the performance of the proposed technique under real, unconstrained conditions. Second, even if the data adequately cover the variable conditions found in practice, the adopted sensing technology may not be capable of acquiring enough information to unambiguously resolve the data and provide enough information. For example, even powerful artificial intelligence models fed with RGB digital images are often unsuccessful in recognizing plant diseases from their symptoms, because different disorders can produce similar visual signs[4].
One way to reduce the gaps caused by data limitations is to apply data fusion techniques. The term “data fusion” can be defined as “the process of combining data from multiple sources to produce more accurate, consistent, and concise information than that provided by any individual data source”[5]. Other stricter definitions do exist to better fit narrower contexts. This type of approach has been applied to agricultural problems since the first half of the 1990s[6], and there has been an increase in the use of this approach. Arguably, the main challenge involved in the use of data fusion techniques involves finding the best approach to fully explore the synergy and complementarities that potentially exist between different types of data and data sources. This is particularly true with data having significantly disparate characteristics (for example, digital images and meteorological data).
It is difficult to find a formalization for the data fusion process that fits all agricultural applications, given the variety of data sources and approaches. The formalization presented by Bleiholder and Naumann[7], although derived in a slightly different context, adopts a three-step view of the data fusion process that is applicable in most cases. In the first step, the corresponding attributes that are used to describe the information in different sources need to be identified. Such a correspondence can be easily identified if the data sources are similar, but it can be challenging as the different types of data are being used. This is one of the main reasons for the existence of the three types of data fusion described in the following paragraph. In the second step, the different objects that are described in the data sources need to be identified and aligned. This step is particularly important when data sources are images, because misalignments can lead to inconsistent representations and, as a result, to unreliable answers. Once the data are properly identified and consistent, the actual data fusion can be applied in the third step. In practice, coping with existing data inconsistencies is often ignored[7]. This situation can be (at least partially) remedied by auxiliary tools, such as data profile techniques, which can reduce inconsistencies by extracting and exploring the metadata associated to the data being fused[8].
The most common categorization divides data fusion techniques into three groups[9]: (a) raw data level (also denoted “low-level” and “early integration”), in which different types of data (raw or preprocessed) are simply concatenated into a single matrix, being used in cases in which pieces of data are of the same nature and were properly normalized. (b) Feature level (also denoted “mid-level” and “intermediate integration”), in which features are first extracted from different types of data and then concatenated into a matrix, being mostly used when pieces of data can be treated in such a way they generate features that are compatible and complementary. (c) Decision level (also denoted “high level” and “late integration”), in which classification and regression algorithms are applied separately to each type of datum and then the outputs generated by each model are combined, being more appropriate when data sources are too distinct to be combined at an earlier stage. An alternative classification of data fusion methods was proposed by Ouhami et al.[10]: probability-based, evidence-based, and knowledge-based (Figure 1).
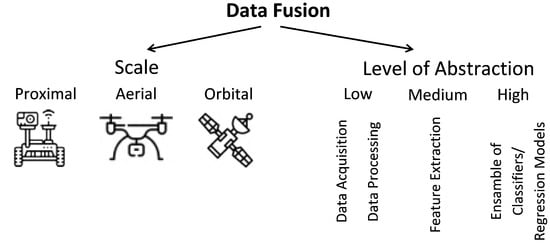
Figure 1. Categorization of data fusion approaches.
In the specific case of agriculture, data can be collected at three different scales—proximal, aerial, and orbital (satellites) (Figure 1). Applications that use proximal data include navigation systems for autonomous vehicles[11][12][13][14][15][16][17], fruit detection[18][19][20][21], plant disease detection[22][23][24], delineation of homogeneous management zones[25][26][27][28][29], soil analysis[30][31][32][33][34][35][36], plant phenotyping[37], among others. Aerial data (collected using UAVs) is used mostly for detection of certain objects (e.g., certain plant species and fruits)[38] and for estimation of agricultural variables (e.g., soil moisture and nitrogen content)[39][40][41]. Satellite data are used for mapping variables as diverse as soil moisture[42][43][44], crop type[45][46][47][48][49][50], crop phenological states[51][52], evapotranspiration[40][53][54][55][56][57][58], nitrogen status[59][60][61][62], biomass[63][64], among others. While most data fusion approaches only use data in the same scale, a few studies have applied data originating from different scales [10][26][28][31][38][40][51][52][64][65][66][67][68][69][70][71].
Table 1. Categories adopted for the data fusion techniques and the data being fused.
| No. | Classes of Data Fusion Technique | No. | Classes of Data Being Fused |
|---|---|---|---|
| 1 | Regression methods | 1 | RGB images |
| 2 | STARFM-like statistical methods | 2 | Multispectral images |
| 3 | Geostatistical tools | 3 | Hyperspectral images |
| 4 | PCA and derivatives | 4 | Thermal images |
| 5 | Kalman filter | 5 | Laser scanning |
| 6 | Machine learning | 6 | SAR images |
| 7 | Deep learning | 7 | Spectroscopy |
| 8 | Decision rules | 8 | Fluorescence images |
| 9 | Majority rules | 9 | Soil measurements |
| 10 | Model output averaging | 10 | Environmental/weather measurements |
| 11 | Others | 11 | Inertial measurements |
| 12 | Position measurements | ||
| 13 | Topographic records and elevation models | ||
| 14 | Historical data | ||
| 15 | Others |
2. Proximal Scale
The majority of studies dedicated to the proximal scale are concentrated in three main areas: prediction of soil properties, delineation of homogeneous zones, and robotic navigation and control. Applications, such as disease and fruit detection, prediction of water content and water stress, estimation of phonological state and yield prediction, are also present. Ten of the references also explored satellite data, and five studies combined proximal and aerial data. Data sources included cameras (RGB, multispectral, thermal, hyperspectral) spectrometers, conductance and resistivity sensors, GPS, inertial sensors, weather data, among many others. With such a variety of sensors available for field applications, efforts to explore their complementarities have been steadily growing (Table 2), but most problems still lack reliable solutions[72].
Table 2. Proximal scale. L, M, and H mean low-, mid-, and high-level data fusion, respectively. The numbers in the fourth column are those adopted in Table 1 for each “fused data” class.
| Ref. | Application | Fusion Technique | Fused Data | Mean Accuracy |
|---|---|---|---|---|
| [30] | Estimation of soil indices | SF (L), MOA (H) | 7 | 0.80–0.90 |
| [73] | Sustainable greenhouse management | Decision rules (L) | 10 | N/A |
| [72] | Human—robot interaction | LSTM-NN (L) | 11 | 0.71–0.97 |
| [25] | Delineation of homogeneous zones in viticulture | GAN (L), geostatistical tools (L) | 2, 9 | N/A |
| [26] | Delineation of homogeneous zones | Kriging and other geostatistical tools (L) | 2, 9 | N/A |
| [51] | Estimation of crop phenological states | Particle filter scheme (L) | 2, 6, 10 | 0.93–0.96 |
| [18] | Fruit detection | LPT (L) and fuzzy logic (L) | 1, 4 | 0.80–0.95 |
| [31] | In-field estimation of soil properties | RK (L), PLSR (L) | 3, 9 | >0.5 |
| [74] | Delineation of homogeneous management zones | Kriging (L), Gaussian anamorphosis (L) | 9, 15 | 0.66 |
| [75] | Delineation of homogeneous management zones | Kriging (L), Gaussian anamorphosis (L) | 9, 15 | N/A |
| [27] | Delineation of homogeneous management zones | Kriging (L),Gaussian anamorphosis (L) | 9, 15 | N/A |
| [76] | Crop nutritional status determination | PCA (L) | 7, 8 | 0.7–0.9 |
| [22] | Detection of olive quick decline syndrome | CNN (M) | 1 | 0.986 |
| [65] | Monitoring Agricultural Terraces | Coregistering and information extraction (L/M) | 5 | N/A |
| [77] | Prediction of canopy water content of rice | BPNN (M), RF (M), PLSR (M) | 2 | 0.98–1.00 |
| [11] | Localization of a wheeled mobile robot | Dempster–Shafer (L) and Kalman filter (L) | 11, 12 | 0.97 |
| [19] | Immature green citrus fruit detection | Color-thermal probability algorithm (H) | 1, 4 | 0.90–0.95 |
| [28] | Delineation of management zones | K-means clustering (L) | 2, 9, 14 | N/A |
| [78] | Segmentation for targeted application of products | Discrete wavelets transform (M) | 1 | 0.92 |
| [12] | System for agricultural vehicle positioning | Kalman filter (L) | 11, 12 | N/A |
| [13] | System for agricultural vehicle positioning | Kalman filter (L) | 11, 12 | N/A |
| [67] | Yield gap attribution in maize | Empirical equations (L) | 15 | 0.37–0.74 |
| [32] | Soil environmental quality assessment | Analytic hierarchy process, weighted average (L) | 15 | N/A |
| [33] | Predict soil properties | PLSR (L) | 7, 9, 13 | 0.80–0.96 |
| [14] | System for agricultural vehicle positioning | Discrete Kalman filter (L) | 11, 13 | N/A |
| [34] | Estimating soil macronutrients | PLSR (L) | 7, 9 | 0.70–0.95 |
| [20] | Citrus fruit detection and localization | Daubechies wavelet transform (L) | 1, 2 | 0.91 |
| [15] | Estimation of agricultural equipment roll angle | Kalman filtering (L) | 11 | N/A |
| [79] | Predicting toxic elements in the soil | PLSR, PCA, and SPA (L/M) | 7, 8 | 0.93–0.98 |
| [68] | Review: image fusion technology in agriculture | N/A | N/A | N/A |
| [80] | Heterogeneous sensor data fusion | Deep multimodal encoder (L) | 10 | N/A |
| [81] | Agricultural vulnerability assessments | Binary relevance (L), RF (L), and XGBoost (L) | 10,14 | 0.67–0.98 |
| [35] | Prediction of multiple soil properties | SMLR (L), PLSR (L), PCA/SMLR combination (L) | 7, 9 | 0.60–0.95 |
| [82] | Prediction of environment variables | Sparse model (L), LR (L), SVM (L), ELM (L) | 10 | 0.96 |
| [64] | Estimation of biomass in grasslands | Simple quadratic combination (L) | 2, 15 | 0.66–0.88 |
| [23] | Plant disease detection | Kohonen self-organizing maps (M) | 3, 8 | 0.95 |
| [83] | Water stress detection | Least squares support vectors machine (M) | 3, 8 | 0.99 |
| [84] | Delineation of water holding capacity zones | ANN (L), MLR (L) | 7, 9 | 0.94–0.97 |
| [85] | Potential of site-specific seeding (potato) | PLSR (L) | 2, 9 | 0.64–0.90 |
| [86] | 3D characterization of fruit trees | Pixel level mapping between the images (L) | 4, 5 | N/A |
| [87] | Measurements of sprayer boom movements | Summations of normalized measurements (L) | 11 | N/A |
| [10] | Review: IoT and data fusion for crop disease | N/A | N/A | N/A |
| [88] | Prediction of wheat yield and protein | Canonical powered partial least-squares (L) | 7, 10 | 0.76–0.94 |
| [69] | Wheat yield prediction | CP-ANN (L), XY-fused networks (L), SKN (L) | 2, 7 | 0.82 |
| [89] | Topsoil clay mapping | PLSR (L) and kNN (L) | 7, 9, 13 | 0.94–0.96 |
| [21] | Fruit detection | CNN (L); scoring system (H) | 1, 2 | 0.84 |
| [37] | 3D reconstruction for agriculture phenotyping | Linear interpolation (L) | 1, 10 | N/A |
| [29] | Delineation of site-specific management zones | CoKriging (L) | 2 | 0.55–0.77 |
| [90] | Orchard mapping and mobile robot localization | Laser data projection onto the RGB images (L) | 1, 5 | 0.97 |
| [24] | Modelling crop disease severity | 2 ANN architectures (L) | 10, 15 | 0.90–0.98 |
| [91] | Tropical soil fertility analysis | SVM (L), PLS (L), least squares modeling (L) | 2, 8 | 0.30–0.95 |
| [92] | Internet of things applied to agriculture | Hydra system (L/M/H) | 9, 10, 15 | 0.93–0.99 |
| [70] | Review: data fusion in agricultural systems | N/A | N/A | N/A |
| [36] | Soil health assessment | PLSR (L) | 7, 9 | 0.78 |
| [93] | Prediction of Soil Texture | SMLR (L), PLSR (L) and PCA (L) | 7, 8 | 0.61–0.88 |
| [94] | Rapid determination of soil class | Outer product analysis (L) | 7 | 0.65 |
| [16] | Navigation of autonomous vehicle | MSPI algorithm with Bayesian estimator (L) | 11, 12 | N/A |
| [38] | Detection of cotton plants | Discriminant analysis (M) | 2, 7 | 0.97 |
| [95] | Map-based variable-rate manure application | K-means clustering (L) | 2, 9 | 0.60–0.93 |
| [17] | Navigation of autonomous vehicles | Kalman filter (L) | 11, 12 | N/A |
| [96] | Robust tomato recognition for robotic harvesting | Wavelet transform (L) | 1 | 0.93 |
| [97] | Navigation of autonomous vehicle | Self-adaptive PCA, dynamic time warping (L) | 1, 11 | N/A |
| [98] | Recognition of wheat spikes | Gram–Schmidt fusion algorithm (L) | 1, 2 | 0.60–0.79 |
3. Aerial Scale
Studies employing UAVs to solve agricultural problems are growing in number, but they are still outnumbered by proximal and orbital approaches. Most studies are dedicated to crop monitoring and object detection (weed, crops, etc.), although applications, such as phenotyping and water management, are also present. Almost all techniques are based on some kind of digital image (RGB, multispectral, thermal, hyperspectral). Many approaches explore the complementarity of aerial images with proximal (four articles) and orbital (six articles) data. Only eight studies employed the aerial data alone (Table 3).
Table 3. Aerial scale. L, M, and H mean low-, mid-, and high-level data fusion, respectively. The numbers in the fourth column are those adopted in Table 1 for each “fused data” class.
| Ref. | Application | Fusion Technique | Fused Data | Mean Accuracy |
|---|---|---|---|---|
| [99] | Root zone soil moisture estimation | NN (M), DRF (M), GBM (M), GLM (M) | 2,11 | 0.90–0.95 |
| [100] | Gramineae weed detection in rice fields | Haar wavelet transformation (L) | 1, 2 | 0.70–0.85 |
| [65] | Monitoring agricultural terraces | Coregistering and information extraction (L) | 5 | N/A |
| [66] | Spectral–temporal response surfaces | Bayesian data imputation (L) | 2, 3 | 0.77–0.83 |
| [101] | Phenotyping of soybean | PLSR (L), SVR (L), ELR (L) | 1, 2, 4 | 0.83–0.90 |
| [39] | Soybean yield prediction | PLSR (M), RF (M), SVR (M), 2 types of DNN (M) | 1, 2, 4 | 0.72 |
| [52] | Crop monitoring | PLSR (M), RF (M), SVR (M), ELR (M) | 1, 2 | 0.60–0.93 |
| [40] | Evapotranspiration estimation | MSDF-ET (L) | 1, 2, 4 | 0.68–0.77 |
| [10] | Review: IoT and data fusion for crop disease | N/A | N/A | N/A |
| [102] | Arid and semi-arid land vegetation monitoring | Decision tree (L/M) | 3, 5 | 0.84–0.89 |
| [41] | Biomass and leaf nitrogen content in sugarcane | PCA and linear regression (L) | 2, 5 | 0.57 |
| [70] | Review: data fusion in agricultural systems | N/A | N/A | N/A |
| [103] | Navigation system for UAV | EKF (L) | 11, 12 | 0.98 |
| [38] | Detection of cotton plants | Discriminant analysis (M) | 2 | 0.97 |
| [71] | Vineyard monitoring | PLSR (M), SVR (M), RFR (M), ELR (M) | 2 | 0.98 |
4. Orbital Scale
A large portion of the articles employing satellite images aimed to either compensate for data gaps present in a primary data source by fusing it with another source of data (for example, combining optical and SAR images)[6][45][47][48][49][51][104][105], or increase the spatial resolution of the relatively coarse images collected by satellites with high revisit frequencies[42][43][44][55][57][58][106][107][108][109]. In the latter, the fused results usually inherit the details of the high spatial resolution images and the temporal revisit the frequencies of their counterparts, although the quality of the fused data usually do not match that obtained through actual missions, especially when surface changes are rapid and subtle[110]. As argued by Tao et al.[111], different sensors and image processing algorithms lead inevitably to data with some level of inconsistency, which can make rapid changes difficult to detect.
Landsat and MODIS images and products still dominate, but other satellite constellations, such as Sentinel, Worldview, GeoEye, and others, are being increasingly adopted. Data fusion has been applied to satellite images for quite some time, and well established techniques, such as STARFM and its variants, are still often used, but the interest for machine learning techniques, especially in the form of deep learning models, has been growing consistently. Water management in its several forms (evapotranspiration estimation, mapping of irrigated areas, drought detection, etc.) is by far the most common application. Yield estimation, crop monitoring, land cover classification, and prediction of soil properties are also common applications.
A major challenge associated with the orbital scale is the existence of highly heterogeneous regions with a high degree of fragmentation[108][112]. Solutions to this problem are not trivial and, as stated by Masiza et al.[113], “…successful mapping of a fragmented agricultural landscape is a function of objectively derived datasets, adapted to geographic context, and an informed optimization of mapping algorithms”. However, there are cases in which target areas can have sizes smaller than the pixel resolution of the satellite images[53]. In theses cases, pairing the images with images or other types of data obtained at higher resolutions (aerial or proximal) may be the only viable solution. Satellite data were fused together with proximal and aerial data in ten and six studies, respectively (Table 4).
Table 4. Orbital scale. L, M, and H mean low-, mid-, and high-level data fusion, respectively. The numbers in the fourth column are those adopted in Table 1 for each “fused data” class.
| Ref. | Application | Fusion Technique | Fused Data | Mean Accuracy |
|---|---|---|---|---|
| [42] | Soil moisture mapping | ESTARFM (L) | 2 | 0.70–0.84 |
| [45] | Crop type mapping | 2D and 3D U-Net (L), SegNet (L), RF (L) | 2, 6 | 0.91–0.99 |
| [43] | Estimation of surface soil moisture | ESTARFM (L) | 2 | 0.55–0.92 |
| [26] | Delineation of homogeneous zones | Kriging and other geostatistical tools | 2, 9 | N/A |
| [51] | Estimation of crop phenological states | Particle filter scheme (L/M) | 2, 6, 10 | 0.93–0.96 |
| [53] | Evapotranspiration mapping at field scales | STARFM (L) | 2 | 0.92–0.95 |
| [31] | In-field estimation of soil properties | RK (L), PLSR (L) | 3, 9 | >0.5 |
| [59] | Estimation of wheat grain nitrogen uptake | BK (L) | 2, 3 | N/A |
| [44] | Surface soil moisture monitoring | Linear regression analysis and Kriging (L/M) | 2, 15 | 0.51–0.84 |
| [46] | Crop discrimination and classification | Voting system (H) | 2, 6 | 0.96 |
| [9] | Review on multimodality and data fusion in RS | N/A | N/A | N/A |
| [47] | Crop Mapping | Pixelwise matching (H) | 2, 6 | 0.94 |
| [110] | Review on fusion between MODIS and Landsat | N/A | N/A | N/A |
| [106] | Mapping crop progress | STARFM (L) | 2 | 0.54–0.86 |
| [66] | Generation of spectral–-temporal response | Bayesian data imputation (L) | 2, 3 | 0.77–0.83 |
| [28] | Delineation of management zones | K-means clustering (L) | 2, 9, 14 | N/A |
| [114] | Mapping irrigated areas | Decision tree (L) | 2 | 0.67–0.93 |
| [54] | Evapotranspiration mapping | Empirical exploration of band relationships (L) | 2, 4 | 0.20–0.97 |
| [28] | Delineation of management zones | K-means clustering (L) | 2, 9, 14 | N/A |
| [67] | Yield gap attribution in maize | Empirical equations (L) | 15 | 0.37–0.74 |
| [63] | Change detection and biomass estimation in rice | Graph-based data fusion (L) | 2 | 0.17–0.90 |
| [107] | Leaf area index estimation | STARFM (L) | 2 | 0.69–0.76 |
| [55] | Evapotranspiration estimates | STARFM (M) | 2 | N/A |
| [115] | Classification of agriculture drought | Optimal weighting of individual indices (M) | 2 | 0.80–0.92 |
| [56] | Mapping daily evapotranspiration | STARFM (L) | 2 | N/A |
| [20] | Mapping of cropping cycles | STARFM (L) | 2 | 0.88–0.91 |
| [116] | Evapotranspiration partitioning at field scales | STARFM (L) | 2 | N/A |
| [68] | Review: image fusion technology in agriculture | N/A | N/A | N/A |
| [52] | Crop monitoring | PLSR (M), RF (M), SVR (M), ELR (M) | 1, 2, 4 | 0.60–0.93 |
| [113] | Mapping of smallholder crop farming | XGBoost (L/M and H), RF (H), SVM (H), ANN (H), NB (H) | 2, 6 | 0.96–0.98 |
| [64] | Estimation of biomass in grasslands | Simple quadratic combination (L/M) | 2, 15 | 0.66–0.88 |
| [40] | Evapotranspiration estimation | MSDF-ET (L) | 1, 2, 4 | 0.68–0.77 |
| [117] | Semantic segmentation of land types | Majority rule (H) | 2 | 0.99 |
| [118] | Eucalyptus trees identification | Fuzzy information fusion (L) | 2 | 0.98 |
| [10] | Review: IoT and data fusion for crop disease | N/A | N/A | N/A |
| [69] | Wheat yield prediction | CP-ANN (M), XY-fused networks (M), SKN (M) | 2, 7 | 0.82 |
| [112] | Drought monitoring | RF (M) | 2, 15 | 0.29–0.77 |
| [48] | Crop type classification and mapping | RF (L) | 2, 6, 13 | 0.37–0.94 |
| [119] | Time series data fusion | Environmental data acquisition module | 10 | N/A |
| [57] | Evapotranspiration prediction in vineyard | STARFM (L) | 2 | 0.77–0.81 |
| [108] | Daily NDVI product at a 30-m spatial resolution | GKSFM (M) | 2 | 0.88 |
| [49] | Crop classification | Committee of MLPs (L) | 2, 6 | 0.65–0.99 |
| [6] | Multisource classification of remotely sensed data | Bayesian formulation (L) | 2, 6 | 0.74 |
| [111] | Fractional vegetation cover estimation | Data fusion and vegetation growth models (L) | 2 | 0.83–0.95 |
| [120] | Land cover monitoring | FARMA (L) | 2, 6 | N/A |
| [121] | Crop ensemble classification | mosaicking (L), classifier majority voting (H) | 2 | 0.82–0.85 |
| [70] | Review: data fusion in agricultural systems | N/A | N/A | N/A |
| [50] | In-season mapping of crop type | Classification tree (M) | 2 | 0.93–0.99 |
| [122] | Building frequent landsat-like imagery | STARFM (L) | 2 | 0.63–0.99 |
| [58] | Evapotranspiration mapping | SADFAET (M) | 2 | N/A |
| [123] | Temporal land use mapping | Dynamic decision tree (M) | 2 | 0.86–0.96 |
| [124] | High-resolution leaf area index estimation | STDFA (L) | 2 | 0.98 |
| [125] | Monitoring cotton root rot | ISTDFA (M) | 2 | 0.79–0.97 |
| [109] | Monitoring crop water content | Modified STARFM (L) | 2 | 0.44–0.85 |
| [104] | Soil moisture content estimation | Vector concatenation, followed by ANN (M) | 2, 6 | 0.39–0.93 |
| [126] | Impact of tile drainage on evapotranspiration | STARFM (L) | 2 | 0.23–0.91 |
| [127] | Estimation of leaf area index | CACAO method (L) | 2 | 0.88 |
| [105] | Mapping winter wheat in urban region | SVM (M), RF (M) | 2, 6 | 0.98 |
| [128] | Leaf area index estimation | ESTARFM (L), linear regression model (M) | 2 | 0.37–0.95 |
| [71] | Vineyard monitoring | PLSR (M), SVR (M), RFR (M), ELR (M) | 2 | 0.98 |
Another important challenge is the difficulty of obtaining/collecting reference data for validation of the techniques applied. This problem can be particularly difficult if the reference data need to be gathered in-loco. It is also important to consider that, even if reference data can be collected, differences in granularity and the positions of the sample points can make the comparison with the fused data difficult or even unfeasible[112].
References
- Barbedo, J. Deep learning applied to plant pathology: The problem of data representativeness. Trop. Plant Pathol. 2022, 47, 85–94 .
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37.
- Coble, K.H.; Mishra, A.K.; Ferrell, S.; Griffin, T. Big Data in Agriculture: A Challenge for the Future. Appl. Econ. Perspect. Policy 2018, 40, 79–96.
- Barbedo, J.G. Factors influencing the use of deep learning for plant disease recognition. Biosyst. Eng. 2018, 172, 84–91.
- Munir, A.; Blasch, E.; Kwon, J.; Kong, J.; Aved, A. Artificial Intelligence and Data Fusion at the Edge. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 62–78.
- Solberg, A.; Jain, A.; Taxt, T. Multisource classification of remotely sensed data: Fusion of Landsat TM and SAR images. IEEE Trans. Geosci. Remote Sens. 1994, 32, 768–778.
- Bleiholder, J.; Naumann, F. Data Fusion. ACM Comput. Surv. 2009, 41, 1–40.
- Caruccio, L.; Cirillo, S. Incremental Discovery of Imprecise Functional Dependencies. J. Data Inf. Qual. 2020, 12, 1–25.
- Dalla Mura, M.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and Opportunities of Multimodality and Data Fusion in Remote Sensing. Proc. IEEE 2015, 103, 1585–1601.
- Ouhami, M.; Hafiane, A.; Es-Saady, Y.; El Hajji, M.; Canals, R. Computer Vision, IoT and Data Fusion for Crop Disease Detection Using Machine Learning: A Survey and Ongoing Research. Remote Sens. 2021, 13, 2486.
- Erfani, S.; Jafari, A.; Hajiahmad, A. Comparison of two data fusion methods for localization of wheeled mobile robot in farm conditions. Artif. Intell. Agric. 2019, 1, 48–55.
- Guo, L.; Zhang, Q. Wireless Data Fusion System for Agricultural Vehicle Positioning. Biosyst. Eng. 2005, 91, 261–269.
- Han, J.H.; Park, C.H.; Kwon, J.H.; Lee, J.; Kim, T.S.; Jang, Y.Y. Performance Evaluation of Autonomous Driving Control Algorithm for a Crawler-Type Agricultural Vehicle Based on Low-Cost Multi-Sensor Fusion Positioning. Appl. Sci. 2020, 10, 4667.
- Khot, L.; Tang, L.; Steward, B.; Han, S. Sensor fusion for improving the estimation of roll and pitch for an agricultural sprayer. Biosyst. Eng. 2008, 101, 13–20.
- Li, Y.; Jia, H.; Qi, J.; Sun, H.; Tian, X.; Liu, H.; Fan, X. An Acquisition Method of Agricultural Equipment Roll Angle Based on Multi-Source Information Fusion. Sensors 2020, 20, 2082.
- Zaidner, G.; Shapiro, A. A novel data fusion algorithm for low-cost localisation and navigation of autonomous vineyard sprayer robots. Biosyst. Eng. 2016, 146, 133–148.
- Zhang, Q.; Chen, Q.; Xu, Z.; Zhang, T.; Niu, X. Evaluating the navigation performance of multi-information integration based on low-end inertial sensors for precision agriculture. Precis. Agric. 2021, 22, 627–646.
- Bulanon, D.; Burks, T.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22.
- Gan, H.; Lee,W.; Alchanatis, V.; Ehsani, R.; Schueller, J. Immature green citrus fruit detection using color and thermal images. Comput. Electron. Agric. 2018, 152, 117–125.
- Li, P.; Lee, S.H.; Hsu, H.Y.; Park, J.S. Nonlinear Fusion of Multispectral Citrus Fruit Image Data with Information Contents. Sensors 2017, 17, 142.
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222.
- Cruz, A.C.; Luvisi, A.; De Bellis, L.; Ampatzidis, Y. X-FIDO: An Effective Application for Detecting Olive Quick Decline Syndrome with Deep Learning and Data Fusion. Front. Plant Sci. 2017, 8, 1741.
- Moshou, D.; Bravo, C.; Oberti, R.; West, J.; Bodria, L.; McCartney, A.; Ramon, H. Plant disease detection based on data fusion of hyper-spectral and multi-spectral fluorescence imaging using Kohonen maps. Real-Time Imaging 2005, 11, 75–83.
- Shankar, P.; Johnen, A.; Liwicki, M. Data Fusion and Artificial Neural Networks for Modelling Crop Disease Severity. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8.
- Anastasiou, E.; Castrignanò, A.; Arvanitis, K.; Fountas, S. A multi-source data fusion approach to assess spatial-temporal variability and delineate homogeneous zones: A use case in a table grape vineyard in Greece. Sci. Total Environ. 2019, 684, 155–163.
- De Benedetto, D.; Castrignano, A.; Diacono, M.; Rinaldi, M.; Ruggieri, S.; Tamborrino, R. Field partition by proximal and remote sensing data fusion. Biosyst. Eng. 2013, 114, 372–383.
- Castrignanò, A.; Buttafuoco, G.; Quarto, R.; Parisi, D.; Viscarra Rossel, R.; Terribile, F.; Langella, G.; Venezia, A. A geostatistical sensor data fusion approach for delineating homogeneous management zones in Precision Agriculture. CATENA 2018, 167, 293–304.
- Guerrero, A.; De Neve, S.; Mouazen, A.M. Data fusion approach for map-based variable-rate nitrogen fertilization in barley and wheat. Soil Tillage Res. 2021, 205, 104789.
- Shaddad, S.; Madrau, S.; Castrignanò, A.; Mouazen, A. Data fusion techniques for delineation of site-specific management zones in a field in UK. Precis. Agric. 2016, 17, 200–217.
- Afriyie, E.; Verdoodt, A.; Mouazen, A.M. Data fusion of visible near-infrared and mid-infrared spectroscopy for rapid estimation of soil aggregate stability indices. Comput. Electron. Agric. 2021, 187, 106229.
- Casa, R.; Castaldi, F.; Pascucci, S.; Basso, B.; Pignatti, S. Geophysical and Hyperspectral Data Fusion Techniques for In-Field Estimation of Soil Properties. Vadose Zone J. 2013, 12, vzj2012.0201.
- Huo, Z.; Tian, J.;Wu, Y.; Ma, F. A Soil Environmental Quality Assessment Model Based on Data Fusion and Its Application in Hebei Province. Sustainability 2020, 12, 6804.
- Ji, W.; Adamchuk, V.I.; Chen, S.; Mat Su, A.S.; Ismail, A.; Gan, Q.; Shi, Z.; Biswas, A. Simultaneous measurement of multiple soil properties through proximal sensor data fusion: A case study. Geoderma 2019, 341, 111–128. 2019.01.006.
- La,W.; Sudduth, K.; Kim, H.; Chung, S. Fusion of spectral and electrochemical sensor data for estimating soil macronutrients. Trans. ASABE 2016, 59, 787–794.
- Mahmood, H.S.; Hoogmoed, W.B.; van Henten, E.J. Sensor data fusion to predict multiple soil properties. Precis. Agric. 2012, 13, 628–645.
- Veum, K.S.; Sudduth, K.A.; Kremer, R.J.; Kitchen, N.R. Sensor data fusion for soil health assessment. Geoderma 2017, 305, 53–61.
- Sampaio, G.S.; Silva, L.A.; Marengoni, M. 3D Reconstruction of Non-Rigid Plants and Sensor Data Fusion for Agriculture Phenotyping. Sensors 2021, 21, 4115.
- Zhang, H.; Lan, Y.; Suh, C.P.C.; Westbrook, J.; Clint Hoffmann, W.; Yang, C.; Huang, Y. Fusion of remotely sensed data from airborne and ground-based sensors to enhance detection of cotton plants. Comput. Electron. Agric. 2013, 93, 55–59.
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599.
- Mokhtari, A.; Ahmadi, A.; Daccache, A.; Drechsler, K. Actual Evapotranspiration from UAV Images: A Multi-Sensor Data Fusion Approach. Remote Sens. 2021, 13, 2315.
- Shendryk, Y.; Sofonia, J.; Garrard, R.; Rist, Y.; Skocaj, D.; Thorburn, P. Fine-scale prediction of biomass and leaf nitrogen content in sugarcane using UAV LiDAR and multispectral imaging. Int. J. Appl. Earth Obs. Geoinf. 2020, 92, 102177.
- Abowarda, A.S.; Bai, L.; Zhang, C.; Long, D.; Li, X.; Huang, Q.; Sun, Z. Generating surface soil moisture at 30 m spatial resolution using both data fusion and machine learning toward better water resources management at the field scale. Remote Sens. Environ. 2021, 255, 112301.
- Bai, L.; Long, D.; Yan, L. Estimation of Surface Soil Moisture With Downscaled Land Surface Temperatures Using a Data Fusion Approach for Heterogeneous Agricultural Land. Water Resour. Res. 2019, 55, 1105–1128.
- Chen, C.F.; Valdez, M.C.; Chang, N.B.; Chang, L.Y.; Yuan, P.Y. Monitoring Spatiotemporal Surface Soil Moisture Variations During Dry Seasons in Central America With Multisensor Cascade Data Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4340–4355.
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-optical fusion for crop type mapping using deep learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235.
- Chen, S.; Useya, J.; Mugiyo, H. Decision-level fusion of Sentinel-1 SAR and Landsat 8 OLI texture features for crop discrimination and classification: Case of Masvingo, Zimbabwe. Heliyon 2020, 6, e05358.
- Forkuor, G.; Conrad, C.; Thiel, M.; Ullmann, T.; Zoungrana, E. Integration of Optical and Synthetic Aperture Radar Imagery for Improving Crop Mapping in Northwestern Benin, West Africa. Remote Sens. 2014, 6, 6472–6499.
- Pott, L.P.; Amado, T.J.C.; Schwalbert, R.A.; Corassa, G.M.; Ciampitti, I.A. Satellite-based data fusion crop type classification and mapping in Rio Grande do Sul, Brazil. ISPRS J. Photogramm. Remote Sens. 2021, 176, 196–210. 2021.04.015.
- Skakun, S.; Kussul, N.; Shelestov, A.Y.; Lavreniuk, M.; Kussul, O. Efficiency Assessment of Multitemporal C-Band Radarsat-2 Intensity and Landsat-8 Surface Reflectance Satellite Imagery for Crop Classification in Ukraine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3712–3719.
- Villa, P.; Stroppiana, D.; Fontanelli, G.; Azar, R.; Brivio, P.A. In-Season Mapping of Crop Type with Optical and X-Band SAR Data: A Classification Tree Approach Using Synoptic Seasonal Features. Remote Sens. 2015, 7, 12859–12886.
- De Bernardis, C.; Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Contribution to Real-Time Estimation of Crop Phenological States in a Dynamical Framework Based on NDVI Time Series: Data Fusion With SAR and Temperature. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3512–3523.
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Daloye, A.M.; Erkbol, H.; Fritschi, F.B. Crop Monitoring Using Satellite/UAV Data Fusion and Machine Learning. Remote Sens. 2020, 12, 1357.
- Cammalleri, C.; Anderson, M.; Gao, F.; Hain, C.; Kustas,W. Mapping daily evapotranspiration at field scales over rainfed and irrigated agricultural areas using remote sensing data fusion. Agric. For. Meteorol. 2014, 186, 1–11.
- Guzinski, R.; Nieto, H.; Sandholt, I.; Karamitilios, G. Modelling High-Resolution Actual Evapotranspiration through Sentinel-2 and Sentinel-3 Data Fusion. Remote Sens. 2020, 12, 1433.
- Knipper, K.; Kustas, W.; Anderson, M.; Alfieri, J.; Prueger, J.; Hain, C.; Gao, F.; Yang, Y.; McKee, L.; Nieto, H.; et al. Evapotranspiration estimates derived using thermal-based satellite remote sensing and data fusion for irrigation management in California vineyards. Irrig. Sci. 2019, 37, 431–449.
- Li, Y.; Huang, C.; Gu, J. Mapping daily evapotranspiration using ASTER and MODIS images based on data fusion over irrigated agricultural areas. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 4394–4397.
- Semmens, K.A.; Anderson, M.C.; Kustas, W.P.; Gao, F.; Alfieri, J.G.; McKee, L.; Prueger, J.H.; Hain, C.R.; Cammalleri, C.; Yang, Y.; et al. Monitoring daily evapotranspiration over two California vineyards using Landsat 8 in a multi-sensor data fusion approach. Remote Sens. Environ. 2016, 185, 155–170.
- Wang, T.; Tang, R.; Li, Z.L.; Jiang, Y.; Liu, M.; Niu, L. An Improved Spatio-Temporal Adaptive Data Fusion Algorithm for Evapotranspiration Mapping. Remote Sens. 2019, 11, 761.
- Castaldi, F.; Castrignanò, A.; Casa, R. A data fusion and spatial data analysis approach for the estimation of wheat grain nitrogen uptake from satellite data. Int. J. Remote Sens. 2016, 37, 4317–4336.
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69.
- Brinkhoff, J.; Dunn, B.W.; Robson, A.J.; Dunn, T.S.; Dehaan, R.L. Modeling Mid-Season Rice Nitrogen Uptake Using Multispectral Satellite Data. Remote Sens. 2019, 11, 1837.
- Nutini, F.; Confalonieri, R.; Crema, A.; Movedi, E.; Paleari, L.; Stavrakoudis, D.; Boschetti, M. An operational workflow to assess rice nutritional status based on satellite imagery and smartphone apps. Comput. Electron. Agric. 2018, 154, 80–92.
- Jimenez-Sierra, D.A.; Benítez-Restrepo, H.D.; Vargas-Cardona, H.D.; Chanussot, J. Graph-Based Data Fusion Applied to: Change Detection and Biomass Estimation in Rice Crops. Remote Sens. 2020, 12, 2683.
- Moeckel, T.; Safari, H.; Reddersen, B.; Fricke, T.; Wachendorf, M. Fusion of Ultrasonic and Spectral Sensor Data for Improving the Estimation of Biomass in Grasslands with Heterogeneous Sward Structure. Remote Sens. 2017, 9, 98.
- Cucchiaro, S.; Fallu, D.J.; Zhang, H.; Walsh, K.; Van Oost, K.; Brown, A.G.; Tarolli, P. Multiplatform-SfM and TLS Data Fusion for Monitoring Agricultural Terraces in Complex Topographic and Landcover Conditions. Remote Sens. 2020, 12, 1946.
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of Spectral–Temporal Response Surfaces by Combining Multispectral Satellite and Hyperspectral UAV Imagery for Precision Agriculture Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146.
- Hu, S.; Mo, X.; Huang, F. Retrieval of photosynthetic capability for yield gap attribution in maize via model-data fusion. Agric. Water Manag. 2019, 226, 105783.
- Li, D.; Song, Z.; Quan, C.; Xu, X.; Liu, C. Recent advances in image fusion technology in agriculture. Comput. Electron. Agric. 2021, 191, 106491.
- Pantazi, X.; Moshou, D.; Alexandridis, T.; Whetton, R.; Mouazen, A. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65.
- Üstundag, B. Data Fusion in Agricultural Information Systems. In Agro-Geoinformatics; Di, L., Üstundag, B., Eds.; Springer: New York, NY, USA, 2021; pp. 103–141.
- Zhou, X.; Yang, L.; Wang, W.; Chen, B. UAV Data as an Alternative to Field Sampling to Monitor Vineyards Using Machine Learning Based on UAV/Sentinel-2 Data Fusion. Remote Sens. 2021, 13, 457.
- Anagnostis, A.; Benos, L.; Tsaopoulos, D.; Tagarakis, A.; Tsolakis, N.; Bochtis, D. Human Activity Recognition through Recurrent Neural Networks for Human–Robot Interaction in Agriculture. Appl. Sci. 2021, 11, 2188.
- Aiello, G.; Giovino, I.; Vallone, M.; Catania, P.; Argento, A. A decision support system based on multisensor data fusion for sustainable greenhouse management. J. Clean. Prod. 2018, 172, 4057–4065.
- Castrignanò, A.; Landrum, C.; Benedetto, D.D. Delineation of Management Zones in Precision Agriculture by Integration of Proximal Sensing with Multivariate Geostatistics. Examples of Sensor Data Fusion. Agric. Conspec. Sci. 2015, 80, 39–45.
- Castrignanò, A.; Buttafuoco, G.; Quarto, R.; Vitti, C.; Langella, G.; Terribile, F.; Venezia, A. A Combined Approach of Sensor Data Fusion and Multivariate Geostatistics for Delineation of Homogeneous Zones in an Agricultural Field. Sensors 2017, 17, 2794.
- Comino, F.; Ayora-Cañada, M.; Aranda, V.; Díaz, A.; Domínguez-Vidal, A. Near-infrared spectroscopy and X-ray fluorescence data fusion for olive leaf analysis and crop nutritional status determination. Talanta 2018, 188, 676–684.
- Elsherbiny, O.; Fan, Y.; Zhou, L.; Qiu, Z. Fusion of Feature Selection Methods and Regression Algorithms for Predicting the CanopyWater Content of Rice Based on Hyperspectral Data. Agriculture 2021, 11, 51.
- Guijarro, M.; Riomoros, I.; Pajares, G.; Zitinski, P. Discrete wavelets transform for improving greenness image segmentation in agricultural images. Comput. Electron. Agric. 2015, 118, 396–407.
- Li, F.; Xu, L.; You, T.; Lu, A. Measurement of potentially toxic elements in the soil through NIR, MIR, and XRF spectral data fusion. Comput. Electron. Agric. 2021, 187, 106257.
- Liu, Z.; Zhang, W.; Lin, S.; Quek, T.Q. Heterogeneous Sensor Data Fusion By Deep Multimodal Encoding. IEEE J. Sel. Top. Signal Process. 2017, 11, 479–491.
- López, I.D.; Figueroa, A.; Corrales, J.C. Multi-Label Data Fusion to Support Agricultural Vulnerability Assessments. IEEE Access 2021, 9, 88313–88326.
- Mancipe-Castro, L.; Gutiérrez-Carvajal, R. Prediction of environment variables in precision agriculture using a sparse model as data fusion strategy. Inf. Process. Agric. 2021.
- Moshou, D.; Pantazi, X.E.; Kateris, D.; Gravalos, I. Water stress detection based on optical multisensor fusion with a least squares support vector machine classifier. Biosyst. Eng. 2014, 117, 15–22.
- Mouazen, A.M.; Alhwaimel, S.A.; Kuang, B.; Waine, T. Multiple on-line soil sensors and data fusion approach for delineation of water holding capacity zones for site specific irrigation. Soil Tillage Res. 2014, 143, 95–105.
- Munnaf, M.; Haesaert, G.; Van Meirvenne, M.; Mouazen, A. Map-based site-specific seeding of consumption potato production using high-resolution soil and crop data fusion. Comput. Electron. Agric. 2020, 178, 105752. 2020.105752.
- Yandún Narváez, F.J.; Salvo del Pedregal, J.; Prieto, P.A.; Torres-Torriti, M.; Auat Cheein, F.A. LiDAR and thermal images fusion for ground-based 3D characterisation of fruit trees. Biosyst. Eng. 2016, 151, 479–494. 2016.10.012.
- Ooms, D.; Lebeau, F.; Ruter, R.; Destain, M.F. Measurements of the horizontal sprayer boom movements by sensor data fusion. Comput. Electron. Agric. 2002, 33, 139–162.
- Øvergaard, S.I.; Isaksson, T.; Korsaeth, A. Prediction of Wheat Yield and Protein Using Remote Sensors on Plots—Part II: Improving Prediction Ability Using Data Fusion. J. Infrared Spectrosc. 2013, 21, 133–140.
- Piikki, K.; Söderström, M.; Stenberg, B. Sensor data fusion for topsoil clay mapping. Geoderma 2013, 199, 106–116.
- Shalal, N.; Low, T.; McCarthy, C.; Hancock, N. Orchard mapping and mobile robot localisation using on-board camera and laser scanner data fusion—Part A: Tree detection. Comput. Electron. Agric. 2015, 119, 254–266.
- Tavares, T.R.; Molin, J.P.; Javadi, S.H.; Carvalho, H.W.P.D.; Mouazen, A.M. Combined Use of Vis-NIR and XRF Sensors for Tropical Soil Fertility Analysis: Assessing Different Data Fusion Approaches. Sensors 2021, 21, 148.
- Torres, A.B.; da Rocha, A.R.; Coelho da Silva, T.L.; de Souza, J.N.; Gondim, R.S. Multilevel data fusion for the internet of things in smart agriculture. Comput. Electron. Agric. 2020, 171, 105309.
- Wang, S.Q.; Li, W.D.; Li, J.; Liu, X.S. Prediction of soil texture using FT-NIR spectroscopy and PXRF spectrometry with data fusion. Soil Sci. 2013, 178, 626–638.
- Xu, H.; Xu, D.; Chen, S.; Ma, W.; Shi, Z. Rapid Determination of Soil Class Based on Visible-Near Infrared, Mid-Infrared Spectroscopy and Data Fusion. Remote Sens. 2020, 12, 1512.
- Zhang, J.; Guerrero, A.; Mouazen, A.M. Map-based variable-rate manure application in wheat using a data fusion approach. Soil Tillage Res. 2021, 207, 104846.
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. Robust Tomato Recognition for Robotic Harvesting Using Feature Images Fusion. Sensors 2016, 16, 173.
- Zhao,W.; Li, T.; Qi, B.; Nie, Q.; Runge, T. Terrain Analytics for Precision Agriculture with Automated Vehicle Sensors and Data Fusion. Sustainability 2021, 13, 2905.
- Zhou, C.; Liang, D.; Yang, X.; Xu, B.; Yang, G. Recognition of Wheat Spike from Field Based Phenotype Platform Using Multi-Sensor Fusion and Improved Maximum Entropy Segmentation Algorithms. Remote Sens. 2018, 10, 246.
- Babaeian, E.; Paheding, S.; Siddique, N.; Devabhaktuni, V.K.; Tuller, M. Estimation of root zone soil moisture from ground and remotely sensed soil information with multisensor data fusion and automated machine learning. Remote Sens. Environ. 2021, 260, 112434.
- Barrero, O.; Perdomo, S. RGB and multispectral UAV image fusion for Gramineae weed detection in rice fields. Precis. Agric. 2018, 19, 809–822.
- Maimaitijiang, M.; Ghulam, A.; Sidike, P.; Hartling, S.; Maimaitiyiming, M.; Peterson, K.; Shavers, E.; Fishman, J.; Peterson, J.; Kadam, S.; et al. Unmanned Aerial System (UAS)-based phenotyping of soybean using multi-sensor data fusion and extreme learning machine. ISPRS J. Photogramm. Remote Sens. 2017, 134, 43–58.
- Sankey, T.; McVay, J.; Swetnam, T.; McClaran, M.; Heilman, P.; Nichols, M. UAV hyperspectral and lidar data and their fusion for arid and semi-arid land vegetation monitoring. Remote Sens. Ecol. Conserv. 2018, 4, 20–33.
- Xiang, H.; Tian, L. Development of a low-cost agricultural remote sensing system based on an autonomous unmanned aerial vehicle (UAV). Biosyst. Eng. 2011, 108, 174–190.
- Yahia, O.; Guida, R.; Iervolino, P. NovelWeight-Based Approach for Soil Moisture Content Estimation via Synthetic Aperture Radar, Multispectral and Thermal Infrared Data Fusion. Sensors 2021, 21, 3457.
- Zhou, T.; Pan, J.; Zhang, P.;Wei, S.; Han, T. MappingWinter Wheat with Multi-Temporal SAR and Optical Images in an Urban Agricultural Region. Sensors 2017, 17, 1210.
- Gao, F.; Anderson, M.C.; Zhang, X.; Yang, Z.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25.
- Kimm, H.; Guan, K.; Jiang, C.; Peng, B.; Gentry, L.F.; Wilkin, S.C.; Wang, S.; Cai, Y.; Bernacchi, C.J.; Peng, J.; et al. Deriving high-spatiotemporal-resolution leaf area index for agroecosystems in the U.S. Corn Belt using Planet Labs CubeSat and STAIR fusion data. Remote Sens. Environ. 2020, 239, 111615.
- Shen, Y.; Shen, G.; Zhai, H.; Yang, C.; Qi, K. A Gaussian Kernel-Based Spatiotemporal Fusion Model for Agricultural Remote Sensing Monitoring. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3533–3545.
- Xu, C.; Qu, J.J.; Hao, X.; Cosh, M.H.; Zhu, Z.; Gutenberg, L. Monitoring crop water content for corn and soybean fields through data fusion of MODIS and Landsat measurements in Iowa. Agric. Water Manag. 2020, 227, 105844.
- Gao, F.; Hilker, T.; Zhu, X.; Anderson, M.; Masek, J.;Wang, P.; Yang, Y. Fusing Landsat and MODIS Data for Vegetation Monitoring. IEEE Geosci. Remote Sens. Mag. 2015, 3, 47–60.
- Tao, G.; Jia, K.;Wei, X.; Xia, M.;Wang, B.; Xie, X.; Jiang, B.; Yao, Y.; Zhang, X. Improving the spatiotemporal fusion accuracy of fractional vegetation cover in agricultural regions by combining vegetation growth models. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102362.
- Park, S.; Im, J.; Park, S.; Rhee, J. Drought monitoring using high resolution soil moisture through multi-sensor satellite data fusion over the Korean peninsula. Agric. For. Meteorol. 2017, 237–238, 257–269.
- Masiza,W.; Chirima, J.G.; Hamandawana, H.; Pillay, R. Enhanced mapping of a smallholder crop farming landscape through image fusion and model stacking. Int. J. Remote Sens. 2020, 41, 8739–8756.
- Gumma, M.K.; Thenkabail, P.S.; Hideto, F.; Nelson, A.; Dheeravath, V.; Busia, D.; Rala, A. Mapping Irrigated Areas of Ghana Using Fusion of 30 m and 250 m Resolution Remote-Sensing Data. Remote Sens. 2011, 3, 816–835.
- Kukunuri, A.N.J.; Murugan, D.; Singh, D. Variance based fusion of VCI and TCI for efficient classification of agriculture drought using MODIS data. Geocarto Int. 2020.
- Li, Y.; Huang, C.; Kustas, W.P.; Nieto, H.; Sun, L.; Hou, J. Evapotranspiration Partitioning at Field Scales Using TSEB and Multi-Satellite Data Fusion in The Middle Reaches of Heihe River Basin, Northwest China. Remote Sens. 2020, 12, 3223.
- De Oliveira, J.P.; Costa, M.G.F.; Filho, C. Methodology of Data Fusion Using Deep Learning for Semantic Segmentation of Land Types in the Amazon. IEEE Access 2020, 8, 187864–187875.
- Oliveira, D.; Martins, L.; Mora, A.; Damásio, C.; Caetano, M.; Fonseca, J.; Ribeiro, R.A. Data fusion approach for eucalyptus trees identification. Int. J. Remote Sens. 2021, 42, 4087–4109.
- Samourkasidis, A.; Athanasiadis, I.N. A semantic approach for timeseries data fusion. Comput. Electron. Agric. 2020, 169, 105171.
- Thomas, N.; Neigh, C.S.R.; Carroll, M.L.; McCarty, J.L.; Bunting, P. Fusion Approach for Remotely-Sensed Mapping of Agriculture (FARMA): A Scalable Open Source Method for Land Cover Monitoring Using Data Fusion. Remote Sens. 2020, 12, 3459.
- Useya, J.; Chen, S. Comparative Performance Evaluation of Pixel-Level and Decision-Level Data Fusion of Landsat 8 OLI, Landsat 7 ETM+ and Sentinel-2 MSI for Crop Ensemble Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4441–4451.
- Wang, P.; Gao, F.; Masek, J.G. Operational Data Fusion Framework for Building Frequent Landsat-Like Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7353–7365.
- Wang, L.;Wang, J.; Qin, F. Feature Fusion Approach for Temporal Land Use Mapping in Complex Agricultural Areas. Remote Sens. 2021, 13, 2517.
- Wu, M.; Wu, C.; Huang, W.; Niu, Z.; Wang, C. High-resolution Leaf Area Index estimation from synthetic Landsat data generated by a spatial and temporal data fusion model. Comput. Electron. Agric. 2015, 115, 1–11.
- Wu, M.; Yang, C.; Song, X.; Hoffmann, W.C.; Huang, W.; Niu, Z.; Wang, C.; Li, W.; Yu, B. Monitoring cotton root rot by synthetic Sentinel-2 NDVI time series using improved spatial and temporal data fusion. Sci. Rep. 2018, 8, 2016.
- Yang, Y.; Anderson, M.; Gao, F.; Hain, C.; Kustas, W.; Meyers, T.; Crow, W.; Finocchiaro, R.; Otkin, J.; Sun, L.; et al. Impact of Tile Drainage on Evapotranspiration in South Dakota, USA, Based on High Spatiotemporal Resolution Evapotranspiration Time Series From a Multisatellite Data Fusion System. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2550–2564.
- Yin, G.; Verger, A.; Qu, Y.; Zhao, W.; Xu, B.; Zeng, Y.; Liu, K.; Li, J.; Liu, Q. Retrieval of High Spatiotemporal Resolution Leaf Area Index with Gaussian Processes, Wireless Sensor Network, and Satellite Data Fusion. Remote Sens. 2019, 11, 244.
- Zhou, X.; Wang, P.; Tansey, K.; Zhang, S.; Li, H.; Tian, H. Reconstruction of time series leaf area index for improving wheat yield estimates at field scales by fusion of Sentinel-2, -3 and MODIS imagery. Comput. Electron. Agric. 2020, 177, 105692.
- Gao, F.; Hilker, T.; Zhu, X.; Anderson, M.; Masek, J.;Wang, P.; Yang, Y. Fusing Landsat and MODIS Data for Vegetation Monitoring. IEEE Geosci. Remote Sens. Mag. 2015, 3, 47–60.
More
Information
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.6K
Entry Collection:
Remote Sensing Data Fusion
Revisions:
2 times
(View History)
Update Date:
07 Apr 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No