Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Jingwen Dong | -- | 1595 | 2022-09-19 10:02:19 | | | |
| 2 | Beatrix Zheng | Meta information modification | 1595 | 2022-09-20 04:18:28 | | | | |
| 3 | Beatrix Zheng | Meta information modification | 1595 | 2022-09-20 04:27:01 | | | | |
| 4 | Beatrix Zheng | -15 word(s) | 1580 | 2022-09-20 04:31:28 | | | | |
| 5 | Beatrix Zheng | Meta information modification | 1580 | 2022-09-21 08:04:48 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Dong, J.; Rum, S.N.M.; Kasmiran, K.A.; Aris, T.N.M.; Mohamed, R. Artificial Intelligence in Adaptive and Intelligent Educational System. Encyclopedia. Available online: https://encyclopedia.pub/entry/27293 (accessed on 24 July 2026).
Dong J, Rum SNM, Kasmiran KA, Aris TNM, Mohamed R. Artificial Intelligence in Adaptive and Intelligent Educational System. Encyclopedia. Available at: https://encyclopedia.pub/entry/27293. Accessed July 24, 2026.
Dong, Jingwen, Siti Nurulain Mohd Rum, Khairul Azhar Kasmiran, Teh Noranis Mohd Aris, Raihani Mohamed. "Artificial Intelligence in Adaptive and Intelligent Educational System" Encyclopedia, https://encyclopedia.pub/entry/27293 (accessed July 24, 2026).
Dong, J., Rum, S.N.M., Kasmiran, K.A., Aris, T.N.M., & Mohamed, R. (2022, September 19). Artificial Intelligence in Adaptive and Intelligent Educational System. In Encyclopedia. https://encyclopedia.pub/entry/27293
Dong, Jingwen, et al. "Artificial Intelligence in Adaptive and Intelligent Educational System." Encyclopedia. Web. 19 September, 2022.
Copy Citation
There has been much discussion among academics on how pupils may be taught online while yet maintaining a high degree of learning efficiency, in part because of the worldwide COVID-19 pandemic in the previous two years. Students may have trouble focusing due to a lack of teacher–student interaction, yet online learning has some advantages that are unavailable in traditional classrooms. The architecture of online courses for students is integrated into a system called the Adaptive and Intelligent Education System (AIES). In AIESs, reinforcement learning is often used in conjunction with the development of teaching strategies, and this reinforcement-learning-based system is known as RLATES.
distanced learning
adaptive and intelligent education system
reinforcement learning
1. Reinforcement Learning
Reinforcement learning is a branch of machine learning, a parallel paradigm to supervised and unsupervised learning. Figure 1 clearly shows the machine learning paradigms.
Figure 1. Machine Learning paradigms.
Reinforcement learning generally consists of five elements [1], namely, agent, environment, action, reward, and state. In a reinforcement learning algorithm, two main elements interact, the agent and the environment. The agent can interact with the environment to generate actions, and the environment returns a reward based on the actions of the agent; then, the agent can perceive the state of the environment and perform the next action based on the reward received. Figure 2 better explains this process.
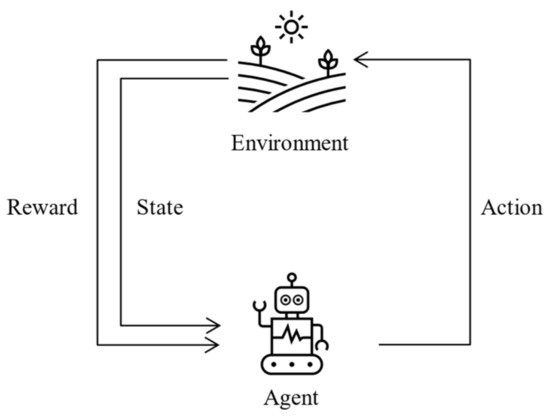
Figure 2. A typical framework of RL scenario.
2. Reinforcement Learning in Adaptive and Intelligent Educational System (RLATES)
Distance learning has attracted increasing attention in recent years. When students and teachers are unable to attend classes face to face in the same classroom, distance learning is essential. Sometimes, learning through resources on the web (text, video, pictures, voice, etc.) or online tutorials provided by teachers can fulfill the basic requirements of distance learning. However, when questions are encountered, students are unable to accurately find the answers through online resources, and the one-to-many teacher–student sessions ultimately do not fulfill one function, which is adaptive instructions [2]. The reason why one-to-one lessons are more effective and more satisfying than small group lessons is that one-to-one lessons allow for personalized teaching strategies, but because of the high financial cost of one-to-one lessons, it is impossible to extend this approach to all groups of students. Based on this situation, the Adaptive Intelligence Educational System was designed to allow students to develop their own personalized teaching strategies if they have access to a computer, thus allowing them to benefit from a one-to-one teaching model at a relatively low cost and allowing each student to have their own virtual teacher.
The principle of AIESs is to resequence all course knowledge modules based on student characteristics, and a variety of machine learning techniques are used in the system to learn student characteristics [3]. According to the principles of AIESs, if reinforcement learning is introduced into the system, it allows the student to interact with the system and allows the system model to continuously improve its learning, thus enhancing its performance. The type of system that introduces reinforcement learning into AIESs is called RLATES.
RLATES comprises two models, the knowledge model and the pedagogical strategy model [4]. In the knowledge model, the content of the teaching is decided, for example, which chapters of the textbook will be covered and which format (video, audio, text, or pictures) will be used for delivery. In the pedagogical strategy model, the teaching strategy is developed, which determines how the material will be delivered.
However, RLATES is not available for teaching directly from the beginning. At the early stage, the model needs to first be trained by feeding it with training data so that the system learns which teaching strategy to use when confronting students with different characteristics. Therefore, the whole experimental process should be separated into two phases when designing the system, the training phase and the teaching phase [5]. Only after the model has been successfully trained can it be implemented into real teaching.
2.1. Current Research
In this section, the current status of the research in the domain of intelligent educational systems is presented. Although there are numerous studies that focus on intelligent educational systems similar to AIESs, the retrieval shows that only a fraction of them adopted reinforcement learning algorithms. The details are shown in Table 1.
Table 1. Current research for intelligent tutoring system.
| No. | Author and Year | Algorithm | Assessment Metrics | Description |
|---|---|---|---|---|
| 1 | Dorça et al. [6] | Q-learning | Performance value (PFM)/distance between learning style (DLS) | Three different automated control strategies are proposed to detect and learn from students’ learning styles. |
| 2 | Iglesias et al. [5] | Q-learning | Number of actions/number of students | Apply the RL in AIESs with database design. |
| 3 | Iglesias et al. [4] | Q-learning | Time consumption/number of students | Apply the reinforcement learning algorithm in AIESs. |
| 4 | Shawky and Badawi [7] | Q-learning | Number of actions/number of steps/cumulative rewards | The system can update states and adding new states or actions automatically. |
| 5 | Thomaz and Breazeal [8] | Q-learning | Number of actions/state/trials | Modify the RL algorithm to separate guidance and feedback channel. |
| 6 | Bassen et al., 2020 [9] | PPO (Proximal Policy Optimization) |
Course completion rate/learning gains | Applied neural network to reduce number of samples required for the algorithm to converge. |
| 7 | Zhang, 2013 [10] | POMDP (Partially Observable Markov Decision Process) |
Rejection rate | The model provides local access to the information when selecting the correct answer to a student’s question. |
According to Table 1, it can be concluded that, in the domain of intelligent teaching systems, most authors still adopt the classical Q-learning algorithm since the Q-learning algorithm is a model-free and policy-free reinforcement learning algorithm that is suitable for implementation in intelligent teaching systems. However, due to the defects of Q-learning, the processing speed is sluggish, and the system response time increases when the Q-table is excessively large. Nonetheless, the Q-learning algorithm is one of the classical algorithms of reinforcement learning and is relatively simple in practical applications compared with other model-free reinforcement learning algorithms, which is probably part of the reason why many authors chose the Q-learning algorithm in their studies.
For the articles listed above, although articles 1–5 all adopt the Q-learning algorithm, their evaluation metrics are distinct. Most of the authors selected the number of actions, the number of students, or time consumption to evaluate the performance of the model. However, the most remarkable article is article 1, in which the authors develop an evaluation metric themselves called PFM. According to the authors’ settings in that article, if PFM ≥ 60, then the performance of the model is good, and if PFM < 60, then the performance of the model is poor. Meanwhile, an assessment using PFM can also indicate the difficulty of the learning content to some extent; if the performance is poor, then this indicates that the learning content is probably relatively difficult. The authors use this evaluation metric to compare the three strategies within the article, and although it does not permit a horizontal comparison of the model’s performance to other articles, it makes the evaluation results more intuitive and straightforward to peruse and understand.
2.2. Applied Reinforcement Learning in RLATES
Based on the introduction to reinforcement learning, it can be seen that reinforcement learning comprises five main components. In order to apply reinforcement learning to RLATES, it is essential to ensure that the components of the system correspond to each of the five components of reinforcement learning algorithms. Therefore, in this section, the application of reinforcement learning to RLATES is introduced.
First, the following descriptions are given of how the components of RLATES correspond to those of the reinforcement learning algorithm [5]:
-
Agent: In RLATES, the agent refers to the student. The learning system is used through the student interacting with the system for subsequent processes; therefore, the student corresponds to the agent in the reinforcement learning algorithm.
-
Environment: In a broad sense, the environment is the entire knowledge structure of the system, and it collects information on the characteristics of the students and tests their knowledge through exams and quizzes distributed throughout the knowledge modules.
-
Action: Actions are the selections that an agent needs to take at each step, so in RLATES, the actions correspond to the knowledge modules, each of which represents an action.
-
State: In reinforcement learning algorithms, the state refers to the state that the environment returns to when the agent performs an action. Therefore, in RLATES, the state corresponds to the student’s learning state, i.e., how the student mastered the knowledge. Here, a vector is used to store the data, and all state values are in the range of 0–1. For a student, if the knowledge has been fully mastered and correctly understood, the state value is set at 1. If the knowledge has not been mastered by the student, then the state value is set at 0.
-
Reward: For reinforcement learning algorithms, each selection returns a different reward value, and similarly, in RLATES, each knowledge module corresponds to a different reward according to the significance. Moreover, in RLATES, the intention is to maximize the cumulative value of this reward.
Next, the application of the reinforcement learning algorithm to RLATES is described in Algorithm 1. Coupling the components in RLATES to the elements in the reinforcement learning algorithm yields the following process [4][5]:
| Algorithm 1 Apply reinforcement learning algorithm to RLATES |
| Initialize Q (s, a) for s ∈ S and a ∈ A Test the current situation of student’s knowledge s Loop for each episode, Pick a knowledge module a, show this module to the student, by using the ε-greedy policy Get the reward r, while the RLATES goal is achieved, a positive r will be obtained, else a null r will be obtained. Test the current situation of student’s knowledge s’ Update Q (s, a): s ← s’ until s reaches the goal state |
References
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285.
- Mousavinasab, E.; Zarifsanaiey, N.; Niakan Kalhori, S.R.; Rakhshan, M.; Keikha, L.; Ghazi Saeedi, M. Intelligent tutoring systems: A systematic review of characteristics, applications, and evaluation methods. Interact. Learn. Environ. 2021, 29, 142–163.
- Suebnukarn, S. Intelligent Tutoring System for Clinical Reasoning Skill Acquisition in Dental Students. J. Dent. Educ. 2009, 73, 1178–1186.
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Reinforcement learning of pedagogical policies in adaptive and intelligent educational systems. Knowl.-Based Syst. 2009, 22, 266–270.
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Learning teaching strategies in an Adaptive and Intelligent Educational System through Reinforcement Learning. Appl. Intell. 2009, 31, 89–106.
- Dorça, F.A.; Lima, L.V.; Fernandes, M.A.; Lopes, C.R. Comparing strategies for modeling students learning styles through reinforcement learning in adaptive and intelligent educational systems: An experimental analysis. Expert Syst. Appl. 2013, 40, 2092–2101.
- Shawky, D.; Badawi, A. Towards a Personalized Learning Experience Using Reinforcement Learning. In Machine Learning Paradigms: Theory and Application; Studies in Computational Intelligence; Hassanien, A.E., Ed.; Springer International Publishing: Cham, Switzerland, 2019; Volume 801, pp. 169–187. ISBN 978-3-030-02356-0.
- Thomaz, A.L.; Breazeal, C. Reinforcement learning with human teachers: Evidence of feedback and guidance with implications for learning performance. In Proceedings of the AAAI; American Association for Artificial Intelligence: Boston, MA, USA, 2006; Volume 6, pp. 1000–1005.
- Bassen, J.; Balaji, B.; Schaarschmidt, M.; Thille, C.; Painter, J.; Zimmaro, D.; Games, A.; Fast, E.; Mitchell, J.C. Reinforcement Learning for the Adaptive Scheduling of Educational Activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; ACM: Honolulu, HI, USA, 2020; pp. 1–12.
- Zhang, P. Using POMDP-based Reinforcement Learning for Online Optimization of Teaching Strategies in an Intelligent Tutoring System. Ph.D. Thesis, University of Guelph, Guelph, ON, Canada, 2013.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.4K
Entry Collection:
COVID-19
Revisions:
5 times
(View History)
Update Date:
21 Sep 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No