There has been much discussion among academics on how pupils may be taught online while yet maintaining a high degree of learning efficiency, in part because of the worldwide COVID-19 pandemic in the previous two years. Students may have trouble focusing due to a lack of teacher–student interaction, yet online learning has some advantages that are unavailable in traditional classrooms. The architecture of online courses for students is integrated into a system called the Adaptive and Intelligent Education System (AIES). In AIESs, reinforcement learning is often used in conjunction with the development of teaching strategies, and this reinforcement-learning-based system is known as RLATES.
- distanced learning
- adaptive and intelligent education system
- reinforcement learning
1. Reinforcement Learning
2. Reinforcement Learning in Adaptive and Intelligent Educational System (RLATES)
2.1. Current Research
| No. | Author and Year | Algorithm | Assessment Metrics | Description |
|---|---|---|---|---|
| 1 | Dorça et al. [6] | Q-learning | Performance value (PFM)/distance between learning style (DLS) | Three different automated control strategies are proposed to detect and learn from students’ learning styles. |
| 2 | Iglesias et al. [5] | Q-learning | Number of actions/number of students | Apply the RL in AIESs with database design. |
| 3 | Iglesias et al. [4] | Q-learning | Time consumption/number of students | Apply the reinforcement learning algorithm in AIESs. |
| 4 | Shawky and Badawi [7] | Q-learning | Number of actions/number of steps/cumulative rewards | The system can update states and adding new states or actions automatically. |
| 5 | Thomaz and Breazeal [8] | Q-learning | Number of actions/state/trials | Modify the RL algorithm to separate guidance and feedback channel. |
| 6 | Bassen et al., 2020 [9] | PPO (Proximal Policy Optimization) |
Course completion rate/learning gains | Applied neural network to reduce number of samples required for the algorithm to converge. |
| 7 | Zhang, 2013 [10] | POMDP (Partially Observable Markov Decision Process) |
Rejection rate | The model provides local access to the information when selecting the correct answer to a student’s question. |
2.2. Applied Reinforcement Learning in RLATES
-
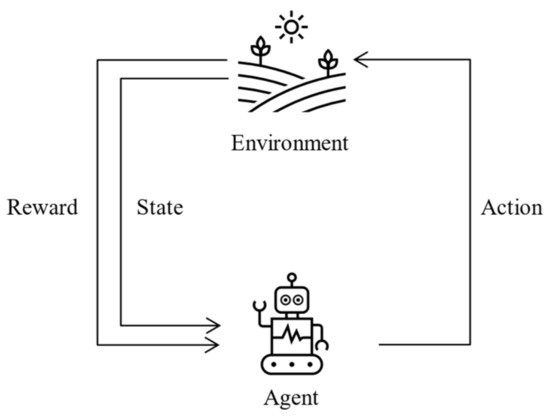
Agent: In RLATES, the agent refers to the student. The learning system is used through the student interacting with the system for subsequent processes; therefore, the student corresponds to the agent in the reinforcement learning algorithm.
-
Environment: In a broad sense, the environment is the entire knowledge structure of the system, and it collects information on the characteristics of the students and tests their knowledge through exams and quizzes distributed throughout the knowledge modules.
-
Action: Actions are the selections that an agent needs to take at each step, so in RLATES, the actions correspond to the knowledge modules, each of which represents an action.
-
State: In reinforcement learning algorithms, the state refers to the state that the environment returns to when the agent performs an action. Therefore, in RLATES, the state corresponds to the student’s learning state, i.e., how the student mastered the knowledge. Here, a vector is used to store the data, and all state values are in the range of 0–1. For a student, if the knowledge has been fully mastered and correctly understood, the state value is set at 1. If the knowledge has not been mastered by the student, then the state value is set at 0.
-
Reward: For reinforcement learning algorithms, each selection returns a different reward value, and similarly, in RLATES, each knowledge module corresponds to a different reward according to the significance. Moreover, in RLATES, the intention is to maximize the cumulative value of this reward.
| Algorithm 1 Apply reinforcement learning algorithm to RLATES |
| Initialize Q (s, a) for s ∈ S and a ∈ A Test the current situation of student’s knowledge s Loop for each episode, Pick a knowledge module a, show this module to the student, by using the ε-greedy policy Get the reward r, while the RLATES goal is achieved, a positive r will be obtained, else a null r will be obtained. Test the current situation of student’s knowledge s’ Update Q (s, a): s ← s’ until s reaches the goal state |
This entry is adapted from the peer-reviewed paper 10.3390/fi14090245
References
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285.
- Mousavinasab, E.; Zarifsanaiey, N.; Niakan Kalhori, S.R.; Rakhshan, M.; Keikha, L.; Ghazi Saeedi, M. Intelligent tutoring systems: A systematic review of characteristics, applications, and evaluation methods. Interact. Learn. Environ. 2021, 29, 142–163.
- Suebnukarn, S. Intelligent Tutoring System for Clinical Reasoning Skill Acquisition in Dental Students. J. Dent. Educ. 2009, 73, 1178–1186.
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Reinforcement learning of pedagogical policies in adaptive and intelligent educational systems. Knowl.-Based Syst. 2009, 22, 266–270.
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Learning teaching strategies in an Adaptive and Intelligent Educational System through Reinforcement Learning. Appl. Intell. 2009, 31, 89–106.
- Dorça, F.A.; Lima, L.V.; Fernandes, M.A.; Lopes, C.R. Comparing strategies for modeling students learning styles through reinforcement learning in adaptive and intelligent educational systems: An experimental analysis. Expert Syst. Appl. 2013, 40, 2092–2101.
- Shawky, D.; Badawi, A. Towards a Personalized Learning Experience Using Reinforcement Learning. In Machine Learning Paradigms: Theory and Application; Studies in Computational Intelligence; Hassanien, A.E., Ed.; Springer International Publishing: Cham, Switzerland, 2019; Volume 801, pp. 169–187. ISBN 978-3-030-02356-0.
- Thomaz, A.L.; Breazeal, C. Reinforcement learning with human teachers: Evidence of feedback and guidance with implications for learning performance. In Proceedings of the AAAI; American Association for Artificial Intelligence: Boston, MA, USA, 2006; Volume 6, pp. 1000–1005.
- Bassen, J.; Balaji, B.; Schaarschmidt, M.; Thille, C.; Painter, J.; Zimmaro, D.; Games, A.; Fast, E.; Mitchell, J.C. Reinforcement Learning for the Adaptive Scheduling of Educational Activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; ACM: Honolulu, HI, USA, 2020; pp. 1–12.
- Zhang, P. Using POMDP-based Reinforcement Learning for Online Optimization of Teaching Strategies in an Intelligent Tutoring System. Ph.D. Thesis, University of Guelph, Guelph, ON, Canada, 2013.