Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Cătălin - Daniel Căleanu | -- | 2066 | 2022-09-14 11:18:19 | | | |
| 2 | Rita Xu | Meta information modification | 2066 | 2022-09-14 11:59:05 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Orășan, I.L.; Seiculescu, C.; Căleanu, C.D. Deep Neural Network Implementations. Encyclopedia. Available online: https://encyclopedia.pub/entry/27163 (accessed on 25 July 2026).
Orășan IL, Seiculescu C, Căleanu CD. Deep Neural Network Implementations. Encyclopedia. Available at: https://encyclopedia.pub/entry/27163. Accessed July 25, 2026.
Orășan, Ioan Lucan, Ciprian Seiculescu, Cătălin Daniel Căleanu. "Deep Neural Network Implementations" Encyclopedia, https://encyclopedia.pub/entry/27163 (accessed July 25, 2026).
Orășan, I.L., Seiculescu, C., & Căleanu, C.D. (2022, September 14). Deep Neural Network Implementations. In Encyclopedia. https://encyclopedia.pub/entry/27163
Orășan, Ioan Lucan, et al. "Deep Neural Network Implementations." Encyclopedia. Web. 14 September, 2022.
Copy Citation
Deep neural networks have recently become increasingly used for a wide range of applications, (e.g., image and video processing). The demand for edge inference is growing, especially in the areas of relevance to the Internet-of-Things. Low-cost microcontrollers as edge devices are a promising solution for optimal application systems from several points of view such as: cost, power consumption, latency, or real-time execution. The implementation of these systems has become feasible due to the advanced development of hardware architectures and DSP capabilities, while the cost and power consumption have been maintained at a low level.
deep neural networks
edge computing
microcontrollers
ARM Cortex-M
1. Introduction
In recent years, a variety of different applications, such as face, speech, images or handwriting recognition, natural language processing, and automatic medical diagnostics, have demonstrated outstanding performance by applying Deep Learning (DL) techniques [1]. To further improve application performance and add additional features, complex Deep Neural Networks (DNN) designs are currently being studied. However, this results in increasingly high computational requirements. To satisfy these requirements, integrated circuit manufacturers have focused on increasing the number of available cores, the working frequencies of processing cores and memory systems, and the specialized hardware circuits. Lately specialized hardware accelerators paired with high bandwidth memory systems is the preferred architecture to manage the high computational demands at manageable power levels. Apart from these mainstream applications, a new class of systems is trying to take advantage of DNN algorithms to solve various tasks. These applications come from the field of smart sensors and devices. Unlike mainstream applications, these have lower complexity but, at the same time, require very low power consumption, as most of these systems have to operate on batteries for long periods of time. Some of these applications can even be implemented on low-cost, low-power microcontrollers such as the ones built around the ARM Cortex-M core.
The ARM Cortex-M core-based architecture is already present in the focus of researchers because of the tooling and firmware support provided by the manufacturers that are very helpful, especially to reduce the development effort, time, and cost. A recent systematic review for tiny machine learning existing research [2] has shown that STM32 microcontrollers and ARM Cortex-M series represent the top of hardware devices used in the field.
2. From Cloud to Edge Computing
Usually, DL models require high computational power and substantial available memory, especially if researchers refer to State-Of-The-Art (SOTA) models. For this reason, some applications based on DL models use cloud computing services, e.g., Google Colaboratory [3], which is a free cloud service hosted by Google. There are also other popular services such as AWS Deep Learning AMIs [4], the Microsoft MLOps solution for accelerated training, deployment, and management of the deep learning projects, and Azure [5]. At the same time, using a cloud computing approach has some significant drawbacks. On the one hand, in a classical cloud computing paradigm, a large number of computational tasks are executed in the cloud. Therefore, traffic overload of the network may cause unacceptable delays in some real-time scenarios [6]. On the other hand, real-time inference is an important consideration, especially for latency-sensitive applications such as autonomous driving. In this case, a cloud computing approach can introduce significant latencies. In addition, there are concerns about whether data transmission to the cloud can usually be performed in a sufficiently secure manner. For these reasons, on-device computing is a new trend that brings deep learning models computation directly to the source of data, rather than transmitting the data to remote devices with high computational capabilities. This approach is generally found under the name of edge computing [7]. The relevant DL applications for edge computing are present in several fields such as smart multimedia, smart transportation, smart cities, and smart industry [8].
This migration from cloud computing to edge computing also comes with certain constraints or limitations that must be considered when developing a DL architecture for a certain task. This is due to computational limitations that are inherent when considering edge computing using resource-constrained low-power embedded devices. To mitigate this problem, two approaches are commonly used: (1) different compression methods are applied to existing DL models and (2) the architecture itself must be optimized directly from the design stage [9].
Considering the first approach, to run a DL model on embedded devices, one or more compression algorithms must be applied. Examples of the most common compression algorithms are: quantization of the model parameters [10], neural network pruning [11], network distillation [12], and binarization [13].
For the second approach, the basic idea is to obtain an optimized architecture that after the training process does not require the use of compression methods. SqueezeNet architecture made a significant contribution in this direction [14]. The main purpose of this architecture is to obtain a small number of parameters with minimal impact on accuracy.
It is important to note that the embedded devices are suitable only for the inference task, which is much less expensive in terms of computational resources compared to the training process. Among these embedded devices are also general-purpose microcontrollers that have been used with high efficiency in various fields, such as IoT applications [15].
2.1. Embedded Hardware for Deep Learning
In the last decade, computational constraints have become easier to cope with due to the introduction of specialized hardware devices on the market, at an accelerated pace [16]. These hardware devices that are found in the context of DL are usually called hardware accelerators. They are optimized and specialized hardware architectures that can reduce system cost and power consumption by optimizing the necessary resources while improving performance [17]. For instance, common implementations of hardware accelerators are based on the use of FPGAs, GPUs, ASICs [18], or Tensor Processing Units (TPUs) developed by Google [19]. The embedded system used to implement deep learning applications must have high processing capacity, as well as be able to acquire and process data in real time. At the same time, the processor must have enough memory to store the model data and the parameters.
System-On-Chip (SoC) devices are an attractive solution that, in addition to high processing capabilities, includes multiple peripheral devices that can be very helpful for the sophisticated requirements of deep-learning applications. Examples of manufacturers that develop AI integrated circuits for edge computing are Samsung, Texas Instruments, Qualcomm, and STM. Some of their recent products are briefly presented below.
The Maxim Integrated MAX78000 ultra-low power microcontroller is a relatively new device specially designed for edge Artificial Intelligence (AI) applications. Integrates a dedicated Convolutional Neural Network (CNN) accelerator along with a low-power ARM Cortex-M4 core and a RISC-V core [20]. Low power AI applications can be developed using this architecture, because it provides a variety of configuration options such as different oscillators, clock sources, or operation modes. One of the main advantages of this device is that it combines an energy-efficient AI processing unit with Maxim Integrated’s proven ultra-low power microcontrollers. It is suitable for battery-powered applications. The architecture is briefly presented in Figure 1, which summarizes the main features of the CNN accelerator and the microcontroller, such as cores, memory footprint, and external interfaces. The microcontroller has a dual core architecture: an ARM Cortex-M4 Processor with FPU running at clock frequencies of up to 100 MHz and a 32-Bit RISC-V Coprocessor running up to 60 MHz. To demonstrate the performance of this device, two applications were used: Keywords Spotting [21] and Face Identification [22]. The accuracy results are quite promising, 99.6% for keywords spotting and 94.4% for face identification.

Figure 1. The architecture of MAX78000.
STMicroelectronics is another example of a manufacturer that has made important contributions to the market to support AI edge computing as a new paradigm for IoT. These contributions were aimed at running neural networks on STM32 general purpose microcontrollers, with a significant impact on the productivity of edge AI system developers by reducing application deployment time. In this case, the focus is not on hardware accelerators, but on an extensive software toolchain designed to port DNN models to standard STM32 microcontrollers with high efficiency for the ARM Cortex-M4 and M7 processor core. The STM32CubeMX.AI framework will be detailed in the next section. A similar solution is also developed for SPC5 automotive microcontrollers. In this case an AI plug-in called SPC5-STUDIO-AI of the SPC5-STUDIO development environment is used.
A Parallel-Ultralow Power (PULP) SoC architecture has been developed [23] in order to achieve peak performance for the new generation of IoT applications, which have higher computing power requirements, up to giga operations per second (GOp/s), and a memory footprint of up to a few MB. However, to be competitive for IoT applications, the power consumption budged had to be maintained at levels similar to those of existing solutions such as ARM Cortex-M microcontrollers. Named Mr. Wolf [23], the device is a fully programmable SoC for IoT edge computing. It contains a RISC-V general purpose processor and a parallel computing cluster. The RISC-V processor was designed to handle the connectivity tasks and manage the I/O peripherals for the system integration with the outside world. This accelerator was designed to handle computationally intensive tasks. It consists of eight customized RISC-V cores, with DSP capabilities and other extensions such as Single Instruction Multiple Data (SIMD) or bit manipulations instructions. Mr. Wolf SoC has already been used in several applications such as tactile data decoding [24], electromyographic gesture recognition [25], stress detection using a wearable multisensor bracelet [26], electroencephalography signals classification for brain–machine interfaces [27]. The results showed that Mr. Wolf exceeds the performance of ARM Cortex-M processors, while maintaining low power consumption.
Other SoCs also have optimization and embedding solutions. For instance, a 16 nm SoC [28] was recently developed with dedicated optimizations for automatic speech recognition real-life applications. Another example is the TI TDAx series of boards [29].
2.2. Deep Learning Frameworks and Tools for Embedded Implementation
Firmware support for microcontrollers has seen accelerated development in recent years. Some examples of firmware and framework solutions are: CMSIS-NN released by ARM in 2018 which is an open source library consisting of efficient kernels developed to maximize Neural Network (NN) performance on ARM Cortex-M processors [30], TensorFlow Lite Micro which is an open source Machine Learning framework to enable DL models on embedded systems [31], STM X-CUBE-AI expansion package providing capabilities of automatic conversion of a pretrained Neural Network for 32 bit microcontrollers [32], MicroTensor (µTensor) which is a lightweight Machine Learning (ML) framework used for TensorFlow models and optimized for ARM cores [33], and PyTorch Mobile to execute ML models on edge devices using the PyTorch ecosystem [34].
CMSIS-NN was developed to help build IoT applications that run small neural networks directly on the systems that collect the data. This approach is preferred over cloud computing, as the number of IoT nodes is increasing. This leads to bandwidth limitations, as well as increasing latencies. The utility of this library has been demonstrated using a CNN designed for image classification task on the CIFAR-10 dataset. An ARM Cortex-M7 platform was used for the demonstration, obtaining a classification of 10.1 images per second with an accuracy of 79.9% [30][35].
With the multitude of available embedded platforms, with different hardware support, converting and optimizing an inference model to run on such a device is a very difficult task. TensorFlow Lite Micro was designed to address this situation and provide a unified ML framework. Covers these shortcomings with a flexible ML framework for embedded devices. In summary, this is an interpreter-based approach where hardware vendors have the possibility to provide platform-specific optimizations; it can be easily adapted to new applications and official benchmark solutions are supported.
X-CUBE-AI is a package that extends the capabilities of STM32CubeMX.AI. It adds the possibility to convert a pre-trained NN into an ANSI C library that is performance optimized for STM32 microcontrollers based on ARM Cortex-M4 and M7 processor cores. The generated ANSI C source files are then compiled to run inference on the microcontroller. The generation process using this framework is depicted in Figure 2. In fact, CMSIS-NN kernels are used at a low level, but using this tool has a series of advantages for the developers such as: a graphical user interface, support for different DL frameworks such as Keras and TensorFlow Lite, 8-bit-quantization, and compatibility with different STM32 microcontroller series.
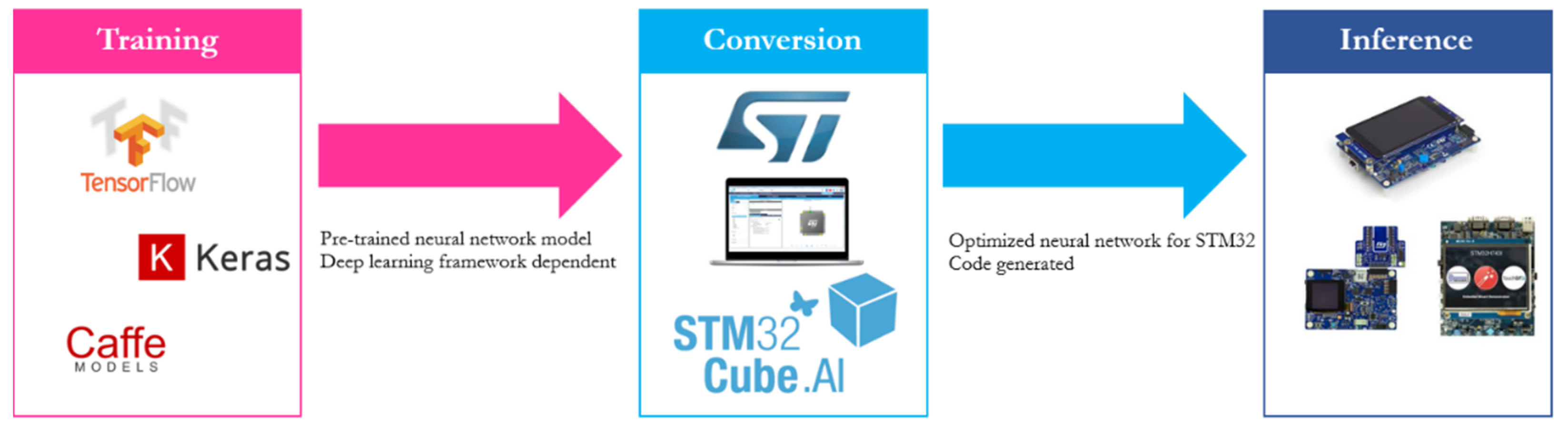
Figure 2. Conversion of a pre-trained model using STM32CubeMX.AI.
µTensor is a framework that converts a model built and trained with TensorFlow into a microcontroller-optimized C++ code. Its structure consists of a runtime library and an offline tool that make this conversion possible. The resulting C++ source files can be compiled to obtain an efficient and optimized inference engine that can run on ARM microcontrollers.
References
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092.
- Han, H.; Siebert, J. TinyML: A Systematic Review and Synthesis of Existing Research. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 21–24 February 2022; pp. 269–274.
- Carneiro, T.; da Nobrega, R.V.M.; Nepomuceno, T.; Bian, G.B.; de Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685.
- Jackovich, J.; Richards, R. Machine Learning with AWS: Explore the Power of Cloud Services for Your Machine Learning and Artificial Intelligence Projects; Packt Publishing: Birmingham, UK, 2018.
- Salvaris, M.; Dean, D.; Tok, W.H. Deep Learning with Azure: Building and Deploying Artificial Intelligence Solutions on the Microsoft AI Platform, 1st ed.; Apress Imprint: Berkeley, CA, USA, 2018.
- Han, Y.; Wang, X.; Leung, V.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. arXiv 2019, arXiv:1907.08349.
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646.
- Wang, F.; Zhang, M.; Wang, X.; Ma, X.; Liu, J. Deep learning for edge computing applications: A state-of-the-art survey. IEEE Access 2020, 8, 58322–58336.
- Berthelier, A.; Chateau, T.; Duffner, S.; Garcia, C.; Blanc, C. Deep Model Compression and Architecture Optimization for Embedded Systems: A Survey. J. Signal Process. Syst. 2020, 93, 863–878.
- Benoit, J.; Skirmantas, K.; Chen, B.; Zhu, M.; Tang, M.; Andrew, G.H.; Hartwig, A.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713.
- Blalock, D.; Ortiz, J.J.G.; Frankle, J.; Guttag, J. What is the state of neural network pruning? arXiv 2020, arXiv:2003.03033.
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531.
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830.
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360.
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for AI-enabled IoT devices?: A review. Sensors 2020, 20, 2533.
- Thompson, C.N.; Greenewald, K.; Lee, K.; Manso, F.G. The Computational Limits of Deep Learning. arXiv 2020, arXiv:2007.05558.
- Misra, J.; Saha, I. Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255.
- Talib, M.A.; Majzoub, S.; Nasir, Q.; Jamal, D. A systematic literature review on hardware implementation of artificial intelligence algorithms. J. Supercomput. 2020, 77, 1897–1938.
- Jouppi, N.; Young, C.; Patil, N.; Patterson, D. Motivation for and evaluation of the first tensor processing unit. IEEE Micro 2018, 38, 10–19.
- Maxim Integrated. Application Note 7417: Developing Power-Optimized Applications on the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7417.html (accessed on 31 May 2021).
- Maxim Integrated. Application Note 7359: Keywords Spotting Using the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7359.html (accessed on 31 May 2021).
- Maxim Integrated. Application Note 7364: Face Identification Using the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7364.html (accessed on 31 May 2021).
- Pullini, A.; Rossi, D.; Loi, I.; Tagliavini, G.; Benini, L. Mr.Wolf: An Energy-Precision Scalable Parallel Ultra Low Power SoC for IoT Edge Processing. IEEE J. Solid-State Circuits 2019, 54, 1970–1981.
- Osta, M.; Ibrahim, A.; Magno, M.; Eggimann, M.; Pullini, A.; Gastaldo, P.; Valle, M. An energy efficient system for touch modality classification in electronic skin applications. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–4.
- Benatti, S.; Montagna, F.; Kartsch, V.; Rahimi, A.; Rossi, D.; Benini, L. Online Learning and Classification of EMG-Based Gestures on a Parallel Ultra-Low Power Platform Using Hyperdimensional Computing. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 516–528.
- Magno, M.; Wang, X.; Eggimann, M.; Cavigelli, L.; Benini, L. InfiniWolf: Energy efficient smart bracelet for edge computing with dual source energy harvesting. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 342–345.
- Schneider, T.; Wang, X.; Hersche, M.; Cavigelli, L.; Benini, L. Q-EEGNet: An energy-efficient 8-bit quantized parallel EEGNet implementation for edge motor-imagery brain-machine interfaces. In Proceedings of the IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 284–289.
- Tambe, T.; Yang, E.-Y.; Ko, G.G.; Chai, Y.; Hooper, C.; Donato, M.; Whatmough, P.N.; Rush, A.M.; Brooks, D.; Wei, G.-Y. 9.8 A 25mm2 SoC for IoT devices with 18ms noise-robust speech-to-text latency via bayesian speech denoising and attention-based sequence-to-sequence DNN speech recognition in 16 nm FinFET. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; pp. 158–160.
- Texas Instruments. Embedded Low-Power Deep Learning with TIDL. Available online: https://www.ti.com/lit/wp/spry314/spry314.pdf (accessed on 31 May 2021).
- Lai, L.; Suda, N.; Chandra, V. CMSIS-NN: Efficient neural network kernels for arm cortex-m cpus. arXiv 2018, arXiv:1801.06601.
- David, R.; Duke, J.; Jain, A.; Reddi, V.J.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Regev, S.; et al. TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems. arXiv 2020, arXiv:2010.08678.
- Falbo, V.; Apicella, T.; Aurioso, D.; Danese, L.; Bellotti, F.; Berta, R.; De Gloria, A. Analyzing machine learning on mainstream microcontrollers. In Proceedings of the International Conference on Applications Electronics Pervading Industry, Environment and Society, Pisa, Italy, 19–20 November 2019; Springer: Cham, Switzerland, 2020; pp. 103–108. Available online: https://link.springer.com/chapter/10.1007/978-3-030-37277-4_12 (accessed on 29 November 2021).
- uTensor. TinyML AI Inference Library. Available online: https://github.com/uTensor/uTensor (accessed on 31 May 2021).
- Pytorch Mobile. End-to-End Workflow from Training to Deployment for iOS and Android Mobile Devices. Available online: https://pytorch.org/mobile/home/ (accessed on 31 May 2021).
- Orășan, I.L.; Căleanu, C.D. ARM embedded low cost solution for implementing deep learning paradigms. In Proceedings of the International Symposium on Electronics and Telecommunications (ISETC), Timișoara, Romania, 5–6 November 2020; pp. 1–4.
More
Information
Subjects:
Engineering, Electrical & Electronic
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
861
Revisions:
2 times
(View History)
Update Date:
14 Sep 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No