Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Cătălin - Daniel Căleanu and Version 2 by Rita Xu.
Deep neural networks have recently become increasingly used for a wide range of applications, (e.g., image and video processing). The demand for edge inference is growing, especially in the areas of relevance to the Internet-of-Things. Low-cost microcontrollers as edge devices are a promising solution for optimal application systems from several points of view such as: cost, power consumption, latency, or real-time execution. The implementation of these systems has become feasible due to the advanced development of hardware architectures and DSP capabilities, while the cost and power consumption have been maintained at a low level.
- deep neural networks
- edge computing
- microcontrollers
- ARM Cortex-M
1. Introduction
In recent years, a variety of different applications, such as face, speech, images or handwriting recognition, natural language processing, and automatic medical diagnostics, have demonstrated outstanding performance by applying Deep Learning (DL) techniques [1]. To further improve application performance and add additional features, complex Deep Neural Networks (DNN) designs are currently being studied. However, this results in increasingly high computational requirements. To satisfy these requirements, integrated circuit manufacturers have focused on increasing the number of available cores, the working frequencies of processing cores and memory systems, and the specialized hardware circuits. Lately specialized hardware accelerators paired with high bandwidth memory systems is the preferred architecture to manage the high computational demands at manageable power levels. Apart from these mainstream applications, a new class of systems is trying to take advantage of DNN algorithms to solve various tasks. These applications come from the field of smart sensors and devices. Unlike mainstream applications, these have lower complexity but, at the same time, require very low power consumption, as most of these systems have to operate on batteries for long periods of time. Some of these applications can even be implemented on low-cost, low-power microcontrollers such as the ones built around the ARM Cortex-M core.
The ARM Cortex-M core-based architecture is already present in the focus of researchers because of the tooling and firmware support provided by the manufacturers that are very helpful, especially to reduce the development effort, time, and cost. A recent systematic review for tiny machine learning existing research [2] has shown that STM32 microcontrollers and ARM Cortex-M series represent the top of hardware devices used in the field.
2. From Cloud to Edge Computing
Usually, DL models require high computational power and substantial available memory, especially if rwesearchers refer to State-Of-The-Art (SOTA) models. For this reason, some applications based on DL models use cloud computing services, e.g., Google Colaboratory [3], which is a free cloud service hosted by Google. There are also other popular services such as AWS Deep Learning AMIs [4], the Microsoft MLOps solution for accelerated training, deployment, and management of the deep learning projects, and Azure [5]. At the same time, using a cloud computing approach has some significant drawbacks. On the one hand, in a classical cloud computing paradigm, a large number of computational tasks are executed in the cloud. Therefore, traffic overload of the network may cause unacceptable delays in some real-time scenarios [6]. On the other hand, real-time inference is an important consideration, especially for latency-sensitive applications such as autonomous driving. In this case, a cloud computing approach can introduce significant latencies. In addition, there are concerns about whether data transmission to the cloud can usually be performed in a sufficiently secure manner. For these reasons, on-device computing is a new trend that brings deep learning models computation directly to the source of data, rather than transmitting the data to remote devices with high computational capabilities. This approach is generally found under the name of edge computing [7]. The relevant DL applications for edge computing are present in several fields such as smart multimedia, smart transportation, smart cities, and smart industry [8]. This migration from cloud computing to edge computing also comes with certain constraints or limitations that must be considered when developing a DL architecture for a certain task. This is due to computational limitations that are inherent when considering edge computing using resource-constrained low-power embedded devices. To mitigate this problem, two approaches are commonly used: (1) different compression methods are applied to existing DL models and (2) the architecture itself must be optimized directly from the design stage [9]. Considering the first approach, to run a DL model on embedded devices, one or more compression algorithms must be applied. Examples of the most common compression algorithms are: quantization of the model parameters [10], neural network pruning [11], network distillation [12], and binarization [13]. For the second approach, the basic idea is to obtain an optimized architecture that after the training process does not require the use of compression methods. SqueezeNet architecture made a significant contribution in this direction [14]. The main purpose of this architecture is to obtain a small number of parameters with minimal impact on accuracy. It is important to note that the embedded devices are suitable only for the inference task, which is much less expensive in terms of computational resources compared to the training process. Among these embedded devices are also general-purpose microcontrollers that have been used with high efficiency in various fields, such as IoT applications [15].2.1. Embedded Hardware for Deep Learning
In the last decade, computational constraints have become easier to cope with due to the introduction of specialized hardware devices on the market, at an accelerated pace [16]. These hardware devices that are found in the context of DL are usually called hardware accelerators. They are optimized and specialized hardware architectures that can reduce system cost and power consumption by optimizing the necessary resources while improving performance [17]. For instance, common implementations of hardware accelerators are based on the use of FPGAs, GPUs, ASICs [18], or Tensor Processing Units (TPUs) developed by Google [19]. The embedded system used to implement deep learning applications must have high processing capacity, as well as be able to acquire and process data in real time. At the same time, the processor must have enough memory to store the model data and the parameters. System-On-Chip (SoC) devices are an attractive solution that, in addition to high processing capabilities, includes multiple peripheral devices that can be very helpful for the sophisticated requirements of deep-learning applications. Examples of manufacturers that develop AI integrated circuits for edge computing are Samsung, Texas Instruments, Qualcomm, and STM. Some of their recent products are briefly presented below. The Maxim Integrated MAX78000 ultra-low power microcontroller is a relatively new device specially designed for edge Artificial Intelligence (AI) applications. Integrates a dedicated Convolutional Neural Network (CNN) accelerator along with a low-power ARM Cortex-M4 core and a RISC-V core [20]. Low power AI applications can be developed using this architecture, because it provides a variety of configuration options such as different oscillators, clock sources, or operation modes. One of the main advantages of this device is that it combines an energy-efficient AI processing unit with Maxim Integrated’s proven ultra-low power microcontrollers. It is suitable for battery-powered applications. The architecture is briefly presented in Figure 1, which summarizes the main features of the CNN accelerator and the microcontroller, such as cores, memory footprint, and external interfaces. The microcontroller has a dual core architecture: an ARM Cortex-M4 Processor with FPU running at clock frequencies of up to 100 MHz and a 32-Bit RISC-V Coprocessor running up to 60 MHz. To demonstrate the performance of this device, two applications were used: Keywords Spotting [21] and Face Identification [22]. The accuracy results are quite promising, 99.6% for keywords spotting and 94.4% for face identification.
Figure 1. The architecture of MAX78000.
2.2. Deep Learning Frameworks and Tools for Embedded Implementation
Firmware support for microcontrollers has seen accelerated development in recent years. Some examples of firmware and framework solutions are: CMSIS-NN released by ARM in 2018 which is an open source library consisting of efficient kernels developed to maximize Neural Network (NN) performance on ARM Cortex-M processors [30], TensorFlow Lite Micro which is an open source Machine Learning framework to enable DL models on embedded systems [31], STM X-CUBE-AI expansion package providing capabilities of automatic conversion of a pretrained Neural Network for 32 bit microcontrollers [32], MicroTensor (µTensor) which is a lightweight Machine Learning (ML) framework used for TensorFlow models and optimized for ARM cores [33], and PyTorch Mobile to execute ML models on edge devices using the PyTorch ecosystem [34]. CMSIS-NN was developed to help build IoT applications that run small neural networks directly on the systems that collect the data. This approach is preferred over cloud computing, as the number of IoT nodes is increasing. This leads to bandwidth limitations, as well as increasing latencies. The utility of this library has been demonstrated using a CNN designed for image classification task on the CIFAR-10 dataset. An ARM Cortex-M7 platform was used for the demonstration, obtaining a classification of 10.1 images per second with an accuracy of 79.9% [30][35][30,35]. With the multitude of available embedded platforms, with different hardware support, converting and optimizing an inference model to run on such a device is a very difficult task. TensorFlow Lite Micro was designed to address this situation and provide a unified ML framework. Covers these shortcomings with a flexible ML framework for embedded devices. In summary, this is an interpreter-based approach where hardware vendors have the possibility to provide platform-specific optimizations; it can be easily adapted to new applications and official benchmark solutions are supported. X-CUBE-AI is a package that extends the capabilities of STM32CubeMX.AI. It adds the possibility to convert a pre-trained NN into an ANSI C library that is performance optimized for STM32 microcontrollers based on ARM Cortex-M4 and M7 processor cores. The generated ANSI C source files are then compiled to run inference on the microcontroller. The generation process using this framework is depicted in Figure 2. In fact, CMSIS-NN kernels are used at a low level, but using this tool has a series of advantages for the developers such as: a graphical user interface, support for different DL frameworks such as Keras and TensorFlow Lite, 8-bit-quantization, and compatibility with different STM32 microcontroller series.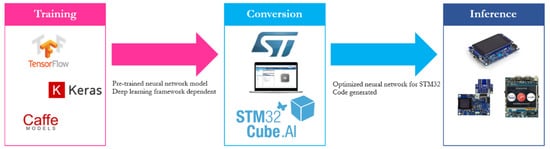
Figure 2. Conversion of a pre-trained model using STM32CubeMX.AI.