Deep neural networks have recently become increasingly used for a wide range of applications, (e.g., image and video processing). The demand for edge inference is growing, especially in the areas of relevance to the Internet-of-Things. Low-cost microcontrollers as edge devices are a promising solution for optimal application systems from several points of view such as: cost, power consumption, latency, or real-time execution. The implementation of these systems has become feasible due to the advanced development of hardware architectures and DSP capabilities, while the cost and power consumption have been maintained at a low level.
- deep neural networks
- edge computing
- microcontrollers
- ARM Cortex-M
1. Introduction
2. From Cloud to Edge Computing
2.1. Embedded Hardware for Deep Learning

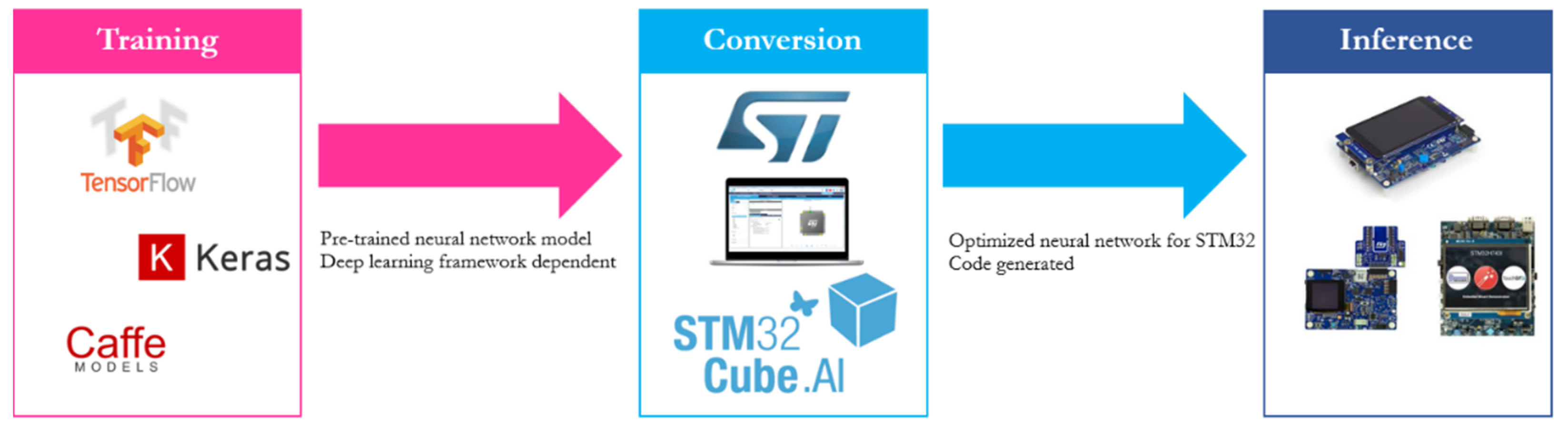
2.2. Deep Learning Frameworks and Tools for Embedded Implementation
This entry is adapted from the peer-reviewed paper 10.3390/electronics11162545
References
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092.
- Han, H.; Siebert, J. TinyML: A Systematic Review and Synthesis of Existing Research. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 21–24 February 2022; pp. 269–274.
- Carneiro, T.; da Nobrega, R.V.M.; Nepomuceno, T.; Bian, G.B.; de Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685.
- Jackovich, J.; Richards, R. Machine Learning with AWS: Explore the Power of Cloud Services for Your Machine Learning and Artificial Intelligence Projects; Packt Publishing: Birmingham, UK, 2018.
- Salvaris, M.; Dean, D.; Tok, W.H. Deep Learning with Azure: Building and Deploying Artificial Intelligence Solutions on the Microsoft AI Platform, 1st ed.; Apress Imprint: Berkeley, CA, USA, 2018.
- Han, Y.; Wang, X.; Leung, V.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. arXiv 2019, arXiv:1907.08349.
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646.
- Wang, F.; Zhang, M.; Wang, X.; Ma, X.; Liu, J. Deep learning for edge computing applications: A state-of-the-art survey. IEEE Access 2020, 8, 58322–58336.
- Berthelier, A.; Chateau, T.; Duffner, S.; Garcia, C.; Blanc, C. Deep Model Compression and Architecture Optimization for Embedded Systems: A Survey. J. Signal Process. Syst. 2020, 93, 863–878.
- Benoit, J.; Skirmantas, K.; Chen, B.; Zhu, M.; Tang, M.; Andrew, G.H.; Hartwig, A.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713.
- Blalock, D.; Ortiz, J.J.G.; Frankle, J.; Guttag, J. What is the state of neural network pruning? arXiv 2020, arXiv:2003.03033.
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531.
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830.
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360.
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for AI-enabled IoT devices?: A review. Sensors 2020, 20, 2533.
- Thompson, C.N.; Greenewald, K.; Lee, K.; Manso, F.G. The Computational Limits of Deep Learning. arXiv 2020, arXiv:2007.05558.
- Misra, J.; Saha, I. Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255.
- Talib, M.A.; Majzoub, S.; Nasir, Q.; Jamal, D. A systematic literature review on hardware implementation of artificial intelligence algorithms. J. Supercomput. 2020, 77, 1897–1938.
- Jouppi, N.; Young, C.; Patil, N.; Patterson, D. Motivation for and evaluation of the first tensor processing unit. IEEE Micro 2018, 38, 10–19.
- Maxim Integrated. Application Note 7417: Developing Power-Optimized Applications on the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7417.html (accessed on 31 May 2021).
- Maxim Integrated. Application Note 7359: Keywords Spotting Using the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7359.html (accessed on 31 May 2021).
- Maxim Integrated. Application Note 7364: Face Identification Using the MAX78000. Available online: https://www.maximintegrated.com/en/design/technical-documents/app-notes/7/7364.html (accessed on 31 May 2021).
- Pullini, A.; Rossi, D.; Loi, I.; Tagliavini, G.; Benini, L. Mr.Wolf: An Energy-Precision Scalable Parallel Ultra Low Power SoC for IoT Edge Processing. IEEE J. Solid-State Circuits 2019, 54, 1970–1981.
- Osta, M.; Ibrahim, A.; Magno, M.; Eggimann, M.; Pullini, A.; Gastaldo, P.; Valle, M. An energy efficient system for touch modality classification in electronic skin applications. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–4.
- Benatti, S.; Montagna, F.; Kartsch, V.; Rahimi, A.; Rossi, D.; Benini, L. Online Learning and Classification of EMG-Based Gestures on a Parallel Ultra-Low Power Platform Using Hyperdimensional Computing. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 516–528.
- Magno, M.; Wang, X.; Eggimann, M.; Cavigelli, L.; Benini, L. InfiniWolf: Energy efficient smart bracelet for edge computing with dual source energy harvesting. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 342–345.
- Schneider, T.; Wang, X.; Hersche, M.; Cavigelli, L.; Benini, L. Q-EEGNet: An energy-efficient 8-bit quantized parallel EEGNet implementation for edge motor-imagery brain-machine interfaces. In Proceedings of the IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 284–289.
- Tambe, T.; Yang, E.-Y.; Ko, G.G.; Chai, Y.; Hooper, C.; Donato, M.; Whatmough, P.N.; Rush, A.M.; Brooks, D.; Wei, G.-Y. 9.8 A 25mm2 SoC for IoT devices with 18ms noise-robust speech-to-text latency via bayesian speech denoising and attention-based sequence-to-sequence DNN speech recognition in 16 nm FinFET. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; pp. 158–160.
- Texas Instruments. Embedded Low-Power Deep Learning with TIDL. Available online: https://www.ti.com/lit/wp/spry314/spry314.pdf (accessed on 31 May 2021).
- Lai, L.; Suda, N.; Chandra, V. CMSIS-NN: Efficient neural network kernels for arm cortex-m cpus. arXiv 2018, arXiv:1801.06601.
- David, R.; Duke, J.; Jain, A.; Reddi, V.J.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Regev, S.; et al. TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems. arXiv 2020, arXiv:2010.08678.
- Falbo, V.; Apicella, T.; Aurioso, D.; Danese, L.; Bellotti, F.; Berta, R.; De Gloria, A. Analyzing machine learning on mainstream microcontrollers. In Proceedings of the International Conference on Applications Electronics Pervading Industry, Environment and Society, Pisa, Italy, 19–20 November 2019; Springer: Cham, Switzerland, 2020; pp. 103–108. Available online: https://link.springer.com/chapter/10.1007/978-3-030-37277-4_12 (accessed on 29 November 2021).
- uTensor. TinyML AI Inference Library. Available online: https://github.com/uTensor/uTensor (accessed on 31 May 2021).
- Pytorch Mobile. End-to-End Workflow from Training to Deployment for iOS and Android Mobile Devices. Available online: https://pytorch.org/mobile/home/ (accessed on 31 May 2021).
- Orășan, I.L.; Căleanu, C.D. ARM embedded low cost solution for implementing deep learning paradigms. In Proceedings of the International Symposium on Electronics and Telecommunications (ISETC), Timișoara, Romania, 5–6 November 2020; pp. 1–4.