Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Chi-Meng Tzeng | -- | 1901 | 2022-04-21 11:46:18 | | | |
| 2 | Vivi Li | Meta information modification | 1901 | 2022-04-22 05:54:50 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Tzeng, C.; , .; Ke, R. Liquid Biopsy, ctDNA Diagnosis through NGS. Encyclopedia. Available online: https://encyclopedia.pub/entry/22098 (accessed on 24 July 2026).
Tzeng C, , Ke R. Liquid Biopsy, ctDNA Diagnosis through NGS. Encyclopedia. Available at: https://encyclopedia.pub/entry/22098. Accessed July 24, 2026.
Tzeng, Chi-Meng, , Rongqin Ke. "Liquid Biopsy, ctDNA Diagnosis through NGS" Encyclopedia, https://encyclopedia.pub/entry/22098 (accessed July 24, 2026).
Tzeng, C., , ., & Ke, R. (2022, April 21). Liquid Biopsy, ctDNA Diagnosis through NGS. In Encyclopedia. https://encyclopedia.pub/entry/22098
Tzeng, Chi-Meng, et al. "Liquid Biopsy, ctDNA Diagnosis through NGS." Encyclopedia. Web. 21 April, 2022.
Copy Citation
Liquid biopsy with circulating tumor DNA (ctDNA) profiling by next-generation sequencing holds great promise to revolutionize clinical oncology. It relies on the basis that ctDNA represents the real-time status of the tumor genome which contains information of genetic alterations. Compared to tissue biopsy, liquid biopsy possesses great advantages such as a less demanding procedure, minimal invasion, ease of frequent sampling, and less sampling bias. Next-generation sequencing (NGS) methods have come to a point that both the cost and performance are suitable for clinical diagnosis. Thus, profiling ctDNA by NGS technologies is becoming more and more popular since it can be applied in the whole process of cancer diagnosis and management.
liquid biopsy
ctDNA
next-generation sequencing
mutation
biomarkers
1. Introduction
It is now well known that a tumor can shed cancer cells, extracellular vesicles, proteins and nucleic acids into the peripheral blood [1]. These tumor-derived substances possess great potential as therapeutic targets or diagnostics biomarkers (Figure 1). The idea of liquid biopsy is to sample the biomarkers found in the non-solid biological tissue for analysis of disease status. Different biological substances such as circulating tumor cells (CTCs), cell-free nucleic acids, exosomes, or proteins can be sampled and analyzed in various body fluids such as blood or urine [2][3]. In particular, the blood is the most widely used sampling source of liquid biopsy due to the rich information it carries and because it is easy to access [4]. Among these blood-borne biomarkers, circulating tumor DNA (ctDNA) has gained a tremendous amount of interest in recent years. In this entry, researchers discuss the biology, clinical utilities, and applications of ctDNA as biomarkers, emphasizing the technologies for their detection.
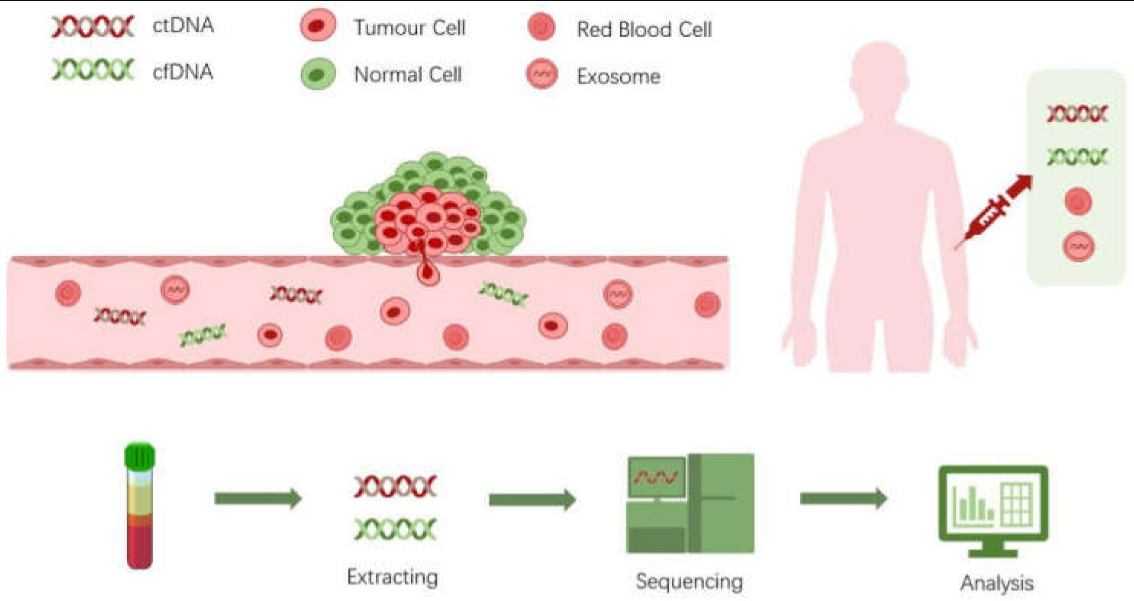
Figure 1. Deciphering of liquid biopsy.
2. Biology of ctDNA
ctDNA is shed into the peripheral blood by tumor cells in cancer patients. However, the biological mechanisms of how ctDNA enters and presents in the blood circulation have not yet been fully elucidated [5]. Generally, it is widely accepted that apoptosis and necrosis of tumor cells are the main sources of ctDNA. Studies have revealed that ctDNAs are generally more fragmented than nonmutant cell-free DNA (cfDNA), with a maximum enrichment of fragments between 90 and 150 bp [6] while the half-life of ctDNA ranged from only 15 minutes to a few hours [7]. Although it is challenging to preserve and use ctDNA as a biomarker because of the short half-life time window, it may reflect a snap-shot of the tumor genome status, providing a way to monitor the disease. However, ctDNA represents only a small part of cfDNA in the circulation. Several biological processes are known to release cfDNA, including phagocytosis, active secretion, neutrophil release, excision repair, and pyroptosis [8]. Thus, discriminating ctDNA from the normal cfDNA is vital to precisely reflect the disease status. Since ctDNA is derived from malignant tumor cells, they carry the tumor-specific abnormality that is not present in the normal cfDNA. The tumor-specific abnormalities that ctDNA possesses are inherited from its tumor origins, such as single-nucleotide mutations, epigenetics changes, and copy number variations [9]. These molecular features can then be used as specific biomarkers for cancer monitoring and management references.
Apart from tumor-specific molecular characteristics, studies have also found that the levels of ctDNA in advanced stage cancers such as breast, colorectal, pancreatic, and gastroesophageal cancers are higher than in the early stage of diseases [10]. However, the amount of ctDNA is not simply associated with the tumor size, but varies in different types of cancer [11][12]. Furthermore, ctDNA can both derive from primary tumor and metastases, thus is associated with the pathological status of the disease [13]. Because of the different origins of ctDNA, liquid biopsy together with ctDNA analysis may be a better representation of tumor genomic diversity compared to biopsy from a single solid tumor sample [14]. In other words, ctDNA reflects a better overview of the most up-to-date status of the tumor genome, making it superior to tissue biopsy analysis for cancer patient diagnosis and management. Circulating cell-free RNA (ccfRNA), mainly including mRNA and miRNA, is another type of cell-free nucleic acid that can be found in the blood stream, and also possesses potential to become a biomarker for cancer [15]. Although ccfRNA shares many similar characteristics to ctDNA, there are more challenges when using them as cancer biomarkers [16]. Thus, more studies and technical advances are still needed before ccfRNA can become as popular as ctDNA in cancer diagnosis. Therefore, researchers focus on the discussion of ctDNA in this entry.
3. Next Generation Sequencing Technologies for ctDNA Detection
Because the ctDNA represents only a small part of the cfDNA, it is important to utilize the tumor-specific alterations to distinguish themselves from their wild-type counterparts. Currently, most methods using ctDNA as cancer biomarkers focus on mutation de tection [17]. Mutations in ctDNA can be detected either by PCR or NGS [18][19]. However, PCR approaches only detect known mutations in certain genes. Patients without those mutations will be left out, limiting their applications as a generic diagnosis technique for ctDNA analysis. NGS approaches, on the other hand, cover a broader range of mutations by examining the whole sequences of genes of interest. In this entry, researchers focus on discussing the NGS approaches for ctDNA profiling.
NGS for ctDNA analysis can be targeted or untargeted as well [20]. Targeted approaches for ctDNA profiling usually sequence dozens of genes to hundreds of genes or even the whole exome. Because of relatively low throughput, high sensitivity can then be achieved by deep sequencing specific regions of interest that cover clinically relevant mutations. To enrich targets, either multiplex PCR or hybridization capture strategies are ap plied to ensure maximal amplification of target gene fragments. Due to better specificity and sensitivity, targeted sequencing is more suitable for clinical diagnosis. In the case of untargeted approaches, no enrichment step is performed, thus sequencing the whole genome. Although whole-genome sequencing scarifies the sequencing depth, it can be used to discover new genomic aberrations related to patient prognosis or treatment strategies, making it suitable for basic biomedical research.
For the sequencing step, the cost, accuracy, and speed are all key factors that need to be taken into consideration for ctDNA profiling. It is particularly true for diagnosis purposes. Under this circumstance, there are currently several platforms more suitable for ctDNA sequencing, including Illumina’s sequencing-by-synthesis (SBS), Thermo Fisher Scientific’s Ion Torrent, and the nanopore sequencing from Oxford Nanopore Technologies [21][22]. Illumina’s sequencing platform is dominating due to its high throughput and high accuracy. The Ion Torrent semiconductor sequencer is lower in throughput but faster in the run speed, making it advantageous when speed is required. During the past decade, nanopore sequencing has been improving in its accuracy but is still lower than the other mainstream sequencers. However, it is advantageous in the convenient library preparation and sequencing procedure. Thus, in the case when the requirement of accuracy is not high, such as profiling copy number variations, nanopore sequencing can be used for ctDNA analysis [23]. After generation of raw sequencing data, applying the right bioinformatic algorithms is also crucial for mutation detection. A review that summarized bioinformatics tools for ctDNA analysis can be found here [24]. There are also databases that can be used to help with the interpretation of the liquid biopsy data. liqDB is a database for liquid biopsy small RNA sequencing profiles that provide users with meaningful information to guide their small RNA liquid biopsy research and to overcome technical and conceptual problems [25]. ctcRbase is a database that can be used for query and browse gene expression data of circulating tumor cells/microemboli [26].
The key for precisely identifying ctDNA from a large amount of background cfDNA is to correctly detect the alterations of ctDNA compared to normal cfDNA and single nucleotide mutation is the most commonly detected alteration [27]. Technically, in the context of ctDNA sequencing, the sensitivity of detecting the so-called mutant allele frequency (MAF) or variant allele frequency (VAF) is often used to evaluate the performance of an NGS ctDNA profiling assay [13][28]. MAF or VAF describes the proportion of DNA molecules containing a mutation over the total number of molecules containing the same allele. Thus, they reflect the amount of ctDNAs when referring to the cfDNAs that contain tumor-specific mutant alleles. Therefore, the lower the MAF can be detected, the more sensitive an NGS assay is for ctDNA analysis.
4. Strategies for True Mutation Detection Using NGS
Because ctDNA is mainly distinguished from normal cfDNA by tumor-specific mutations, it is thus critical to identify a true mutation for sensitive ctDNA detection. Plus, the low levels of ctDNA presented in the bloodstream also warrant highly sensitive and specific methods that can detect and quantify mutant alleles in cfDNA. This can be achieved both by experimental designs and bioinformatics algorithms. Some of these strategies are presented below to elucidate the general principles.
Tagged-amplicon deep sequencing (TAm-Seq) introduces a two-step amplification strategy to first amplify regions of interest by multiplex PCR using specifically designed primers at low concentrations to avoid inter-primer interactions, followed by using a microfluidic system in a second amplification step to amplify individual target regions using the amplicons from the first step [29]. Sequencing adaptors were attached to the amplification products and unique molecular identifiers were used to tag different samples by another PCR step. Tam-seq was able to identify mutations of MAF as low as 2% with sensitivity and specificity over 97% [29]. The enhanced TAm-Seq (eTAm-Seq) can detect MAF as low as 0.25% with a sensitivity of 94%. It also utilizes revised bioinformatics analysis to identify single-nucleotide variants (SNVs), short insertions/deletions (indels) and copy number variants (CNVs) [30].
Unique molecular identifiers (UMIs) are often used to barcode individual templates so that the amplicons from different templates can be identified [31]. UMIs are normally short DNA fragments that are constituted by random nucleotide bases. The idea is that for a DNA sequence of N bases, there will be 4N different types of barcodes that can be used to label different templates before amplification. If a mutation does not appear in most of the same UMI-connected sequences, it is likely to be an error introduced by amplification or the sequencing reaction. By using this strategy, the Safe-SeqS reduces the sequencing errors by at least 70-fold and has a sensitivity as high as ~98% for detecting tumor-specific mutations [32].
A combination of optimized library preparation and bioinformatics algorithm is often used to achieve better performance of NGS assays for low-abundance sequence aberration in ctDNA analysis. Target enrichment of DNA fragments containing recurrent mutations combined with deep sequencing can also improve the sensitivity of mutation detection. CAncer Personalized Profiling by deep Sequencing (CAPP-Seq) is such an NGS assay that combines a target-selection library preparation approach with specialized bioinformatics workflow [33]. It generates a library of selectors that can specifically bind to recurrently mutated genomic regions for target enrichment. Combined with dedicated bioinformatics analysis, CAPP-Seq can detect MAF ~ 0.02% with a sensitivity of nearly 100% among stage II-IV NSCLC patients [33]. Targeted error correction sequencing (TEC-Seq) is another example of experimental and bioinformatic optimizations to improve assay performance, including optimized target capture and library preparation, maximizing the representation of unique cfDNA both using different mapping positions and molecular barcodes, redundant sequencing, filtering of mapping and sequencing artefacts, and identifying and removing normal cell proliferation alterations [34]. Target capturing a panel of genes and deep sequencing (~30,000×) of the captured DNA fragments is performed to ensure high sensitivity and specificity. It was able to detect somatic mutations in the plasma of 71%, 59%, 59% and 68%, respectively in colorectal, breast, lung, or ovarian cancer patients with stage I or II diseases, demonstrating very promising results for broad cancer diagnosis at early stages.
References
- Junqueira-Neto, S.; Batista, I.A.; Costa, J.L.; Melo, S.A. Liquid Biopsy beyond Circulating Tumor Cells and Cell-Free DNA. Acta Cytol. 2019, 63, 479–488.
- Poulet, G.; Massias, J.; Taly, V. Liquid Biopsy: General Concepts. Acta Cytol. 2019, 63, 449–455.
- Dakubo, G.D. Cancer Biomarkers in Body Fluids; Springer International Publishing: Cham, Switzerland, 2017.
- Goodwin, S.; McPherson, J.D.; McCombie, W.R. Coming of age: Ten years of next-generation sequencing technologies. Nat. Rev. Genet. 2016, 17, 333–351.
- Thierry, A.R.; El Messaoudi, S.; Gahan, P.B.; Anker, P.; Stroun, M. Origins, structures, and functions of circulating DNA in oncology. Cancer Metastasis Rev. 2016, 35, 347–376.
- Mouliere, F.; Chandrananda, D.; Piskorz, A.M.; Moore, E.K.; Morris, J.; Ahlborn, L.B.; Mair, R.; Goranova, T.; Marass, F.; Heider, K.; et al. Enhanced detection of circulating tumor DNA by fragment size analysis. Sci. Transl. Med. 2018, 10, eaat4921.
- Fleischhacker, M.; Schmidt, B. Circulating nucleic acids (CNAs) and cancer—A survey. Biochim. Biophys. Acta BBA Rev. Cancer 2007, 1775, 181–232.
- Aucamp, J.; Bronkhorst, A.J.; Badenhorst, C.P.S.; Pretorius, P.J. The diverse origins of circulating cell-free DNA in the human body: A critical re-evaluation of the literature. Biol. Rev. 2018, 93, 1649–1683.
- Elazezy, M.; Joosse, S.A. Techniques of using circulating tumor DNA as a liquid biopsy component in cancer management. Comput. Struct. Biotechnol. J. 2018, 16, 370–378.
- Cheng, F.; Su, L.; Qian, C. Circulating tumor DNA: A promising biomarker in the liquid biopsy of cancer. Oncotarget 2016, 7, 48832–48841.
- Diehl, F.; Li, M.; Dressman, D.; He, Y.; Shen, D.; Szabo, S.; Diaz, L.A.; Goodman, S.N.; David, K.A.; Juhl, H.; et al. Detection and quantification of mutations in the plasma of patients with colorectal tumors. Proc. Natl. Acad. Sci. USA 2005, 102, 16368–16373.
- Avanzini, S.; Kurtz, D.M.; Chabon, J.J.; Moding, E.J.; Hori, S.S.; Gambhir, S.S.; Alizadeh, A.A.; Diehn, M.; Reiter, J.G. A mathematical model of ctDNA shedding predicts tumor detection size. Sci. Adv. 2020, 6, eabc4308.
- Stewart, C.M.; Kothari, P.D.; Mouliere, F.; Mair, R.; Somnay, S.; Benayed, R.; Zehir, A.; Weigelt, B.; Dawson, S.-J.; Arcila, M.E.; et al. The value of cell-free DNA for molecular pathology. J. Pathol. 2018, 244, 616–627.
- Sueoka-Aragane, N.; Nakashima, C.; Yoshida, H.; Matsumoto, N.; Iwanaga, K.; Ebi, N.; Nishiyama, A.; Yatera, K.; Kuyama, S.; Fukuda, M.; et al. The role of comprehensive analysis with circulating tumor DNA in advanced non-small cell lung cancer patients considered for osimertinib treatment. Cancer Med. 2021, 10, 3873–3885.
- Schwarzenbach, H.; Hoon, D.S.B.; Pantel, K. Cell-free nucleic acids as biomarkers in cancer patients. Nat. Rev. Cancer 2011, 11, 426–437.
- Zaporozhchenko, I.A.; Ponomaryova, A.A.; Rykova, E.Y.; Laktionov, P.P. The potential of circulating cell-free RNA as a can-cer biomarker: Challenges and opportunities. Expert Rev. Mol. Diagn. 2018, 18, 133–145.
- Keller, L.; Belloum, Y.; Wikman, H.; Pantel, K. Clinical relevance of blood-based ctDNA analysis: Mutation detection and beyond. Br. J. Cancer 2021, 124, 345–358.
- Lu, L.; Bi, J.; Bao, L. Genetic profiling of cancer with circulating tumor DNA analysis. J. Genet. Genom. 2018, 45, 79–85.
- Kastrisiou, M.; Zarkavelis, G.; Pentheroudakis, G.; Magklara, A. Clinical application of next-generation sequencing as a liq-uid biopsy technique in advanced colorectal cancer: A trick or a treat? Cancers 2019, 11, 1573.
- Bai, Y.; Wang, Z.; Liu, Z.; Liang, G.; Gu, W.; Ge, Q. Technical progress in circulating tumor DNA analysis using next genera-tion sequencing. Mol. Cell Probes 2020, 49, 101480.
- Levy, S.E.; Myers, R.M. Advancements in Next-Generation Sequencing. Annu. Rev. Genom. Hum. Genet. 2016, 17, 95–115.
- Srivastava, V.K. Sequencing Technologies: Introduction and Applications. Int. J. Hum. Genet. 2019, 19.
- Martignano, F.; Munagala, U.; Crucitta, S.; Mingrino, A.; Semeraro, R.; Del Re, M.; Petrini, I.; Magi, A.; Conticello, S.G. Na-nopore sequencing from liquid biopsy: Analysis of copy number variations from cell-free DNA of lung cancer patients. Mol. Cancer 2021, 20, 1–6.
- Chen, S.; Liu, M.; Zhou, Y. Bioinformatics Analysis for Cell-Free Tumor DNA Sequencing Data. Methods Mol. Biol. 2018, 67–95.
- Aparicio-Puerta, E.; Jáspez, D.; Lebrón, R.; Koppers-Lalic, D.; Marchal, J.A.; Hackenberg, M. liqDB: A small-RNAseq knowledge discovery database for liquid biopsy studies. Nucleic Acids Res. 2019, 47, D113–D120.
- Zhao, L.; Wu, X.; Li, T.; Luo, J.; Dong, D. ctcRbase: The gene expression database of circulating tumor cells and microemboli. Database 2020, 2020.
- Cheng, F.; Zhao, J.; Zhao, Z. Advances in computational approaches for prioritizing driver mutations and significantly mutated genes in cancer genomes. Brief. Bioinform. 2016, 17, 642–656.
- Bos, M.K.; Nasserinejad, K.; Jansen, M.P.H.M.; Angus, L.; Atmodimedjo, P.N.; de Jonge, E.; Dinjens, W.N.M.; van Schaik, R.H.N.; Del Re, M.; Dubbink, H.J.; et al. Comparison of variant allele frequency and number of mutant molecules as units of measurement for circulating tumor DNA. Mol. Oncol. 2021, 15, 57–66.
- Forshew, T.; Murtaza, M.; Parkinson, C.; Gale, D.; Tsui, D.W.Y.; Kaper, F.; Dawson, S.-J.; Piskorz, A.M.; Jimenez-Linan, M.; Bentley, D.; et al. Noninvasive Identification and Monitoring of Cancer Mutations by Targeted Deep Sequencing of Plasma DNA. Sci. Transl. Med. 2012, 4, 136ra68.
- Gale, D.; Lawson, A.R.J.; Howarth, K.; Madi, M.; Durham, B.; Smalley, S.; Calaway, J.; Blais, S.; Jones, G.; Clark, J.; et al. Development of a highly sensitive liquid biopsy platform to detect clinically-relevant cancer mutations at low allele fractions in cell-free DNA. PLoS ONE 2018, 13, e0194630.
- Smith, T.; Heger, A.; Sudbery, I. UMI-tools: Modeling sequencing errors in Unique Molecular Identifiers to improve quantification accuracy. Genome Res. 2017, 27, 491–499.
- Kinde, I.; Wu, J.; Papadopoulos, N.; Kinzler, K.W.; Vogelstein, B. Detection and quantification of rare mutations with massively parallel sequencing. Proc. Natl. Acad. Sci. USA 2011, 108, 9530–9535.
- Newman, A.M.; Bratman, S.V.; To, J.; Wynne, J.F.; Eclov, N.C.W.; Modlin, L.A.; Liu, C.L.; Neal, J.W.; Wakelee, H.A.; Merritt, R.E.; et al. An ultrasensitive method for quantitating circulating tumor DNA with broad patient coverage. Nat. Med. 2014, 20, 548–554.
- Phallen, J.; Sausen, M.; Adleff, V.; Leal, A.; Hruban, C.; White, J.; Anagnostou, V.; Fiksel, J.; Cristiano, S.; Papp, E.; et al. Direct detection of early-stage cancers using circulating tumor DNA. Sci. Transl. Med. 2017, 9, eaan2415.
More
Information
Subjects:
Biotechnology & Applied Microbiology
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.3K
Entry Collection:
Extraction Techniques in Sample Preparation
Revisions:
2 times
(View History)
Update Date:
22 Apr 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No