 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Zongwei Liang | -- | 2056 | 2022-04-19 09:44:11 | | | |
| 2 | Lindsay Dong | + 934 word(s) | 2990 | 2022-04-20 03:24:27 | | | | |
| 3 | Lindsay Dong | -3 word(s) | 2987 | 2022-04-20 03:34:00 | | | | |
| 4 | Lindsay Dong | Meta information modification | 2987 | 2022-04-20 03:41:31 | | | | |
| 5 | Lindsay Dong | Meta information modification | 2987 | 2022-04-21 08:13:52 | | | | |
| 6 | Lindsay Dong | Meta information modification | 2987 | 2022-04-21 08:16:42 | | |
Video Upload Options
SeAttE is a novel tensor ecomposition model based on Separating Attribute space for knowledge graph completion. SeAttE is the first model among the tensor decomposition family to consider the attribute space separation task. Furthermore, SeAttE transforms the learning of too many parameters for the attribute space separation task into the structure’s design. This operation allows the model to focus on learning the semantic equivalence between relations, causing the performance to approach the theoretical limit.
1. Introduction
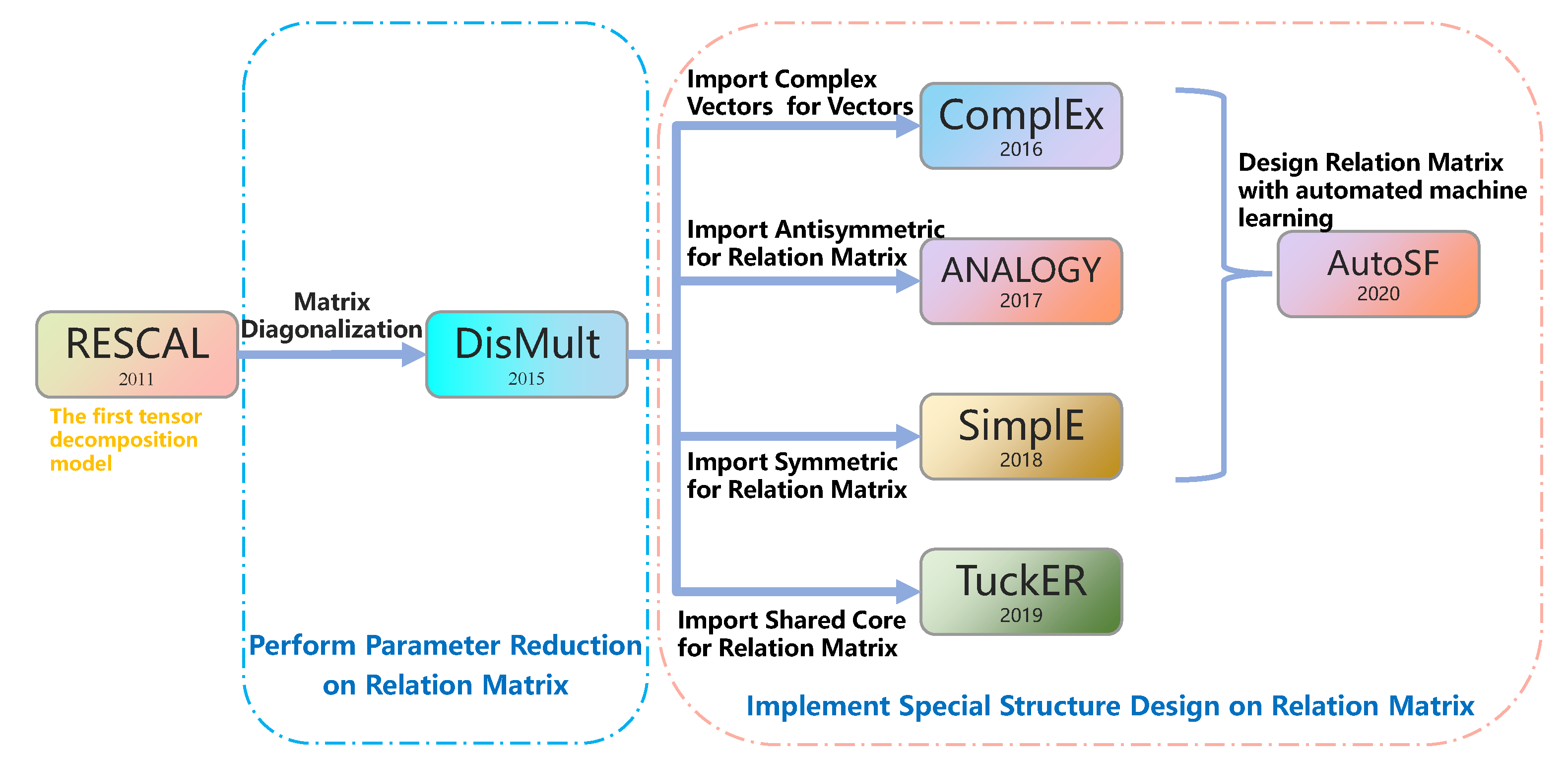
2. Related Work and Critical Differences
3. Background
3.1. KG Completion and Notations
KGs are collections of factual triples , where represents a triple in the knowledge graph, are head, tail entities and relations, respectively. Scholars associates the entities and relations r with vectors in knowledge graph embedding. Then scholars design an appropriate scoring function , to map the embedding of the triple to a certain score. For a particular question , the task of KG completion is ranking all possible answers and obtain the preference of prediction.
Using and to distinguish matrix representation and vector representation of the relations, respectively. T, ⟨⋅⟩ and ∘ denote the operation of transpose, the generalized dot product and the Hadamard product, respectively. Especially, scholars utilize to represent the matrix of relation in SeAttE. Let ∥∥, () and () denote the norm, matrix diagonalization and the real part of complex vectors.
3.2. Basic Models
Tensor Factorization Models. Models in this family interpret link prediction as a task of tensor decomposition, where triples are decomposed into a combination (e.g., a multi-linear product) of low-dimensional vectors for entities and relations. CP [34] represents triples with canonical decomposition. Note that the same entity has different representations at the head and tail of the triplet. The score function can be expressed as:
where .
RESCAL [5] represents a relation as a matrix that describes the interactions between latent representations of entities. The score function is defined as:
DistMult [6] forces all relations to be diagonal matrices, which consistently reduces the space of parameters to be learned, resulting in a much easier model to train. On the other hand, this makes the scoring function commutative, which amounts to treating all relations as symmetric.
where .
ComplEx [7] extends the real space to complex spaces and constrains the embeddings for relation to be a diagonal matrix. The bilinear product becomes a Hermitian product in complex spaces. The score function can be expressed as:
where .
4. SeAttE Model
4.1. Motivation and Design of SeAttE
4.1.1. Motivation
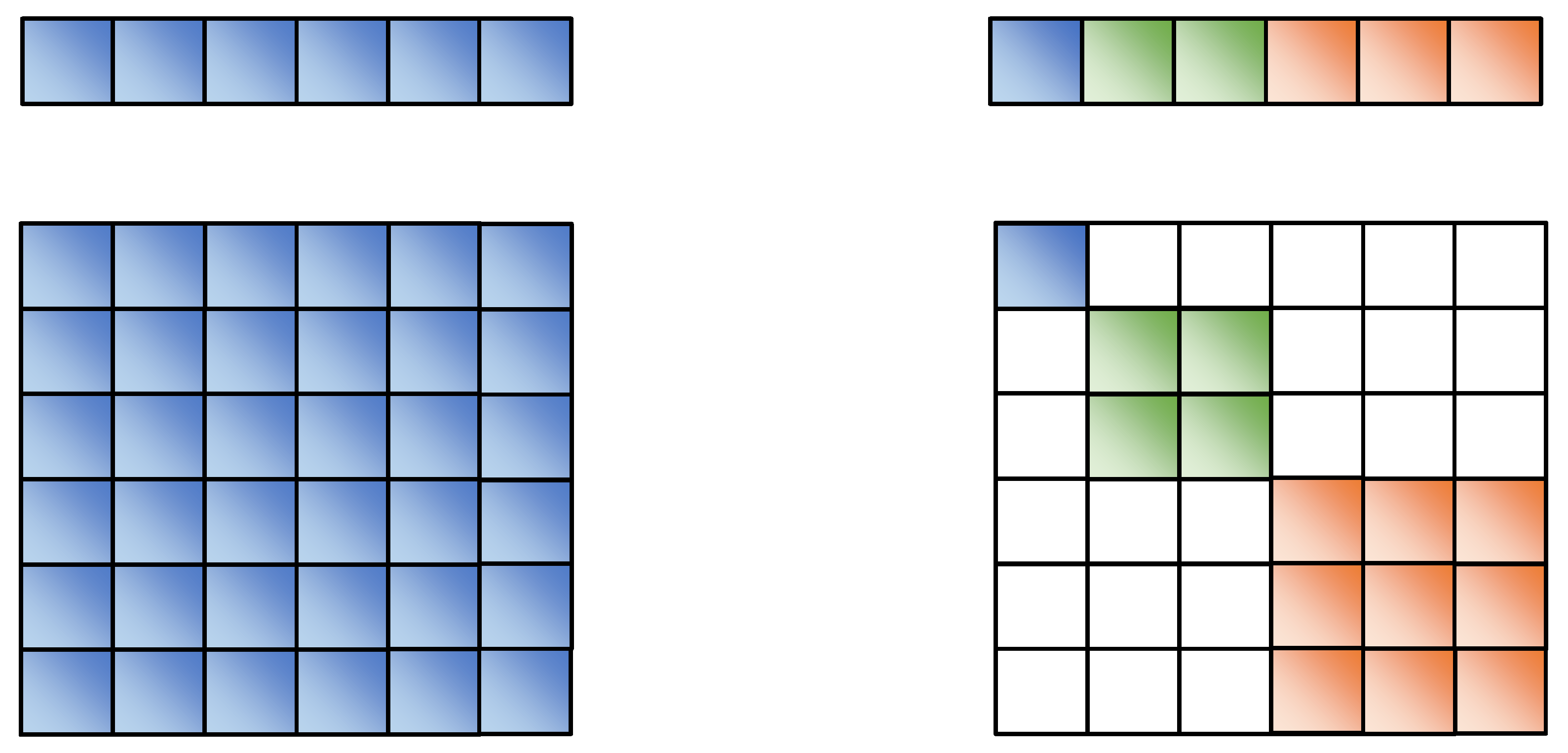
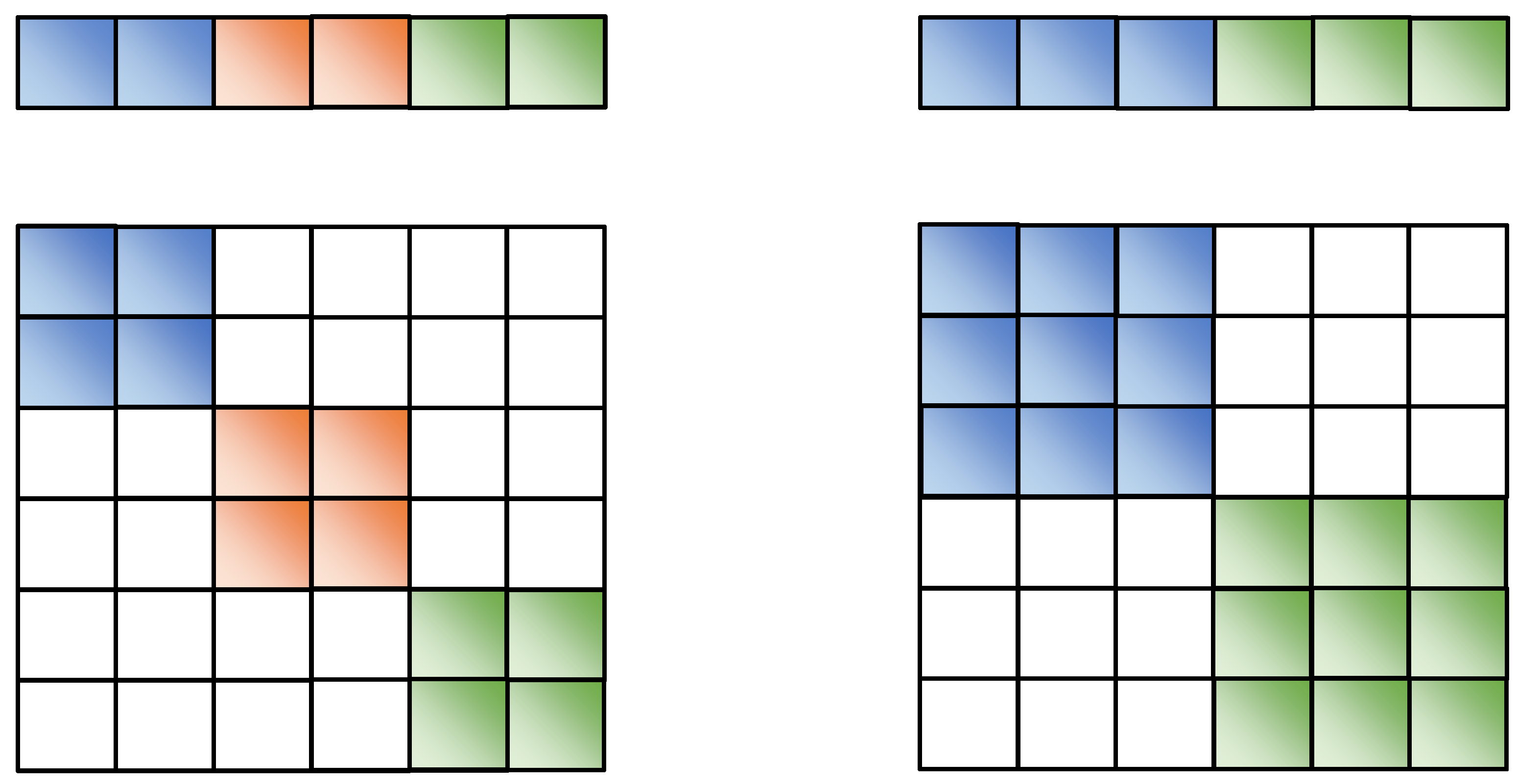
4.1.2. Design
4.2. Relation to Previous Tensor Factorization Models
RESCAL is the basic tensor decomposition model. Due to the tremendous amount of parameters of this model, the dimension of the entity cannot be well expanded. When the dimension of the attribute subspace of SeAttE satisfies , SeAttE is equivalent to RESCAL.
where and .
DisMult is the simplest tensor decomposition model, which diagonalizes all relation matrices. When the max dimension of the attribute subspace of SeAttE k is set to 1, then is a 1-dimensional matrix, that is, a numerical value. The relationship matrix is equivalent to the diagonal. Under these circumstances, SeAttE is equivalent to DisMult.
where .
ComplEx imports complex representations to characterize symmetric and antisymmetric relations.
where and .
From the above formula, it can find that ComplEx is equivalent to RESCAL with
References
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; Burges, C.J.C., Bottou, L., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 2787–2795.
- Suchanek, F.M.; Kasneci, G.; Weikum, G. YAGO: A Large Ontology from Wikipedia and WordNet. J. Web Semant. 2008, 6, 203–217.
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z.G. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, 11–15 November 2007; Aberer, K., Choi, K., Noy, N.F., Allemang, D., Lee, K., Nixon, L.J.B., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4825, pp. 722–735.
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A.Y. Reasoning With Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 926–934.
- Nickel, M.; Tresp, V.; Kriegel, H. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the ICML’11: Proceedings of the 28th International Conference on International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011.
- Yang, B.; tau Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Washington, DC, USA, 28 June–2 July 2011.
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. arXiv 2016, arXiv:1606.06357.
- Balazevic, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor Factorization for Knowledge Graph Completion. arXiv 2019, arXiv:1901.09590.
- Kazemi, S.M.; Poole, D. SimplE Embedding for Link Prediction in Knowledge Graphs. In Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; pp. 4289–4300.
- Zhang, Y.; Yao, Q.; Dai, W.; Chen, L. AutoSF: Searching Scoring Functions for Knowledge Graph Embedding. In Proceedings of the 36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, TX, USA, 20–24 April 2020; pp. 433–444.
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Schuurmans, D., Wellman, M.P., Eds.; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1955–1961.
- Liu, H.; Wu, Y.; Yang, Y. Analogical Inference for Multi-relational Embeddings. arXiv 2017, arXiv:1705.02426.
- Hitchcock, F.L. The Expression of a Tensor or a Polyadic as a Sum of Products. J. Math. Phys. 1927, 6, 164–189.
- Gao, H.; Yang, K.; Yang, Y.; Zakari, R.Y.; Owusu, J.W.; Qin, K. QuatDE: Dynamic Quaternion Embedding for Knowledge Graph Completion. arXiv 2021, arXiv:2105.09002.
- Lu, H.; Hu, H.; Lin, X. DensE: An enhanced non-commutative representation for knowledge graph embedding with adaptive semantic hierarchy. Neurocomputing 2022, 476, 115–125.
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014.
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015.
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 15 July 2015.
- Sun, Z.; Deng, Z.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. arXiv 2019, arXiv:1902.10197.
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 3065–3072.
- Tang, Y.; Huang, J.; Wang, G.; He, X.; Zhou, B. Orthogonal Relation Transforms with Graph Context Modeling for Knowledge Graph Embedding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Event, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2713–2722.
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018.
- Nguyen, D.Q.; Nguyen, T.; Nguyen, D.Q.; Phung, D.Q. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. arXiv 2018, arXiv:1712.02121.
- Nguyen, D.Q.; Vu, T.; Nguyen, T.; Nguyen, D.Q.; Phung, D.Q. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. arXiv 2019, arXiv:1808.04122.
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based Multi-Relational Graph Convolutional Networks. arXiv 2020, arXiv:1911.03082.
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Volume 1: Long Papers. Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4710–4723.
- Wan, G.; Pan, S.; Gong, C.; Zhou, C.; Haffari, G. Reasoning Like Human: Hierarchical Reinforcement Learning for Knowledge Graph Reasoning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; pp. 1926–1932.
- Hildebrandt, M.; Serna, J.A.Q.; Ma, Y.; Ringsquandl, M.; Joblin, M.; Tresp, V. Reasoning on Knowledge Graphs with Debate Dynamics. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 4123–4131.
- Qu, M.; Chen, J.; Xhonneux, L.A.C.; Bengio, Y.; Tang, J. RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021.
- Biswas, R.; Alam, M.; Sack, H. MADLINK: Attentive Multihop and Entity Descriptions for Link Prediction in Knowledge Graphs; IOS Press: Amsterdam, The Netherlands, 2021.
- Zhang, Z.; Cai, J.; Wang, J. Duality-Induced Regularizer for Tensor Factorization Based Knowledge Graph Completion. arXiv 2020, arXiv:2011.05816.
- Lei, D.; Jiang, G.; Gu, X.; Sun, K.; Mao, Y.; Ren, X. Learning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Virtual Event, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8541–8547.
- Liang, Z.; Yang, J.; Liu, H.; Huang, K. A Semantic Filter Based on Relations for Knowledge Graph Completion. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021; Moens, M., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 7920–7929.
- Lacroix, T.; Usunier, N.; Obozinski, G. Canonical Tensor Decomposition for Knowledge Base Completion. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2869–2878.

