SeAttE is a novel tensor ecomposition model based on Separating Attribute space for knowledge graph completion. SeAttE is the first model among the tensor decomposition family to consider the attribute space separation task. Furthermore, SeAttE transforms the learning of too many parameters for the attribute space separation task into the structure’s design. This operation allows the model to focus on learning the semantic equivalence between relations, causing the performance to approach the theoretical limit.
- NLP
- knowledge graphs
- knowledge representation
- link prediction
- attribute space
1. Introduction
2. Related Work and Critical Differences
3. Background


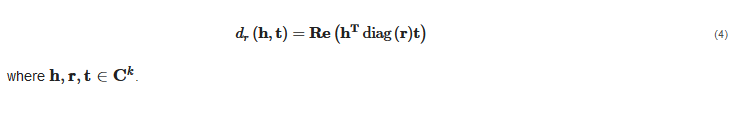
4. SeAttE Model
4.1. Motivation and Design of SeAttE
4.1.1. Motivation
As shown in3. Background
3.1. KG Completion and Notations
KGs are collections of factual triples , where represents a triple in the knowledge graph, are head, tail entities and relations, respectively. We associates the entities and relations r with vectors in knowledge graph embedding. Then we design an appropriate scoring function , to map the embedding of the triple to a certain score. For a particular question , the task of KG completion is ranking all possible answers and obtain the preference of prediction.
Using and to distinguish matrix representation and vector representation of the relations, respectively. T, ⟨⋅⟩ and ∘ denote the operation of transpose, the generalized dot product and the Hadamard product, respectively. Especially, we utilize to represent the matrix of relation in SeAttE. Let ∥∥, () and () denote the norm, matrix diagonalization and the real part of complex vectors.
3.2. Basic Models
Tensor Factorization Models. Models in this family interpret link prediction as a task of tensor decomposition, where triples are decomposed into a combination (e.g., a multi-linear product) of low-dimensional vectors for entities and relations. CP [34] represents triples with canonical decomposition. Note that the same entity has different representations at the head and tail of the triplet. The score function can be expressed as:
where .
RESCAL [5] represents a relation as a matrix that describes the interactions between latent representations of entities. The score function is defined as:
DistMult [6] forces all relations to be diagonal matrices, which consistently reduces the space of parameters to be learned, resulting in a much easier model to train. On the other hand, this makes the scoring function commutative, which amounts to treating all relations as symmetric.
where .
ComplEx [7] extends the real space to complex spaces and constrains the embeddings for relation to be a diagonal matrix. The bilinear product becomes a Hermitian product in complex spaces. The score function can be expressed as:
where .
4. SeAttE Model
4.1. Motivation and Design of SeAttE
4.1.1. Motivation
As shown in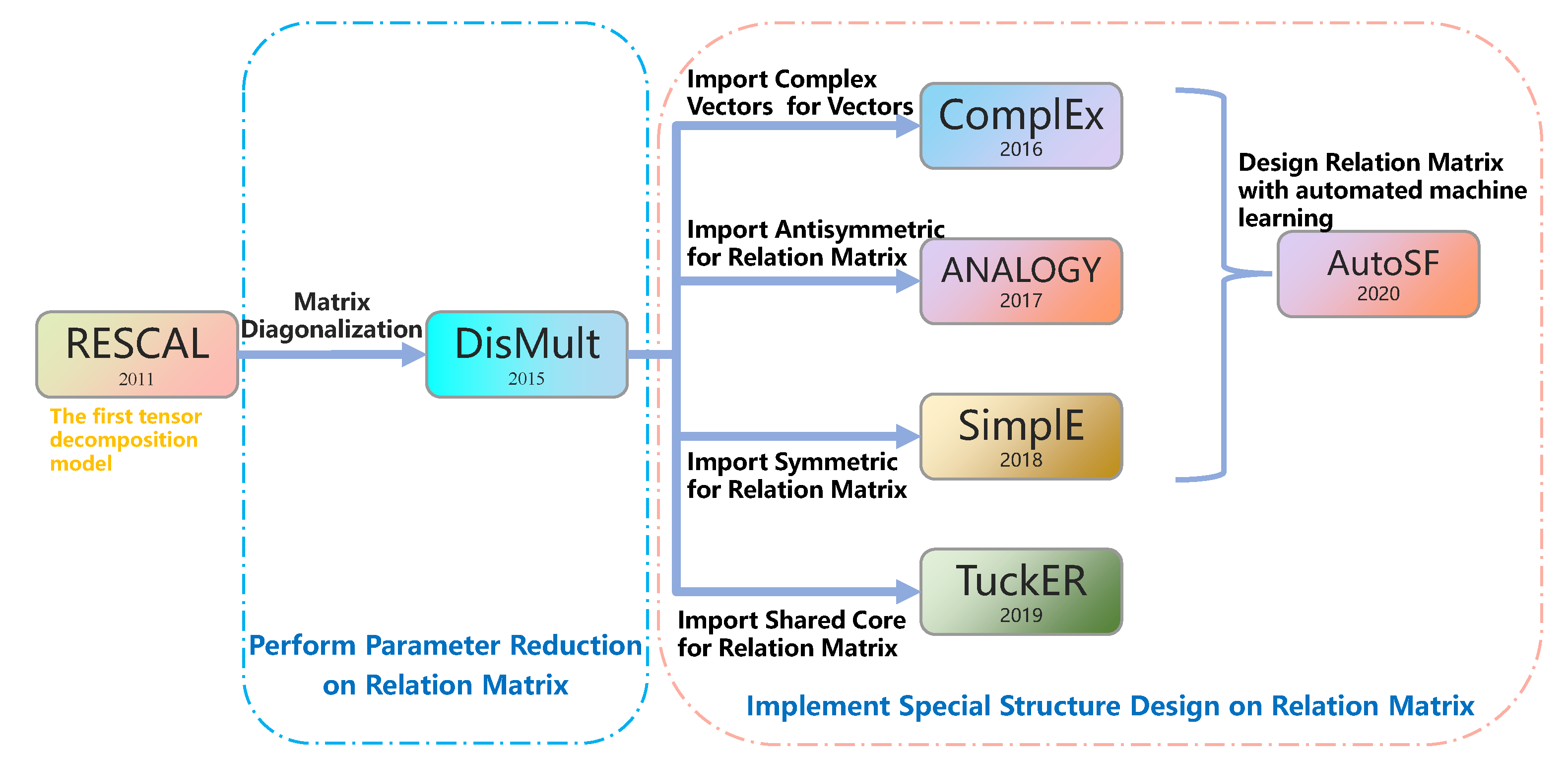
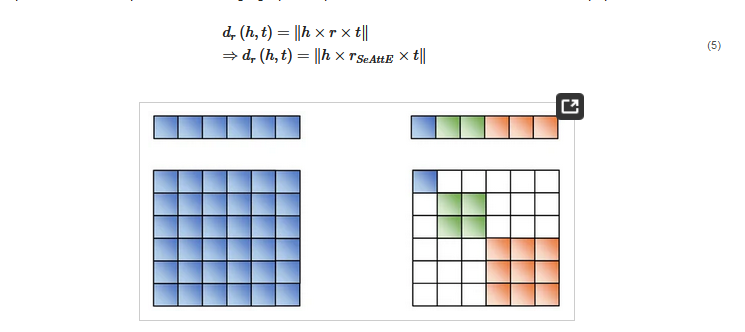
4.1.2. Design
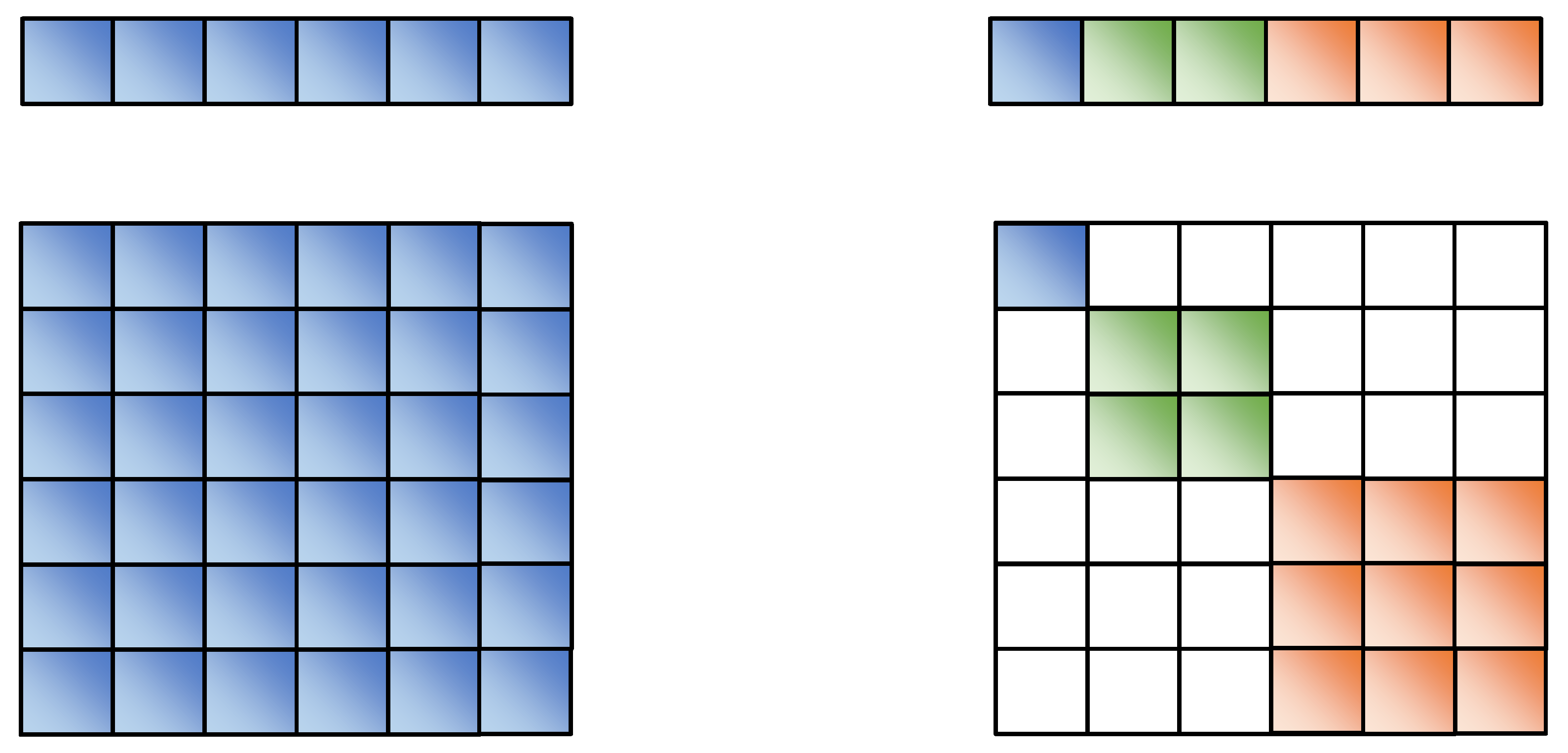
In theory, the subspace separation should be related to the actual relations, which cannot be designed in advance. We design the structure of attribute subspace segmentation to reduce the model’s workload in learning segmentation tasks of different semantic dimensions. In order to facilitate the design and implementation of the model, SeAttE adopts the exact size of attribute subspace design. Assuming that the dimension of each entity vector is d and the dimension of each attribute subspace is k, each entity contains d/k attribute spaces.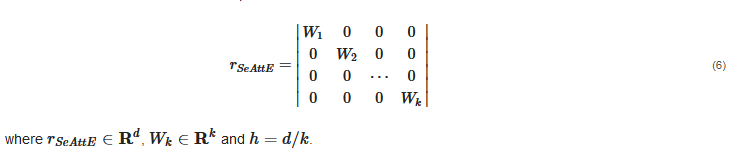 As shown in the left part of
As shown in the left part of 4.1.2. Design
In theory, the subspace separation should be related to the actual relations, which cannot be designed in advance. We design the structure of attribute subspace segmentation to reduce the model’s workload in learning segmentation tasks of different semantic dimensions. In order to facilitate the design and implementation of the model, SeAttE adopts the exact size of attribute subspace design. Assuming that the dimension of each entity vector is d and the dimension of each attribute subspace is k, each entity contains d/k attribute spaces. where and As shown in the left part of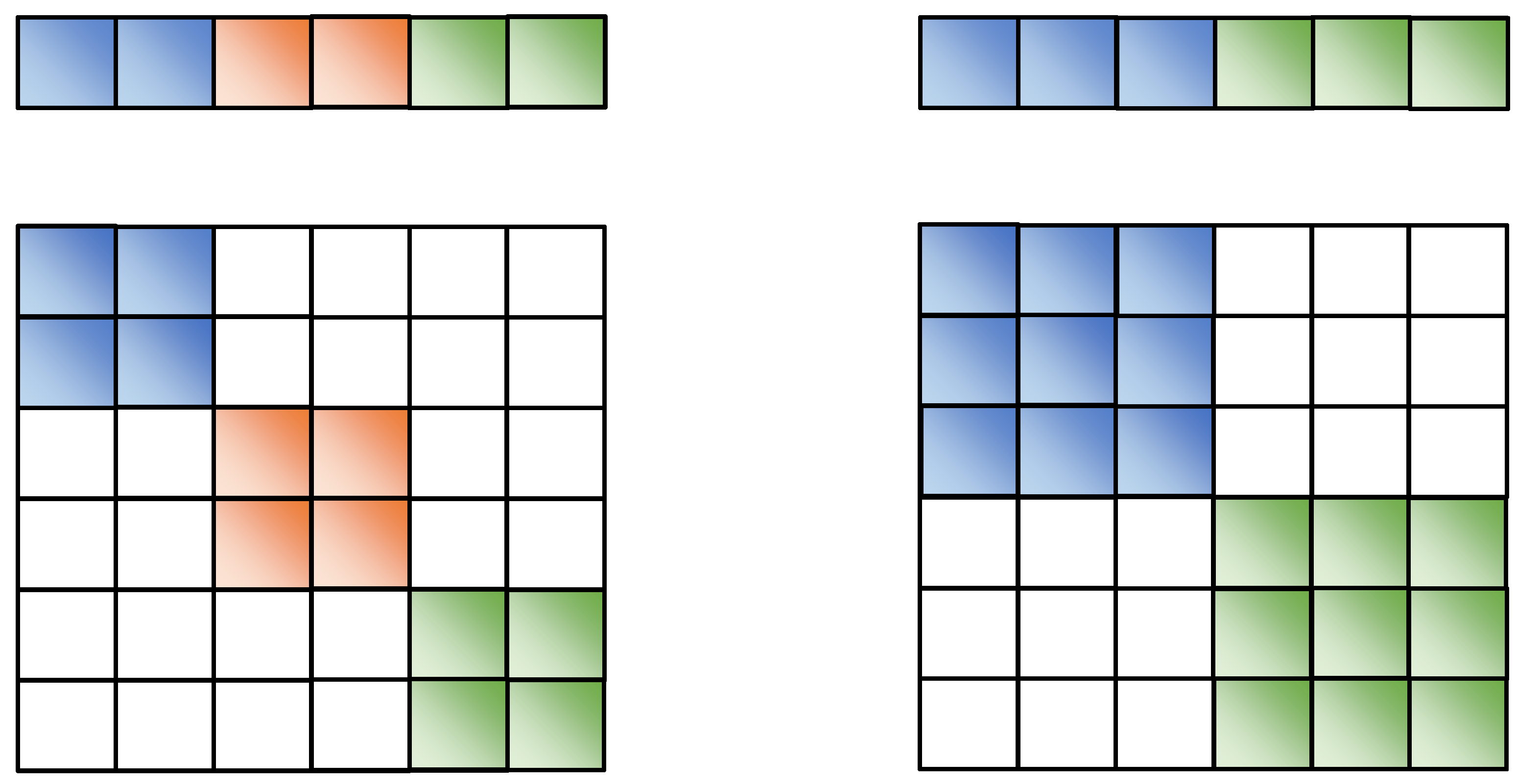
4.2. Relation to Previous Tensor Factorization Models


4.2. Relation to Previous Tensor Factorization Models
RESCAL is the basic tensor decomposition model. Due to the tremendous amount of parameters of this model, the dimension of the entity cannot be well expanded. When the dimension of the attribute subspace of SeAttE satisfies , SeAttE is equivalent to RESCAL.
where and .
DisMult is the simplest tensor decomposition model, which diagonalizes all relation matrices. When the max dimension of the attribute subspace of SeAttE k is set to 1, then is a 1-dimensional matrix, that is, a numerical value. The relationship matrix is equivalent to the diagonal. Under these circumstances, SeAttE is equivalent to DisMult.
where .
ComplEx imports complex representations to characterize symmetric and antisymmetric relations.
where and .
From the above formula, we can find that ComplEx is equivalent to RESCAL with
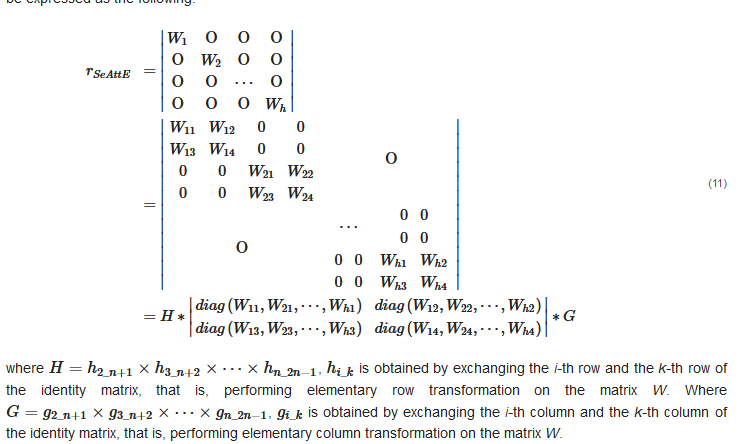
. The model performs a particular regularization for each relation matrix, which only retains the diagonal elements of the four sub-matrices of the matrix, and the remaining elements are set to 0. When the dimension of the attribute subspace of the SeAttE model k is set to 2, the relation matrix can also be expressed as the following. where is obtained by exchanging the i-th row and the k-th row of the identity matrix, that is, performing elementary row transformation on the matrix W. Where is obtained by exchanging the i-th column and the k-th column of the identity matrix, that is, performing elementary column transformation on the matrix W.