SeAttE is a novel tensor ecomposition model based on Separating Attribute space for knowledge graph completion. SeAttE is the first model among the tensor decomposition family to consider the attribute space separation task. Furthermore, SeAttE transforms the learning of too many parameters for the attribute space separation task into the structure’s design. This operation allows the model to focus on learning the semantic equivalence between relations, causing the performance to approach the theoretical limit.
- NLP
- knowledge graphs
- knowledge representation
- link prediction
- attribute space
1. Introduction
2. Related Work and Critical Differences
Tensor Decomposition Models. These models implicitly consider triples as tensor decomposition. DistMult [6] constrains all relation embeddings to be diagonal matrices, which reduces the space of parameters to access a more accessible model to train. RESCAL [5] represents each relationship with a total rank matrix. ComplEx [7] extends the KG embeddings to the complex space to better model asymmetric and inverse relations. Analogy [12] employs the general bilinear scoring function but adds two main constraints inspired by analogical structures. Based on the Tucker decomposition, TuckER [8] factorizes a tensor into a set of vectors and a smaller shared core matrix. SimplE [9] is a simple enhancement of CP to allow the two embeddings of each entity to be learned dependently. HolE [11] is a multiplicative model that is isomorphic to ComplEx [7]. Inspired by the recent success of automated machine learning (AutoML), AutoSF [10] proposes to automatically design scoring functions for distinct KGs by the AutoML techniques. QuatDE [14] captures the variety of relational patterns and separates different semantic information of the entity, using transition vectors to adjust the point position of the entity embedding vectors in the quaternion space via Hamilton product, enhancing the feature interaction capability between elements of the triplet. DensE [15] develops a novel knowledge graph embedding method to provide an improved modeling scheme for the complex composition patterns of relations. Geometric Models. Geometric Models interpret relations as geometric transformations in the latent space. TransE [1] is the first translation-based method, which treats relations as translation operations from the head entities to the tail entities. Along with TransE [1], multiple variants, including TransH [16], TransR [17] and TransD [18], are proposed to improve the embedding performance of KGs. Recently, RotatE [19] defines each relation as a rotation from head entities to tail entities. Inspired by the fact that concentric circles in the polar coordinate system can naturally reflect the hierarchy, HAKE [20] maps entities into the polar coordinate system. HAKE [20] can effectively model the semantic hierarchies in knowledge graphs. OTE [21] proposes a distance-based knowledge graph embedding. First, OTE extends the modeling of RotatE from 2D complex domain to high dimensional space with orthogonal relation transforms. Second, graph context is proposed to integrate graph structure information into the distance scoring function to measure the plausibility of the triples during training and inference. Deep Learning Models. Deep Learning Models use deep neural networks to perform knowledge graph completion. ConvE [22] and ConvKB [23] employ convolutional neural networks to define score functions. CapsE [24] embeds entities and relations into one-dimensional vectors under the basic assumption that different embeddings encode homologous aspects in the same positions. CompGCN [25] utilizes graph convolutional networks to update the knowledge graph embedding. Neural Tensor Network (NTN) combines E-MLP with several bilinear parts. Nathani [26] proposes a novel attention-based feature embedding that captures both entity and relation features in any given entity’s neighborhood. RLH [27] is inspired by the hierarchical structure through which a human being handles cognitionally ambiguous cases. The whole reasoning process is decomposed into a hierarchy of two-level Reinforcement Learning policies for encoding historical information and learning structured action space. R2D2 [28] is a novel method for automatic reasoning on knowledge graphs based on debate dynamics. R2D2 is to frame the task of triple classification as a debate game between two reinforcement learning agents which extract arguments-paths in the knowledge graph—with the goal to promote the fact being true (thesis) or the fact being false (antithesis), respectively. RNNLogic [29] is a probabilistic model. RNNLogic treats logic rules as a latent variable, and simultaneously trains a rule generator as well as a reasoning predictor with logic rules. MADLINK [30] introduces an attentive encoder–decoder-based link prediction approach considering both structural information of the KG and the textual entity descriptions. There are also other models, such as DURA [31], which are proposed to solve overfitting. RuleGuider [32] leverages high-quality rules generated by symbolic-based methods to provide reward supervision for walk-based agents. SFBR [33] provides a relation-based semantic filter to extract the attributes that need to be compared and suppress the irrelevant attributes of entities. Together, most of the above studies intend to find a more robust representing approach. Measuring the effectiveness of certain triples is to compare the matching degree of specific attributes based on relations. Only a few models, such as TransH [16], TransR [17], and TransD [18], consider that entities in different triples should have different representation. However, these variants require many resources occupations and are limited to particular models.3. Background
3.1. KG Completion and Notations
KGs are collections of factual triples , where represents a triple in the knowledge graph, are head, tail entities and relations, respectively. ScholarsWe associates the entities and relations r with vectors in knowledge graph embedding. Then scholarswe design an appropriate scoring function , to map the embedding of the triple to a certain score. For a particular question , the task of KG completion is ranking all possible answers and obtain the preference of prediction.
Using and to distinguish matrix representation and vector representation of the relations, respectively. T, ⟨⋅⟩ and ∘ denote the operation of transpose, the generalized dot product and the Hadamard product, respectively. Especially, scholarswe utilize to represent the matrix of relation in SeAttE. Let ∥∥, () and () denote the norm, matrix diagonalization and the real part of complex vectors.
3.2. Basic Models
Tensor Factorization Models. Models in this family interpret link prediction as a task of tensor decomposition, where triples are decomposed into a combination (e.g., a multi-linear product) of low-dimensional vectors for entities and relations. CP [34] represents triples with canonical decomposition. Note that the same entity has different representations at the head and tail of the triplet. The score function can be expressed as:
where .
RESCAL [5] represents a relation as a matrix that describes the interactions between latent representations of entities. The score function is defined as:
DistMult [6] forces all relations to be diagonal matrices, which consistently reduces the space of parameters to be learned, resulting in a much easier model to train. On the other hand, this makes the scoring function commutative, which amounts to treating all relations as symmetric.
where .
ComplEx [7] extends the real space to complex spaces and constrains the embeddings for relation to be a diagonal matrix. The bilinear product becomes a Hermitian product in complex spaces. The score function can be expressed as:
where .
4. SeAttE Model
4.1. Motivation and Design of SeAttE
4.1.1. Motivation
As shown in Figure 2, RESCAL is the basic tensor decomposition model. Since RESCAL represents the relations as a matrix, the large number of parameters makes it difficult for the model to learn effectively. So DisMult directly diagonalizes the matrix, significantly reducing the number of parameters. However, over-simplified models limit the performance. Subsequently, variants are invented for describing specific types of relations, such as asymmetric and hierarchical relations, which are equivalent to designing unique structures for describing specific types of relationships. Such models need to look for special functions to precisely fit different relations categories. Some relations can be well characterized in models, while some are not. This design from a specific relationship type is challenging to cover all relations. No matter how sophisticated the design of such models is, it is difficult to surpass the RESCAL model theoretically. Moreover, the previous tensor decomposition model did not consider the problem of attribute separation. The unnoticed task of attribute separation in the traditional models is just handed over to the training. However, the amount of parameters for this task is tremendous, and the model is prone to overfitting.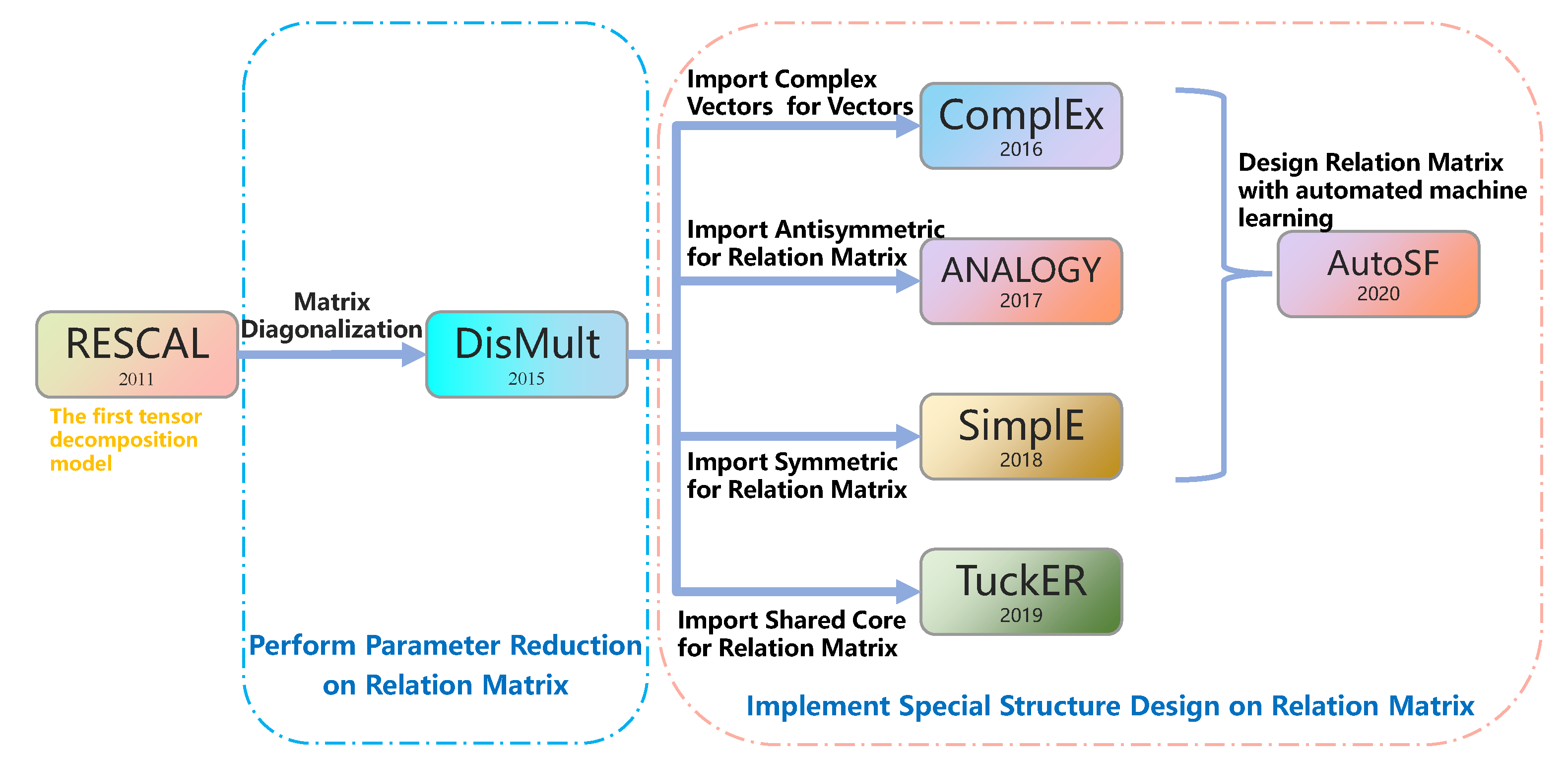
4.1.2. Design
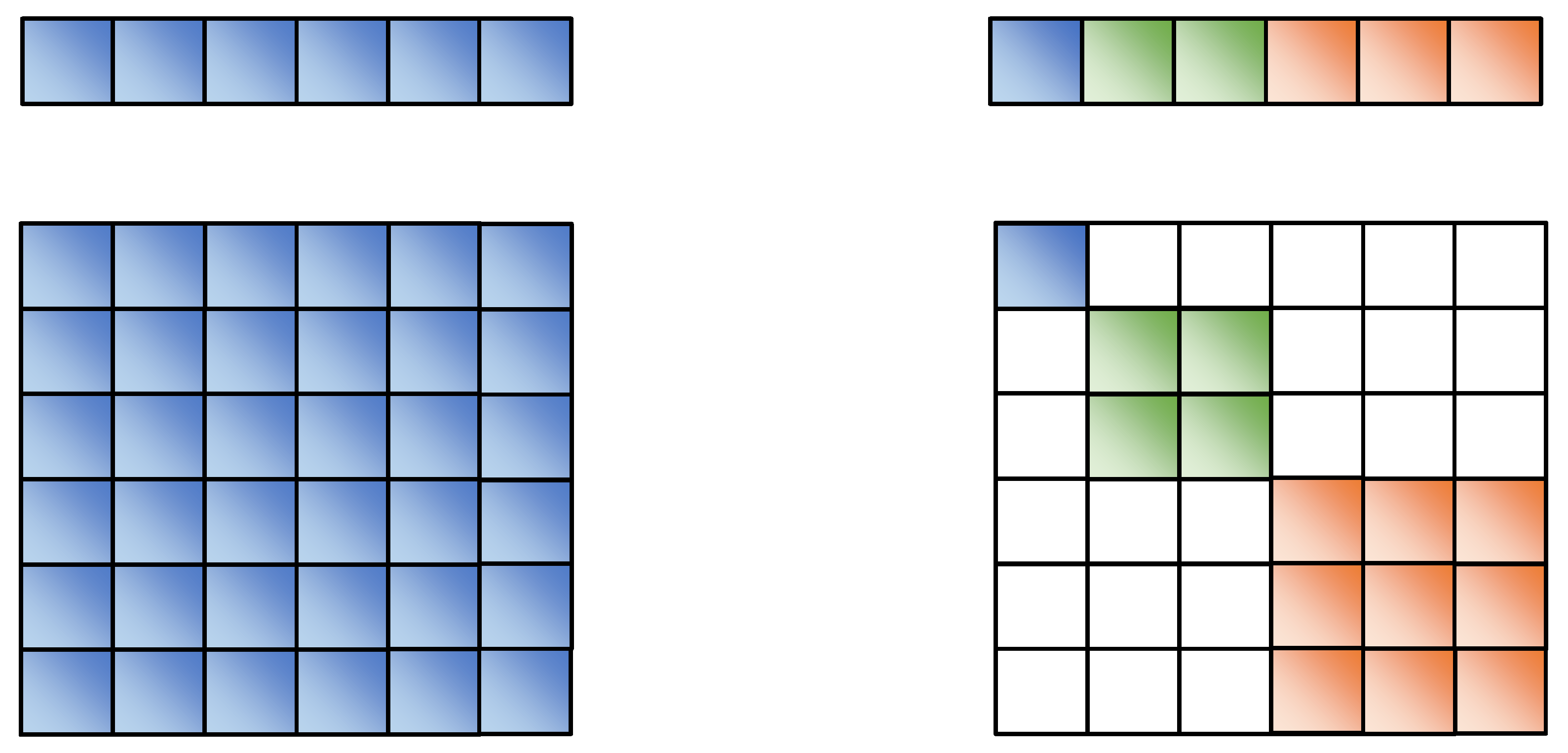
In theory, the subspace separation should be related to the actual relations, which cannot be designed in advance. ScholarsWe design the structure of attribute subspace segmentation to reduce the model’s workload in learning segmentation tasks of different semantic dimensions. In order to facilitate the design and implementation of the model, SeAttE adopts the exact size of attribute subspace design. Assuming that the dimension of each entity vector is d and the dimension of each attribute subspace is k, each entity contains d/k attribute spaces. where and As shown in the left part of Figure 4, the dimension of each entity vector d is eight, and the dimension of each attribute subspace k is two, then the entity contains four attributes subspaces. As shown in the right part of Figure 4, when the dimension of each attribute subspace d is two and the dimension of each subspace k is four, the entity contains two attributes subspaces.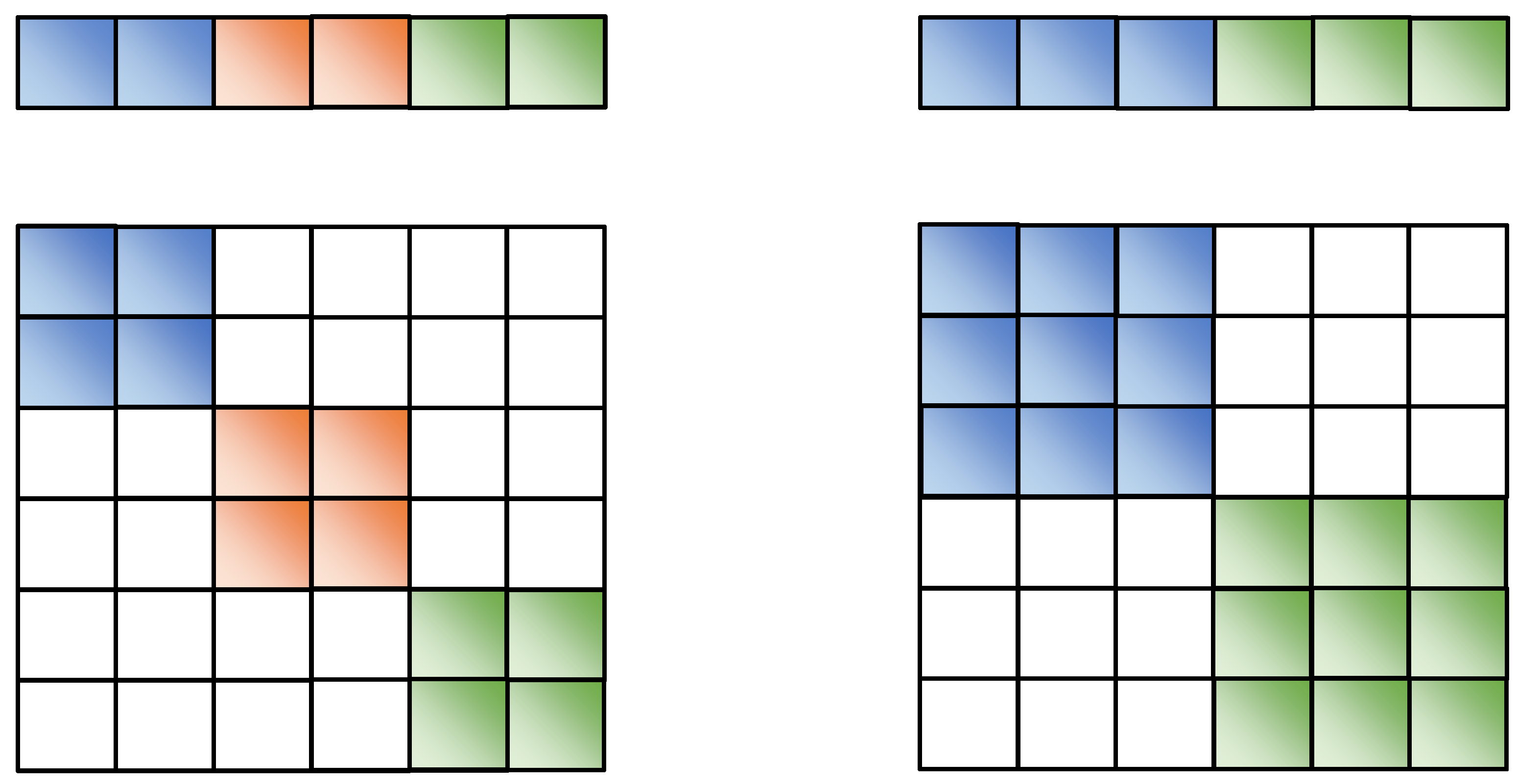
4.2. Relation to Previous Tensor Factorization Models
RESCAL is the basic tensor decomposition model. Due to the tremendous amount of parameters of this model, the dimension of the entity cannot be well expanded. When the dimension of the attribute subspace of SeAttE satisfies , SeAttE is equivalent to RESCAL.
where and .
DisMult is the simplest tensor decomposition model, which diagonalizes all relation matrices. When the max dimension of the attribute subspace of SeAttE k is set to 1, then is a 1-dimensional matrix, that is, a numerical value. The relationship matrix is equivalent to the diagonal. Under these circumstances, SeAttE is equivalent to DisMult.
where .
ComplEx imports complex representations to characterize symmetric and antisymmetric relations.
where and .
From the above formula, itwe can find that ComplEx is equivalent to RESCAL with
. The model performs a particular regularization for each relation matrix, which only retains the diagonal elements of the four sub-matrices of the matrix, and the remaining elements are set to 0. When the dimension of the attribute subspace of the SeAttE model k is set to 2, the relation matrix can also be expressed as the following. where is obtained by exchanging the i-th row and the k-th row of the identity matrix, that is, performing elementary row transformation on the matrix W. Where is obtained by exchanging the i-th column and the k-th column of the identity matrix, that is, performing elementary column transformation on the matrix W.