Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Nils Hütten | -- | 3361 | 2024-02-14 10:02:07 | | | |
| 2 | Nils Hütten | Meta information modification | 3361 | 2024-02-14 10:03:57 | | | | |
| 3 | Mona Zou | Meta information modification | 3361 | 2024-02-19 09:59:50 | | | | |
| 4 | Mona Zou | Meta information modification | 3361 | 2024-02-26 10:15:02 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Hütten, N.; Alves Gomes, M.; Hölken, F.; Andricevic, K.; Meyes, R.; Meisen, T. Deep Learning for Automated Visual Inspection. Encyclopedia. Available online: https://encyclopedia.pub/entry/55036 (accessed on 24 June 2026).
Hütten N, Alves Gomes M, Hölken F, Andricevic K, Meyes R, Meisen T. Deep Learning for Automated Visual Inspection. Encyclopedia. Available at: https://encyclopedia.pub/entry/55036. Accessed June 24, 2026.
Hütten, Nils, Miguel Alves Gomes, Florian Hölken, Karlo Andricevic, Richard Meyes, Tobias Meisen. "Deep Learning for Automated Visual Inspection" Encyclopedia, https://encyclopedia.pub/entry/55036 (accessed June 24, 2026).
Hütten, N., Alves Gomes, M., Hölken, F., Andricevic, K., Meyes, R., & Meisen, T. (2024, February 14). Deep Learning for Automated Visual Inspection. In Encyclopedia. https://encyclopedia.pub/entry/55036
Hütten, Nils, et al. "Deep Learning for Automated Visual Inspection." Encyclopedia. Web. 14 February, 2024.
Copy Citation
This article evaluates the state of the art of deep-learning-based automated visual inspection in manufacturing and maintenance applications and contrasts it to academic research in the field of computer vision. By doing so itidentifies to what extent computer vision innovations are already being used and which potential improvements could be realized by further transferring promising concepts.
Existing work is either focused on specific industry sectors or methodologies but not on industrial VI as a whole or is outdated by almost two decades. We surveyed 196 open access publications from 2010 to March 2023 from the fields of manufacturing and maintenance with no restriction regarding industries. Our main findings were:
- The vast majority of publications utilize supervised learning approaches on relatively small datasets with convolutional neural networks.
- The timegap between publication of new approaches in deep learning-based computer vision and its first application in industrial visual inspection is approximately three years
- First vision transformer models emerge in 2022 and seem to outperform established models but their excellent self-supervised learning capabilities are not explored to date
automated visual inspection
industrial applications
deep learning
computer vision
convolutional neural network
vision transformer
1. Introduction
Industrial production and maintenance are under constant pressure from increasing quality requirements due to rising product demands, changing resources, and cost specifications. In addition, there are constantly changing framework conditions due to new and changing legal requirements, standards, and norms. Ultimately, the increasing general flow of information via social media and other platforms leads to an increased risk of reputational damage from substandard products. These influences, combined with the fact that quality assurance is still predominantly performed or supported by human inspectors, have led to the need for advances in continuous quality control. Since vision is the predominant conscious sense of humans, most inspection techniques in the past and even today are of a visual nature [1]. However, manual visual inspection (VI) has several drawbacks, which have been studied, for example, by Steger et al., Sheehan et al., and Chiang et al. [2][3][4], specifically including high labor costs, low efficiency, and low real-time performance in the case of fast-moving inspection objects or large surface areas. According to Swain and Guttmann [5], minimal error rates of 10−3 can be reached for very simple accept/reject tasks. Though highly dependent on the inspection task, Drury and Fox [6] observed error rates of 20% to 30% in more complex VI tasks in their studies. In addition, decreasing efficiency and accuracy occur during human inspection due to fatigue and resulting attention deficits.
As a way to counteract these effects, automation solutions were pushed in the 1980s. The goal was to increase efficiency and performance and reduce costs while minimizing human error. Accordingly, computer vision (CV) methods were introduced to VI, which was initially only relevant for the automation of simple, monotonous tasks. In the beginning, they served more as a support for inspectors [7], but as development progressed, whole tasks were solved without human involvement. This was the beginning of automated visual inspection (AVI).
2. Requirements for Deep-Learning Models in AVI
Several requirements have to be considered when introducing DL-based AVI to a previously manual inspection process or even to an already automated process that uses classical CV methods. To answer our second question, “What are the requirements that have to be considered when applying DL-based models to AVI?”, the researchers analyzed our publication corpus with regard to requirements, with either a direct textual mention or indirect mention through evaluation procedures, as well as reported metrics. These requirements can be grouped in two dimensions: on the one hand, between general and application- or domain-specific requirements or, on the other hand, between hard technical and soft human factors. The most general technical challenge is performance, as visualized in Figure 1.
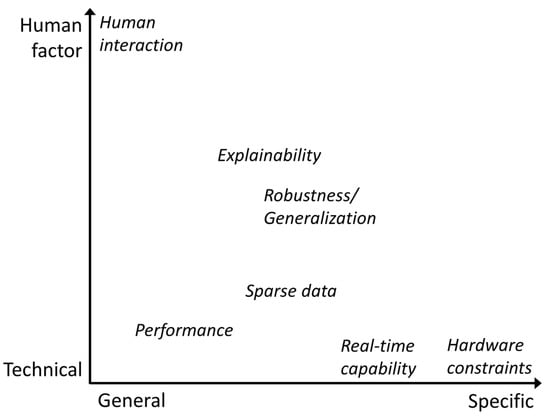
Figure 1. AVI requirements grouped by their combined properties with regard to specificity and whether they are technical-factor- or human-factor-driven.
In the case of the automation of previously manual processes, human-level performance is usually used as a reference value, which is intended to guarantee the same level of safety, as mentioned by Brandoli et al. for aircraft maintenance [8]. If the target process is already automated, the DL-based solution needs to prevail against the established solution. Performance can be measured by different metrics, as some processes are more focused on false positives (FPs), like the one investigated by Wang et al. [9], or false negatives (FNs). Therefore, it cannot be considered a purely general requirement, as it is affected by the choice of metric. Real-time capability is a strictly technical challenge, as it can be defined by the number of frames per second (FPS) a model can process but is mostly specific, as it is mainly required when inspecting manufactured goods on a conveyor belt or rails/streets from a fast-moving vehicle for maintenance [9][10][11][12]. Hardware constraints are the most specific and rare technical challenge found in our publication corpus. This usually means that the models have to run on a particular edge device, which is limited in memory, the number of floating-point operations per second (FLOPS), or even the possible computational operations it can perform [13]. Sparse (labeled) data are primarily a technical challenge, where the emphasis is put on the fact that models with more parameters generally perform better but require more data samples to optimize those parameters, as well. The labeling process introduces the human factor into this requirement because a consistent understanding of the boundary between different classes is necessary in order to produce a coherent distribution of labels with as few non-application-related inconsistencies or outliers as possible. This is especially true if there are few samples and if multiple different persons create the labels. Models need to perform well with these small labeled industrial datasets [14][15][16][17][18] or, even better, work without labeled data [19][20]. One of the key advantages of DL-based models compared to classic CV methods is their generalization capability, which makes them robust against partly hidden objects, changing lighting conditions, or new damage types. This characteristic is required for many use cases where it is not possible to enforce controlled conditions or have full visibility, such as rail track inspection [12][21][22], or it is an added benefit when a model is able to extrapolate to previously unseen damages [23]. As this requirement is not easily quantifiable and application-specific to a certain degree, the researchers place it centrally in both dimensions. Part of any industrial transformation process is the people involved, whether they are directly affected as part of the process or indirectly affected through interfaces with the process. To improve the acceptance of change processes, it is necessary to convince domain experts that they can trust the new DL solution. In addition, explainability can also be helpful from a model development perspective to determine the reason for certain model confusions that lead to errors [24].
3. Visual Inspection Use Cases
In order to answer our second guiding question, “Which AVI use cases are currently being addressed by DL models?”, the researchers examined the reviewed publications to determine whether it is possible to summarize the solved VI tasks into specific use cases. The researchers identified a hierarchy of VI use cases based on the surveyed literature, that visualized in Figure 2.
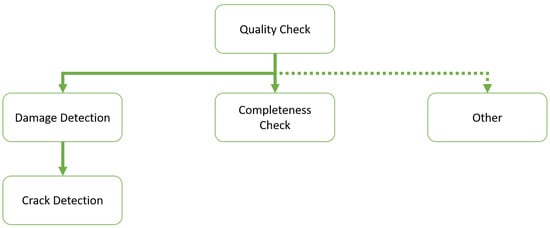
Figure 2. Hierarchical structure of top-level VI use cases based on the surveyed literature.
As previously mentioned, VI is getting more challenging due to ever-increasing quality requirements, and all use cases can be considered to be at least quality inspection. In our literature review, quality inspection use cases are those that do not detect defects or missing parts but the state of an object. For example, determining the state of woven fabrics or leather quality is a use case the researchers considered to be only quality inspection [25][26]. Damage detection, also referred to as defect detection in the literature, summarizes all VI use cases that classify or detect at least one type of damage. An example of damage detection use cases is the surface defect detection of internal combustion engine parts [27] or the segmentation of different steel surface defects [28]. Crack detection can be considered a specialization of damage detection use cases and has its own category because of its occurrence frequency in the surveyed literature. The crack detection use case deals solely with crack classification, localization, or segmentation. The application context is usually the maintenance of public buildings, for example, pavement cracks [29][30] or concrete cracks [31][32]. In addition to detecting defects, another VI use case is to check whether a part is missing or not. Completeness check summarizes these use cases. A completeness check can be the determination of whether something is missing, or to the contrary, the determination of whether something is present. O’Byrne et al. [33] proposed a method to detect barnacles on ship hulls. Another example is provided by Chandran et al. [21], who propose a DL approach to detect rail track fasteners for railway maintenance. The last VI use case class the researchers defined as other, which includes VI use cases that cannot directly be seen through only quality inspection and are not of the damage detection or completeness check type. Example use cases are plant disease detection [34][35] or type classification [36]. Figure 3 shows the distribution of the VI use cases over the investigated literature. Most publications (53.57%) deal with damage detection use cases. The second most (27.55%) researched VI use case is crack detection, followed by quality inspection (6.63%) as well as other use cases (6.63%), and the least occurring type is completeness check use cases (5.61%).
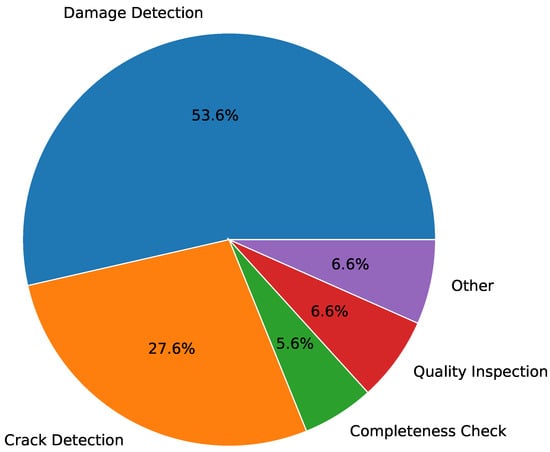
Figure 3. Distribution of reviewed publications by VI use cases.
4. Overview on How to Solve Automated Visual Inspection with Deep-Learning Models
In the following, the researchers aim to answer our third guiding question, “Are there certain recurring AVI tasks that these use cases can be categorized into?”, by investigating with which DL approach the VI use cases can be solved. For this, the researchers determined four different AVI tasks to categorize the approaches. Each of these tasks aims to answer one or more questions about the inspected object. Binary classification tries to answer the question, Is the inspected object in the desired state? This applies mainly to accept/reject tasks, like separating correctly produced parts from scrap parts, regardless of the type of deficiency. Multi-class classification goes one step further, trying to answer the question, In which state is the inspected object? By additionally identifying the type of deficiency, it is possible to, e.g., distinguish between parts that are irreparably damaged and parts that can still be reworked to pass the requirements or determine the rework steps that are necessary. Localization further answers the question, Where do the researchers find this state on the inspected object? This adds information about the locality of a state of interest, as well as enabling the finding of more than one target. It can be utilized, e.g., to check assemblies for their completeness. The fourth AVI task, multi-class localization, answers the question, Where do ind which state on the inspected object? For example, the state of a bolt can be present, missing, rusty, or cracked. Thus, the set of states is not fixed and depends, among other things, on application-specific conditions, as well as on the object under inspection.
These four AVI tasks are closely related to the three most common CV tasks, image classification, object detection, and segmentation, which are visualized in Figure 4.
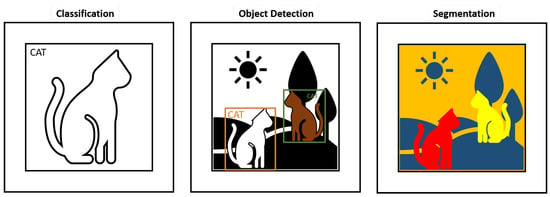
Figure 4. Visualization of the three different CV tasks—classification, object detection with two bounding boxes, and segmentation.
In image classification, the goal is to assign a corresponding label to an image. Object detection is performed by a method or model that searches for objects of interest. Usually, the object is indicated by a rectangular bounding box, and simultaneously, object classification is performed for each object. Unlike pure classification, multiple objects can be detected and classified. Image segmentation is the process of separating every recognizable object into corresponding pixel segments. This means that both classification AVI tasks are performed by image classification models, while both localization tasks are performed by either an object detection model or a segmentation model.
Figure 5 shows the composition of our publication corpus with regard to the application context, industry sector, and AVI task.
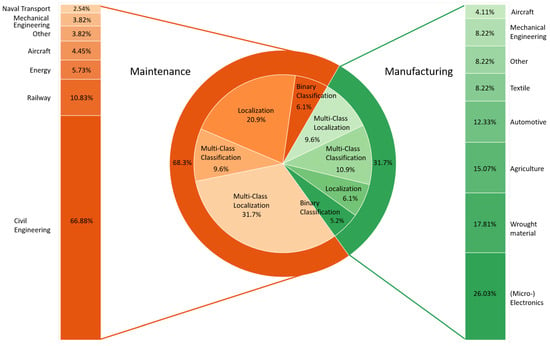
Figure 5. Distribution of reviewed publications by inspection context, VI task, and associated industrial sector.
The number of papers in the maintenance context outweigh those addressing manufacturing by two to one, as depicted by the outer pie chart in the center. Each of those contexts is associated with several different industrial sectors in which AVI is applied. The share of the industry sectors in each context is plotted on the left- and right-hand sides. The biggest shares in maintenance are held by the fields of civil engineering, railway, energy, and aircraft. These sum up to a total of 87.89% of all maintenance publications. The manufacturing sectors, (micro-) electronics, wrought material, agriculture, automotive, and textiles, add up to a total of 79.46% of all manufacturing papers. In addition to the industry sectors, the researchers also group the applications per context by the AVI task. The distribution of VI tasks for each industry context is visualized by the inner pie chart. For maintenance applications, 77.01% of their total 68.3% is covered by basic and multi-class localization tasks. Only 15.7% of the tasks can be attributed to classification tasks. In manufacturing, the VI tasks are spread across 16.1% classification and 15.7% localization publications. The multi-class variants are clearly more frequent for both, with 9.6% for localization and 10.9% for classification.
In the following subsections, one for each AVI task, the researchers investigate the collected literature and utilized models. Only the best-performing architecture is mentioned if multiple are utilized. Models that are derived from established base architectures like Residual Networks (ResNet) [37] are still considered to belong to that architecture family unless they are combined or stacked with another architecture. The researchers also subsumed all versions of the “you only look once” (YOLO) architecture [38] under YOLO. Models that are custom designs of the authors and not based on any established architectures are subsumed under the categories multi-layer perceptron (MLP), convolutional neural network (CNN), or Transformer based on their main underlying mechanisms.
4.1. Visual Inspection via Binary Classification
In the surveyed literature, 21 publications describe a way to approach AVI with binary image classification; these are summarized in Table 1. Following the general trend of VI use cases, damage detection is addressed ten times with binary classification.
Adibhatla et al. [20] used a ResNet, Selmaier et al. [16] used an Xception architecture, and Jian et al. [39] used a DenseNet to classify whether damage is visible or not. Crack detection is addressed seven times with binary classification. In four publications, the authors propose a CNN architecture for AVI crack detection. In the other two publications, crack detection was performed with an AlexNet or a Visual geometry group model (VGG). Ali et al. [40] proposed a sliding window vision transformer (ViT) as a binary classifier for crack detection in pavement structures. Binary classification is also utilized for completeness checks and plant disease detection (other). For plant disease detection, Ahmad et al. [34] used an MLP, while O’Byrne et al. [33] used a custom CNN for a completeness check use case.
Table 1. Overview of VI use cases and models that solve these problems via binary classification.
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [41] |
| CNN | 4 | [42][43][44][45] | |
| VGG | 1 | [46] | |
| ViT | 1 | [40] | |
| Damage Detection | AlexNet | 1 | [47] |
| CNN | 1 | [48] | |
| DenseNet | 3 | [8][39][49] | |
| Ensemble | 1 | [50] | |
| MLP | 1 | [51] | |
| ResNet | 1 | [20] | |
| SVM | 1 | [52] | |
| Xception | 1 | [16] | |
| Quality Inspection | AlexNet | 1 | [53] |
| MLP | 1 | [54] | |
| Other | MLP | 1 | [34] |
| Completeness Check | CNN | 1 | [33] |
4.2. Visual Inspection via Multi-Class Classification
Table 2 presents an overview of 42 publications that solve various use cases of AVI through multi-class classification and the models that are used to solve them. The models used to solve these use cases include popular DL architectures such as AlexNet, CNN, DenseNet, EfficientNet, GAN, MLP, MobileNet, ResNet, single-shot detector (SSD), and VGG. Twenty-one publications describe approaches for damage detection, of which six approaches are based on custom CNNs. The other four authors used ResNet-based architectures. Kumar et al. [55] proposed an MLP architecture to perform damage detection. Also, an EfficientNet and a single-shot detector (SSD) were employed for multi-class damage detection. Five publications cover crack detection use cases. For example, Alqahtani [56] used a CNN, and Elhariri et al. [57] as well as Kim et al. [58] used a VGG. Also, DL models like ResNet, DenseNet, and an ensemble architecture are proposed by some authors. Completeness checks were performed with the help of a ResNet by Chandran et al. [21] or an SSD, as shown by Yang et al. [59]. In seven publications, the authors used custom CNNs, DenseNet, ResNet, or VGG in quality inspection use cases. Also, other use cases can be addressed by different DL-based CV models or MLPs.
Table 2. Overview of VI use cases and models that solve these use cases via multi-class classification.
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [60] |
| CNN | 1 | [56] | |
| EfficientNet | 1 | [61] | |
| ResNet | 1 | [62] | |
| VGG | 2 | [57][58] | |
| Damage Detection | AlexNet | 1 | [63] |
| CNN | 6 | [36][64][65][66][67][68] | |
| CNN LSTM | 1 | [69] | |
| EfficientNet | 2 | [70][71] | |
| Ensemble | 1 | [26] | |
| GAN | 2 | [72][73] | |
| MLP | 1 | [55] | |
| MobileNet | 1 | [74] | |
| ResNet | 4 | [75][76][77][78] | |
| VGG | 2 | [30][79] | |
| Completeness Check | ResNet | 1 | [21] |
| SSD | 1 | [59] | |
| Quality Inspection | CNN | 3 | [80][81][82] |
| DenseNet | 1 | [83] | |
| ResNet | 2 | [25][84] | |
| VGG | 1 | [85] | |
| Other | CNN | 1 | [35] |
| EfficientNet | 1 | [86] | |
| MLP | 1 | [87] | |
| MobileNet | 1 | [88] | |
| ResNet | 1 | [24] | |
| VGG | 1 | [89] |
4.3. Visual Inspection via Localization
As previously mentioned, localization is used to detect where an object of interest is located. Table 3 summarizes which VI use cases are addressed with localization and the appropriate models. In a total of 50 publications, localization was employed for AVI. Contrary to classification approaches, crack detection is the most addressed VI use case, with a total of 26 publications investigating it. The most utilized approach for crack detection is the CNN, which was applied in eight publications. Furthermore, in three other publications, extended CNN architectures were used. Kang et al. [90] introduced a CNN with an attention mechanism, and Yuan et al. [91] used a CNN with an encoder–decoder architecture. Andrushia et al. [92] combined a CNN with a long short-term memory cell (LSTM) to process the images recurrently for crack detection. Among custom CNN approaches, six authors used UNet to detect cracks, mostly in public constructions. Damage detection via localization occurred 16 times and was addressed with at least twelve different DL-based models. Three authors decided to approach it with DL-based models of the Transformer family. For example, Wan et al. [93] utilized a Swin-Transformer to localize damages on rail surfaces. Completeness checks can be executed with YOLO and/or regional convolutional neural networks (RCNNs). Furthermore, YOLO can be used for vibration estimation, as shown by Su et al. [94]. Oishi et al. [95] proposed a Faster RCNN to localize abnormalities on potato plants.
Table 3. Overview of VI use cases and models that solve these use cases via localization.
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | CNN | 8 | [17][29][32][96][97][98][99][100] |
| CNN LSTM | 1 | [92] | |
| Attention CNN | 1 | [90] | |
| Custom encoder–decoder CNN | 1 | [91] | |
| DeepLab | 3 | [101][102][103] | |
| Ensemble | 3 | [104][105][106] | |
| Fully convolutional network (FCN) | 2 | [107][108] | |
| Faster RCNN | 1 | [109] | |
| UNet | 6 | [110][111][112][113][114][115] | |
| Damage Detection | DenseNet | 1 | [116] |
| Faster RCNN | 1 | [117] | |
| GAN | 1 | [118] | |
| Mask RCNN | 2 | [119][120] | |
| ResNet | 1 | [18] | |
| SSD | 1 | [121] | |
| Swin | 1 | [93] | |
| Transformer | 1 | [122] | |
| UNet | 3 | [123][124][125] | |
| VAE | 1 | [19] | |
| ViT | 1 | [126] | |
| YOLO | 2 | [127][128] | |
| Completeness Check | Mask RCNN | 1 | [129] |
| YOLO | 1 | [130] | |
| Quality Inspection | YOLO | 1 | [131] |
| Other | Faster RCNN | 1 | [95] |
| UNet | 2 | [14][132] | |
| YOLO | 2 | [94][133] |
4.4. Visual Inspection via Multi-Class Localization
The majority of the literature reviewed used multi-class localization for VI. In 83 publications, it is shown how to approach different use cases, like crack or damage detection, with multi-class localization. Table 4 provides a detailed overview. As for the two classification approaches, damage detection is the most investigated VI use case, with 58 publications. Therein, YOLO and Faster RCNNs are the two most used models, with over ten publications. They are followed by CNNs and Mask RCNN models, which are utilized more than five times. FCN, SSD, and UNet can also be used as approaches to multi-class damage detection. Huetten et al. [134] conducted a comparative study of several CNN models highly utilized in AVI and three vision transformer models, namely, detection transformer (DETR), deformable detection transformer (DDETR), and Retina-Swin, on three different damage detection use cases on freight cars. Multi-class localization was used in 15 publications for crack detection. In five publications, the authors performed crack detection with a YOLO model. Crack detection can also be performed with AlexNet, DeepLab, FCN, Mask RCNN, and UNet, which was shown in different publications. In three different publications, the authors show how to conduct quality inspection with YOLO. YOLO can be used in a tobacco use case, as well (other), as shown by Wang et al. [135].
Table 4. Overview of VI use cases and models that solve these use cases via multi-class localization.
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [136] |
| DeepLab | 2 | [31][137] | |
| FCN | 1 | [138] | |
| Mask RCNN | 5 | [139][140][141][142][143] | |
| UNet | 1 | [144] | |
| YOLO | 5 | [145][146][147][148][149] | |
| Damage Detection | CNN | 7 | [150][151][152][153][154][155][156] |
| DETR | 1 | [157] | |
| EfficientNet | 1 | [158] | |
| FCN | 3 | [159][160][161] | |
| FCOS | 1 | [162] | |
| Faster RCNN | 10 | [163][164][165][166][167][168][169][170][171][172] | |
| Mask RCNN | 6 | [23][173][174][175][176][177] | |
| MobileNet | 1 | [9] | |
| RCNN | 1 | [15] | |
| SSD | 5 | [178][179][180][181][182] | |
| Swin | 1 | [134] | |
| UNet | 4 | [28][183][184][185] | |
| VGG | 1 | [186] | |
| YOLO | 16 | [11][27][187][188][189][190][191][192][193][194][195][196][197][198][199][200] | |
| Completeness Check | CNN | 1 | [201] |
| Ensemble | 1 | [202] | |
| Faster RCNN | 2 | [203][204] | |
| YOLO | 2 | [12][22] | |
| Quality Inspection | YOLO | 3 | [10][205][206] |
| Other | YOLO | 1 | [135] |
References
- Drury, C.G.; Watson, J. Good practices in visual inspection. In Human Factors in Aviation Maintenance-Phase Nine, Progress Report, FAA/Human Factors in Aviation Maintenance; 2002.
- Steger, C.; Ulrich, M.; Wiedemann, C. Machine Vision Algorithms and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2018.
- Sheehan, J.J.; Drury, C.G. The analysis of industrial inspection. Appl. Ergon. 1971, 2, 74–78.
- Chiang, H.Q.; Hwang, S.L. Human performance in visual inspection and defect diagnosis tasks: A case study. Int. J. Ind. Ergon. 1988, 2, 235–241.
- Swain, A.D.; Guttmann, H.E. Handbook of Human-Reliability Analysis with Emphasis on Nuclear Power Plant Applications, Final Report; Sandia National Lab.: Albuquerque, NM, USA, 1983.
- Drury, C.; Fox, J. The imperfect inspector. Human Reliability in Quality Control; Taylor & Francis: London, UK, 1975; pp. 11–16.
- Jiang, X.; Gramopadhye, A.K.; Melloy, B.J.; Grimes, L.W. Evaluation of best system performance: Human, automated, and hybrid inspection systems. Hum. Factors Ergon. Manuf. Serv. Ind. 2003, 13, 137–152.
- Brandoli, B.; de Geus, A.R.; Souza, J.R.; Spadon, G.; Soares, A.; Rodrigues, J.F., Jr.; Komorowski, J.; Matwin, S. Aircraft Fuselage Corrosion Detection Using Artificial Intelligence. Sensors 2021, 21, 4026.
- Wang, Z.; Gao, J.; Zeng, Q.; Sun, Y. Multitype Damage Detection of Container Using CNN Based on Transfer Learning. Math. Probl. Eng. 2021, 2021, 5395494.
- Chen, Y.W.; Shiu, J.M. An implementation of YOLO-family algorithms in classifying the product quality for the acrylonitrile butadiene styrene metallization. Int. J. Adv. Manuf. Technol. 2022, 119, 8257–8269.
- Zhang, M.; Zhang, Y.; Zhou, M.; Jiang, K.; Shi, H.; Yu, Y.; Hao, N. Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt. Appl. Sci. 2021, 11, 7282.
- Wei, X.; Wei, D.; Da, S.; Jia, L.; Li, Y. Multi-Target Defect Identification for Railway Track Line Based on Image Processing and Improved YOLOv3 Model. IEEE Access 2020, 8, 61973–61988.
- Kin, N.W.; Asaari, M.S.M.; Rosdi, B.A.; Akbar, M.F. Fpga Implementation of CNN for Defect Classification on CMP Ring. J. Teknol.-Sci. Eng. 2021, 83, 101–108.
- Smith, A.G.; Petersen, J.; Selvan, R.; Rasmussen, C.R. Segmentation of roots in soil with U-Net. Plant Methods 2020, 16, 1.
- Kuric, I.; Klarak, J.; Bulej, V.; Saga, M.; Kandera, M.; Hajducik, A.; Tucki, K. Approach to Automated Visual Inspection of Objects Based on Artificial Intelligence. Appl. Sci. 2022, 12, 864.
- Selmaier, A.; Kunz, D.; Kisskalt, D.; Benaziz, M.; Fuerst, J.; Franke, J. Artificial Intelligence-Based Assistance System for Visual Inspection of X-ray Scatter Grids. Sensors 2022, 22, 811.
- Fan, Z.; Li, C.; Chen, Y.; Wei, J.; Loprencipe, G.; Chen, X.; Di Mascio, P. Automatic Crack Detection on Road Pavements Using Encoder-Decoder Architecture. Materials 2020, 13, 2960.
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity. Sensors 2018, 18, 209.
- Ulger, F.; Yuksel, S.E.; Yilmaz, A. Anomaly Detection for Solder Joints Using beta-VAE. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 2214–2221.
- Adibhatla, V.A.; Huang, Y.C.; Chang, M.C.; Kuo, H.C.; Utekar, A.; Chih, H.C.; Abbod, M.F.; Shieh, J.S. Unsupervised Anomaly Detection in Printed Circuit Boards through Student-Teacher Feature Pyramid Matching. Electronics 2021, 10, 3177.
- Chandran, P.; Asber, J.; Thiery, F.; Odelius, J.; Rantatalo, M. An Investigation of Railway Fastener Detection Using Image Processing and Augmented Deep Learning. Sustainability 2021, 13, 12051.
- Wang, T.; Yang, F.; Tsui, K.L. Real-Time Detection of Railway Track Component via One-Stage Deep Learning Networks. Sensors 2020, 20, 4325.
- Ferguson, M.; Ronay, A.; Lee, Y.T.T.; Law, K.H. Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning. Smart Sustain. Manuf. Syst. 2018, 2, 137–164.
- Wang, P.; Tseng, H.W.; Chen, T.C.; Hsia, C.H. Deep Convolutional Neural Network for Coffee Bean Inspection. Sens. Mater. 2021, 33, 2299–2310.
- Hussain, M.A.I.; Khan, B.; Wang, Z.; Ding, S. Woven Fabric Pattern Recognition and Classification Based on Deep Convolutional Neural Networks. Electronics 2020, 9, 1048.
- Aslam, M.; Khan, T.M.; Naqvi, S.S.; Holmes, G.; Naffa, R. Ensemble Convolutional Neural Networks With Knowledge Transfer for Leather Defect Classification in Industrial Settings. IEEE Access 2020, 8, 198600–198614.
- Chen, Y.; Fu, Q.; Wang, G. Surface Defect Detection of Nonburr Cylinder Liner Based on Improved YOLOv4. Mob. Inf. Syst. 2021, 2021.
- Neven, R.; Goedeme, T. A Multi-Branch U-Net for Steel Surface Defect Type and Severity Segmentation. Metals 2021, 11, 870.
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573.
- Samma, H.; Suandi, S.A.; Ismail, N.A.; Sulaiman, S.; Ping, L.L. Evolving Pre-Trained CNN Using Two-Layers Optimizer for Road Damage Detection From Drone Images. IEEE Access 2021, 9, 158215–158226.
- Sun, Y.; Yang, Y.; Yao, G.; Wei, F.; Wong, M. Autonomous Crack and Bughole Detection for Concrete Surface Image Based on Deep Learning. IEEE Access 2021, 9, 85709–85720.
- Wang, D.; Cheng, J.; Cai, H. Detection Based on Crack Key Point and Deep Convolutional Neural Network. Appl. Sci. 2021, 11, 11321.
- O’Byrne, M.; Ghosh, B.; Schoefs, F.; Pakrashi, V. Applications of Virtual Data in Subsea Inspections. J. Mar. Sci. Eng. 2020, 8, 328.
- Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf Image-Based Plant Disease Identification Using Color and Texture Features. Wirel. Pers. Commun. 2021, 121, 1139–1168.
- Velasquez, D.; Sanchez, A.; Sarmiento, S.; Toro, M.; Maiza, M.; Sierra, B. A Method for Detecting Coffee Leaf Rust through Wireless Sensor Networks, Remote Sensing, and Deep Learning: Case Study of the Caturra Variety in Colombia. Appl. Sci. 2020, 10, 697.
- Pagani, L.; Parenti, P.; Cataldo, S.; Scott, P.J.; Annoni, M. Indirect cutting tool wear classification using deep learning and chip colour analysis. Int. J. Adv. Manuf. Technol. 2020, 111, 1099–1114.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016.
- Jian, B.l.; Hung, J.P.; Wang, C.C.; Liu, C.C. Deep Learning Model for Determining Defects of Vision Inspection Machine Using Only a Few Samples. Sens. Mater. 2020, 32, 4217–4231.
- Ali, L.; Jassmi, H.A.; Khan, W.; Alnajjar, F. Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures. Buildings 2023, 13, 55.
- Rajadurai, R.S.; Kang, S.T. Automated Vision-Based Crack Detection on Concrete Surfaces Using Deep Learning. Appl. Sci. 2021, 11, 5229.
- Hallee, M.J.; Napolitano, R.K.; Reinhart, W.F.; Glisic, B. Crack Detection in Images of Masonry Using CNNs. Sensors 2021, 21, 4929.
- Mohammed, M.A.; Han, Z.; Li, Y. Exploring the Detection Accuracy of Concrete Cracks Using Various CNN Models. Adv. Mater. Sci. Eng. 2021, 2021, 9923704.
- Stephen, O.; Maduh, U.J.; Sain, M. A Machine Learning Method for Detection of Surface Defects on Ceramic Tiles Using Convolutional Neural Networks. Electronics 2022, 11, 55.
- Chaiyasarn, K.; Sharma, M.; Ali, L.; Khan, W.; Poovarodom, N. Crack detection in historical structures based on convolutional neural network. Int. J. Geomate 2018, 15, 240–251.
- Ali, L.; Alnajjar, F.; Al Jassmi, H.; Gocho, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688.
- Santos, R.; Ribeiro, D.; Lopes, P.; Cabral, R.; Calcada, R. Detection of exposed steel rebars based on deep-learning techniques and unmanned aerial vehicles. Autom. Constr. 2022, 139, 104324.
- Woo, J.; Lee, H. Nonlinear and Dotted Defect Detection with CNN for Multi-Vision-Based Mask Inspection. Sensors 2022, 22, 8945.
- Avdelidis, N.P.; Tsourdos, A.; Lafiosca, P.; Plaster, R.; Plaster, A.; Droznika, M. Defects Recognition Algorithm Development from Visual UAV Inspections. Sensors 2022, 22, 4682.
- Stephen, O.; Madanian, S.; Nguyen, M. A Hard Voting Policy-Driven Deep Learning Architectural Ensemble Strategy for Industrial Products Defect Recognition and Classification. Sensors 2022, 22, 7846.
- Ortiz, A.; Bonnin-Pascual, F.; Garcia-Fidalgo, E.; Company-Corcoles, J.P. Vision-Based Corrosion Detection Assisted by a Micro-Aerial Vehicle in a Vessel Inspection Application. Sensors 2016, 16, 2118.
- Jin, W.W.; Chen, G.H.; Chen, Z.; Sun, Y.L.; Ni, J.; Huang, H.; Ip, W.H.; Yung, K.L. Road Pavement Damage Detection Based on Local Minimum of Grayscale and Feature Fusion. Appl. Sci. 2022, 12, 13006.
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805.
- Walther, D.; Schmidt, L.; Schricker, K.; Junger, C.; Bergmann, J.P.; Notni, G.; Maeder, P. Automatic detection and prediction of discontinuities in laser beam butt welding utilizing deep learning. J. Adv. Join. Processes 2022, 6, 100119.
- Kumar, G.S.; Natarajan, U.; Ananthan, S.S. Vision inspection system for the identification and classification of defects in MIG welding joints. Int. J. Adv. Manuf. Technol. 2012, 61, 923–933.
- Alqahtani, H.; Bharadwaj, S.; Ray, A. Classification of fatigue crack damage in polycrystalline alloy structures using convolutional neural networks. Eng. Fail. Anal. 2021, 119, 104908.
- Elhariri, E.; El-Bendary, N.; Taie, S.A. Using Hybrid Filter-Wrapper Feature Selection With Multi-Objective Improved-Salp Optimization for Crack Severity Recognition. IEEE Access 2020, 8, 84290–84315.
- Kim, B.; Choi, S.W.; Hu, G.; Lee, D.E.; Juan, R.O.S. An Automated Image-Based Multivariant Concrete Defect Recognition Using a Convolutional Neural Network with an Integrated Pooling Module. Sensors 2022, 22, 3118.
- Yang, J.; Li, S.; Wang, Z.; Yang, G. Real-Time Tiny Part Defect Detection System in Manufacturing Using Deep Learning. IEEE Access 2019, 7, 89278–89291.
- Dang, X.; Shang, X.; Hao, Z.; Su, L. Collaborative Road Damage Classification and Recognition Based on Edge Computing. Electronics 2022, 11, 3304.
- Alqethami, S.; Alghamdi, S.; Alsubait, T.; Alhakami, H. RoadNet: Efficient Model to Detect and Classify Road Damages. Appl. Sci. 2022, 12, 11529.
- Chandra, S.; AlMansoor, K.; Chen, C.; Shi, Y.; Seo, H. Deep Learning Based Infrared Thermal Image Analysis of Complex Pavement Defect Conditions Considering Seasonal Effect. Sensors 2022, 22, 9365.
- Wang, D.; Xu, Y.; Duan, B.; Wang, Y.; Song, M.; Yu, H.; Liu, H. Intelligent Recognition Model of Hot Rolling Strip Edge Defects Based on Deep Learning. Metals 2021, 11, 223.
- Schlosser, T.; Friedrich, M.; Beuth, F.; Kowerko, D. Improving automated visual fault inspection for semiconductor manufacturing using a hybrid multistage system of deep neural networks. J. Intell. Manuf. 2022, 33, 1099–1123.
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Convolutional sparse coding-based deep random vector functional link network for distress classification of road structures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 654–676.
- Ahmad, A.; Jin, Y.; Zhu, C.; Javed, I.; Maqsood, A.; Akram, M.W. Photovoltaic cell defect classification using convolutional neural network and support vector machine. IET Renew. Power Gener. 2020, 14, 2693–2702.
- Shin, H.K.; Ahn, Y.H.; Lee, S.H.; Kim, H.Y. Automatic Concrete Damage Recognition Using Multi-Level Attention Convolutional Neural Network. Materials 2020, 13, 5549.
- Dunphy, K.; Fekri, M.N.; Grolinger, K.; Sadhu, A. Data Augmentation for Deep-Learning-Based Multiclass Structural Damage Detection Using Limited Information. Sensors 2022, 22, 6193.
- Stephen, O.; Madanian, S.; Nguyen, M. A Robust Deep Learning Ensemble-Driven Model for Defect and Non-Defect Recognition and Classification Using a Weighted Averaging Sequence-Based Meta-Learning Ensembler. Sensors 2022, 22, 9971.
- Chen, C.; Chandra, S.; Han, Y.; Seo, H. Deep Learning-Based Thermal Image Analysis for Pavement Defect Detection and Classification Considering Complex Pavement Conditions. Remote Sens. 2022, 14, 106.
- Nagy, A.M.; Czuni, L. Classification and Fast Few-Shot Learning of Steel Surface Defects with Randomized Network. Appl. Sci. 2022, 12, 3967.
- Dunphy, K.; Sadhu, A.; Wang, J. Multiclass damage detection in concrete structures using a transfer learning-based generative adversarial networks. Struct. Control Health Monit. 2022, 29.
- Guo, X.; Liu, X.; Krolczyk, G.; Sulowicz, M.; Glowacz, A.; Gardoni, P.; Li, Z. Damage Detection for Conveyor Belt Surface Based on Conditional Cycle Generative Adversarial Network. Sensors 2022, 22, 3485.
- Ogunjinmi, P.D.; Park, S.S.; Kim, B.; Lee, D.E. Rapid Post-Earthquake Structural Damage Assessment Using Convolutional Neural Networks and Transfer Learning. Sensors 2022, 22, 3471.
- Chen, H.C. Automated Detection and Classification of Defective and Abnormal Dies in Wafer Images. Appl. Sci. 2020, 10, 3423.
- Wu, X.; Xu, H.; Wei, X.; Wu, Q.; Zhang, W.; Han, X. Damage Identification of Low Emissivity Coating Based on Convolution Neural Network. IEEE Access 2020, 8, 156792–156800.
- Stamoulakatos, A.; Cardona, J.; McCaig, C.; Murray, D.; Filius, H.; Atkinson, R.; Bellekens, X.; Michie, C.; Andonovic, I.; Lazaridis, P.; et al. Automatic Annotation of Subsea Pipelines Using Deep Learning. Sensors 2020, 20, 674.
- Konovalenko, I.; Maruschak, P.; Brevus, V.; Prentkovskis, O. Recognition of Scratches and Abrasions on Metal Surfaces Using a Classifier Based on a Convolutional Neural Network. Metals 2021, 11, 549.
- Xiang, S.; Jiang, S.; Liu, X.; Zhang, T.; Yu, L. Spiking VGG7: Deep Convolutional Spiking Neural Network with Direct Training for Object Recognition. Electronics 2022, 11, 2097.
- Meister, S.; Wermes, M.; Stueve, J.; Groves, R.M. Cross-evaluation of a parallel operating SVM-CNN classifier for reliable internal decision-making processes in composite inspection. J. Manuf. Syst. 2021, 60, 620–639.
- Meister, S.; Moeller, N.; Stueve, J.; Groves, R.M. Synthetic image data augmentation for fibre layup inspection processes: Techniques to enhance the data set. J. Intell. Manuf. 2021, 32, 1767–1789.
- Al-Waisy, A.S.; Ibrahim, D.; Zebari, D.A.; Hammadi, S.; Mohammed, H.; Mohammed, M.A.; Damasevicius, R. Identifying defective solar cells in electroluminescence images using deep feature representations. PeerJ Comput. Sci. 2022, 8, e992.
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Deterioration level estimation via neural network maximizing category-based ordinally supervised multi-view canonical correlation. Multimed. Tools Appl. 2021, 80, 23091–23112.
- Konovalenko, I.; Maruschak, P.; Brezinova, J.; Vinas, J.; Brezina, J. Steel Surface Defect Classification Using Deep Residual Neural Network. Metals 2020, 10, 846.
- Liu, Z.; Zhang, C.; Li, C.; Ding, S.; Dong, Y.; Huang, Y. Fabric defect recognition using optimized neural networks. J. Eng. Fibers Fabr. 2019, 14, 1558925019897396.
- Mushabab Alqahtani, M.; Kumar Dutta, A.; Almotairi, S.; Ilayaraja, M.; Abdulrahman Albraikan, A.; Al-Wesabi, F.N.; Al Duhayyim, M. Sailfish Optimizer with EfficientNet Model for Apple Leaf Disease Detection. Comput. Mater. Contin. 2023, 74, 217–233.
- Barman, U.; Pathak, C.; Mazumder, N.K. Comparative assessment of Pest damage identification of coconut plant using damage texture and color analysis. Multimed. Tools Appl. 2023, 82, 25083–25105.
- Ksibi, A.; Ayadi, M.; Soufiene, B.O.; Jamjoom, M.M.; Ullah, Z. MobiRes-Net: A Hybrid Deep Learning Model for Detecting and Classifying Olive Leaf Diseases. Appl. Sci. 2022, 12, 10278.
- Wu, L.; Liu, Z.; Bera, T.; Ding, H.; Langley, D.A.; Jenkins-Barnes, A.; Furlanello, C.; Maggio, V.; Tong, W.; Xu, J. A deep learning model to recognize food contaminating beetle species based on elytra fragments. Comput. Electron. Agric. 2019, 166, 105002.
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. Int. J. 2022, 21, 2190–2205.
- Yuan, G.; Li, J.; Meng, X.; Li, Y. CurSeg: A pavement crack detector based on a deep hierarchical feature learning segmentation framework. IET Intell. Transp. Syst. 2022, 16, 782–799.
- Andrushia, D.; Anand, N.; Neebha, T.M.; Naser, M.Z.; Lubloy, E. Autonomous detection of concrete damage under fire conditions. Autom. Constr. 2022, 140, 104364.
- Wan, C.; Ma, S.; Song, K. TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects. Coatings 2022, 12, 1730.
- Su, L.; Huang, H.; Qin, L.; Zhao, W. Transformer Vibration Detection Based on YOLOv4 and Optical Flow in Background of High Proportion of Renewable Energy Access. Front. Energy Res. 2022, 10, 764903.
- Oishi, Y.; Habaragamuwa, H.; Zhang, Y.; Sugiura, R.; Asano, K.; Akai, K.; Shibata, H.; Fujimoto, T. Automated abnormal potato plant detection system using deep learning models and portable video cameras. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102509.
- Naddaf-Sh, M.M.; Hosseini, S.; Zhang, J.; Brake, N.A.; Zargarzadeh, H. Real-Time Road Crack Mapping Using an Optimized Convolutional Neural Network. Complexity 2019, 2019, 2470735.
- Song, W.; Jia, G.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 6412562.
- Saleem, M.R.; Park, J.W.; Lee, J.H.; Jung, H.J.; Sarwar, M.Z. Instant bridge visual inspection using an unmanned aerial vehicle by image capturing and geo-tagging system and deep convolutional neural network. Struct. Health Monit. Int. J. 2021, 20, 1760–1777.
- Chen, R. Migration Learning-Based Bridge Structure Damage Detection Algorithm. Sci. Program. 2021, 2021, 1102521.
- Chun, C.; Ryu, S.K. Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors 2019, 19, 5501.
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated Detection for Concrete Surface Cracks Based on Deeplabv3+BDF. Buildings 2023, 13, 118.
- Kou, L.; Sysyn, M.; Fischer, S.; Liu, J.; Nabochenko, O. Optical Rail Surface Crack Detection Method Based on Semantic Segmentation Replacement for Magnetic Particle Inspection. Sensors 2022, 22, 8214.
- Siriborvornratanakul, T. Downstream Semantic Segmentation Model for Low-Level Surface Crack Detection. Adv. Multimed. 2022, 2022, 3712289.
- Chen, H.; Lin, H.; Yao, M. Improving the Efficiency of Encoder-Decoder Architecture for Pixel-Level Crack Detection. IEEE Access 2019, 7, 186657–186670.
- Li, S.; Zhao, X. A Performance Improvement Strategy for Concrete Damage Detection Using Stacking Ensemble Learning of Multiple Semantic Segmentation Networks. Sensors 2022, 22, 3341.
- Shim, S.; Kim, J.; Cho, G.C.; Lee, S.W. Stereo-vision-based 3D concrete crack detection using adversarial learning with balanced ensemble discriminator networks. Struct. Health Monit. Int. J. 2023, 22, 1353–1375.
- Meng, M.; Zhu, K.; Chen, K.; Qu, H. A Modified Fully Convolutional Network for Crack Damage Identification Compared with Conventional Methods. Model. Simul. Eng. 2021, 2021, 5298882.
- Wu, D.; Zhang, H.; Yang, Y. Deep Learning-Based Crack Monitoring for Ultra-High Performance Concrete (UHPC). J. Adv. Transp. 2022, 2022, 4117957.
- Ali, L.; Khan, W.; Chaiyasarn, K. Damage detection and localization in masonry structure using faster region convolutional networks. Int. J. Geomater. 2019, 17, 98–105.
- Dong, C.; Li, L.; Yan, J.; Zhang, Z.; Pan, H.; Catbas, F.N. Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder-Decoder Network. Sensors 2021, 21, 4135.
- Jamshidi, M.; El-Badry, M.; Nourian, N. Improving Concrete Crack Segmentation Networks through CutMix Data Synthesis and Temporal Data Fusion. Sensors 2023, 23, 504.
- Yu, G.; Dong, J.; Wang, Y.; Zhou, X. RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation. Sensors 2023, 23, 53.
- Loverdos, D.; Sarhosis, V. Automatic image-based brick segmentation and crack detection of masonry walls using machine learning. Autom. Constr. 2022, 140, 104389.
- Pantoja-Rosero, B.G.; Oner, D.; Kozinski, M.; Achanta, R.; Fua, P.; Perez-Cruz, F.; Beyer, K. TOPO-Loss for continuity-preserving crack detection using deep learning. Constr. Build. Mater. 2022, 344.
- Zhao, S.; Kang, F.; Li, J. Non-Contact Crack Visual Measurement System Combining Improved U-Net Algorithm and Canny Edge Detection Method with Laser Rangefinder and Camera. Appl. Sci. 2022, 12, 10651.
- Shim, S.; Cho, G.C. Lightweight Semantic Segmentation for Road-Surface Damage Recognition Based on Multiscale Learning. IEEE Access 2020, 8, 102680–102690.
- Ji, H.; Cui, X.; Ren, W.; Liu, L.; Wang, W. Visual inspection for transformer insulation defects by a patrol robot fish based on deep learning. IET Sci. Meas. Technol. 2021, 15, 606–618.
- Shim, S.; Kim, J.; Lee, S.W.; Cho, G.C. Road damage detection using super-resolution and semi-supervised learning with generative adversarial network. Autom. Constr. 2022, 135, 104139.
- Dong, J.; Li, Z.; Wang, Z.; Wang, N.; Guo, W.; Ma, D.; Hu, H.; Zhong, S. Pixel-Level Intelligent Segmentation and Measurement Method for Pavement Multiple Damages Based on Mobile Deep Learning. IEEE Access 2021, 9, 143860–143876.
- Li, T.; Hao, T. Damage Detection of Insulators in Catenary Based on Deep Learning and Zernike Moment Algorithms. Appl. Sci. 2022, 12, 5004.
- Chen, S.; Zhang, Y.; Zhang, Y.; Yu, J.; Zhu, Y. Embedded system for road damage detection by deep convolutional neural network. Math. Biosci. Eng. 2019, 16, 7982–7994.
- Luo, Q.; Su, J.; Yang, C.; Gui, W.; Silven, O.; Liu, L. CAT-EDNet: Cross-Attention Transformer-Based Encoder-Decoder Network for Salient Defect Detection of Strip Steel Surface. IEEE Trans. Instrum. Meas. 2022, 71, 5009813.
- Liu, W.; Zhang, J.; Su, Z.; Zhou, Z.; Liu, L. Binary Neural Network for Automated Visual Surface Defect Detection. Sensors 2021, 21, 6868.
- Konovalenko, I.; Maruschak, P.; Brezinova, J.; Prentkovskis, O.; Brezina, J. Research of U-Net-Based CNN Architectures for Metal Surface Defect Detection. Machines 2022, 10, 327.
- Konovalenko, I.; Maruschak, P.; Kozbur, H.; Brezinova, J.; Brezina, J.; Nazarevich, B.; Shkira, Y. Influence of Uneven Lighting on Quantitative Indicators of Surface Defects. Machines 2022, 10, 194.
- Wang, Z.; Zhang, Y.; Luo, L.; Wang, N. AnoDFDNet: A Deep Feature Difference Network for Anomaly Detection. J. Sens. 2022, 2022, 3538541.
- Park, S.S.; Tran, V.T.; Lee, D.E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229.
- van Ruitenbeek, R.E.; Bhulai, S. Multi-view damage inspection using single-view damage projection. Mach. Vis. Appl. 2022, 33, 46.
- Zhao, G.; Hu, J.; Xiao, W.; Zou, J. A mask R-CNN based method for inspecting cable brackets in aircraft. Chin. J. Aeronaut. 2021, 34, 214–226.
- Pan, X.; Yang, T.Y. Image-based monitoring of bolt loosening through deep-learning-based integrated detection and tracking. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1207–1222.
- Brion, D.A.J.; Shen, M.; Pattinson, S.W. Automated recognition and correction of warp deformation in extrusion additive manufacturing. Addit. Manuf. 2022, 56, 102838.
- Salcedo, E.; Jaber, M.; Carrion, J.R. A Novel Road Maintenance Prioritisation System Based on Computer Vision and Crowdsourced Reporting. J. Sens. Actuator Netw. 2022, 11, 15.
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095.
- Huetten, N.; Meyes, R.; Meisen, T. Vision Transformer in Industrial Visual Inspection. Appl. Sci. 2022, 12, 11981.
- Wang, C.; Zhao, J.; Yu, Z.; Xie, S.; Ji, X.; Wan, Z. Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning. Appl. Sci. 2022, 12, 10347.
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452.
- Tanveer, M.; Kim, B.; Hong, J.; Sim, S.H.; Cho, S. Comparative Study of Lightweight Deep Semantic Segmentation Models for Concrete Damage Detection. Appl. Sci. 2022, 12, 12786.
- Islam, M.M.M.; Kim, J.M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder-Decoder Network. Sensors 2019, 19, 4251.
- Kumar, P.; Sharma, A.; Kota, S.R. Automatic Multiclass Instance Segmentation of Concrete Damage Using Deep Learning Model. IEEE Access 2021, 9, 90330–90345.
- He, Y.; Jin, Z.; Zhang, J.; Teng, S.; Chen, G.; Sun, X.; Cui, F. Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning. Appl. Sci. 2022, 12, 7364.
- Kulambayev, B.; Beissenova, G.; Katayev, N.; Abduraimova, B.; Zhaidakbayeva, L.; Sarbassova, A.; Akhmetova, O.; Issayev, S.; Suleimenova, L.; Kasenov, S.; et al. A Deep Learning-Based Approach for Road Surface Damage Detection. Comput. Mater. Contin. 2022, 73, 3403–3418.
- Zhou, S.; Pan, Y.; Huang, X.; Yang, D.; Ding, Y.; Duan, R. Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning. Materials 2022, 15, 3940.
- Bai, Y.; Zha, B.; Sezen, H.; Yilmaz, A. Engineering deep learning methods on automatic detection of damage in infrastructure due to extreme events. Struct. Health Monit. Int. J. 2023, 22, 338–352.
- Dais, D.; Bal, I.E.; Smyrou, E.; Sarhosis, V. Automatic crack classification and segmentation on masonry surfaces using convolutional neural networks and transfer learning. Autom. Constr. 2021, 125, 103606.
- Hu, G.X.; Hu, B.L.; Yang, Z.; Huang, L.; Li, P. Pavement Crack Detection Method Based on Deep Learning Models. Wirel. Commun. Mob. Comput. 2021, 2021, 5573590.
- Du, F.J.; Jiao, S.J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537.
- Li, L.; Fang, B.; Zhu, J. Performance Analysis of the YOLOv4 Algorithm for Pavement Damage Image Detection with Different Embedding Positions of CBAM Modules. Appl. Sci. 2022, 12, 10180.
- Wang, L.; Li, J.; Kang, F. Crack Location and Degree Detection Method Based on YOLOX Model. Appl. Sci. 2022, 12, 12572.
- Yang, Z.; Ni, C.; Li, L.; Luo, W.; Qin, Y. Three-Stage Pavement Crack Localization and Segmentation Algorithm Based on Digital Image Processing and Deep Learning Techniques. Sensors 2022, 22, 8459.
- Yin, J.; Qu, J.; Huang, W.; Chen, Q. Road Damage Detection and Classification based on Multi-level Feature Pyramids. Ksii Trans. Internet Inf. Syst. 2021, 15, 786–799.
- Xu, H.; Chen, B.; Qin, J. A CNN-Based Length-Aware Cascade Road Damage Detection Approach. Sensors 2021, 21, 689.
- Mallaiyan Sathiaseelan, M.A.; Paradis, O.P.; Taheri, S.; Asadizanjani, N. Why Is Deep Learning Challenging for Printed Circuit Board (PCB) Component Recognition and How Can We Address It? Cryptography 2021, 5, 9.
- Schwebig, A.I.M.; Tutsch, R. Intelligent fault detection of electrical assemblies using hierarchical convolutional networks for supporting automatic optical inspection systems. J. Sens. Sens. Syst. 2020, 9, 363–374.
- Yan, S.; Song, X.; Liu, G. Deeper and Mixed Supervision for Salient Object Detection in Automated Surface Inspection. Math. Probl. Eng. 2020, 2020, 3751053.
- Liang, H.; Lee, S.C.; Seo, S. Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network. Sensors 2022, 22, 9599.
- Zhang, H.; Wu, Z.; Qiu, Y.; Zhai, X.; Wang, Z.; Xu, P.; Liu, Z.; Li, X.; Jiang, N. A New Road Damage Detection Baseline with Attention Learning. Appl. Sci. 2022, 12, 7594.
- Lin, C.S.; Hsieh, H.Y. An Automatic Defect Detection System for Synthetic Shuttlecocks Using Transformer Model. IEEE Access 2022, 10, 37412–37421.
- Abedini, F.; Bahaghighat, M.; S’hoyan, M. Wind turbine tower detection using feature descriptors and deep learning. Facta Univ. Ser. Electron. Energetics 2020, 33, 133–153.
- Kim, H.; Lee, S.; Han, S. Railroad Surface Defect Segmentation Using a Modified Fully Convolutional Network. Ksii Trans. Internet Inf. Syst. 2020, 14, 4763–4775.
- Zhang, Z.; Liang, M.; Wang, Z. A Deep Extractor for Visual Rail Surface Inspection. IEEE Access 2021, 9, 21798–21809.
- Tabernik, D.; Sela, S.; Skvarc, J.; Skocaj, D. Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf. 2020, 31, 759–776.
- Shi, H.; Lai, R.; Li, G.; Yu, W. Visual inspection of surface defects of extreme size based on an advanced FCOS. Appl. Artif. Intell. 2022, 36, 2122222.
- Zhou, Q.; Situ, Z.; Teng, S.; Chen, W.; Chen, G.; Su, J. Comparison of classic object-detection techniques for automated sewer defect detection. J. Hydroinform. 2022, 24, 406–419.
- Shin, H.K.; Lee, S.W.; Hong, G.P.; Sael, L.; Lee, S.H.; Kim, H.Y. Defect-Detection Model for Underground Parking Lots Using Image Object-Detection Method. Comput. Mater. Contin. 2021, 66, 2493–2507.
- Urbonas, A.; Raudonis, V.; Maskeliunas, R.; Damasevicius, R. Automated Identification of Wood Veneer Surface Defects Using Faster Region-Based Convolutional Neural Network with Data Augmentation and Transfer Learning. Appl. Sci. 2019, 9, 4898.
- Roberts, R.; Giancontieri, G.; Inzerillo, L.; Di Mino, G. Towards Low-Cost Pavement Condition Health Monitoring and Analysis Using Deep Learning. Appl. Sci. 2020, 10, 319.
- Shihavuddin, A.S.M.; Chen, X.; Fedorov, V.; Christensen, A.N.; Riis, N.A.B.; Branner, K.; Dahl, A.B.; Paulsen, R.R. Wind Turbine Surface Damage Detection by Deep Learning Aided Drone Inspection Analysis. Energies 2019, 12, 676.
- Allam, A.; Moussa, M.; Tarry, C.; Veres, M. Detecting Teeth Defects on Automotive Gears Using Deep Learning. Sensors 2021, 21, 8480.
- Lee, K.; Hong, G.; Sael, L.; Lee, S.; Kim, H.Y. MultiDefectNet: Multi-Class Defect Detection of Building Facade Based on Deep Convolutional Neural Network. Sustainability 2020, 12, 9785.
- Wei, R.; Bi, Y. Research on Recognition Technology of Aluminum Profile Surface Defects Based on Deep Learning. Materials 2019, 12, 1681.
- Palanisamy, P.; Mohan, R.E.; Semwal, A.; Melivin, L.M.J.; Gomez, B.F.; Balakrishnan, S.; Elangovan, K.; Ramalingam, B.; Terntzer, D.N. Drain Structural Defect Detection and Mapping Using AI-Enabled Reconfigurable Robot Raptor and IoRT Framework. Sensors 2021, 21, 7287.
- Siu, C.; Wang, M.; Cheng, J.C.P. A framework for synthetic image generation and augmentation for improving automatic sewer pipe defect detection. Autom. Constr. 2022, 137, 104213.
- Chen, Q.; Gan, X.; Huang, W.; Feng, J.; Shim, H. Road Damage Detection and Classification Using Mask R-CNN with DenseNet Backbone. Comput. Mater. Contin. 2020, 65, 2201–2215.
- Zhang, J.; Cosma, G.; Watkins, J. Image Enhanced Mask R-CNN: A Deep Learning Pipeline with New Evaluation Measures for Wind Turbine Blade Defect Detection and Classification. J. Imaging 2021, 7, 46.
- Dogru, A.; Bouarfa, S.; Arizar, R.; Aydogan, R. Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace 2020, 7, 171.
- Kim, B.; Cho, S. Automated Multiple Concrete Damage Detection Using Instance Segmentation Deep Learning Model. Appl. Sci. 2020, 10, 8008.
- Kim, A.; Lee, K.; Lee, S.; Song, J.; Kwon, S.; Chung, S. Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding. Appl. Sci. 2022, 12, 10097.
- Yan, K.; Zhang, Z. Automated Asphalt Highway Pavement Crack Detection Based on Deformable Single Shot Multi-Box Detector Under a Complex Environment. IEEE Access 2021, 9, 150925–150938.
- Jang, J.; Shin, M.; Lim, S.; Park, J.; Kim, J.; Paik, J. Intelligent Image-Based Railway Inspection System Using Deep Learning-Based Object Detection and Weber Contrast-Based Image Comparison. Sensors 2019, 19, 4738.
- Ramalingam, B.; Manuel, V.H.; Elara, M.R.; Vengadesh, A.; Lakshmanan, A.K.; Ilyas, M.; James, T.J.Y. Visual Inspection of the Aircraft Surface Using a Teleoperated Reconfigurable Climbing Robot and Enhanced Deep Learning Technique. Int. J. Aerosp. Eng. 2019, 2019, 5137139.
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141.
- Lv, L.; Yao, Z.; Wang, E.; Ren, X.; Pang, R.; Wang, H.; Zhang, Y.; Wu, H. Efficient and Accurate Damage Detector for Wind Turbine Blade Images. IEEE Access 2022, 10, 123378–123386.
- Wei, Z.; Fernandes, H.; Herrmann, H.G.; Tarpani, J.R.; Osman, A. A Deep Learning Method for the Impact Damage Segmentation of Curve-Shaped CFRP Specimens Inspected by Infrared Thermography. Sensors 2021, 21, 395.
- Munawar, H.S.; Ullah, F.; Shahzad, D.; Heravi, A.; Qayyum, S.; Akram, J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings 2022, 12, 156.
- Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors 2022, 22, 2330.
- Zheng, Z.; Zhang, S.; Yu, B.; Li, Q.; Zhang, Y. Defect Inspection in Tire Radiographic Image Using Concise Semantic Segmentation. IEEE Access 2020, 8, 112674–112687.
- Wu, W.; Li, Q. Machine Vision Inspection of Electrical Connectors Based on Improved Yolo v3. IEEE Access 2020, 8, 166184–166196.
- Kumar, P.; Batchu, S.; Swamy S., N.; Kota, S.R. Real-Time Concrete Damage Detection Using Deep Learning for High Rise Structures. IEEE Access 2021, 9, 112312–112331.
- Lin, H.I.; Wibowo, F.S. Image Data Assessment Approach for Deep Learning-Based Metal Surface Defect-Detection Systems. IEEE Access 2021, 9, 47621–47638.
- Shihavuddin, A.S.M.; Rashid, M.R.A.; Maruf, M.H.; Abul Hasan, M.; ul Haq, M.A.; Ashique, R.H.; Al Mansur, A. Image based surface damage detection of renewable energy installations using a unified deep learning approach. Energy Rep. 2021, 7, 4566–4576.
- Yu, L.; Yang, E.; Luo, C.; Ren, P. AMCD: An accurate deep learning-based metallic corrosion detector for MAV-based real-time visual inspection. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 8087–8098.
- Du, F.; Jiao, S.; Chu, K. Application Research of Bridge Damage Detection Based on the Improved Lightweight Convolutional Neural Network Model. Appl. Sci. 2022, 12, 6225.
- Guo, Y.; Zeng, Y.; Gao, F.; Qiu, Y.; Zhou, X.; Zhong, L.; Zhan, C. Improved YOLOV4-CSP Algorithm for Detection of Bamboo Surface Sliver Defects With Extreme Aspect Ratio. IEEE Access 2022, 10, 29810–29820.
- Huang, H.; Luo, X. A Holistic Approach to IGBT Board Surface Fractal Object Detection Based on the Multi-Head Model. Machines 2022, 10, 713.
- Li, Y.; Fan, Y.; Wang, S.; Bai, J.; Li, K. Application of YOLOv5 Based on Attention Mechanism and Receptive Field in Identifying Defects of Thangka Images. IEEE Access 2022, 10, 81597–81611.
- Ma, H.; Lee, S. Smart System to Detect Painting Defects in Shipyards: Vision AI and a Deep-Learning Approach. Appl. Sci. 2022, 12, 2412.
- Teng, S.; Liu, Z.; Li, X. Improved YOLOv3-Based Bridge Surface Defect Detection by Combining High- and Low-Resolution Feature Images. Buildings 2022, 12, 1225.
- Wan, F.; Sun, C.; He, H.; Lei, G.; Xu, L.; Xiao, T. YOLO-LRDD: A lightweight method for road damage detection based on improved YOLOv5s. Eurasip J. Adv. Signal Process. 2022, 2022, 98.
- Zhang, C.; Yang, T.; Yang, J. Image Recognition of Wind Turbine Blade Defects Using Attention-Based MobileNetv1-YOLOv4 and Transfer Learning. Sensors 2022, 22, 6009.
- Wang, C.; Zhou, Z.; Chen, Z. An Enhanced YOLOv4 Model With Self-Dependent Attentive Fusion and Component Randomized Mosaic Augmentation for Metal Surface Defect Detection. IEEE Access 2022, 10, 97758–97766.
- Du, X.; Cheng, Y.; Gu, Z. Change Detection: The Framework of Visual Inspection System for Railway Plug Defects. IEEE Access 2020, 8, 152161–152172.
- Zheng, D.; Li, L.; Zheng, S.; Chai, X.; Zhao, S.; Tong, Q.; Wang, J.; Guo, L. A Defect Detection Method for Rail Surface and Fasteners Based on Deep Convolutional Neural Network. Comput. Intell. Neurosci. 2021, 2021, 2565500.
- Zhang, Y.; Sun, X.; Loh, K.J.; Su, W.; Xue, Z.; Zhao, X. Autonomous bolt loosening detection using deep learning. Struct. Health Monit. Int. J. 2020, 19, 105–122.
- Lei, T.; Lv, F.; Liu, J.; Zhang, L.; Zhou, T. Research on Fault Detection Algorithm of Electrical Equipment Based on Neural Network. Math. Probl. Eng. 2022, 2022, 9015796.
- An, Y.; Lu, Y.N.; Wu, T.R. Segmentation Method of Magnetic Tile Surface Defects Based on Deep Learning. Int. J. Comput. Commun. Control 2022, 17.
- Chen, S.W.; Tsai, C.J.; Liu, C.H.; Chu, W.C.C.; Tsai, C.T. Development of an Intelligent Defect Detection System for Gummy Candy under Edge Computing. J. Internet Technol. 2022, 23, 981–988.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
2.0K
Revisions:
4 times
(View History)
Update Date:
26 Feb 2024
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No