1. Introduction
Industrial production and maintenance are under constant pressure from increasing quality requirements due to rising product demands, changing resources, and cost specifications. In addition, there are constantly changing framework conditions due to new and changing legal requirements, standards, and norms. Ultimately, the increasing general flow of information via social media and other platforms leads to an increased risk of reputational damage from substandard products. These influences, combined with the fact that quality assurance is still predominantly performed or supported by human inspectors, have led to the need for advances in continuous quality control. Since vision is the predominant conscious sense of humans, most inspection techniques in the past and even today are of a visual nature [
1]. However, manual visual inspection (VI) has several drawbacks, which have been studied, for example, by Steger et al., Sheehan et al., and Chiang et al. [
2,
3,
4], specifically including high labor costs, low efficiency, and low real-time performance in the case of fast-moving inspection objects or large surface areas. According to Swain and Guttmann [
5], minimal error rates of 10
−3 can be reached for very simple accept/reject tasks. Though highly dependent on the inspection task, Drury and Fox [
6] observed error rates of 20% to 30% in more complex VI tasks in their studies. In addition, decreasing efficiency and accuracy occur during human inspection due to fatigue and resulting attention deficits.
As a way to counteract these effects, automation solutions were pushed in the 1980s. The goal was to increase efficiency and performance and reduce costs while minimizing human error. Accordingly, computer vision (CV) methods were introduced to VI, which was initially only relevant for the automation of simple, monotonous tasks. In the beginning, they served more as a support for inspectors [
7], but as development progressed, whole tasks were solved without human involvement. This was the beginning of automated visual inspection (AVI).
2. Requirements for Deep-Learning Models in AVI
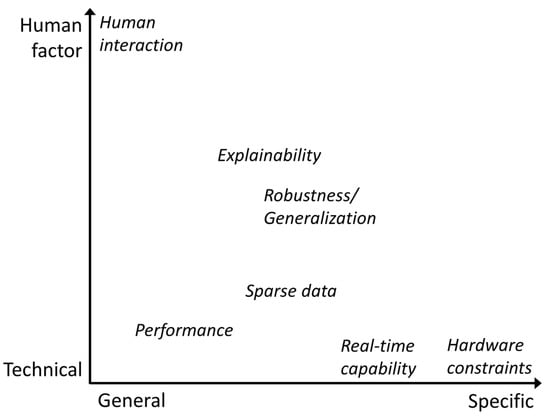
Several requirements have to be considered when introducing DL-based AVI to a previously manual inspection process or even to an already automated process that uses classical CV methods. To answer our second question, “What are the requirements that have to be considered when applying DL-based models to AVI?”, the researchers analyzed our publication corpus with regard to requirements, with either a direct textual mention or indirect mention through evaluation procedures, as well as reported metrics. These requirements can be grouped in two dimensions: on the one hand, between general and application- or domain-specific requirements or, on the other hand, between hard technical and soft human factors. The most general technical challenge is performance, as visualized in Figure 2.
Figure 2. AVI requirements grouped by their combined properties with regard to specificity and whether they are technical-factor- or human-factor-driven.
In the case of the automation of previously manual processes, human-level performance is usually used as a reference value, which is intended to guarantee the same level of safety, as mentioned by Brandoli et al. for aircraft maintenance [
38]. If the target process is already automated, the DL-based solution needs to prevail against the established solution. Performance can be measured by different metrics, as some processes are more focused on false positives (FPs), like the one investigated by Wang et al. [
39], or false negatives (FNs). Therefore, it cannot be considered a purely general requirement, as it is affected by the choice of metric. Real-time capability is a strictly technical challenge, as it can be defined by the number of frames per second (FPS) a model can process but is mostly specific, as it is mainly required when inspecting manufactured goods on a conveyor belt or rails/streets from a fast-moving vehicle for maintenance [
39,
40,
41,
42]. Hardware constraints are the most specific and rare technical challenge found in our publication corpus. This usually means that the models have to run on a particular edge device, which is limited in memory, the number of floating-point operations per second (FLOPS), or even the possible computational operations it can perform [
43]. Sparse (labeled) data are primarily a technical challenge, where the emphasis is put on the fact that models with more parameters generally perform better but require more data samples to optimize those parameters, as well. The labeling process introduces the human factor into this requirement because a consistent understanding of the boundary between different classes is necessary in order to produce a coherent distribution of labels with as few non-application-related inconsistencies or outliers as possible. This is especially true if there are few samples and if multiple different persons create the labels. Models need to perform well with these small labeled industrial datasets [
44,
45,
46,
47,
48] or, even better, work without labeled data [
49,
50]. One of the key advantages of DL-based models compared to classic CV methods is their generalization capability, which makes them robust against partly hidden objects, changing lighting conditions, or new damage types. This characteristic is required for many use cases where it is not possible to enforce controlled conditions or have full visibility, such as rail track inspection [
42,
51,
52], or it is an added benefit when a model is able to extrapolate to previously unseen damages [
53]. As this requirement is not easily quantifiable and application-specific to a certain degree, the researchers place it centrally in both dimensions. Part of any industrial transformation process is the people involved, whether they are directly affected as part of the process or indirectly affected through interfaces with the process. To improve the acceptance of change processes, it is necessary to convince domain experts that they can trust the new DL solution. In addition, explainability can also be helpful from a model development perspective to determine the reason for certain model confusions that lead to errors [
54].
3. Visual Inspection Use Cases
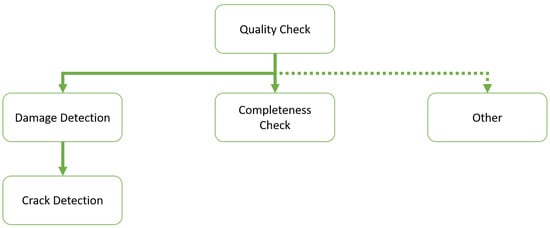
In order to answer our second guiding question, “Which AVI use cases are currently being addressed by DL models?”, the researchers examined the reviewed publications to determine whether it is possible to summarize the solved VI tasks into specific use cases. The researchers identified a hierarchy of VI use cases based on the surveyed literature, that visualized in Figure 3.
Figure 3. Hierarchical structure of top-level VI use cases based on the surveyed literature.
As previously mentioned, VI is getting more challenging due to ever-increasing quality requirements, and all use cases can be considered to be at least
quality inspection. In our literature review, quality inspection use cases are those that do not detect defects or missing parts but the state of an object. For example, determining the state of woven fabrics or leather quality is a use case the researchers considered to be only quality inspection [
55,
56].
Damage detection, also referred to as defect detection in the literature, summarizes all VI use cases that classify or detect at least one type of damage. An example of damage detection use cases is the surface defect detection of internal combustion engine parts [
57] or the segmentation of different steel surface defects [
58].
Crack detection can be considered a specialization of damage detection use cases and has its own category because of its occurrence frequency in the surveyed literature. The crack detection use case deals solely with crack classification, localization, or segmentation. The application context is usually the maintenance of public buildings, for example, pavement cracks [
59,
60] or concrete cracks [
61,
62]. In addition to detecting defects, another VI use case is to check whether a part is missing or not.
Completeness check summarizes these use cases. A completeness check can be the determination of whether something is missing, or to the contrary, the determination of whether something is present. O’Byrne et al. [
63] proposed a method to detect barnacles on ship hulls. Another example is provided by Chandran et al. [
51], who propose a DL approach to detect rail track fasteners for railway maintenance. The last VI use case class the researchers defined as
other, which includes VI use cases that cannot directly be seen through only quality inspection and are not of the damage detection or completeness check type. Example use cases are plant disease detection [
64,
65] or type classification [
66].
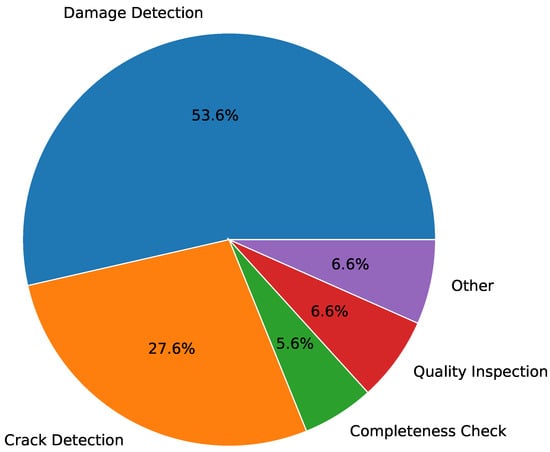
Figure 4 shows the distribution of the VI use cases over the investigated literature. Most publications (53.57%) deal with damage detection use cases. The second most (27.55%) researched VI use case is crack detection, followed by quality inspection (6.63%) as well as other use cases (6.63%), and the least occurring type is completeness check use cases (5.61%).
Figure 4. Distribution of reviewed publications by VI use cases.
4. Overview on How to Solve Automated Visual Inspection with Deep-Learning Models
In the following, the researchers aim to answer our third guiding question, “Are there certain recurring AVI tasks that these use cases can be categorized into?”, by investigating with which DL approach the VI use cases can be solved. For this, the researchers determined four different AVI tasks to categorize the approaches. Each of these tasks aims to answer one or more questions about the inspected object. Binary classification tries to answer the question, Is the inspected object in the desired state? This applies mainly to accept/reject tasks, like separating correctly produced parts from scrap parts, regardless of the type of deficiency. Multi-class classification goes one step further, trying to answer the question, In which state is the inspected object? By additionally identifying the type of deficiency, it is possible to, e.g., distinguish between parts that are irreparably damaged and parts that can still be reworked to pass the requirements or determine the rework steps that are necessary. Localization further answers the question, Where do the researchers find this state on the inspected object? This adds information about the locality of a state of interest, as well as enabling the finding of more than one target. It can be utilized, e.g., to check assemblies for their completeness. The fourth AVI task, multi-class localization, answers the question, Where do ind which state on the inspected object? For example, the state of a bolt can be present, missing, rusty, or cracked. Thus, the set of states is not fixed and depends, among other things, on application-specific conditions, as well as on the object under inspection.
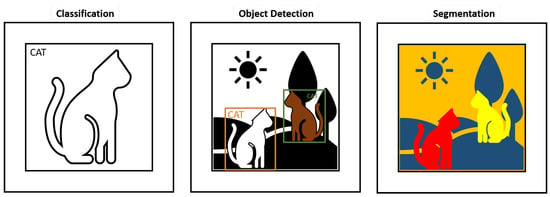
These four AVI tasks are closely related to the three most common CV tasks, image classification, object detection, and segmentation, which are visualized in Figure 5.
Figure 5. Visualization of the three different CV tasks—classification, object detection with two bounding boxes, and segmentation.
In image classification, the goal is to assign a corresponding label to an image. Object detection is performed by a method or model that searches for objects of interest. Usually, the object is indicated by a rectangular bounding box, and simultaneously, object classification is performed for each object. Unlike pure classification, multiple objects can be detected and classified. Image segmentation is the process of separating every recognizable object into corresponding pixel segments. This means that both classification AVI tasks are performed by image classification models, while both localization tasks are performed by either an object detection model or a segmentation model.
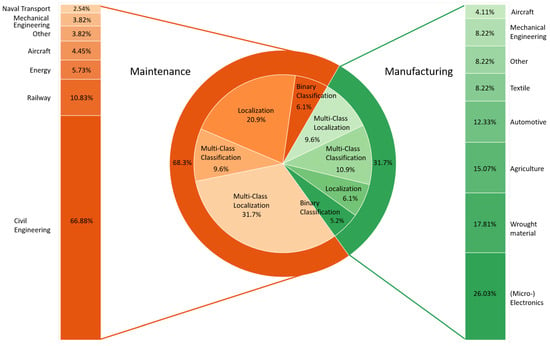
Figure 6 shows the composition of our publication corpus with regard to the application context, industry sector, and AVI task.
Figure 6. Distribution of reviewed publications by inspection context, VI task, and associated industrial sector.
The number of papers in the maintenance context outweigh those addressing manufacturing by two to one, as depicted by the outer pie chart in the center. Each of those contexts is associated with several different industrial sectors in which AVI is applied. The share of the industry sectors in each context is plotted on the left- and right-hand sides. The biggest shares in maintenance are held by the fields of civil engineering, railway, energy, and aircraft. These sum up to a total of 87.89% of all maintenance publications. The manufacturing sectors, (micro-) electronics, wrought material, agriculture, automotive, and textiles, add up to a total of 79.46% of all manufacturing papers. In addition to the industry sectors, the researchers also group the applications per context by the AVI task. The distribution of VI tasks for each industry context is visualized by the inner pie chart. For maintenance applications, 77.01% of their total 68.3% is covered by basic and multi-class localization tasks. Only 15.7% of the tasks can be attributed to classification tasks. In manufacturing, the VI tasks are spread across 16.1% classification and 15.7% localization publications. The multi-class variants are clearly more frequent for both, with 9.6% for localization and 10.9% for classification.
In the following subsections, one for each AVI task, the researchers investigate the collected literature and utilized models. Only the best-performing architecture is mentioned if multiple are utilized. Models that are derived from established base architectures like Residual Networks (ResNet) [
67] are still considered to belong to that architecture family unless they are combined or stacked with another architecture. The researchers also subsumed all versions of the “you only look once” (YOLO) architecture [
68] under YOLO. Models that are custom designs of the authors and not based on any established architectures are subsumed under the categories multi-layer perceptron (MLP), convolutional neural network (CNN), or Transformer based on their main underlying mechanisms.
4.1. Visual Inspection via Binary Classification
In the surveyed literature, 21 publications describe a way to approach AVI with binary image classification; these are summarized in Table 2. Following the general trend of VI use cases, damage detection is addressed ten times with binary classification.
Adibhatla et al. [
50] used a ResNet, Selmaier et al. [
46] used an Xception architecture, and Jian et al. [
69] used a DenseNet to classify whether damage is visible or not. Crack detection is addressed seven times with binary classification. In four publications, the authors propose a CNN architecture for AVI crack detection. In the other two publications, crack detection was performed with an AlexNet or a Visual geometry group model (VGG). Ali et al. [
70] proposed a sliding window vision transformer (ViT) as a binary classifier for crack detection in pavement structures. Binary classification is also utilized for completeness checks and plant disease detection (other). For plant disease detection, Ahmad et al. [
64] used an MLP, while O’Byrne et al. [
63] used a custom CNN for a completeness check use case.
Table 2. Overview of VI use cases and models that solve these problems via binary classification.
| VI Use Case |
Model |
Count |
References |
| Crack Detection |
AlexNet |
1 |
[71] |
| CNN |
4 |
[72,73,74,75] |
| VGG |
1 |
[76] |
| ViT |
1 |
[70] |
| Damage Detection |
AlexNet |
1 |
[77] |
| CNN |
1 |
[78] |
| DenseNet |
3 |
[38,69,79] |
| Ensemble |
1 |
[80] |
| MLP |
1 |
[81] |
| ResNet |
1 |
[50] |
| SVM |
1 |
[82] |
| Xception |
1 |
[46] |
| Quality Inspection |
AlexNet |
1 |
[83] |
| MLP |
1 |
[84] |
| Other |
MLP |
1 |
[64] |
| Completeness Check |
CNN |
1 |
[63] |
4.2. Visual Inspection via Multi-Class Classification
Table 3 presents an overview of 42 publications that solve various use cases of AVI through multi-class classification and the models that are used to solve them. The models used to solve these use cases include popular DL architectures such as AlexNet, CNN, DenseNet, EfficientNet, GAN, MLP, MobileNet, ResNet, single-shot detector (SSD), and VGG. Twenty-one publications describe approaches for damage detection, of which six approaches are based on custom CNNs. The other four authors used ResNet-based architectures. Kumar et al. [
85] proposed an MLP architecture to perform damage detection. Also, an EfficientNet and a single-shot detector (SSD) were employed for multi-class damage detection. Five publications cover crack detection use cases. For example, Alqahtani [
86] used a CNN, and Elhariri et al. [
87] as well as Kim et al. [
88] used a VGG. Also, DL models like ResNet, DenseNet, and an ensemble architecture are proposed by some authors. Completeness checks were performed with the help of a ResNet by Chandran et al. [
51] or an SSD, as shown by Yang et al. [
89]. In seven publications, the authors used custom CNNs, DenseNet, ResNet, or VGG in quality inspection use cases. Also, other use cases can be addressed by different DL-based CV models or MLPs.
Table 3. Overview of VI use cases and models that solve these use cases via multi-class classification.
| VI Use Case |
Model |
Count |
References |
| Crack Detection |
AlexNet |
1 |
[90] |
| CNN |
1 |
[86] |
| EfficientNet |
1 |
[91] |
| ResNet |
1 |
[92] |
| VGG |
2 |
[87,88] |
| Damage Detection |
AlexNet |
1 |
[93] |
| CNN |
6 |
[66,94,95,96,97,98] |
| CNN LSTM |
1 |
[99] |
| EfficientNet |
2 |
[100,101] |
| Ensemble |
1 |
[56] |
| GAN |
2 |
[102,103] |
| MLP |
1 |
[85] |
| MobileNet |
1 |
[104] |
| ResNet |
4 |
[105,106,107,108] |
| VGG |
2 |
[60,109] |
| Completeness Check |
ResNet |
1 |
[51] |
| SSD |
1 |
[89] |
| Quality Inspection |
CNN |
3 |
[110,111,112] |
| DenseNet |
1 |
[113] |
| ResNet |
2 |
[55,114] |
| VGG |
1 |
[115] |
| Other |
CNN |
1 |
[65] |
| EfficientNet |
1 |
[116] |
| MLP |
1 |
[117] |
| MobileNet |
1 |
[118] |
| ResNet |
1 |
[54] |
| VGG |
1 |
[119] |
4.3. Visual Inspection via Localization
As previously mentioned, localization is used to detect where an object of interest is located.
Table 4 summarizes which VI use cases are addressed with localization and the appropriate models. In a total of 50 publications, localization was employed for AVI. Contrary to classification approaches, crack detection is the most addressed VI use case, with a total of 26 publications investigating it. The most utilized approach for crack detection is the CNN, which was applied in eight publications. Furthermore, in three other publications, extended CNN architectures were used. Kang et al. [
120] introduced a CNN with an attention mechanism, and Yuan et al. [
121] used a CNN with an encoder–decoder architecture. Andrushia et al. [
122] combined a CNN with a long short-term memory cell (LSTM) to process the images recurrently for crack detection. Among custom CNN approaches, six authors used UNet to detect cracks, mostly in public constructions. Damage detection via localization occurred 16 times and was addressed with at least twelve different DL-based models. Three authors decided to approach it with DL-based models of the Transformer family. For example, Wan et al. [
123] utilized a Swin-Transformer to localize damages on rail surfaces. Completeness checks can be executed with YOLO and/or regional convolutional neural networks (RCNNs). Furthermore, YOLO can be used for vibration estimation, as shown by Su et al. [
124]. Oishi et al. [
125] proposed a Faster RCNN to localize abnormalities on potato plants.
Table 4. Overview of VI use cases and models that solve these use cases via localization.
| VI Use Case |
Model |
Count |
References |
| Crack Detection |
CNN |
8 |
[47,59,62,126,127,128,129,130] |
| CNN LSTM |
1 |
[122] |
| Attention CNN |
1 |
[120] |
| Custom encoder–decoder CNN |
1 |
[121] |
| DeepLab |
3 |
[131,132,133] |
| Ensemble |
3 |
[134,135,136] |
| Fully convolutional network (FCN) |
2 |
[137,138] |
| Faster RCNN |
1 |
[139] |
| UNet |
6 |
[140,141,142,143,144,145] |
| Damage Detection |
DenseNet |
1 |
[146] |
| Faster RCNN |
1 |
[147] |
| GAN |
1 |
[148] |
| Mask RCNN |
2 |
[149,150] |
| ResNet |
1 |
[48] |
| SSD |
1 |
[151] |
| Swin |
1 |
[123] |
| Transformer |
1 |
[152] |
| UNet |
3 |
[153,154,155] |
| VAE |
1 |
[49] |
| ViT |
1 |
[156] |
| YOLO |
2 |
[157,158] |
| Completeness Check |
Mask RCNN |
1 |
[159] |
| YOLO |
1 |
[160] |
| Quality Inspection |
YOLO |
1 |
[161] |
| Other |
Faster RCNN |
1 |
[125] |
| UNet |
2 |
[44,162] |
| YOLO |
2 |
[124,163] |
4.4. Visual Inspection via Multi-Class Localization
The majority of the literature reviewed used multi-class localization for VI. In 83 publications, it is shown how to approach different use cases, like crack or damage detection, with multi-class localization.
Table 5 provides a detailed overview. As for the two classification approaches, damage detection is the most investigated VI use case, with 58 publications. Therein, YOLO and Faster RCNNs are the two most used models, with over ten publications. They are followed by CNNs and Mask RCNN models, which are utilized more than five times. FCN, SSD, and UNet can also be used as approaches to multi-class damage detection. Huetten et al. [
164] conducted a comparative study of several CNN models highly utilized in AVI and three vision transformer models, namely, detection transformer (DETR), deformable detection transformer (DDETR), and Retina-Swin, on three different damage detection use cases on freight cars. Multi-class localization was used in 15 publications for crack detection. In five publications, the authors performed crack detection with a YOLO model. Crack detection can also be performed with AlexNet, DeepLab, FCN, Mask RCNN, and UNet, which was shown in different publications. In three different publications, the authors show how to conduct quality inspection with YOLO. YOLO can be used in a tobacco use case, as well (other), as shown by Wang et al. [
165].
Table 5. Overview of VI use cases and models that solve these use cases via multi-class localization.
| VI Use Case |
Model |
Count |
References |
| Crack Detection |
AlexNet |
1 |
[166] |
| DeepLab |
2 |
[61,167] |
| FCN |
1 |
[168] |
| Mask RCNN |
5 |
[169,170,171,172,173] |
| UNet |
1 |
[174] |
| YOLO |
5 |
[175,176,177,178,179] |
| Damage Detection |
CNN |
7 |
[180,181,182,183,184,185,186] |
| DETR |
1 |
[187] |
| EfficientNet |
1 |
[188] |
| FCN |
3 |
[189,190,191] |
| FCOS |
1 |
[192] |
| Faster RCNN |
10 |
[193,194,195,196,197,198,199,200,201,202] |
| Mask RCNN |
6 |
[53,203,204,205,206,207] |
| MobileNet |
1 |
[39] |
| RCNN |
1 |
[45] |
| SSD |
5 |
[208,209,210,211,212] |
| Swin |
1 |
[164] |
| UNet |
4 |
[58,213,214,215] |
| VGG |
1 |
[216] |
| YOLO |
16 |
[41,57,217,218,219,220,221,222,223,224,225,226,227,228,229,230] |
| Completeness Check |
CNN |
1 |
[231] |
| Ensemble |
1 |
[232] |
| Faster RCNN |
2 |
[233,234] |
| YOLO |
2 |
[42,52] |
| Quality Inspection |
YOLO |
3 |
[40,235,236] |
| Other |
YOLO |
1 |
[165] |
This entry is adapted from the peer-reviewed paper 10.3390/asi7010011