Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Tin Lai | -- | 2955 | 2024-01-16 10:24:09 | | | |
| 2 | Catherine Yang | Meta information modification | 2955 | 2024-01-18 02:39:42 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Lai, T. Explainable AI for Health Care. Encyclopedia. Available online: https://encyclopedia.pub/entry/53883 (accessed on 25 July 2026).
Lai T. Explainable AI for Health Care. Encyclopedia. Available at: https://encyclopedia.pub/entry/53883. Accessed July 25, 2026.
Lai, Tin. "Explainable AI for Health Care" Encyclopedia, https://encyclopedia.pub/entry/53883 (accessed July 25, 2026).
Lai, T. (2024, January 16). Explainable AI for Health Care. In Encyclopedia. https://encyclopedia.pub/entry/53883
Lai, Tin. "Explainable AI for Health Care." Encyclopedia. Web. 16 January, 2024.
Copy Citation
Artificial intelligence (AI) have facilitated its widespread adoption in primary medical services, addressing the demand–supply imbalance in healthcare. Vision Transformers (ViT) have emerged as state-of-the-art computer vision models, benefiting from self-attention modules. However, compared to traditional machine learning approaches, deep learning models are complex and are often treated as a “black box” that can cause uncertainty regarding how they operate. Explainable artificial intelligence (XAI) refers to methods that explain and interpret machine learning models’ inner workings and how they come to decisions, which is especially important in the medical domain to guide healthcare decision-making processes.
explainable AI (XAI)
multi-head attention
vision transformer
interpretability in artificial intelligence
1. Introduction
Artificial intelligence (AI) has made significant strides in various domains in recent years, revolutionizing industries and shaping how we approach complex problems. One of AI’s most remarkable applications is in medical imaging [1], where it has brought about unprecedented advancements in automated image analysis, diagnosis, and decision making. Medical images are one of the most common clinical diagnostic methods [2]. These images vary in properties based on the medical diagnosis and specific anatomical locations, like the skin [3][4][5][6], chest [3][7][8][9][10], brain [11][12], liver [13], and others. Deep learning algorithms have found numerous critical applications in the healthcare domain, ranging from detecting diabetes [14], uses in genomics [15], and applications in mental health support [16]. Among the latest breakthroughs in computer vision models, Vision Transformers (ViT) [17] have emerged by leveraging self-attention mechanisms to achieve state-of-the-art performance in various visual tasks.
As medical professionals increasingly rely on AI-powered systems to aid in diagnosis and treatment planning [18], the need for interpretability and transparency in AI models becomes paramount [19]. Deep learning models, including ViTs, often exhibit highly complex and intricate internal representations, making it challenging for experts to comprehend their decision-making process. The opaque nature of these models raises concerns about their reliability and safety, especially in critical applications such as medical diagnostics, where accurate and trustworthy results are of the utmost importance [20]. Explainable artificial intelligence (XAI) is a burgeoning field that seeks to bridge the gap between the black box nature of AI algorithms and the need for understandable and interpretable decision-making processes [21]. XAI addresses a fundamental challenge: How can we make AI’s decision-making process more transparent and comprehensible to both experts and non-experts? While complex models might achieve impressive accuracy, their inability to provide human-readable explanations hinders their adoption in critical applications such as healthcare, finance, and legal domains. This limitation not only undermines users’ trust but also poses ethical and regulatory concerns. The integration of XAI can also lead to improved collaboration between AI systems and human experts, as well as the identification of novel patterns and insights that might have been overlooked otherwise.
In the realm of XAI, several techniques contribute to enhancing the transparency and trustworthiness of complex machine learning models. Local interpretable model-agnostic explanations (LIMEs) offer insights into any model’s predictions by approximating its behavior with interpretable surrogate models [22]. LIME is model-agnostic, which means it is applicable to most AI models without relying on any specific model architecture. Gradient-based saliency methods, like Grad-CAM, illuminate the model-specific regions of input data that contribute most to predictions, fostering an understanding of where the model focuses its attention [23]. Furthermore, in medical domain, decision understanding is often achieved through interactive dashboards that visualize model outcomes and insights, allowing end users to assess predictions, contributing factors, and uncertainties for informed decision making. These concepts collectively illuminate the intricate inner workings of machine learning models, promoting transparency and user confidence.
2. Explainability Methods in XAI
The importance of interpretability in machine learning models is widely acknowledged, but defining what constitutes interpretability remains a challenge [24]. Various definitions have been proposed, emphasizing openness, accuracy, reliability, and understandability [24][25]. However, these definitions often overlook the user’s perspective, and their needs are not adequately addressed in the produced explanations [26]. This is especially relevant in interpretable machine learning systems, where the audience’s understanding and trust in the models are crucial.
Interpretability becomes even more critical in medical imaging as it influences clinicians’ decision making and patients’ acceptance of the model’s predictions. Interpretable machine learning systems offer valuable insights into their reasoning, helping users, such as clinicians, comprehend and verify predictions, ensuring fairness and unbiased outcomes for diverse populations. As deep learning algorithms find numerous applications in healthcare, the demand for interpretable models grows, necessitating the establishment of uniform criteria for interpretable ML in this vital domain. The following summarizes explainability methods that are commonly used in the XAI field.
2.1. Gradient-Weighted Class Activation Mapping (Grad-CAM) Method
Grad-CAM is a gradient-based interpretability technique introduced by Selvaraju et al. [23] that aims to generate a localization map of the significant regions in an image that contribute the most to the decision made by a neural network. Leveraging the spatial information retained in convolutional layers, Grad-CAM utilizes the gradients propagated to the last convolutional layer to attribute importance values to each network neuron with respect to the final decision. An appealing advantage of Grad-CAM over similar methods is its applicability without requiring re-training or architectural changes, making it readily adaptable to various CNN-based models. Moreover, combined with guided back-propagation through element-wise multiplication, known as Guided Grad-CAM, it enables the generation of high-resolution and class-discriminative visualizations [23].
2.1.1. Saliency Maps
Saliency Maps, introduced by Simonyan et al. [27], is a gradient-based visualization technique that sheds light on the contribution of individual pixels in an image to its final classification made by a neural network. This method involves a backward pass through the network to calculate the gradients of the loss function with respect to the input’s pixels [28]. Doing so reveals the impact of each pixel during the back-propagation step, providing insights into how much each pixel affects the final classification, particularly concerning a specific class of interest. The results from Saliency Maps can be interpreted as another image, either the same size as the input image or easily projectable onto it, highlighting the most important pixels that attribute the image to a specific class [27].
2.1.2. Concept Activation Vectors (CAVs)
Concept Activation Vectors (CAVs) [29] represents an interpretability technique that offers global explanations for neural networks based on user-defined concepts [28]. To leverage CAVs, two datasets need to be gathered: one containing instances relevant to the desired concept and the other comprising unrelated images serving as a random reference. For a specific instance, a binary classifier is trained on these two datasets to classify between instances related to the concept of interest and unrelated ones. The CAV is then derived as the coefficient vector of this binary classifier. Testing with CAVs (TCAVs) allows averaging the concept-based contributions from the relevant dataset and comparing them to the contributions from the random dataset regarding the class of interest. Consequently, CAVs establish connections between high-level user-defined concepts and classes, both positively and negatively. This approach is particularly useful in the medical field, where medical specialists can conveniently relate the defined concepts with existing classes without delving into the intricacies of neural networks [29].
2.1.3. Deep Learning Important Features (DeepLift)
Deep Learning Important Features, commonly known as DeepLift [30], is an explainability method capable of determining contribution scores by comparing the difference in neuron activation to a reference behavior. By employing back-propagation, DeepLift quantifies the contribution of each input feature when decomposing the output prediction. By comparing the output difference between the original input and a reference input, DeepLift can assess how much an input deviates from the reference. One of the significant advantages of DeepLift is its ability to overcome issues related to gradient zeroing or discontinuities, making it less susceptible to misleading biases and capable of recognizing dependencies that other methods may overlook. However, carefully considering the reference input and output is essential for achieving meaningful results using DeepLift [30].
2.1.4. Layer-Wise Relevance Propagation (LRP)
Layer-wise Relevance Propagation (LRP) [31] is an explainability technique that provides transparent insights into complex neural network models, even with different input modalities like text, images, and videos. LRP propagates the prediction backward through the model, ensuring that the neurons’ received relevance is equally distributed among the lower layers. The proper set of parameters and LRP rules make achieving high-quality explanations for intricate models feasible.
2.1.5. Guided Back-Propagation
Guided back-propagation [32] is an explanation method that combines ReLU and deconvolution, wherein at least one of these is applied with masked negative values. By introducing a guidance signal from the higher layer to the typical back-propagation process, guided back-propagation prevents the backward flow of negative gradients, corresponding to the neurons that decrease visualized activation of the higher layer unit. This technique is particularly effective without switching, allowing visualization of a neural network’s intermediate and last layers.
3. Vision Transformer for Medical Images
ViTs have proven to be effective in solving a wide range of vision problems, thanks to their capability to capture long-range relationships in data. Unlike CNNs, which rely on the inductive bias of locality within their convolutional layers, vanilla ViTs directly learn these relationships from the data. However, the success of ViTs has also brought challenges in interpreting their decision-making process, mainly due to their long-range reasoning capabilities.
3.1. Black Box Methods
TransMed [33] is a pioneering work that introduces the use of Vision Transformers (ViTs) for medical image classification. Their architecture, TransMed, combines the strengths of convolutional neural networks (CNNs) for extracting low-level features and ViTs for encoding global context. TransMed focuses on classifying parotid tumors in multi-modal MRI medical images and employs a novel image fusion strategy to effectively capture mutual information from different modalities, yielding competitive results on their privately collected parotid tumor classification dataset.
The authors of Lu et al. [34] propose a two-stage framework for glioma sub-type classification in brain images. The framework performs contrastive pre-training and then uses a transformer-based sparse attention module for feature aggregation. Their approach demonstrates its effectiveness through ablation studies on the TCGA-NSCLC [35] dataset. The authors of Gheflati and Rivaz [36] systematically evaluated pure and hybrid pre-trained ViT models for breast cancer classification. Their experiments on two breast ultrasound datasets show that ViT-based models outperform CNNs in classifying images into benign, malignant, and normal categories.
Several other works employ hybrid Transformer–CNN architectures for medical image classification in different organs. For instance, Khan and Lee [37] propose Gene-Transformer to predict lung cancer subtypes, showcasing its superiority over CNN baselines on the TCGA-NSCLC [35] dataset. The authors of Chen et al. [38] presents a multi-scale GasHis–Transformer for diagnosing gastric cancer in the stomach, demonstrating strong generalization ability across other histopathological imaging datasets. The authoers of Jiang et al. [39] propose a hybrid model combining convolutional and transformer layers for diagnosing acute lymphocytic leukemia, utilizing a symmetric cross-entropy loss function.
3.2. Interpretable Vision Transformer
Interpretable vision models aim to reveal the most influential features contributing to a model’s decision. We can visualize the most influential region contributing to ViT’s predictions with methods such as saliency-based techniques and Grad-CAM. Thanks to their interpretability, these models are particularly valuable in building trust among physicians and patients, making them suitable for practical implementation in clinical settings. Table 1 provides a high-level overview of existing state-of-the-art interoperability methods that are specifically designed for transformer models. A naïve method that only visualizes the last attentive block will often be uninformative. In addition, some interoperability methods might be class-agnostic, which means the visualization remains the same for the prediction of all classes (e.g., rollout [40]). In contrast, some correlation methods can illustrate different interpretation results for different target classification results (e.g., transformer attribution [41]).
ViT-based methods can be used for COVID-19 diagnosis [42], where the low-level CXR features can be extracted from a pre-trained self-supervised backbone network. SimCLR [43] is a popular backbone using contrastive-learning-based model training methods. The backbone network extracts abnormal CXR feature embeddings from the CheXpert dataset [44]. The ViT model then uses these embeddings for high-level COVID-19 diagnosis. Extensive experiments on three CXR test datasets from different hospitals show their approach’s superiority over CNN-based models. They also validate the generalization ability of their method and use saliency map visualizations [41] for interpretability. Similarly, COVID-ViT [45] is another ViT-based model for classifying COVID from non-COVID images in the MIA-COVID19 challenge [46]. Their experiments on 3D CT lung images demonstrate the ViT-based approach’s superiority over the DenseNet baseline [47] in terms of F1 score.
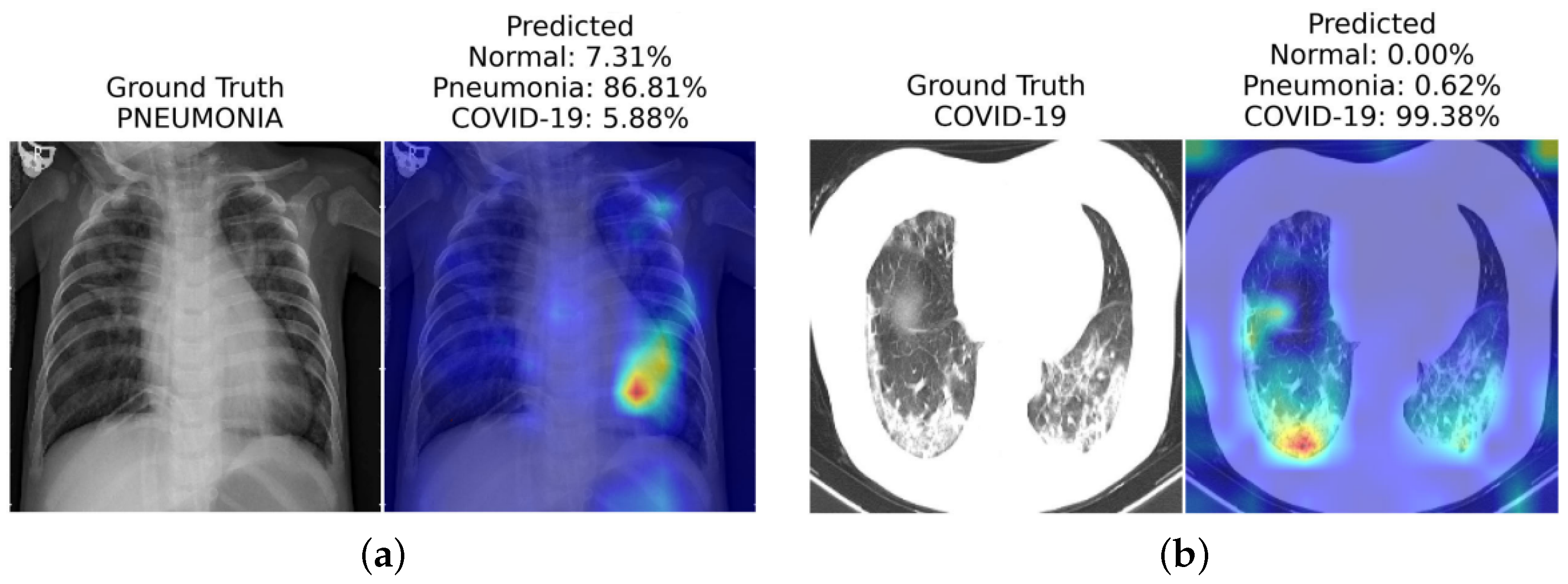
In another work, Mondal et al. [10] introduce xViTCOS for COVID-19 screening from lungs CT and X-ray images (see Figure 1). The xViTCOS model is first pre-trained on ImageNet to learn generic image representations, which is then further fine-tuned on a large chest radiographic dataset. Additionally, xViTCOS employs an explainability-driven saliency-based approach [41] with clinically interpretable visualizations to highlight the critical factors in the predictions. The model is experimentally evaluated on the COVID CT-2A dataset [48] for chest X-ray, which is effective in identifying abnormal cases.
Table 1. Summary table on interoperability approaches for transformer models. Class-specific refers to whether the approach can attribute different attentive scores that are specific to the predicted class (in multi-class predictions). Metrics used to evaluate each methods are pixel accuracy, mean average precision (mAP), mean F1 score (mF1), and mean intersection over union (mIoU).
| Interoperability Method | Class Specific? |
Metrics | Highlights and Summary | |||
|---|---|---|---|---|---|---|
| Pixel Acc. | mAP | mF1 | mIoU | |||
| Raw Attention | 67.87 | 80.24 | 29.44 | 46.37 | Raw attention only consider the attention map of the last block of the transformer architecture | |
| Rollout [40] | 73.54 | 84.76 | 43.68 | 55.42 | Rollout assume a linear Combination of tokens and quantify the influence of skip connections with identity mateix | |
| GradCAM [23] | ✓ | 65.91 | 71.60 | 19.42 | 41.30 | Provides a class-specific explanation by adding weights to gradient based feature map |
| Partial LRP [49] | 76.31 | 84.67 | 38.82 | 57.95 | Considers the information flow within the network by identifying the most important heads in each encoder layer through relevance propagation | |
| Transformer Attribution [41] | ✓ | 76.30 | 85.28 | 41.85 | 58.34 | Combines relevancy and attention-map gradient by regarding the gradient as a weight to the relevance for certain prediction task |
| Generic Attribution [50] | ✓ | 79.68 | 85.99 | 40.10 | 61.92 | Generic attribution extends the usage of Transformer attribution to co-attention and self-attention based models with a generic relevancy update rule |
| Token-wise Approx. [51] | ✓ | 82.15 | 88.04 | 45.72 | 66.32 | Uses head-wise and token-wise approximations to visualize tokens interaction in the pooled vector with noise-decreasing strategy |
The authors of Shome et al. [52] have introduced another ViT-based model for the diagnosis of COVID-19 infection at a large scale. They combined multiple open-source COVID-19 CXR datasets to accomplish this, forming a comprehensive multi-class and binary classification dataset. In order to enhance visual representation and model interpretability, they implemented Grad-CAM-based visualization [23]. The Transformer-based Multiple Instance Learning (TransMIL) architectures proposed by Shao et al. [53] aims to address whole slide brain tumor classification. Their approach involves embedding patches from whole slide images (WSI) into the feature space of a ResNet-50 model. Subsequently, the sequence of embedded features undergoes a series of processing steps in their proposed pipeline, including squaring the sequence, correlation modeling, conditional position encoding using the Pyramid Position Encoding Generator (PPEG) module, local information fusion, feature aggregation, and mapping from the transformer space to the label space. This innovative approach holds promise for accurate brain tumor classification, as illustrated in their work [53]. The self-attention module in transformers can leverage global interactions between encoder features, while cross-attention in the skip connections allows a fine spatial recovery. For example, Figure 2 highlights the attention level across the whole image for a segmentation task in a U-Net Transformer architecture [54][55].
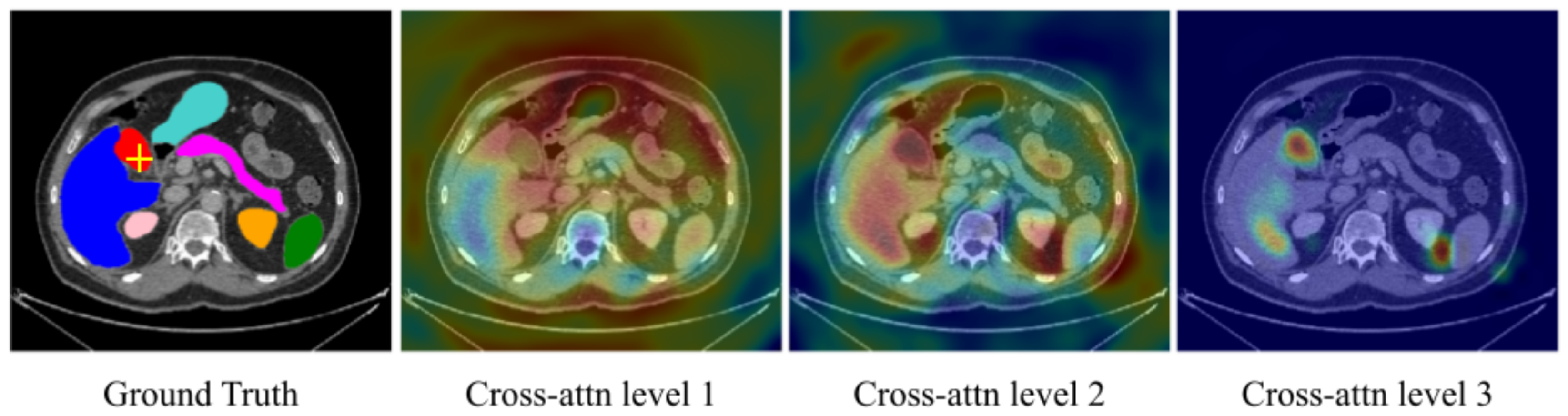
Figure 2. Cross-attention maps with U-Transformer [55] for the yellow-crossed pixel (left image). The attention maps at each level highlight the different regions contributing to the segmentation. “Cross-attention Level 1” is an earlier layer focusing on a wide image region. In contrast, we can see that “Cross-attention Level 3”, which is closer to the model output, corresponds to high-resolution feature maps and focuses on more specific regions that explain its predictions.
In whole slide imaging (WSI)-based pathology diagnosis, annotating individual instances can be expensive and laborious. Therefore, a label is assigned to a set of instances known as a “bag”. This weakly supervised learning type is called Multiple Instance Learning (MIL) [56], where a bag is labeled positive if at least one instance is positive or negative when all instances in a bag are negative. However, most current MIL methods assume that the instances in each bag are independent and identically distributed, overlooking any correlations among different instances.
To address this limitation, Shao et al. [53] proposes TransMIL, a novel approach that explores morphological and spatial information in weakly supervised WSI classification. Their method aggregates morphological information using two transformer-based modules and a position encoding layer. To encode spatial information, they introduce a pyramid position encoding generator. TransMIL achieves state-of-the-art performance on three computational pathology datasets: CAMELYON16 (breast) [57], TCGA-NSCLC (lung) [35], and TCGA-R (kidney). Their approach demonstrates superior performance and faster convergence than CNN-based state-of-the-art methods, making it a promising and interpretable solution for histopathology classification. Attention-based ViT can further derive instance probability for highlighting regions of interest. For example, AB-MIL [58] uses the derivation of instance probability for feature distillation as shown in Figure 3. The attentive method can also be used for interpreting the classification of retinal images [59].

Figure 3. Visualization of the probability derivation output from [58] lung cancer region detection. Each pair of images contains (left) ground truth with the tumor regions delineated by blue lines and (right) the probability derivation output. Brighter cyan colors indicate higher probabilities of being tumors for the corresponding locations. We can see that most high cyan region localizes the positive detection regions.
For the diagnosis of lung tumors, Zheng Zheng et al. [60] proposes the graph transformer network (GTN), leveraging the graph-based representation of WSI. GTN consists of a graph convolutional layer [61], a transformer, and a pooling layer. Additionally, GTN utilises GraphCAM [41] to identify regions highly associated with the class label. Thorough evaluations on the TCGA dataset [35] demonstrate the effectiveness of GTN in accurately diagnosing lung tumors. This graph-based approach provides valuable insights into the spatial relationships among regions, enhancing the interpretability of the classification results.
References
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep learning-enabled medical computer vision. NPJ Digit. Med. 2021, 4, 5.
- Shung, K.K.; Smith, M.B.; Tsui, B.M. Principles of Medical Imaging; Academic Press: Cambridge, MA, USA, 2012.
- Hu, B.; Vasu, B.; Hoogs, A. X-MIR: EXplainable Medical Image Retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 440–450.
- Lucieri, A.; Bajwa, M.N.; Braun, S.A.; Malik, M.I.; Dengel, A.; Ahmed, S. ExAID: A Multimodal Explanation Framework for Computer-Aided Diagnosis of Skin Lesions. arXiv 2022, arXiv:2201.01249.
- Stieler, F.; Rabe, F.; Bauer, B. Towards Domain-Specific Explainable AI: Model Interpretation of a Skin Image Classifier using a Human Approach. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1802–1809.
- Lucieri, A.; Bajwa, M.N.; Braun, S.A.; Malik, M.I.; Dengel, A.; Ahmed, S. On interpretability of deep learning based skin lesion classifiers using concept activation vectors. In Proceedings of the 2020 international joint conference on neural networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–10.
- Lenis, D.; Major, D.; Wimmer, M.; Berg, A.; Sluiter, G.; Bühler, K. Domain aware medical image classifier interpretation by counterfactual impact analysis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2020; pp. 315–325.
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays. Comput. Methods Programs Biomed. 2020, 196, 105608.
- Corizzo, R.; Dauphin, Y.; Bellinger, C.; Zdravevski, E.; Japkowicz, N. Explainable image analysis for decision support in medical healthcare. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 4667–4674.
- Mondal, A.K.; Bhattacharjee, A.; Singla, P.; Prathosh, A. xViTCOS: Explainable vision transformer based COVID-19 screening using radiography. IEEE J. Transl. Eng. Health Med. 2021, 10, 1–10.
- Bang, J.S.; Lee, M.H.; Fazli, S.; Guan, C.; Lee, S.W. Spatio-Spectral Feature Representation for Motor Imagery Classification Using Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3038–3049.
- Li, J.; Shi, H.; Hwang, K.S. An explainable ensemble feedforward method with Gaussian convolutional filter. Knowl.-Based Syst. 2021, 225, 107103.
- Mohagheghi, S.; Foruzan, A.H. Developing an explainable deep learning boundary correction method by incorporating cascaded x-Dim models to improve segmentation defects in liver CT images. Comput. Biol. Med. 2022, 140, 105106.
- Hu, H.; Lai, T.; Farid, F. Feasibility Study of Constructing a Screening Tool for Adolescent Diabetes Detection Applying Machine Learning Methods. Sensors 2022, 22, 6155.
- Yang, S.; Zhu, F.; Ling, X.; Liu, Q.; Zhao, P. Intelligent Health Care: Applications of Deep Learning in Computational Medicine. Front. Genet. 2021, 12, 607471.
- Lai, T.; Shi, Y.; Du, Z.; Wu, J.; Fu, K.; Dou, Y.; Wang, Z. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. arXiv 2023, arXiv:2307.11991.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929.
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep learning applications in medical image analysis. IEEE Access 2017, 6, 9375–9389.
- MacDonald, S.; Steven, K.; Trzaskowski, M. Interpretable AI in healthcare: Enhancing fairness, safety, and trust. In Artificial Intelligence in Medicine: Applications, Limitations and Future Directions; Springer: Berlin/Heidelberg, Germany, 2022; pp. 241–258.
- Ghosh, A.; Kandasamy, D. Interpretable artificial intelligence: Why and when. Am. J. Roentgenol. 2020, 214, 1137–1138.
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115.
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144.
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626.
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2016, arXiv:1606.03490.
- Freitas, A.A. Comprehensible Classification Models: A Position Paper. SIGKDD Explor. Newsl. 2014, 15, 1–10.
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. arXiv 2017, arXiv:1706.07269.
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualizing Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034.
- Molnar, C. Interpretable Machine Learning; Lulu Press: Morrisville, NC, USA, 2020.
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). arXiv 2017, arXiv:1711.11279.
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 3145–3153.
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140.
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806.
- Dai, Y.; Gao, Y.; Liu, F. Transmed: Transformers advance multi-modal medical image classification. Diagnostics 2021, 11, 1384.
- Lu, M.; Pan, Y.; Nie, D.; Liu, F.; Shi, F.; Xia, Y.; Shen, D. SMILE: Sparse-Attention based Multiple Instance Contrastive Learning for Glioma Sub-Type Classification Using Pathological Images. In Proceedings of the MICCAI Workshop on Computational Pathology, PMLR, Virtual Event, 27 September 2021; pp. 159–169.
- Napel, S.; Plevritis, S.K. NSCLC Radiogenomics: Initial Stanford Study of 26 Cases. The Cancer Imaging Archive2014. Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=6883610 (accessed on 29 July 2023).
- Gheflati, B.; Rivaz, H. Vision Transformers for Classification of Breast Ultrasound Images. arXiv 2021, arXiv:2110.14731.
- Khan, A.; Lee, B. Gene Transformer: Transformers for the Gene Expression-based Classification of Lung Cancer Subtypes. arXiv 2021, arXiv:2108.11833.
- Chen, H.; Li, C.; Li, X.; Wang, G.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; Yao, Y.; Teng, Y.; et al. GasHis-Transformer: A Multi-scale Visual Transformer Approach for Gastric Histopathology Image Classification. arXiv 2021, arXiv:2104.14528.
- Jiang, Z.; Dong, Z.; Wang, L.; Jiang, W. Method for Diagnosis of Acute Lymphoblastic Leukemia Based on ViT-CNN Ensemble Model. Comput. Intell. Neurosci. 2021, 2021, 7529893.
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928.
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 782–791.
- Park, S.; Kim, G.; Oh, Y.; Seo, J.B.; Lee, S.M.; Kim, J.H.; Moon, S.; Lim, J.K.; Ye, J.C. Vision Transformer for COVID-19 CXR Diagnosis using Chest X-ray Feature Corpus. arXiv 2021, arXiv:2103.07055.
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1597–1607.
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597.
- Gao, X.; Qian, Y.; Gao, A. COVID-VIT: Classification of COVID-19 from CT chest images based on vision transformer models. arXiv 2021, arXiv:2107.01682.
- Kollias, D.; Arsenos, A.; Soukissian, L.; Kollias, S. MIA-COV19D: COVID-19 Detection through 3-D Chest CT Image Analysis. arXiv 2021, arXiv:2106.07524.
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708.
- Gunraj, H.; Sabri, A.; Koff, D.; Wong, A. COVID-Net CT-2: Enhanced Deep Neural Networks for Detection of COVID-19 from Chest CT Images Through Bigger, More Diverse Learning. arXiv 2021, arXiv:2101.07433.
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019.
- Chefer, H.; Gur, S.; Wolf, L. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021; pp. 397–406.
- Chen, J.; Li, X.; Yu, L.; Dou, D.; Xiong, H. Beyond Intuition: Rethinking Token Attributions inside Transformers. Transactions on Machine Learning Research. 2023. Available online: https://openreview.net/pdf?id=rm0zIzlhcX (accessed on 29 July 2023).
- Shome, D.; Kar, T.; Mohanty, S.N.; Tiwari, P.; Muhammad, K.; AlTameem, A.; Zhang, Y.; Saudagar, A.K.J. COVID-Transformer: Interpretable COVID-19 Detection Using Vision Transformer for Healthcare. Int. J. Environ. Res. Public Health 2021, 18, 11086.
- Shao, Z.; Bian, H.; Chen, Y.; Wang, Y.; Zhang, J.; Ji, X.; Zhang, Y. TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication. arXiv 2021, arXiv:2106.00908.
- Huang, J.; Xing, X.; Gao, Z.; Yang, G. Swin deformable attention u-net transformer (sdaut) for explainable fast mri. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 538–548.
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-net transformer: Self and cross attention for medical image segmentation. In Proceedings of the Machine Learning in Medical Imaging: 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2021; pp. 267–276.
- Fung, G.; Dundar, M.; Krishnapuram, B.; Rao, R.B. Multiple instance learning for computer aided diagnosis. Adv. Neural Inf. Process. Syst. 2007, 19, 425.
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. Jama 2017, 318, 2199–2210.
- Zhang, H.; Meng, Y.; Zhao, Y.; Qiao, Y.; Yang, X.; Coupland, S.E.; Zheng, Y. DTFD-MIL: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18802–18812.
- Playout, C.; Duval, R.; Boucher, M.C.; Cheriet, F. Focused attention in transformers for interpretable classification of retinal images. Med. Image Anal. 2022, 82, 102608.
- Zheng, Y.; Gindra, R.; Betke, M.; Beane, J.; Kolachalama, V.B. A deep learning based graph-transformer for whole slide image classification. medRxiv 2021.
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907.
More
Information
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
891
Revisions:
2 times
(View History)
Update Date:
18 Jan 2024
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No