Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Alexandra Pereira Nunes | -- | 1209 | 2023-12-05 11:55:13 | | | |
| 2 | Camila Xu | -115 word(s) | 1094 | 2023-12-06 02:03:59 | | | | |
| 3 | Camila Xu | Meta information modification | 1094 | 2023-12-06 02:05:14 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Nunes, A.; Matos, A. Improving Semantic Segmentation Performance in Underwater Images. Encyclopedia. Available online: https://encyclopedia.pub/entry/52374 (accessed on 26 July 2026).
Nunes A, Matos A. Improving Semantic Segmentation Performance in Underwater Images. Encyclopedia. Available at: https://encyclopedia.pub/entry/52374. Accessed July 26, 2026.
Nunes, Alexandra, Aníbal Matos. "Improving Semantic Segmentation Performance in Underwater Images" Encyclopedia, https://encyclopedia.pub/entry/52374 (accessed July 26, 2026).
Nunes, A., & Matos, A. (2023, December 05). Improving Semantic Segmentation Performance in Underwater Images. In Encyclopedia. https://encyclopedia.pub/entry/52374
Nunes, Alexandra and Aníbal Matos. "Improving Semantic Segmentation Performance in Underwater Images." Encyclopedia. Web. 05 December, 2023.
Copy Citation
Semantic segmentation is an important task for the various fields of robotics, which often relies on visual data from cameras. Semantic segmentation is increasingly used in exploration by underwater robots, for example in autonomous navigation so that the robot can recognise the elements of its environment during the mission to avoid collisions. Other applications are found in the search for archaeological artefacts, in the inspection of underwater structures or in species monitoring.
semantic segmentation
data augmentation
enhancement techniques
underwater
visual information
1. Introduction
Semantic segmentation is an important task for the various fields of robotics, which often relies on visual data from cameras. Nowadays, it is increasingly used in robots for underwater exploration, especially for autonomous navigation when the robot needs to recognise the elements it encounters during the mission, for example, to avoid collisions. Likewise, it can be used in object recognition and in the search for archaeological artefacts or even in the inspection of underwater structures such as platforms, cables or pipelines.
Further applications can be found in marine biology and ecology in the identification of species, but also in the search and rescue of missing persons or in military defence, through the classification of mines. The main objective of this task is to assign each pixel of an image to a corresponding class of the represented image. This is a dense classification and often it is difficult to get good results in prediction. In traditional approaches, there are some problems with the accuracy of the results because the data obtained in underwater environments have challenges such as colour distortion, low contrast, noise or uneven illumination and for these reasons some important information is lost. In addition, traditional methods are generally not very transferable or robust, so the segmentation result of a single traditional method is poor in most cases. It is therefore necessary to resort to advanced approaches, often involving Deep Learning, to better address these underwater challenges.
Further applications can be found in marine biology and ecology in the identification of species, but also in the search and rescue of missing persons or in military defence, through the classification of mines. The main objective of this task is to assign each pixel of an image to a corresponding class of the represented image. This is a dense classification and often it is difficult to get good results in prediction. In traditional approaches, there are some problems with the accuracy of the results because the data obtained in underwater environments have challenges such as colour distortion, low contrast, noise or uneven illumination and for these reasons some important information is lost. In addition, traditional methods are generally not very transferable or robust, so the segmentation result of a single traditional method is poor in most cases. It is therefore necessary to resort to advanced approaches, often involving Deep Learning, to better address these underwater challenges.
Thus, the main purpose of this research was to find out if there are some approaches to augment the quality and diversity of training data commonly used in outdoor environments to improve the results of segmentation in the underwater context (see Figure 1).
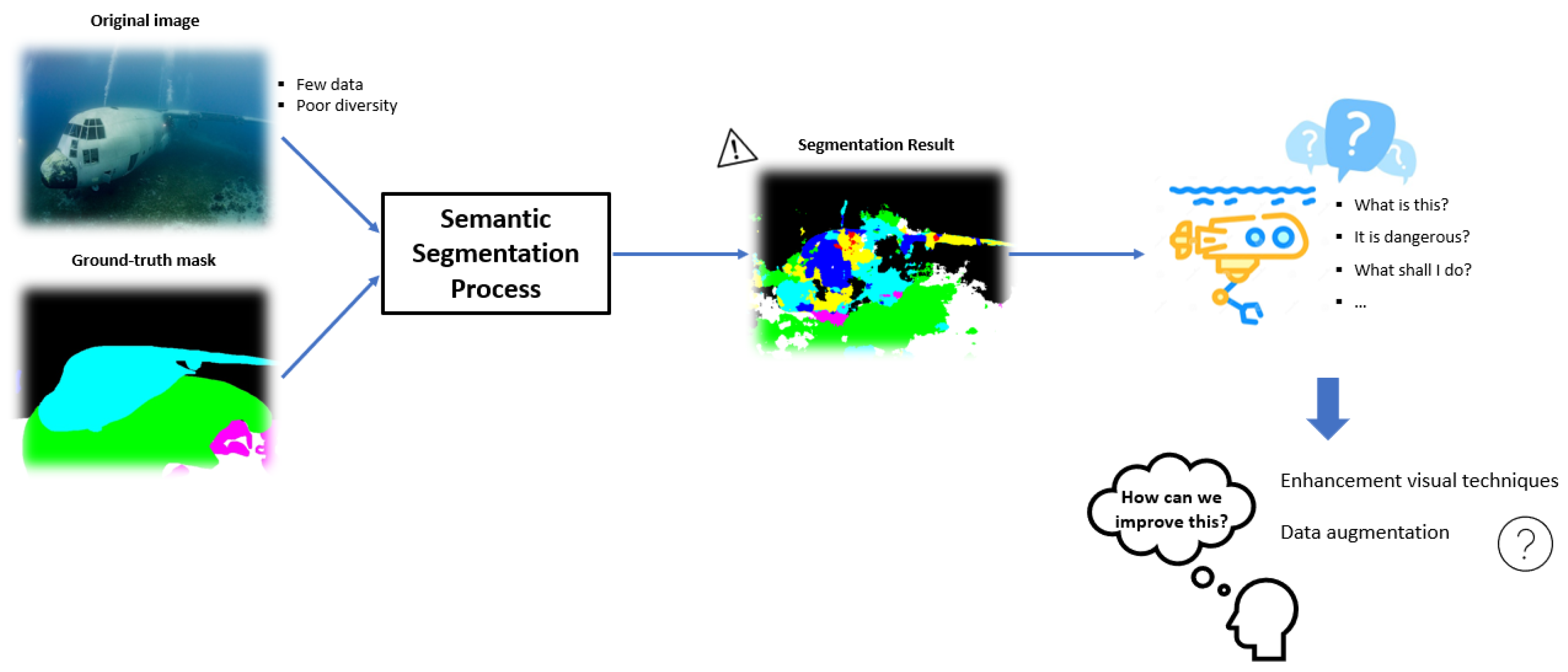
Figure 1. Diagram of the general framework of the proposal.
2. Auxiliary Techniques for Semantic Segmentation
According to the literature and all that is known about the visual conditions of this environment, there are high expectations of the improvements that the enhancement of visual data will bring to the results of all processes that need to manipulate underwater images, namely semantic segmentations. According to the current state of the art, there are several techniques for different enhancements. One of them deals with the restoration of true colours, another with filtering techniques to de-noise the image, and others that allow the removal of backscatter caused by tiny particles in the water that reflect light back to the camera. After some research in the literature and existing knowledge, it was decided to test only a few techniques, most of which enhance contrast and highlight the boundaries of objects (crucial for a good training process) and which have already performed well in another related task such as feature extraction. Therefore, three techniques were tested that seemed suitable for the intended application: Contrast Limited Adaptive Equalisation (CLAHE), White Balance (WB) and a third technique derived from diving experience that summarises some enhancements suitable for underwater imaging.Another reason for the poor results of semantic segmentation could be that the dataset is often too small compared to the need, and obtaining labelled datasets is expensive and time-consuming. Therefore, it is challenging to train the models with small datasets, and this dataset contains only about 1500 images. Another approach to improve the results is data augmentation, which consists of various techniques that change the appearance of the images, e.g. rotating, zooming, flipping, colour variations etc. In this way, the dataset can be enlarged. The use of data augmentation offers some advantages for Deep Learning methods, such as improving generalisation, increasing the robustness of the model to different variations in the input, using smaller datasets for some needed applications, and avoiding overfitting because the training data is more diverse. It is also worth noting that in most cases this approach is only used for the training dataset, as is the case in this research. In underwater scenarios, this is particularly important because, as explained earlier, underwater imagery presents many challenges and the model has to cope with all the changes and variations. Therefore, it was crucial in this context to take into account lighting changes, distortions and perspective changes. In addition, the water causes movement of the camera or objects during the shot and often additional noise occurs as the conditions for the shooting equipment are often not the best, etc. So, it is possible to get more images with only one image to better train the class of human divers. However, some of these changes are not useful for all scenarios as they change the sense of reality, e.g. when the seaweed appears at the bottom of the image. For example, vertical flipping is useful in some cases, especially when the camera captures images in an upper plane with respect to the object, i.e. images from the bottom of the underwater floor. But it is wrong in cases where the image is taken in front of the object, because the air bubbles that can never come down. In many cases, extreme transformations (flipping or rotating) must be avoided.
For this reason, it is important to ensure that this process does not provide misleading information. The data augmentation in this application assumes that the images are taken from a vehicle that does not rotate much along the x-axis. It is critical that the consistency of the data provided is maintained. The changes must represent reality and the greatest possible number of variations in the real world. There are already many methods of data augmentation to increase the size and diversity of datasets. However, when a segmented dataset is needed, the transformation must be applied to each image while keeping the ground truth consistent. Sometimes it is non-trivial to maintain this so as not to add false information or, for example, black pixels during the rotation transformation. To solve this problem, it is often necessary to add a crop to the result of the first transformation. But not all transformations require an intervention in the mask, such as the changes in the colour information of the image, where there are no changes in the position or size of the objects.
Information
Subjects:
Engineering, Ocean
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
444
Revisions:
3 times
(View History)
Update Date:
06 Dec 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No