Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Tang, J.; Ding, X.; Hu, D.; Guo, B.; Shen, Y.; Ma, P.; Jiang, Y. Heterogeneous Federated Learning via Relational Adaptive Distillation. Encyclopedia. Available online: https://encyclopedia.pub/entry/50241 (accessed on 26 July 2026).
Tang J, Ding X, Hu D, Guo B, Shen Y, Ma P, et al. Heterogeneous Federated Learning via Relational Adaptive Distillation. Encyclopedia. Available at: https://encyclopedia.pub/entry/50241. Accessed July 26, 2026.
Tang, Jianwu, Xuefeng Ding, Dasha Hu, Bing Guo, Yuncheng Shen, Pan Ma, Yuming Jiang. "Heterogeneous Federated Learning via Relational Adaptive Distillation" Encyclopedia, https://encyclopedia.pub/entry/50241 (accessed July 26, 2026).
Tang, J., Ding, X., Hu, D., Guo, B., Shen, Y., Ma, P., & Jiang, Y. (2023, October 13). Heterogeneous Federated Learning via Relational Adaptive Distillation. In Encyclopedia. https://encyclopedia.pub/entry/50241
Tang, Jianwu, et al. "Heterogeneous Federated Learning via Relational Adaptive Distillation." Encyclopedia. Web. 13 October, 2023.
Copy Citation
As the development of the Internet of Things (IoT) continues, Federated Learning (FL) is gaining popularity as a distributed machine learning framework that does not compromise the data privacy of each participant. However, the data held by enterprises and factories in the IoT often have different distribution properties (Non-IID), leading to poor results in their federated learning.
federated learning
data heterogeneity
catastrophic forgetting
1. Introduction
With the growth of the Internet of Things and advances in Big Data-driven artificial intelligence, the network’s data are increasingly created by geographically distributed enterprise endpoints and IoT devices. The IoT in the context of Big Data is growing rapidly in the industrial sector. However, centralized aggregation of industrial Big Data to cloud servers leads to unaffordable transmission overheads and also violates the data privacy of each enterprise or client, which results in distributed databases consisting of multiple “data islands”. In light of the challenges posed by “data islands” in the development and application of the Internet of Things, Federated Learning (FL) [1] was first proposed in 2016 for collaborative learning with privacy constraints. It has been widely used in the IoT tasks such as smart cities [2], healthcare [3][4][5] and financial security [6]. Meanwhile, in the industrial Internet of Things, the use of federated learning to enable collaborative training of all parties while ensuring sensitive enterprise data is gradually becoming mainstream.
Although federated learning does not require centralized data aggregation to the cloud, however, there will be skewed distribution of data across enterprises during practical applications, which will lead to degradation of FL performance. For example, the data collected for mobile terminal input methods have different distributions for people with different operating habits. There are also many differences in the distribution of sensor acquisition data used by different plants to classify equipment faults or detect quality defects, both in terms of sensor type acquisition differences and fault type distribution differences. Wearable IoT sensor data for monitoring patient vital signs in the medical field are also heavily used for artificial intelligence learning to enable online diagnostics such as expert systems. However, the data collected by these edge IoT devices still suffer from inconsistencies in the distribution of features and labels. In summary, this huge challenge called Non-IID hinders the application of federated learning in IoT in the context of Big Data, and this research aims to propose a generalized method to address this challenge in federal learning for IoT applications.
Similar to the problem in continuous learning [7], this variation among distributions causes each client to forget the global knowledge during their local updates, which in turn severely affects the performance and convergence in federated learning [8][9]. Figure 1 illustrates the catastrophic forgetting in continuous learning and federated learning. This phenomenon is referred to as “Client-drift” in [10]. FedProx [11] constrains the local updates by adding a regularization term to the local objective function to regulate its update direction towards the global objective. In recent years, knowledge distillation [12] is widely used for transferring knowledge between models to serve the purpose of compressing model size and improving model accuracy. In order to get a more robust global model, ref. [13] combines federated learning with knowledge distillation to fine-tune the global model after aggregation with an additional public dataset. Ref. [14] applies large model self-distillation on the server side to better maintain global knowledge. All these methods require an auxiliary public dataset for knowledge distillation, and FedGEMS even requires homogenous datasets for auxiliary data. Considering the existence of the forgetting phenomenon in federated learning, which is similar to continuous learning, especially in the case of data heterogeneity, this research attempts to introduce knowledge distillation in the local training phase, using collaborative distillation of global and local models to retain each other’s knowledge. Inspired by Relational KD [15], the high-dimensional relational knowledge naturally contained in a global model is distilled after each aggregation to achieve better performance in combination with single-sample knowledge. Relational knowledge distillation considers that “relationships” among knowledge are more representative of the teacher’s “knowledge” than separate representations. Similar to the view in linguistic structuralism [16], which focuses on structural relationships in symbolic systems, primary information is often located in structural relationships in the data embedding space rather than existing independently. Meanwhile, in order to weigh the effect of constraints on single-sample knowledge versus relational knowledge, this research introduces an adaptive coefficient module to dynamically adjust its constraints.
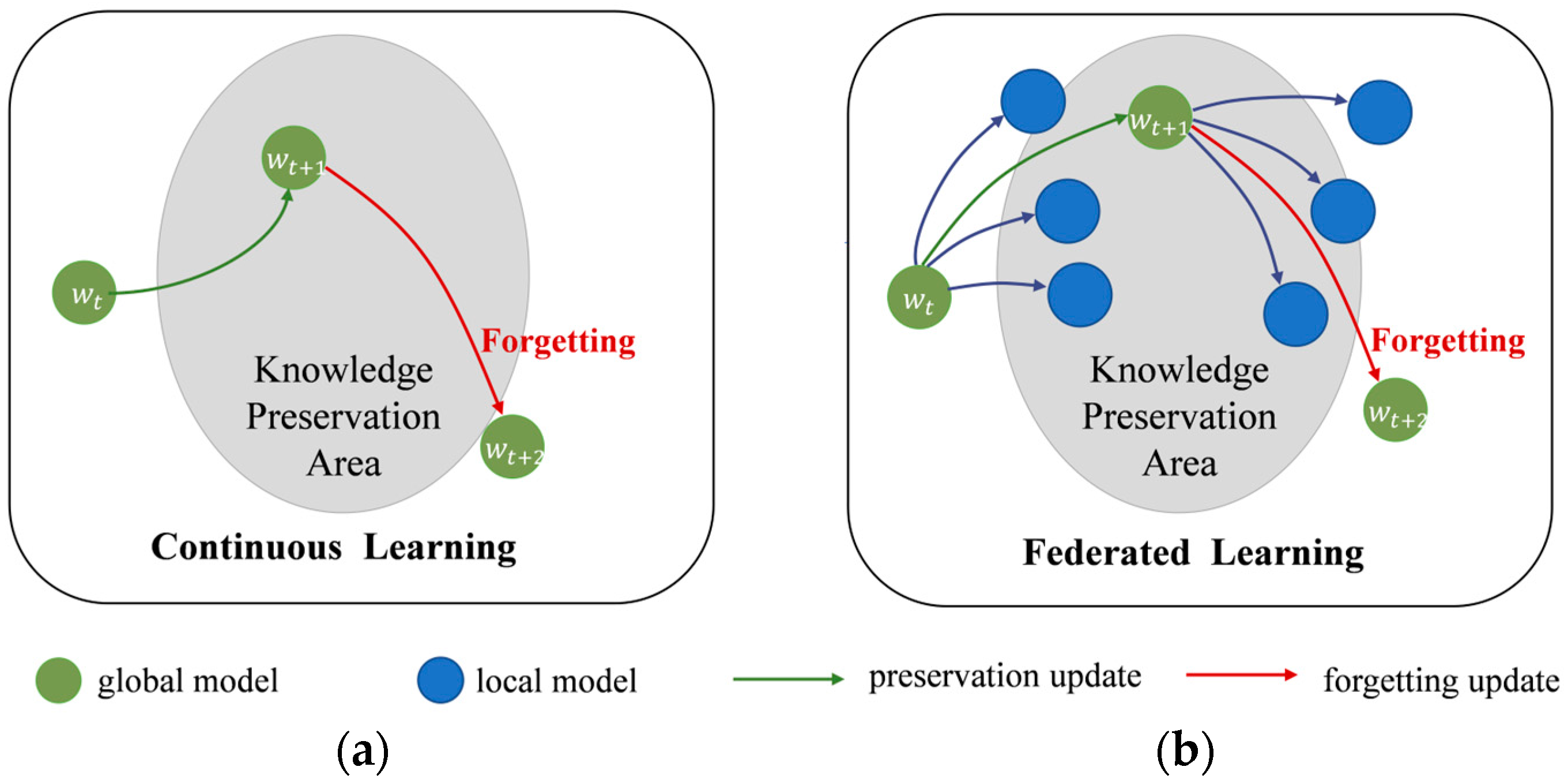
Figure 1. Catastrophic forgetting. (a) Forgetting in continuous learning; (b) forgetting in federated learning.
Inspired by above considerations, researchers propose a relational adaptive distillation paradigm called Relational Adaptive Distillation for Heterogeneous Federated Learning, abbreviated as FedRAD. The aggregated global model is downloaded by the selected clients during each round of communication and collaboratively distilled [17] with their own local models, transmitting both single-sample knowledge based on classical knowledge distillation and relational knowledge based on high-dimensional structural representations. This method can fully exploit the potential of knowledge distillation to exploit various types of knowledge in distributed data, which helps to motivate local models to learn higher dimensional knowledge representations from global models and minimize the forgetting phenomenon of local training in data heterogeneous scenarios. To better weigh the penalty focus of single-sample knowledge versus relational knowledge, researchers further propose an entropy-wise adaptive weight (EWAW) strategy to help local models adaptively control the impact of distillations based on the global model’s predictions on each data batch to prevent excessive transfer of negative knowledge. When the prediction of the global model is plausible, the local model learns the single-sample knowledge and relational knowledge in a balanced way. Otherwise, the local model focuses more on relational knowledge.
2. Federated Learning
With the emergence of various data privacy protection requirements, secure multi-party computing [18][19] is commonly used in the past as the major method to resolve the conflict between data confidentiality and sharing in the IoT. However, its huge error accumulation and high computational cost in deep learning applications make it difficult for it to be competent for deep learning scenarios. In contrast, federated learning is widely used in deep learning as an emerging distributed learning paradigm. FedAvg [1] is a traditional classical federated learning paradigm, where the parameters or gradients of all local models are aggregated by the server to form a global model after some local updates are performed by each client, and the aggregation weights are proportional to the local data size. A key challenge of this classical paradigm is that the clients’ data are usually non-identically distributed (Non-IID). Many works have attempted to solve the Non-IID problem by improving the server aggregation phase or the local training phase. Refs. [20][21] start from a clustering perspective by assuming that there are differences in the similarity of data distributions among different clients, assigning similar clients into a cluster and implementing global model training within each cluster to reduce the impact of non-identical distributions. These methods are premised on the assumption of similarity in the distribution of client data, perform poorly in scenarios where the distribution of client data varies too much and fail to truly address the forgetting phenomenon that occurs during local training. Refs. [11][22][23] aim to improve the local training phase by adding a regularization term to local model as a constraint to adjust the deviation between local and global models and reduce the client drift phenomenon. Another technical route is to improve the server-side aggregation phase [24][25].
3. Knowledge Distillation in FL
Knowledge distillation can transfer knowledge from large teacher models to small student models and is widely used for model compression [26][27] and collaborative learning among students to improve performance [17][28]. In order to address data heterogeneity, knowledge distillation applied to federated learning has proven to be an effective approach. Many works take aim at ensemble distillation, i.e., transferring knowledge to a global model as the student by aggregating client knowledge as the teacher. Ref. [29] use transfer learning on public datasets and ensemble distillation on the client side to improve model performance and reduce communication consumption. This is achieved by accomplishing knowledge transfer while exchanging only model predictions rather than model parameters. Ref. [13] combine federated learning with knowledge distillation to fine-tune the global model after aggregation with an additional public dataset in order to get a more robust global model. Ref. [14] improve on FedMD by holding a large model on the server side for self-distillation to better preserve global knowledge, which also avoids the forgetting of knowledge by the model. However, all these FL methods above require an additional public dataset similar to the client’s private datasets for knowledge distillation, and these carefully prepared public datasets are not always available. Some recent works attempt to extract knowledge without using additional public datasets: Ref. [30] aggregates and averages the logits in different classes transferred by each client on the server side for distribution as distillation knowledge in order to avoid reliance on public datasets. However, this method directly averages all logit of the same class, which tends to blur the knowledge across clients. Ref. [31] combine split learning to split the local model into a feature extraction network and a classification network, which use the intermediate features as inputs transmitted to the server-side classification network for knowledge distillation. This approach reduces the high computing power requirements for edge computing but performs poorly in the data heterogeneity scenario. Ref. [32] propose that the triangular upper bound of the federated learning objective function should be optimized especially in Non-IID scenarios, where both local training and knowledge distillation are used to lower the upper bound to improve performance. Refs. [33][34][35] use a pre-trained generator to generate pseudo data as a public dataset to assist in training, e.g., FedFTG trains a generator against the global model to generate difficult pseudo data in order to assist in training the global model to avoid forgetting. However, these methods of using a generator to add data require extremely high-quality generated samples, and often need a large computational cost to obtain high-quality samples. Ref. [36] perform knowledge distillation in the local training phase by broadcasting local data representations and the corresponding soft predictions, which is named “hyper-knowledge”. This method has some similarity to ours, without the need for generative model and public datasets, but is more concerned with balancing the performance of the local and global models.
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282.
- Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; Li, K. Applications of Federated Learning in Smart Cities: Recent Advances, Taxonomy, and Open Challenges. Connect. Sci. 2022, 34, 1–28.
- Liu, Q.; Chen, C.; Qin, J.; Dou, Q.; Heng, P.-A. FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 1013–1023.
- Vaid, A.; Jaladanki, S.; Xu, J.; Teng, S.; Kumar, A.; Lee, S.; Somani, S.; Paranjpe, I.; Freitas, J.; Wanyan, B.; et al. Federated Learning of Electronic Health Records to Improve Mortality Prediction in Hospitalized Patients with COVID-19: Machine Learning Approach. JMIR Med. Inform. 2021, 9, e24207.
- Zhao, L.; Huang, J. A Distribution Information Sharing Federated Learning Approach for Medical Image Data. Complex Intell. Syst. 2023, 2023, 1–12.
- Byrd, D.; Polychroniadou, A. Differentially Private Secure Multi-Party Computation for Federated Learning in Financial Applications. In Proceedings of the ICAIF ’20: The First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 16:1–16:9.
- Ring, M.B. Child: A First Step Towards Continual Learning. In Learning to Learn; Thrun, S., Pratt, L.Y., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 261–292.
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582.
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020.
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 5132–5143.
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. In Proceedings of the Machine Learning and Systems 2020, MLSys 2020, Austin, TX, USA, 2–4 March 2020.
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531.
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble Distillation for Robust Model Fusion in Federated Learning. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020.
- Cheng, S.; Wu, J.; Xiao, Y.; Liu, Y. FedGEMS: Federated Learning of Larger Server Models via Selective Knowledge Fusion. arXiv 2021, arXiv:2110.11027.
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational Knowledge Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 3967–3976.
- Matthews, P. A Short History of Structural Linguistics; Cambridge University Press: Cambridge, UK, 2001; ISBN 978-0-521-62568-5.
- Anil, R.; Pereyra, G.; Passos, A.; Ormándi, R.; Dahl, G.E.; Hinton, G.E. Large Scale Distributed Neural Network Training through Online Distillation. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018.
- Yao, A.C.-C. Protocols for Secure Computations (Extended Abstract). In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science, Chicago, IL, USA, 3–5 November 1982; pp. 160–164.
- Yao, A.C.-C. How to Generate and Exchange Secrets (Extended Abstract). In Proceedings of the 27th Annual Symposium on Foundations of Computer Science, Toronto, ON, Canada, 27–29 October 1986; pp. 162–167.
- Sattler, F.; Müller, K.-R.; Samek, W. Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3710–3722.
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 19586–19597.
- Hanzely, F.; Richtárik, P. Federated Learning of a Mixture of Global and Local Models. arXiv 2020, arXiv:2002.05516.
- Dinh, C.T.; Tran, N.H.; Nguyen, T.D. Personalized Federated Learning with Moreau Envelopes. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020.
- Chen, H.-Y.; Chao, W.-L. FedBE: Making Bayesian Model Ensemble Applicable to Federated Learning. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021.
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.S.; Khazaeni, Y. Federated Learning with Matched Averaging. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020.
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020.
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for BERT Model Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4322–4331.
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328.
- Li, D.; Wang, J. FedMD: Heterogenous Federated Learning via Model Distillation. arXiv 2019, arXiv:1910.03581.
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data. arXiv 2018, arXiv 1811.11479.
- He, C.; Annavaram, M.; Avestimehr, S. Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020.
- Li, X.; Chen, B.; Lu, W. FedDKD: Federated Learning with Decentralized Knowledge Distillation. Appl. Intell. 2023, 53, 18547–18563.
- Zhang, L.; Shen, L.; Ding, L.; Tao, D.; Duan, L.-Y. Fine-Tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 10164–10173.
- Zhu, Z.; Hong, J.; Zhou, J. Data-Free Knowledge Distillation for Heterogeneous Federated Learning. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Volume 139, pp. 12878–12889.
- Zhang, L.; Wu, D.; Yuan, X. FedZKT: Zero-Shot Knowledge Transfer towards Resource-Constrained Federated Learning with Heterogeneous On-Device Models. In Proceedings of the 42nd IEEE International Conference on Distributed Computing Systems, ICDCS 2022, Bologna, Italy, 10–13 July 2022; pp. 928–938.
- Chen, H.; Wang, C.; Vikalo, H. The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation. In Proceedings of the Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, 1–5 May 2023.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
661
Revisions:
2 times
(View History)
Update Date:
13 Oct 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No