Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Dasha Hu and Version 2 by Rita Xu.
As the development of the Internet of Things (IoT) continues, Federated Learning (FL) is gaining popularity as a distributed machine learning framework that does not compromise the data privacy of each participant. However, the data held by enterprises and factories in the IoT often have different distribution properties (Non-IID), leading to poor results in their federated learning.
- federated learning
- data heterogeneity
- catastrophic forgetting
1. Introduction
With the growth of the Internet of Things and advances in Big Data-driven artificial intelligence, the network’s data are increasingly created by geographically distributed enterprise endpoints and IoT devices. The IoT in the context of Big Data is growing rapidly in the industrial sector. However, centralized aggregation of industrial Big Data to cloud servers leads to unaffordable transmission overheads and also violates the data privacy of each enterprise or client, which results in distributed databases consisting of multiple “data islands”. In light of the challenges posed by “data islands” in the development and application of the Internet of Things, Federated Learning (FL) [1] was first proposed in 2016 for collaborative learning with privacy constraints. It has been widely used in the IoT tasks such as smart cities [2], healthcare [3][4][5][3,4,5] and financial security [6]. Meanwhile, in the industrial Internet of Things, the use of federated learning to enable collaborative training of all parties while ensuring sensitive enterprise data is gradually becoming mainstream.
Although federated learning does not require centralized data aggregation to the cloud, however, there will be skewed distribution of data across enterprises during practical applications, which will lead to degradation of FL performance. For example, the data collected for mobile terminal input methods have different distributions for people with different operating habits. There are also many differences in the distribution of sensor acquisition data used by different plants to classify equipment faults or detect quality defects, both in terms of sensor type acquisition differences and fault type distribution differences. Wearable IoT sensor data for monitoring patient vital signs in the medical field are also heavily used for artificial intelligence learning to enable online diagnostics such as expert systems. However, the data collected by these edge IoT devices still suffer from inconsistencies in the distribution of features and labels. In summary, this huge challenge called Non-IID hinders the application of federated learning in IoT in the context of Big Data, and this woresearchk aims to propose a generalized method to address this challenge in federal learning for IoT applications.
Similar to the problem in continuous learning [7], this variation among distributions causes each client to forget the global knowledge during their local updates, which in turn severely affects the performance and convergence in federated learning [8][9][8,9]. Figure 1 illustrates the catastrophic forgetting in continuous learning and federated learning. This phenomenon is referred to as “Client-drift” in [10]. FedProx [11] constrains the local updates by adding a regularization term to the local objective function to regulate its update direction towards the global objective. In recent years, knowledge distillation [12] is widely used for transferring knowledge between models to serve the purpose of compressing model size and improving model accuracy. In order to get a more robust global model, ref. [13] combines federated learning with knowledge distillation to fine-tune the global model after aggregation with an additional public dataset. Ref. [14] applies large model self-distillation on the server side to better maintain global knowledge. All these methods require an auxiliary public dataset for knowledge distillation, and FedGEMS even requires homogenous datasets for auxiliary data. Considering the existence of the forgetting phenomenon in federated learning, which is similar to continuous learning, especially in the case of data heterogeneity, this woresearchk attempts to introduce knowledge distillation in the local training phase, using collaborative distillation of global and local models to retain each other’s knowledge. Inspired by Relational KD [15], the high-dimensional relational knowledge naturally contained in a global model is distilled after each aggregation to achieve better performance in combination with single-sample knowledge. Relational knowledge distillation considers that “relationships” among knowledge are more representative of the teacher’s “knowledge” than separate representations. Similar to the view in linguistic structuralism [16], which focuses on structural relationships in symbolic systems, primary information is often located in structural relationships in the data embedding space rather than existing independently. Meanwhile, in order to weigh the effect of constraints on single-sample knowledge versus relational knowledge, this woresearchk introduces an adaptive coefficient module to dynamically adjust its constraints.
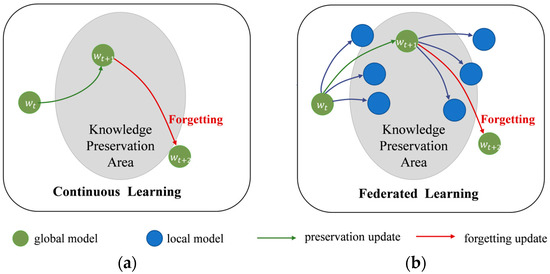
Figure 1. Catastrophic forgetting. (a) Forgetting in continuous learning; (b) forgetting in federated learning.
Inspired by above considerations, reswearchers propose a relational adaptive distillation paradigm called Relational Adaptive Distillation for Heterogeneous Federated Learning, abbreviated as FedRAD. The aggregated global model is downloaded by the selected clients during each round of communication and collaboratively distilled [17] with their own local models, transmitting both single-sample knowledge based on classical knowledge distillation and relational knowledge based on high-dimensional structural representations. This method can fully exploit the potential of knowledge distillation to exploit various types of knowledge in distributed data, which helps to motivate local models to learn higher dimensional knowledge representations from global models and minimize the forgetting phenomenon of local training in data heterogeneous scenarios. To better weigh the penalty focus of single-sample knowledge versus relational knowledge, researchwers further propose an entropy-wise adaptive weight (EWAW) strategy to help local models adaptively control the impact of distillations based on the global model’s predictions on each data batch to prevent excessive transfer of negative knowledge. When the prediction of the global model is plausible, the local model learns the single-sample knowledge and relational knowledge in a balanced way. Otherwise, the local model focuses more on relational knowledge.