Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Arika Ligmann-Zielinska | -- | 2037 | 2023-09-28 23:33:42 | | | |
| 2 | Dean Liu | Meta information modification | 2037 | 2023-09-29 03:57:39 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Paudel, R.; Ligmann-Zielinska, A. Data Extraction Approach for Empirical Agent-Based Model Development. Encyclopedia. Available online: https://encyclopedia.pub/entry/49786 (accessed on 25 July 2026).
Paudel R, Ligmann-Zielinska A. Data Extraction Approach for Empirical Agent-Based Model Development. Encyclopedia. Available at: https://encyclopedia.pub/entry/49786. Accessed July 25, 2026.
Paudel, Rajiv, Arika Ligmann-Zielinska. "Data Extraction Approach for Empirical Agent-Based Model Development" Encyclopedia, https://encyclopedia.pub/entry/49786 (accessed July 25, 2026).
Paudel, R., & Ligmann-Zielinska, A. (2023, September 28). Data Extraction Approach for Empirical Agent-Based Model Development. In Encyclopedia. https://encyclopedia.pub/entry/49786
Paudel, Rajiv and Arika Ligmann-Zielinska. "Data Extraction Approach for Empirical Agent-Based Model Development." Encyclopedia. Web. 28 September, 2023.
Copy Citation
Agent-based model (ABM) development needs information on system components and interactions. Qualitative narratives contain contextually rich system information beneficial for ABM conceptualization. Traditional qualitative data extraction is manual, complex, and time- and resource-consuming. Moreover, manual data extraction is often biased and may produce questionable and unreliable models. A possible alternative is to employ automated approaches borrowed from Artificial Intelligence.
agent-based modeling
natural language processing
unsupervised data extraction
1. Introduction
Qualitative data provide thick contextual information [1][2][3][4] that can support reliable complex system model development. Qualitative data analysis explores systems components, their complex relationships, and behavior [3][4][5]) and provides a structured framework that can guide the formulation of quantitative models [6][7][8][9][10]. However, qualitative research is complex, and time- and resource-consuming [1][4]. Data analysis usually involves keyword-based data extraction and evaluation that requires multiple coders to reduce biases. Moreover, model development using qualitative data requires multiple, lengthy, and expensive stakeholder interactions [11][12], which adds to its inconvenience. Consequently, quantitative modelers often avoid using qualitative data for their model development. Modelers often skip qualitative data analysis or use unorthodox approaches for framework development, which may lead to failed capturing of target systems’ complex dynamics and produce inaccurate and unreliable outputs [13].
The development in the information technology sector has substantially increased access to qualitative data over the past few decades. Harvesting extensive credible data is crucial for reliable model development. Increased access to voluminous data presents a challenge and an opportunity for model developers [14]. However, qualitative data analysis has always been a hard nut to crack for complex modelers. Most existing qualitative data analyses are highly supervised (i.e., performed mainly by humans) and hence, bias-prone and inefficient for large datasets.
This study proposes a methodology that uses an efficient, largely unsupervised qualitative data extraction for credible Agent-Based Model (ABM) development using Natural Language Processing (NLP) toolkits. ABM requires information on agents (emulating the target system’s decision makers), their attributes, actions, and interactions for its development. The development of a model greatly depends on its intended purpose. Abstract theoretical models concentrate on establishing new relationships and theories with less emphasis on data requirements and structure. In contrast, application-driven models aim to explain specific target systems and tend to be data-intensive. They require a higher degree of adherence to data requirements, validity, feasibility, and transferability [15][16][17]. Our methodology is particularly applicable to application-driven models rich in empirical data.
ABMs help understand phenomena that emerge from nonlinear interactions of autonomous and heterogeneous constituents of complex systems [18][19][20]. ABM is a bottom-up approach; interactions at the micro-level produce complex and emergent phenomena at a macro (higher) level. As micro-scale data become more accessible to the research community, modelers increasingly use empirical data for more realistic system representation and simulation [11][21][22][23][24].
Quantitative data are primarily useful as inputs for parameterizing and running simulations. Additionally, quantitative model outputs are also used for model verification and validation. Qualitative data, on the other hand, find uses at various stages of the model cycle [25]. Apart from the routine tasks of identifying systems constituents and behaviors for model development, qualitative data support the model structure and output representations [26][27]. Qualitative model representations facilitate communication for learning, model evaluation, and replication.
Various approaches have been proposed to conceptualize computational models. First of all, selected quantitative models have predefined structures for model representation. System dynamics, for instance, uses Causal Loop Diagrams as qualitative tools [28]. Causal Loop Diagrams elucidate systems components, their interrelationships, and feedback that can be used for learning and developing quantitative system dynamics models. ABM, however, does not have a predefined structure for model representation; models are primarily based on either highly theoretical or best-guess ad-hoc structures, which are problematic for model structural validation [16][29].
As a consequence, social and cognitive theories [30][31][32][33][34] often form the basis for translating qualitative data to empirical ABM [35]. Since social behavior is complex and challenging to comprehend, using social and cognition theories helps determine the system’s expected behavior. Moreover, using theories streamlines data management and analysis for model development.
Another school of thought bases model development on stakeholder cognition. Rather than relying mainly on social theories, this approach focuses on extracting empirical information about system components and behaviors. Participatory or companion modeling [36], as well as role-playing games [11], are some of the conventional approaches to eliciting stakeholder knowledge for model development [23][24]. Stakeholders usually develop model structures in real time, while some modelers prefer to process stakeholders’ information after the discussions. For instance, [37] employs computer technologies to post-process stakeholder responses to develop a rule-induction algorithm for her ABM.
Stakeholders are assumed to be the experts of their systems, and using their knowledge in model building makes the model valid and reliable. However, stakeholder involvement is not always feasible; for instance, when modeling remote places or historical events. In such cases, modelers resort to information elicitation tools for information extraction. In the context of ABM, translating empirical textual data into agent architecture is complex and requires concrete algorithms and structures [25][38]. Therefore, modelers first explore the context of the narratives and then identify potential context-specific scopes. Determining narrative elements becomes straightforward once context and scopes are identified [38].
Many ABM modelers have formulated structures for organizing qualitative data for model development. For instance, [39] used Institutional Analysis and Development framework for managing qualitative data in their Modeling Agent system based on Institutions Analysis (MAIA). MAIA comprises five structures: collective, constitutional, physical, operational, and evaluative. Information on agents is populated in a collective structure, while behavior rules and environment go in constitutional and physical structures. Similar frameworks were introduced by [40][41], to name but a few. However, all these structures use manual, slow, and bias-prone data processing and extraction. A potential solution presented in this paper is to employ AI tools, such as NLP, for unsupervised information extraction for model development [30].
2. The Proposed Framework
In response to these limitations, our study proposes and tests a largely unsupervised domain-independent approach for developing ABM structures from informal semi-structured interviews using Python-based semantic and syntactic NLP tools (Figure 1). The method primarily uses syntactic NLP approaches for information extraction directly to the object-oriented programming (OOP) framework (i.e., agents, attributes, and actions/interactions) using widely accepted approaches in database design and OOP [42]. Database designers and OOP programmers generally exploit the syntactic structure of sentences for information extraction. Syntactic analysis usually treats the subject of a sentence as a class (an entity for a database) and the main verb as a method (a relationship for a database). Since the approach is not based on machine learning, it does not require large training data. The semantic analysis is limited to external static datasets such as WordNet (https://wordnet.princeton.edu/) (accessed on 8 July 2020) and VerbNet (https://verbs.colorado.edu/verbnet/) (accessed on 21 July 2020).
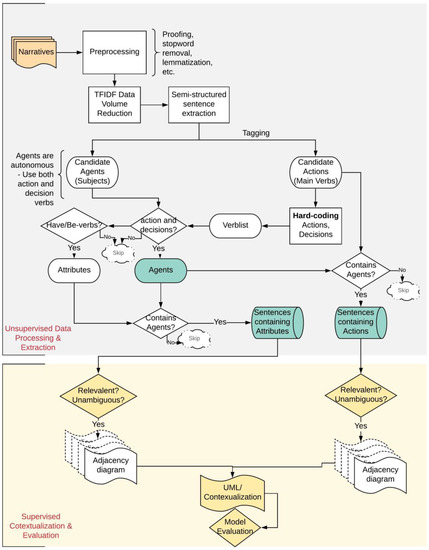
Figure 1. Largely unsupervised information extraction for ABM development. TFIDF: term frequency inverse document frequency.
In the proposed approach, information extraction includes systems agents, their actions, and interactions from qualitative data for model development using syntactic and semantic NLP tools. As our information extraction approach is primarily unsupervised and does not require manual interventions, researcher argue that, in addition to being efficient, it reduces the potential for subjectivity and biases arising from modelers’ preconceptions about target systems.
The extracted information is then represented using Unified Modeling Language (UML) for an object-oriented model development platform. UML is a standardized graphical representation of software development [43]. It has a set of well-defined class and activity diagrams that effectively represent the inner workings of ABMs [44]. UML diagrams represent systems classes, their attributes, and actions. Identified candidate agents, attributes, and actions were manually arranged in the UML structure for supporting model software development. Although there are other forms of graphical ABM representations such as Petri Nets [45], Conceptual Model for Simulation [29], and sequence and activity diagrams [46], UML is natural in representing ABM, named by [47] the default lingua franca of ABM.
In our approach, model development is mainly unsupervised and involves the following steps (Figure 1):
-
Unsupervised data processing and extraction;
-
Data preprocessing (cleaning and normalization);
-
Data volume reduction;
-
Tagging and information extraction;
-
Supervised contextualization and evaluation;
-
UML/Model conceptualization;
-
Model evaluation.
Steps one and two are required since semi-structured interviews often contain redundant or inflected texts that can bog down NLP analysis. Hence, removing non-informative contents from large textual data is highly recommended at the start of the analysis. NLP is well-equipped with stop words removal tools that can effectively remove redundant texts. Similarly, tools such as stemming and lemmatizing help normalize texts to their base forms [48].
Step three is data volume reduction, which can tremendously speed up NLP analyses. Traditional volume reduction approaches usually contain highly supervised keyword-based methods. Data analysts use predefined keywords to select and extract sentences perceived to be relevant [49]. Keyword identification generally requires a priori knowledge of the system and is often bias-prone. Consequently, researcher recommend a domain-independent unsupervised Term Frequency Inverse Document Frequency (TFIDF) approach [50] that eliminates manual keyword identification requirements. The approach provides weightage to individual words based on their uniqueness and machine-perceived importance. The TFIDF differentiates between important and common words by comparing their frequency in individual documents and across entire texts. Sentences that have high cumulative TFIDF scores are perceived to have higher importance. Given a document collection D, a word w, and an individual document d ε D, TFIDF can be defined as follows:
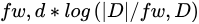 where fw,d equals the number of times w appears in d, |D| is the size of the corpus, and fw,D equals the number of documents in which w appears in D [50].
where fw,d equals the number of times w appears in d, |D| is the size of the corpus, and fw,D equals the number of documents in which w appears in D [50].
Step four involves tagging and information extraction. Once the preprocessed data are reduced, researcher move to tagging agents, attributes, and actions/interactions that can occur. Researcher propose the following approaches for tagging agent architecture:
Candidate agents: Following the conventional approaches in database design and OOP [42], researcher propose identifying the subjects of sentences as candidate agents. For instance, the farmer in ‘the farmer grows cotton’ can be a candidate agent. NLP has well-developed tools such as part-of-speech tagger and named-entity tagger that can be used to detect subjects of sentences.
Candidate actions: The main verbs of sentences can become candidate actions. The main verbs need candidate agents as the subject of the sentences. For example, in the sentence ‘the farmer grows cotton,’ the farmer is a candidate agent, and the subject of the sentence; grows is the main verb and, hence, a candidate action.
Candidate attributes: Attributes are properties inherent to the agents. Sentences containing candidate agents as subjects and be or have as their primary (non-auxiliary) verbs provide attribute information, e.g., ‘the farmer is a member of a cooperative,’ and ‘the farmer has 10 ha of land.’ Additionally, the use of possessive words also indicates attributes, e.g., the cow in the sentence ‘my cow is very small’ is an attribute.
Candidate interactions: Main verbs indicating relationships between two candidate agents are identified as interactions. Hence the sentences containing two or more candidate agents provide information on interactions, e.g., ‘The government trains the farmers.’
Since the data tagging is strictly unsupervised, false positives are likely to occur. The algorithm can over-predict agents, as the subjects of all the sentences are treated as candidate agents. In ABM, however, agents are defined as autonomous actors, they act and make decisions. Hence, researcher propose to use a hard-coded list of action verbs (e.g., eat, grow, and walk) and decision verbs (e.g., choose, decide, and think) to filter agents from the list of candidate agents. Only the candidate agents that use both types of verbs qualify as agents. Candidate agents not using both verbs are categorized as entities that may be subjected to manual evaluation. Similarly, people use different terminologies that are semantically similar. researcher recommend using external databases such as WordNet to group semantically similar terminologies.
Step five involves supervised contextualization and evaluation. While the unsupervised analysis reduces data volume and translates semi-structured interviews to the agent–action–attribute structure, noise can percolate to the outputs since the process is unsupervised. Additionally, the outputs need to be contextualized. Consequently, researcher suggest performing a series of supervised output filtration followed by manual contextualization and validation. The domain-independent unsupervised analysis extracts individual sentences that can sometimes be ambiguous or domain-irrelevant. Hence the output should be filtered based on ambiguity and domain relevancy. Once output filtration is performed, contextual structures can be developed and validated with domain experts and stakeholders.
References
- Miles, M.B. Qualitative data as an attractive nuisance: The problem of analysis. Adm. Sci. Q. 1979, 24, 590–601.
- Mortelmans, D. Analyzing qualitative data using NVivo. In The Palgrave Handbook of Methods for Media Policy Research; Palgrave Macmillan: London, UK, 2019; pp. 435–450.
- Rich, M.; Ginsburg, K.R. The reason and rhyme of qualitative research: Why, when, and how to use qualitative methods in the study of adolescent health. J. Adolesc. Health 1999, 25, 371–378.
- Watkins, D.C. Qualitative research: The importance of conducting research that doesn’t “count”. Health Promot. Pract. 2012, 13, 153–158.
- Kemp-Benedict, E. From Narrative to Number: A Role for Quantitative Models in Scenario analysis. In Proceedings of the International Congress on Environmental Modelling and Software, Osnabrück, Germany, 1 July 2004.
- Ackermann, F.; Eden, C.; Williams, T. Modeling for litigation: Mixing qualitative and quantitative approaches. Interfaces 1997, 27, 48–65.
- Coyle, G. Qualitative and quantitative modelling in system dynamics: Some research questions. Syst. Dyn. Rev. J. Syst. Dyn. Soc. 2000, 16, 225–244.
- Forbus, K.D.; Falkenhainer, B. Self-Explanatory Simulations: An Integration of Qualitative and Quantitative Knowledge. In Proceedings of the AAAI, Boston, MA, USA, 29 July–3 August 1990; pp. 380–387.
- Jo, H.I.; Jeon, J.Y. Compatibility of quantitative and qualitative data-collection protocols for urban soundscape evaluation. Sustain. Cities Soc. 2021, 74, 103259.
- Wolstenholme, E.F. Qualitative vs quantitative modelling: The evolving balance. J. Oper. Res. Soc. 1999, 50, 422–428.
- Djenontin, I.N.S.; Zulu, L.C.; Ligmann-Zielinska, A. Improving representation of decision rules in LUCC-ABM: An example with an elicitation of farmers’ decision making for landscape restoration in central Malawi. Sustainability 2020, 12, 5380.
- Polhill, J.G.; Sutherland, L.-A.; Gotts, N.M. Using qualitative evidence to enhance an agent-based modelling system for studying land use change. J. Artif. Soc. Soc. Simul. 2010, 13, 10.
- Landrum, B.; Garza, G. Mending fences: Defining the domains and approaches of quantitative and qualitative research. Qual. Psychol. 2015, 2, 199.
- Runck, B. GeoComputational Approaches to Evaluate the Impacts of Communication on Decision-Making in Agriculture. Ph.D. Thesis, University of Minnesota, Minneapolis, MN, USA, 2018.
- Du, J.; Ligmann-Zielinska, A. The Volatility of Data Space: Topology Oriented Sensitivity Analysis. PLoS ONE 2015, 10, e0137591.
- Grimm, V.; Augusiak, J.; Focks, A.; Frank, B.M.; Gabsi, F.; Johnston, A.S.; Liu, C.; Martin, B.T.; Meli, M.; Radchuk, V. Towards better modelling and decision support: Documenting model development, testing, and analysis using TRACE. Ecol. Model. 2014, 280, 129–139.
- Ligmann-Zielinska, A.; Siebers, P.-O.; Magliocca, N.; Parker, D.C.; Grimm, V.; Du, J.; Cenek, M.; Radchuk, V.; Arbab, N.N.; Li, S. ‘One size does not fit all’: A roadmap of purpose-driven mixed-method pathways for sensitivity analysis of agent-based models. J. Artif. Soc. Soc. Simul. 2020, 23.
- An, L.; Linderman, M.; Qi, J.; Shortridge, A.; Liu, J. Exploring Complexity in a Human–Environment System: An Agent-Based Spatial Model for Multidisciplinary and Multiscale Integration. Ann. Assoc. Am. Geogr. 2005, 95, 54–79.
- Railsback, S.F.; Grimm, V. Agent-Based and Individual-Based Modeling: A Practical Introduction; Princeton University Press: Princeton, NJ, USA, 2019.
- Wilensky, U.; Rand, W. An Introduction to Agent-Based Modeling: Modeling Natural, Social, and Engineered Complex Systems with NetLogo; Mit Press: Cambridge, MA, USA, 2015.
- Janssen, M.; Ostrom, E. Empirically based, agent-based models. Ecol. Soc. 2006, 11.
- O’Sullivan, D.; Evans, T.; Manson, S.; Metcalf, S.; Ligmann-Zielinska, A.; Bone, C. Strategic directions for agent-based modeling: Avoiding the YAAWN syndrome. J. Land. Use Sci. 2016, 11, 177–187.
- Robinson, D.T.; Brown, D.G.; Parker, D.C.; Schreinemachers, P.; Janssen, M.A.; Huigen, M.; Wittmer, H.; Gotts, N.; Promburom, P.; Irwin, E.; et al. Comparison of empirical methods for building agent-based models in land use science. J. Land. Use Sci. 2007, 2, 31–55.
- Smajgl, A.; Barreteau, O. Empirical Agent-Based Modelling-Challenges and Solutions; Springer: Berlin/Heidelberg, Germany, 2014; Volume 1.
- Seidl, R. Social scientists, qualitative data, and agent-based modeling. In Proceedings of the Social Simulation Conference, Barcelona, Spain, 1–5 September 2014.
- Grimm, V.; Berger, U.; DeAngelis, D.L.; Polhill, J.G.; Giske, J.; Railsback, S.F. The ODD protocol: A review and first update. Ecol. Model. 2010, 221, 2760–2768.
- Müller, B.; Balbi, S.; Buchmann, C.M.; De Sousa, L.; Dressler, G.; Groeneveld, J.; Klassert, C.J.; Le, Q.B.; Millington, J.D.A.; Nolzen, H. Standardised and transparent model descriptions for agent-based models: Current status and prospects. Environ. Model. Softw. 2014, 55, 156–163.
- Ford, A.; Ford, F.A. Modeling the Environment: An Introduction to System Dynamics Models of Environmental Systems; Island press: Washington, DC, USA, 1999.
- Heath, B.L.; Ciarallo, F.W.; Hill, R.R. Validation in the agent-based modelling paradigm: Problems and a solution. Int. J. Simul. Process Model. 2012, 7, 229–239.
- An, L.; Grimm, V.; Bai, Y.; Sullivan, A.; Turner II, B.; Malleson, N.; Heppenstall, A.; Vincenot, C.; Robinson, D.; Ye, X. Modeling agent decision and behavior in the light of data science and artificial intelligence. Environ. Model. Softw. 2023, 166, 105713.
- Balke, T.; Gilbert, N. How Do Agents Make Decisions? A Survey. J. Artif. Soc. Soc. Simul. 2014, 17, 13.
- Doscher, C.; Moore, K.; Smallman, C.; Wilson, J.; Simmons, D. An Agent-Based Model of Tourist Movements in New Zealand. In Empirical Agent-Based Modelling-Challenges and Solutions: Volume 1, The Characterisation and Parameterisation of Empirical Agent-Based Models; Springer: Berlin/Heidelberg, Germany, 2014; pp. 39–51.
- Edwards-Jones, G. Modelling farmer decision-making: Concepts, progress and challenges. Anim. Sci. 2006, 82, 783–790.
- Janssen, M.; Jager, W. An integrated approach to simulating behavioural processes: A case study of the lock-in of consumption patterns. J. Artif. Soc. Soc. Simul. 1999, 2, 21–35.
- Becu, N.; Barreteau, O.; Perez, P.; Saising, J.; Sungted, S. A methodology for identifying and for-malizing farmers’ representations of watershed management: A case study from northern Thailand. In Companion Modeling and Multi-Agent Systems for Integrated Natural Resource Management in Asia; International Rice Research Institute: Manila, Philippines, 2005; p. 41.
- Voinov, A.; Bousquet, F. Modelling with stakeholders. Environ. Model. Softw. 2010, 25, 1268–1281.
- Bharwani, S. Understanding complex behavior and decision making using ethnographic knowledge elicitation tools (KnETs). Soc. Sci. Comput. Rev. 2006, 24, 78–105.
- Edmonds, B. A context-and scope-sensitive analysis of narrative data to aid the specification of agent behaviour. J. Artif. Soc. Soc. Simul. 2015, 18, 17.
- Ghorbani, A.; Schrauwen, N.; Dijkema, G.P.J. Using Ethnographic Information to Conceptualize Agent-based Models. In Proceedings of the European Social Simulation Association Conference, Warsaw, Poland, 16–20 September 2013.
- Gilbert, N.; Terna, P. How to build and use agent-based models in social science. Mind Soc. 2000, 1, 57–72.
- Huigen, M.G. First principles of the MameLuke multi-actor modelling framework for land use change, illustrated with a Philippine case study. J. Environ. Manag. 2004, 72, 5–21.
- Harmain, H.M.; Gaizauskas, R. CM-Builder: An automated NL-based CASE tool. In Proceedings of the ASE 2000 Fifteenth IEEE International Conference on Automated Software Engineering, Grenoble, France, 11–15 September 2000; pp. 45–53.
- Bersini, H. UML for ABM. J. Artif. Soc. Soc. Simul. 2012, 15, 9.
- Collins, A.; Petty, M.; Vernon-Bido, D.; Sherfey, S. A Call to Arms: Standards for Agent-Based Modeling and Simulation. J. Artif. Soc. Soc. Simul. 2015, 18, 12.
- Bakam, I.; Kordon, F.; Le Page, C.; Bousquet, F. Formalization of a spatialized multiagent model using coloured petri nets for the study of an hunting management system. In Proceedings of the International Workshop on Formal Approaches to Agent-Based Systems, Greenbelt, MD, USA, 5–7 April 2000; pp. 123–132.
- Gilbert, N. Agent-based social simulation: Dealing with complexity. Complex. Syst. Netw. Excell. 2004, 9, 1–14.
- Miller, J.H.; Page, S.E. Complex Adaptive Systems: An Introduction to Computational Models of Social Life; Princeton University Press: Princeton, NJ, USA, 2009.
- Manning, C.; Raghavan, P.; Schütze, H. Introduction to information retrieval. Nat. Lang. Eng. 2010, 16, 100–103.
- Namey, E.; Guest, G.; Thairu, L.; Johnson, L. Data reduction techniques for large qualitative data sets. Handb. Team-Based Qual. Res. 2008, 2, 137–161.
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; pp. 133–142.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
988
Revisions:
2 times
(View History)
Update Date:
29 Sep 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No