 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Chenghao Wang | -- | 6958 | 2023-09-13 11:35:50 | | | |
| 2 | Chenghao Wang | + 506 word(s) | 7464 | 2023-09-13 11:53:12 | | | | |
| 3 | Chenghao Wang | Meta information modification | 7464 | 2023-09-13 12:02:24 | | | | |
| 4 | Lindsay Dong | Meta information modification | 7464 | 2023-09-14 03:19:12 | | | | |
| 5 | Lindsay Dong | Meta information modification | 7464 | 2023-09-15 10:54:11 | | |
Video Upload Options
Deep learning based on neural network has been widely used in image recognition, speech recognition, natural language processing, automatic driving and other fields, and has made breakthrough progress. FPGA stands out in the field of accelerated deep learning with its flexible architecture and logical unit, high energy efficiency ratio, strong compatibility, low delay and other advantages.
1. Introduction
2. The Development of Neural Networks
| Stage | Year | Character | Content |
|---|---|---|---|
| Generation of models | 1943 | Warren McCulloch and Walter Pitts | McCulloch–Pitts model [15] |
| 1948 | Alan Mathison Turing | B-type Turing machine [16] | |
| 1949 | Donald Hebb | Hebb algorithm [17] | |
| 1951 | McCulloch and Marvin Minsky | The first neural network machine SNARC | |
| 1958 | Frank Rosenblatt | Perceptron model [18] | |
| Lag phase | 1969 | Marvin Minsky | Perception [19] |
| 1974 | Paul J. Werbos | Backpropogation (BP) algorithm [20] | |
| 1980 | Kunihiko Fukushima | Neocognitron model [21] | |
| The rise of backpropagation algorithms | 1982 | John J. Hopfield | Hopfield model [22] |
| 1985 | Hinton and Sejnowski | Boltzmann machine [23] | |
| 1986 | David Rumelhart and James McClelland | Redescription of the BP algorithm [24] | |
| 1989 | LeCun | Introducing the BP algorithm to the convolutional neural network [25] | |
| Confusion period | 1990–2005 | The rise of machine learning models has brought about great challenges to the development of neural networks | |
| The rise of deep learning | 2006 | Geoffrey Hinton | Deep Belief Networks [26] |
| 2012 | Alex Krizhevsky | AlexNet [27] | |
| 2014 | Christian Szegedy | GoogLeNet [28] | |
| Visual Geometry Group and Google DeepMind | VGGNet [29] | ||
| Ian J. Goodfellow | GAN [30] | ||
| Yi Sun and Xiaogang Wang | DeepID [31] | ||
| Ross Girshick and Jeff Donahue | Region-CNN (RCNN) [32] | ||
| 2015 | Joseph Redmon | You Only Look Once (YOLOv1) [33] | |
| 2016 | AlphaGo, an artificial intelligence machine developed by Google’s DeepMind, beat Go world champion Lee Sedol 4-1 | ||
| Joseph Redmon | YOLOv2 [34] | ||
| 2018 | Joseph Redmon | YOLOv3 [35] | |
| 2020 | Alexey Bochkovskiy | YOLOv4 [36] | |
| 2020–2022 | YOLOv5, YOLOv6 [37], YOLOv7 [38], etc. | ||
2.1. Deep Neural Network (DNN)
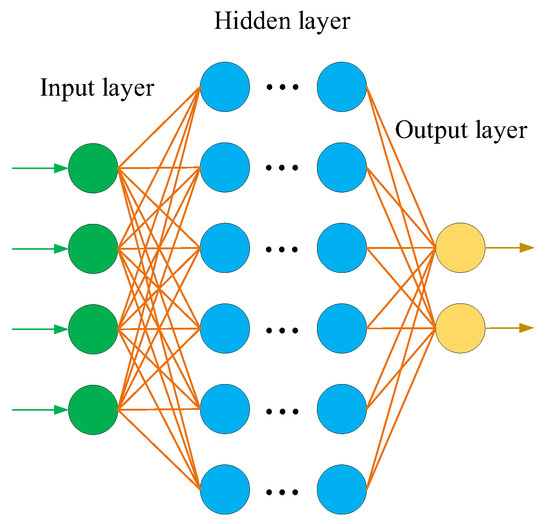
2.2. Convolutional Neural Network (CNN)
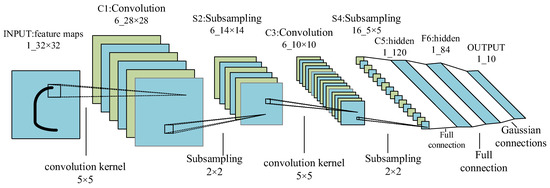
2.3. Recurrent Neural Network (RNN)
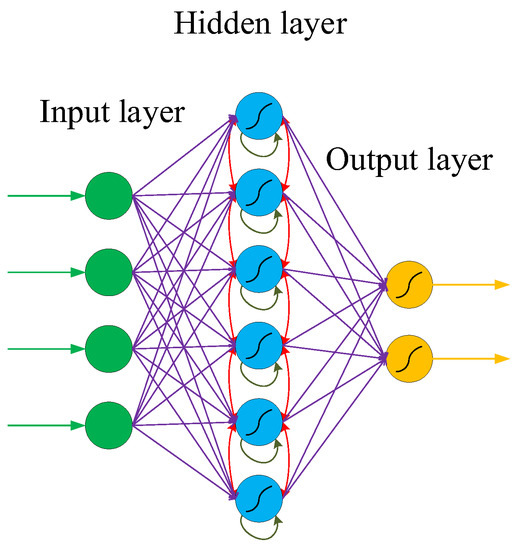
2.4. Generative Adversarial Network (GAN)
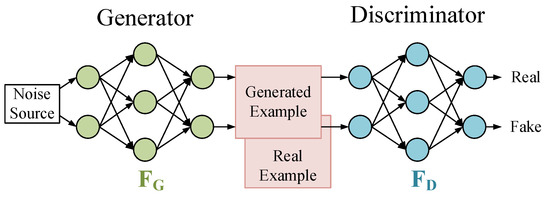
3. Application of Neural Networks Based on FPGA
3.1. Application of CNNs Based on FPGA
3.2. Application of RNNs Based on FPGA
3.3. Application of GANs Based on FPGA
4. Neural Network Optimization Technology Based on FPGA
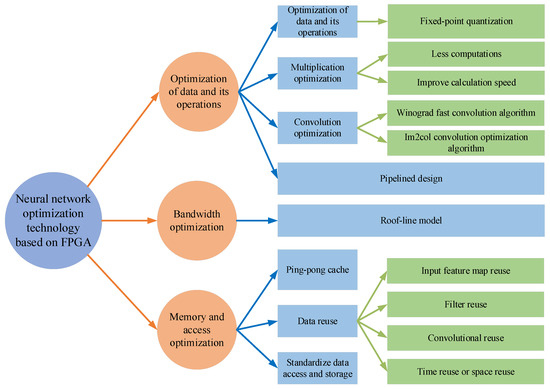
4.1. Optimization of Data and Its Operations
4.1.1. Fixed-Point Quantitative
4.1.2. Multiplication Optimization
4.1.3. Convolution Optimization
4.1.4. Pipelined Design
4.2. Bandwidth Optimization
4.3. Memory and Access Optimization
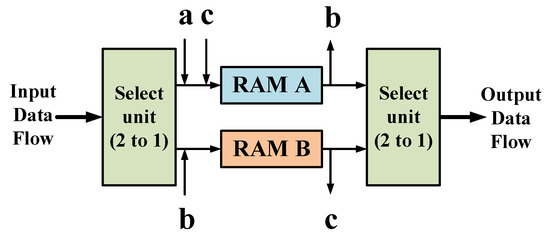
4.3.1. Ping-Pong Cache
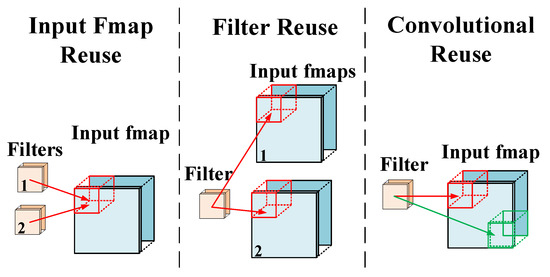
4.3.2. Data Reuse
4.3.3. Standardized Data Access and Storage
5. Design of the DNN Accelerator and Acceleration Framework Based on FPGA
In the optimization design of neural networks that are based on FPGA, some FPGA synthesis tools are generally used. The existing synthesis tools (HLS, OpenCL, etc.) that are highly suitable for FPGA greatly reduce the design and deployment time of neural networks, and the hardware-level design (such as RTL, register transfer level) can improve the efficiency and achieve a better acceleration effect. However, with the continuous development of neural networks, its deployment on FPGA has gradually become the focus of researchers. This further accelerates the emergence of more accelerators and acceleration frameworks for neural network deployment on FPGA. This is because with the acceleration of the specific neural network model, the idea is the most direct, and the design purpose is also the clearest. These accelerators are often hardware designs for the comprehensive application of the various acceleration techniques described above. When used in specific situations, such accelerators usually only need to fine-tune the program or parameters to be used, which is very convenient [13].
5.1. FPGA Accelerator Design for Different Neural Networks
5.1.1. The CNN Accelerator Based on FPGA
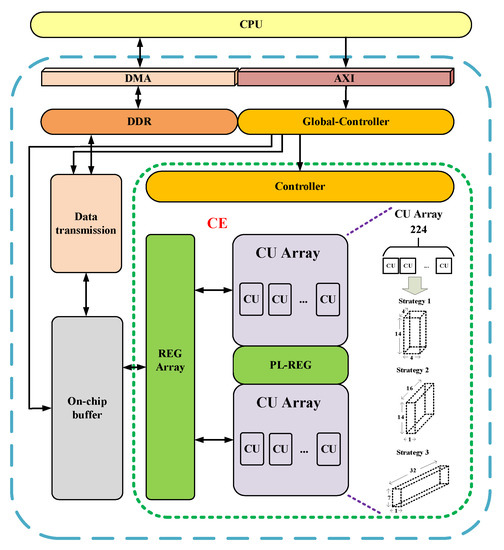
5.1.2. The RNN Accelerator Based on FPGA
5.1.3. The GAN Accelerator Based on FPGA
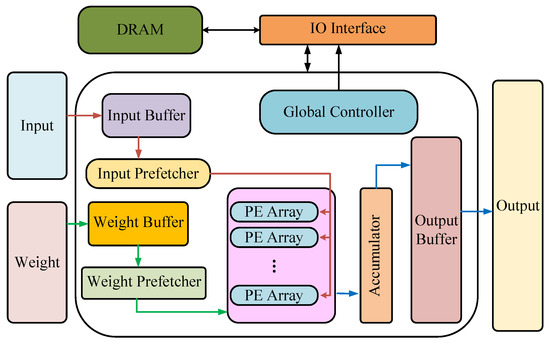
5.2. Accelerator Design for Specific Application Scenarios
5.2.1. FPGA Accelerator for Speech Recognition
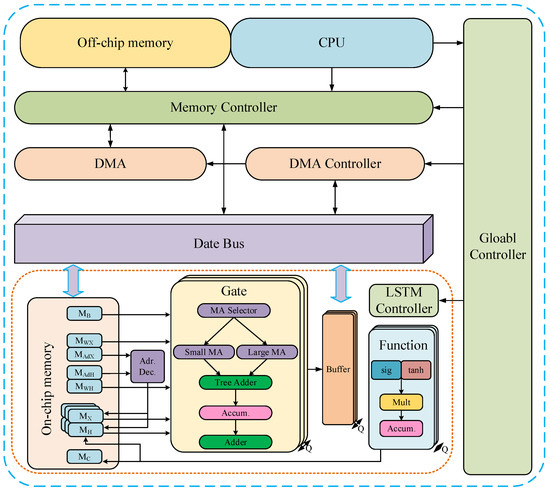
5.2.2. FPGA Accelerator for Speech Recognition
5.2.3. FPGA Accelerator for Natural Language Processing
5.3. FPGA accelerator for optimization strategy
5.3.1. Calculation optimization
5.3.2. Storage Optimization
5.4. Other FPGA accelerator design
References
- Subramanian, A.S.; Weng, C.; Watanabe, S.; Yu, M.; Yu, D. Deep learning based multi-source localization with source splitting and its effectiveness in multi-talker speech recognition. Comput. Speech Lang. 2022, 75, 101360.
- Kumar, L.A.; Renuka, D.K.; Rose, S.L.; Shunmuga-priya, M.C.; Wartana, I.M. Deep learning based assistive technology on audio visual speech recognition for hearing impaired. Int. J. Cogn. Comput. Eng. 2022, 3, 24–30.
- Roßbach, J.; Kollmeier, B.; Meyer, B.T. A model of speech recognition for hearing-impaired listeners based on deep learning. J. Acoust. Soc. Am. 2022, 151, 1417–1427.
- Garcia, G.R.; Michau, G.; Ducoffe, M.; Gupta, J.S.; Fink, O. Temporal signals to images: Monitoring the condition of industrial assets with deep learning image processing algorithms. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 236, 617–627.
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. A review on deep learning in medical image analysis. Int. J. Multimed. Inf. Retr. 2022, 11, 19–38.
- Zuo, C.; Qian, J.; Feng, S.; Yin, W.; Li, Y.; Fan, P.; Han, J.; Qian, K.; Qian, C. Deep learning in optical metrology: A review. Light Sci. Appl. 2022, 11, 1–54.
- Lauriola, I.; Lavelli, A.; Aiolli, F. An introduction to deep learning in natural language processing: Models, techniques, and tools. Neurocomputing 2022, 470, 443–456.
- Razumovskaia, E.; Glavaš, G.; Majewska, O.; Ponti, E.M.; Vulic, I. Natural Language Processing for Multilingual Task-Oriented Dialogue. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Dublin, Ireland, 22–27 May 2022; pp. 44–50.
- Li, B.; Hou, Y.; Che, W. Data Augmentation Approaches in Natural Language Processing: A Survey; AI Open: Beijing, China, 2022.
- Hu, Y.; Liu, Y.; Liu, Z. A Survey on Convolutional Neural Network Accelerators: GPU, FPGA and ASIC. In Proceedings of the 2022 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022; pp. 100–107.
- Mittal, S.; Umesh, S. A survey on hardware accelerators and optimization techniques for RNNs. J. Syst. Archit. 2021, 112, 101839.
- Shrivastava, N.; Hanif, M.A.; Mittal, S.; Sarangi, S.R.; Shafique, M. A survey of hardware architectures for generative adversarial networks. J. Syst. Archit. 2021, 118, 102227.
- Liu, T.; Zhu, J.; Zhang, Y. Review on FPGA-Based Accelerators in Deep Learning. J. Front. Comput. Sci. Technol. 2021, 15, 2093–2104.
- Jiao, L.; Sun, Q.; Yang, Y.; Feng, Y.; Li, X. Development, Implementation and Prospect of FPGA-Based Deep Neural Networks. Chin. J. Comput. 2022, 45, 441–471.
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133.
- Turing, A. Intelligent Machinery (1948); B. Jack Copeland: Oxford, NY, USA, 2004; p. 395.
- Hebb, D.O. The Organization of Behavior: A Neuropsychological Theory; Psychology Press: Mahwah, NJ, USA; London, UK, 2005.
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386.
- Minsky, M.; Papert, S.A. Perceptrons, Reissue of the 1988 Expanded Edition with a New Foreword by Léon Bottou: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017.
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560.
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285.
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558.
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169.
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536.
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551.
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144.
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 1891–1898.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788.
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271.
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767.
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934.
- Li, C.; Li, L.; Jiang, H.; Wenig, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976.
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696.
- Guo, W.; Xu, G.; Liu, B.; Wang, Y. Hyperspectral Image Classification Using CNN-Enhanced Multi-Level Haar Wavelet Features Fusion Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5.
- Chakraborty, S.; Paul, S.; Hasan, K.M. A transfer learning-based approach with deep cnn for covid-19-and pneumonia-affected chest x-ray image classification. SN Comput. Sci. 2022, 3, 1–10.
- Sharma, T.; Nair, R.; Gomathi, S. Breast cancer image classification using transfer learning and convolutional neural network. Int. J. Mod. Res. 2022, 2, 8–16. Available online: http://ijmore.co.in/index.php/ijmore/article/view/6 (accessed on 23 September 2022).
- Han, G.; Huang, S.; Ma, J.; He, Y. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 1 March–22 February 2022; Volume 36, pp. 780–789.
- Ramachandra, A.C. Real Time Object Detection System with YOLO and CNN Models: A Review. arXiv 2022, arXiv:2208.00773.
- Saralioglu, E.; Gungor, O. Semantic segmentation of land cover from high resolution multispectral satellite images by spectral-spatial convolutional neural network. Geocarto Int. 2022, 37, 657–677.
- Valdez-Rodríguez, J.E.; Calvo, H.; Felipe-Riverón, E.; Moreno-Armendariz, M.A. Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model. Sensors 2022, 22, 1669.
- Nguyen, C.; Asad, Z.; Deng, R.; Huo, Y. Evaluating transformer-based semantic segmentation networks for pathological image segmentation. In Proceedings of the Medical Imaging 2022: Image Processing, Tianjin, China, 14–16 January 2022; Volume 12032, pp. 942–947.
- Sağlam, S.; Tat, F.; Bayar, S. FPGA Implementation of CNN Algorithm for Detecting Malaria Diseased Blood Cells. In Proceedings of the 2019 International Symposium on Advanced Electrical and Communication Technologies (ISAECT), Rome, Italy, 27–29 November 2019; pp. 1–5.
- Zhang, Q. Application of CNN Optimization Design Based on APSOC in the Classification of Congenital Heart Disease. Master’s Thesis, Yunnan University, Kunming, China, 2020.
- Wang, C. Implementation and Verification of CNN Based on FPGA. Ph.D. Thesis, Hebei University, Baoding, China, 2020.
- Ferreira, J.C.; Fonseca, J. An FPGA implementation of a long short-term memory neural network. In Proceedings of the 2016 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 30 November–2 December 2016; pp. 1–8.
- Guan, Y.; Yuan, Z.; Sun, G.; Cong, J. FPGA-based accelerator for long short-term memory recurrent neural networks. In Proceedings of the 2017 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 16–19 January 2017; pp. 629–634.
- Li, Z.; Ding, C.; Wang, S.; Wen, W.; Zhou, Y.; Liu, C.; Qiu, Q.; Xu, W.; Lin, X.; Qian, X.; et al. E-RNN: Design optimization for efficient recurrent neural networks in FPGAs. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 69–80.
- Gao, C.; Rios-Navarro, A.; Chen, X.; Liu, S.C.; Delbruck, T. EdgeDRNN: Recurrent neural network accelerator for edge inference. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 419–432.
- Yazdanbakhsh, A.; Brzozowski, M.; Khaleghi, B.; Ghodrati, S.; Samadi, K.; Kim, N.S.; Esmaeilzadeh, H. Flexigan: An end-to-end solution for fpga acceleration of generative adversarial networks. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 65–72.
- Vanhoucke, V.; Senior, A.; Mao, M.Z. Improving the Speed of Neural Networks on CPUs. In Proceedings of the Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011, Granada, Spain, 15 December 2011.
- Zhang, S.; Cao, J.; Zhang, Q.; Zhang, Q.; Zhang, Y.; Wang, Y. An fpga-based reconfigurable cnn accelerator for yolo. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–11 May 2020; pp. 74–78.
- Li, Z.; Chen, J.; Wang, L.; Cheng, B.; Yu, J.; Jiang, S. CNN Weight Parameter Quantization Method for FPGA. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1548–1553.
- Chang, S.E.; Li, Y.; Sun, M.; Shi, R.; So, H.K.H.; Qian, X.; Wang, Y.; Lin, X. Mix and match: A novel fpga-centric deep neural network quantization framework. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, 27 February–3 March 2021; pp. 208–220.
- Zhao, X.; Wang, Y.; Cai, X.; Liu, C.; Zhang, L. Linear Symmetric Quantization of Neural Networks for Low-Precision Integer Hardware. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020.
- Bao, Z.; Zhan, K.; Zhang, W.; Guo, J. LSFQ: A Low Precision Full Integer Quantization for High-Performance FPGA-Based CNN Acceleration. In Proceedings of the 2021 IEEE Symposium in Low-Power and High-Speed Chips (COOL CHIPS), Tokyo, Japan, 14–16 April 2021; pp. 1–6.
- Zhao, X.; Zhang, X.; Yang, F.; Xu, P.; Li, W.; Chen, F. Research on Machine Learning Optimization Algorithm of CNN for FPGA Architecture. J. Phys. Conf. Ser. 2021, 2006, 012012.
- Shi, T.J.; Liu, Y.F.; Tian, J.; Zhao, Y.X. Design of FPGA recurrent neural network accelerator based on high level synthesis. Inform. Technol. Inform. 2022, 1, 151–153.
- Fowers, J.; Ovtcharov, K.; Strauss, K.; Chung, E.S.; Sitt, G. A high memory bandwidth fpga accelerator for sparse matrix-vector multiplication. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014; pp. 36–43.
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating binarized neural networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84.
- Gupta, A.; Suneja, K. Hardware Design of Approximate Matrix Multiplier based on FPGA in Verilog. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 496–498.
- Iakovidis, D.K.; Maroulis, D.E.; Bariamis, D.G. FPGA architecture for fast parallel computation of co-occurrence matrices. Microprocess. Microsyst. 2007, 31, 160–165.
- Abbaszadeh, A.; Iakymchuk, T.; Bataller-Mompeán, M.; Francés-Villora, J.V.; Rosado-Muñoz, A. Anscalable matrix computing unit architecture for FPGA, and SCUMO user design interface. Electronics 2019, 8, 94.
- Kala, S.; Nalesh, S. Efficient cnn accelerator on fpga. IETE J. Res. 2020, 66, 733–740.
- Kang, S.; Lee, S.; Kim, B.; Kim, H.; Sohn, K.; Kim, N.S.; Lee, E. An FPGA-based RNN-T Inference Accelerator with PIM-HBM. In Proceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Virtual, 27 February–1 March 2022; pp. 146–152.
- Lavin, A.; Gray, S. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE conference on computer vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021.
- Lu, L.; Liang, Y. SpWA: An efficient sparse winograd convolutional neural networks accelerator on FPGAs. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6.
- Kala, S.; Mathew, J.; Jose, B.R.; Nalesh, S. UniWiG: Unified winograd-GEMM architecture for accelerating CNN on FPGAs. In Proceedings of the 2019 32nd International Conference on VLSI Design and 2019 18th International Conference on Embedded Systems (VLSID), Delhi, India, 5–9 January 2019; pp. 209–214.
- Bao, C.; Xie, T.; Feng, W.; Chang, L.; Yu, C. A power-efficient optimizing framework fpga accelerator based on winograd for yolo. IEEE Access 2020, 8, 94307–94317.
- Wang, X.; Wang, C.; Cao, J.; Gong, L.; Zhou, X. Winonn: Optimizing fpga-based convolutional neural network accelerators using sparse winograd algorithm. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 4290–4302.
- Li, B.; Qi, Y.R.; Zhou, Q.L. Design and optimization of target detection accelerator based on Winograd algorithm. Acta Electron. Sin. 2022, 50, 2387–2397.
- Tang, F.; Zhang, W.; Tian, X.; Fan, X.; Cao, X. Optimization of Convolution Neural Network Algorithm Based on FPGA. ESTC 2017. Communications in Computer and Information Science; Springer: Singapore, 2018; Volume 857, pp. 131–140.
- Yu, F.; Cao, Y.; Tang, Y. Realization of Quantized Neural Network for Super-resolution on PYNQ. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Fayetteville, AR, USA, 3–6 May 2020; p. 233.
- Ye, T.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Performance Modeling and FPGA Acceleration of Homomorphic Encrypted Convolution. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 115–121.
- Zhang, H.; Jiang, J.; Fu, Y.; Chang, Y.C. Yolov3-tiny Object Detection SoC Based on FPGA Platform. In Proceedings of the 2021 6th International Conference on Integrated Circuits and Microsystems (ICICM), Nanjing, China, 22–24 October 2021; pp. 291–294.
- Xiao, C.; Shi, C.; Xu, D.; Lin, F.; Ning, K. SDST-Accelerating GEMM-based Convolution through Smart Data Stream Transformation. In Proceedings of the 2022 22nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Taormina, Italy, 16–19 May 2022; pp. 396–403.
- Özkilbaç, B.; Ozbek, I.Y.; Karacali, T. Real-Time Fixed-Point Hardware Accelerator of Convolutional Neural Network on FPGA Based. In Proceedings of the 2022 5th International Conference on Computing and Informatics (ICCI), New Cairo, Egypt, 9–10 March 2022; pp. 1–5.
- Liu, Z.; Dou, Y.; Jiang, J.; Xu, J.; Li, S.; Zhou, Y.; Xu, Y. Throughput-optimized FPGA accelerator for deep convolutional neural networks. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2017, 10, 1–23.
- Xing, Y.; Liang, S.; Sui, L.; Jia, X.; Qiu, J.; Liu, X.; Wang, Y.; Shan, Y.; Wang, Y. Dnnvm: End-to-end compiler leveraging heterogeneous optimizations on fpga-based cnn accelerators. IEEE Trans. Comput.-Aid. Des. Integr. Circuits Syst. 2019, 39, 2668–2681.
- Wang, W.; Zhou, K.; Wang, Y.; Wang, G.; Yang, Z.; Yuan, J. FPGA parallel structure design of convolutional neural network (CNN) algorithm. Microelectron. Comput. 2019, 36, 57–62, 66.
- Wen, D.; Jiang, J.; Dou, Y.; Xu, J.; Xiao, T. An energy-efficient convolutional neural network accelerator for speech classification based on FPGA and quantization. CCF Trans. High Perform. Comput. 2021, 3, 4–16.
- Varadharajan, S.K.; Nallasamy, V. P-SCADA-a novel area and energy efficient FPGA architectures for LSTM prediction of heart arrthymias in BIoT applications. Expert Syst. 2022, 39, e12687.
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An insightful visual performance model for multicore architectures. Commun. ACM 2009, 52, 65–76.
- Siracusa, M.; Di-Tucci, L.; Rabozzi, M.; Williams, S.; Sozzo, E.D.; Santambrogio, M.D. A cad-based methodology to optimize hls code via the roofline model. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual, 2–5 November 2020; pp. 1–9.
- Calore, E.; Schifano, S.F. Performance assessment of FPGAs as HPC accelerators using the FPGA Empirical Roofline. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 83–90.
- Feng, Y.X.; Hu, S.Q.; Li, X.M.; Yu, J.C. Implementation and optimisation of pulse compression algorithm on open CL-based FPGA. J. Eng. 2019, 2019, 7752–7754.
- Di, X.; Yang, H.G.; Jia, Y.; Huang, Z.; Mao, N. Exploring efficient acceleration architecture for winograd-transformed transposed convolution of GANs on FPGAs. Electronics 2020, 9, 286.
- Yu, X.L.; Li, B.Q.; Dong, M.S.; Yin, W.M. Target Detection and Tracking System Based on FPGA. In Proceedings of the IOP Conference Series: Materials Science and Engineering. IOP Publ. 2020, 793, 012008.
- Li, T.Y.; Zhang, F.; Guo, W.; Shen, J.J.; Sun, M.Q. An FPGA-based JPEG preprocessing accelerator for image classification. J. Eng. 2022, 2022, 919–927.
- Zhang, H.; Li, Z.; Yang, H.; Cheng, X.; Zeng, X. A High-Efficient and Configurable Hardware Accelerator for Convolutional Neural Network. In Proceedings of the 2021 IEEE 14th International Conference on ASIC (ASICON), Kunming, China, 26–29 October 2021; pp. 1–4.
- Nguyen, X.Q.; Pham-Quoc, C. An FPGA-based Convolution IP Core for Deep Neural Networks Acceleration. REV J. Electron. Commun. 2022, 1, 1–2.
- Dinelli, G.; Meoni, G.; Rapuano, E.; Pacini, T.; Fanucci, L. MEM-OPT: A scheduling and data re-use system to optimize on-chip memory usage for CNNs on-board FPGAs. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 335–347.
- Miyajima, T.; Sano, K. A memory bandwidth improvement with memory space partitioning for single-precision floating-point FFT on Stratix 10 FPGA. In Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), Portland, OR, USA, 7–10 September 2021; pp. 787–790.
- Zhang, B.; Zeng, H.; Prasanna, V. Accelerating large scale GCN inference on FPGA. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Fayetteville, AR, USA, 3–6 May 2020; p. 241.
- Du, Z.; Zhang, Q.L.; Lin, M.; Li, S.; Li, X.; Ju, L. A comprehensive memory management framework for CPU-FPGA heterogenous SoCs. IEEE Trans. Comput.-Aid. Des. Integr. Circuits Syst. 2022; in press.
- Li, X.; Huang, H.; Chen, T.; Gao, H.; Hu, X.; Xiong, X. A hardware-efficient computing engine for FPGA-based deep convolutional neural network accelerator. Microelectron. J. 2022, 128, 105547.
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780.
- Cho, K.; Van-Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078.
- Nan, G.; Wang, Z.; Wang, C.; Wu, B.; Wang, Z.; Liu, W.; Lombardi, F. An Energy Efficient Accelerator for Bidirectional Recurrent Neural Networks (BiRNNs) Using Hybrid-Iterative Compression with Error Sensitivity. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 3707–3718.
- Ram, S.R.; Kumar, M.V.; Subramanian, B.; Bacanin, N.; Zivkovic, M.; Strumberger, I. Speech enhancement through improvised conditional generative adversarial networks. Microprocess. Microsyst. 2020, 79, 103281.
- Ghasemzadeh, S.A.; Tavakoli, E.B.; Kamal, M.; Afzali-Kusha, A.; Pedram, M. BRDS: An FPGA-based LSTM accelerator with row-balanced dual-ratio sparsification. arXiv 2021, arXiv:2101.02667.
- Jiang, W.; Yu, H.; Ha, Y. A High-Throughput Full-Dataflow MobileNetv2 Accelerator on Edge FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022; in press.
- Zhang, F.; Li, Y.; Ye, Z. Apply Yolov4-Tiny on an FPGA-Based Accelerator of Convolutional Neural Network for Object Detection. In Proceedings of the Journal of Physics: Conference Series. IOP Publ. 2022, 2303, 012032.
- Latotzke, C.; Ciesielski, T.; Gemmeke, T. Design of High-Throughput Mixed-Precision CNN Accelerators on FPGA. arXiv 2022, arXiv:2208.04854.
- Peng, H.; Huang, S.; Geng, T.; Li, A.; Jiang, W.; Liu, H.; Wang, S.; Ding, C. Accelerating Transformer-based Deep Learning Models on FPGAs using Column Balanced Block Pruning. In Proceedings of the 2021 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 7–9 April 2021; pp. 142–148.
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45.
- Rapuano, E.; Pacini, T.; Fanucci, L. A Post-training Quantization Method for the Design of Fixed-Point-Based FPGA/ASIC Hardware Accelerators for LSTM/GRU Algorithms. Comput. Intell. Neurosci. 2022, 2022, 9485933.
- Li, Z.; Sun, M.; Lu, A.; Ma, H.; Yuan, G.; Xie, Y.; Tang, H.; Li, Y.; Leeser, M.; Wang, Z.; et al. Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization. arXiv 2022, arXiv:2208.05163.

