 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Yanhong Peng | -- | 3528 | 2023-07-19 11:32:44 | | | |
| 2 | Lindsay Dong | + 135 word(s) | 3663 | 2023-07-21 02:45:57 | | |
Video Upload Options
Deep learning techniques for processing 3D point cloud data have seen significant advancements, given their unique ability to extract relevant features and handle unstructured data. These techniques find wide-ranging applications in fields like robotics, autonomous vehicles, and various other computer-vision applications.
1. Introduction
1.1. Basic Concepts
| Name and Reference | Year | Scene Type | Sensors | Website |
|---|---|---|---|---|
| KITTI [18] | 2012 | Urban (Driving) | RGB and LiDAR | https://www.cvlibs.net/datasets/kitti/ (accessed on 4 July 2023) |
| SUN RGB-D [6] | 2015 | Indoor | RGB-D | https://rgbd.cs.princeton.edu/(accessed on 4 July 2023) |
| ScanNetV2 [4] | 2018 | Indoor | RGB-D and Mesh | http://www.scan-net.org/ (accessed on 4 July 2023) |
| H3D [19] | 2019 | Urban (Driving) | RGB and LiDAR | https://usa.honda-ri.com/h3d (accessed on 4 July 2023) |
| Argoverse [20] | 2019 | Urban (Driving) | RGB and LiDAR | https://www.argoverse.org/ (accessed on 4 July 2023) |
| Lyft L5 [21] | 2019 | Urban (Driving) | RGB and LiDAR | - |
| A*3D [22] | 2019 | Urban (Driving) | RGB and LiDAR | https://github.com/I2RDL2/ASTAR-3D (accessed on 4 July 2023) |
| Waymo Open [9] | 2020 | Urban (Driving) | RGB and LiDAR | https://waymo.com/open/ (accessed on 4 July 2023) |
| nuScenes [10] | 2020 | Urban (Driving) | RGB and LiDAR | https://www.nuscenes.org/ (accessed on 4 July 2023) |
1.2. 3D Datasets
1.3. Point Clouds Imaging
1.4. Point Cloud Transformation Algorithms
2. The Representation of 3D Model
3. 3D Transformer
3.1. 3D Transformer Architecture
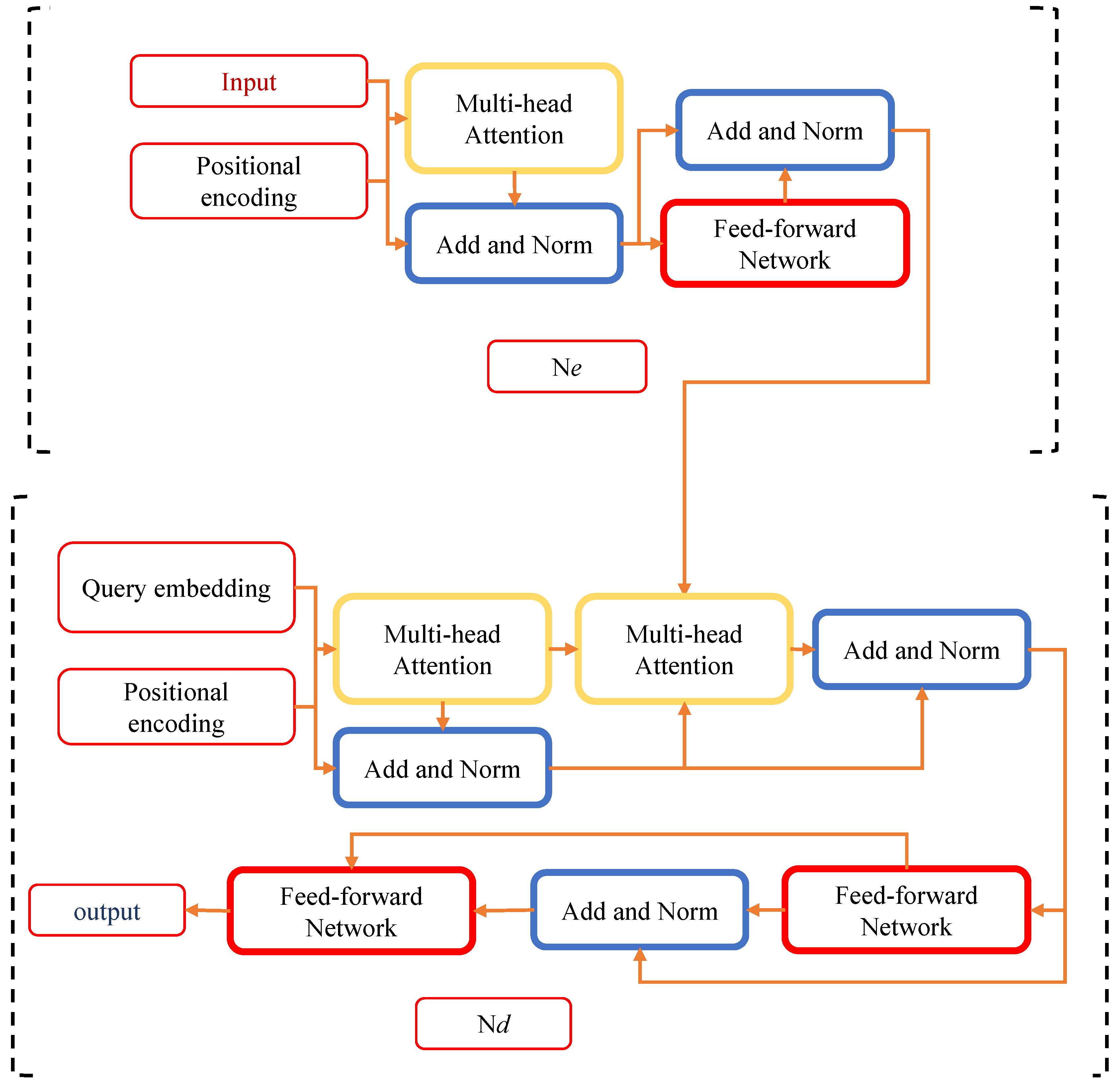
3.2. Classification of 3D Transformers
4. Applications
4.1. 3D Object Detection
4.2. 3D Object Classification
Object classification in deep learning pertains to the identification of an object’s category or class present in data sources such as images, videos, or other types of data [59]. This involves training a neural network model on a substantial dataset of labeled images, with each image being associated with a distinct object class. The trained model can subsequently be employed to predict the class of objects in novel, unseen images [46][60].
Point cloud classification [61][62][63][64] strives to classify each point in the cloud into a predefined set of categories or classes [65][66][67]. This task frequently arises in the fields of robotics, autonomous vehicles, and other computer vision applications where sensor data are represented in the form of point clouds. In order to classify a given 3D shape into a specific category, certain unique characteristics must be identified.
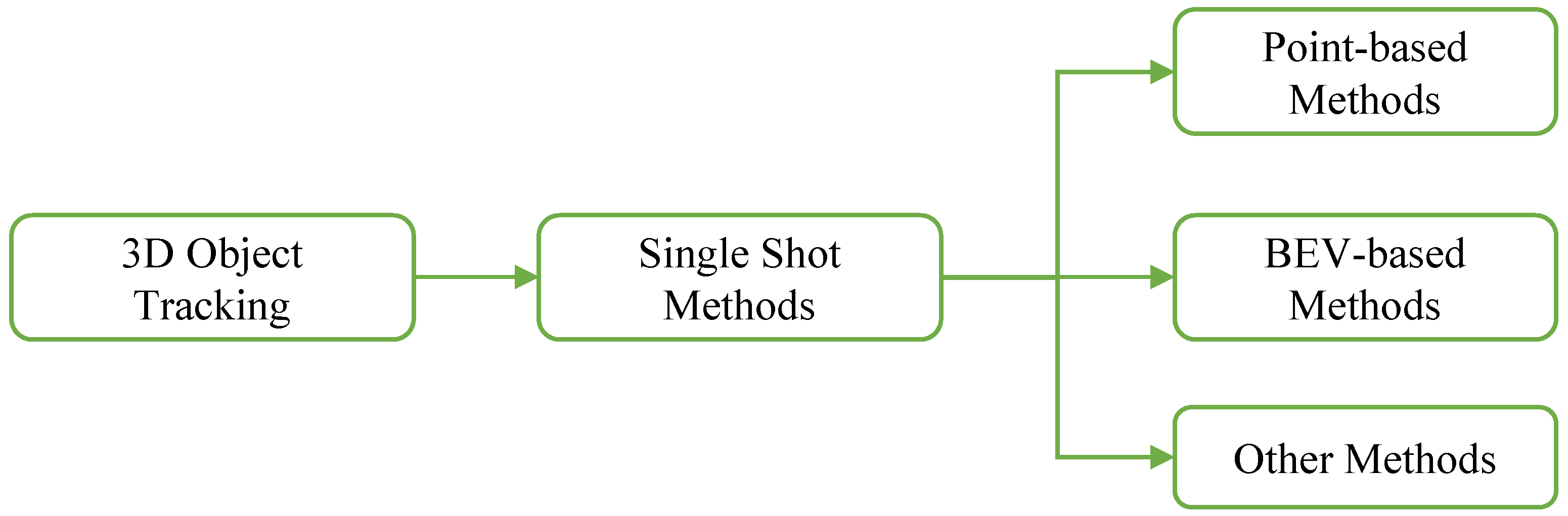
4.3. 3D Object Tracking
4.4. 3D Estimation
4.5. 3D Segmentation
4.6. 3D Point Cloud Completion
References
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364.
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920.
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012.
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839.
- Uy, M.A.; Pham, Q.H.; Hua, B.S.; Nguyen, T.; Yeung, S.K. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1588–1597.
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576.
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361.
- Li, G.; Jiao, Y.; Knoop, V.L.; Calvert, S.C.; van Lint, J.W.C. Large Car-following Data Based on Lyft level-5 Open Dataset: Following Autonomous Vehicles vs. Human-driven Vehicles. arXiv 2023, arXiv:2305.18921.
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454.
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631.
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847.
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298.
- Varney, N.; Asari, V.K.; Graehling, Q. DALES: A large-scale aerial LiDAR data set for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 186–187.
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307.
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.E. Paris-rue-Madame database: A 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification methods. In Proceedings of the 4th International Conference on Pattern Recognition, Applications and Methods ICPRAM 2014, Angers, France, 6–8 March 2014.
- Roynard, X.; Deschaud, J.E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557.
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543.
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237.
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.T. The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9552–9557.
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, California, CA, USA, 20–24 May 2019; pp. 8748–8757.
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2d2: Audi autonomous driving dataset. arXiv 2020, arXiv:2004.06320.
- Pham, Q.H.; Sevestre, P.; Pahwa, R.S.; Zhan, H.; Pang, C.H.; Chen, Y.; Mustafa, A.; Chandrasekhar, V.; Lin, J. A 3D dataset: Towards autonomous driving in challenging environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2267–2273.
- Muro, M.; Maxim, R.; Whiton, J. Automation and Artificial Intelligence: How Machines Are Affecting People and Places; Brookings Institution: Washington, DC, USA, 2019.
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One million scenes for autonomous driving: Once dataset. arXiv 2021, arXiv:2106.11037.
- Behroozpour, B.; Sandborn, P.A.; Wu, M.C.; Boser, B.E. Lidar system architectures and circuits. IEEE Commun. Mag. 2017, 55, 135–142.
- Mikhail, E.M.; Bethel, J.S.; McGlone, J.C. Introduction to Modern Photogrammetry; John Wiley & Sons: Hoboken, NJ, USA, 2001.
- Bell, T.; Li, B.; Zhang, S. Structured light techniques and applications. In Wiley Encyclopedia of Electrical and Electronics Engineering; Wiley: Hoboken, NJ, USA, 1999; pp. 1–24.
- Angelsky, O.V.; Bekshaev, A.Y.; Hanson, S.G.; Zenkova, C.Y.; Mokhun, I.I.; Jun, Z. Structured light: Ideas and concepts. Front. Phys. 2020, 8, 114.
- Chetverikov, D.; Svirko, D.; Stepanov, D.; Krsek, P. The trimmed iterative closest point algorithm. In Proceedings of the 2002 International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; Volume 3, pp. 545–548.
- Zhang, J.; Yao, Y.; Deng, B. Fast and robust iterative closest point. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3450–3466.
- Biber, P.; Straßer, W. The normal distributions transform: A new approach to laser scan matching. In Proceedings of the Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No. 03CH37453), Las Vegas, NV, USA, 27–31 October 2003; Volume 3, pp. 2743–2748.
- Cheng, Z.Q.; Wang, Y.; Li, B.; Xu, K.; Dang, G.; Jin, S. A Survey of Methods for Moving Least Squares Surfaces. In Proceedings of the VG/ SIGGRAPH, Los Angeles, CA, USA, 10–11 August 2008; pp. 9–23.
- Orts-Escolano, S.; Morell, V.; Garcia-Rodriguez, J.; Cazorla, M. Point cloud data filtering and downsampling using growing neural gas. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8.
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459.
- Ringnér, M. What is principal component analysis? Nat. Biotechnol. 2008, 26, 303–304.
- Lahoud, J.; Cao, J.; Khan, F.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Yang, M.H. 3d vision with transformers: A survey. arXiv 2022, arXiv:2208.04309.
- Li, Y.; Yang, M.; Zhang, Z. A survey of multi-view representation learning. IEEE Trans. Knowl. Data Eng. 2018, 31, 1863–1883.
- Xiong, F.; Zhang, B.; Xiao, Y.; Cao, Z.; Yu, T.; Zhou, J.T.; Yuan, J. A2j: Anchor-to-joint regression network for 3d articulated pose estimation from a single depth image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 793–802.
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular depth estimation using deep learning: A review. Sensors 2022, 22, 5353.
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L. A review of algorithms for filtering the 3D point cloud. Signal Process. Image Commun. 2017, 57, 103–112.
- Ashburner, J.; Friston, K.J. Voxel-based morphometry—The methods. Neuroimage 2000, 11, 805–821.
- Ashburner, J.; Friston, K.J. Why voxel-based morphometry should be used. Neuroimage 2001, 14, 1238–1243.
- Tam, G.K.; Cheng, Z.Q.; Lai, Y.K.; Langbein, F.C.; Liu, Y.; Marshall, D.; Martin, R.R.; Sun, X.F.; Rosin, P.L. Registration of 3D point clouds and meshes: A survey from rigid to nonrigid. IEEE Trans. Vis. Comput. Graph. 2012, 19, 1199–1217.
- Bassier, M.; Vergauwen, M.; Poux, F. Point cloud vs. mesh features for building interior classification. Remote Sens. 2020, 12, 2224.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660.
- Ding, Z.; Hu, Y.; Ge, R.; Huang, L.; Chen, S.; Wang, Y.; Liao, J. 1st Place Solution for Waymo Open Dataset Challenge–3D Detection and Domain Adaptation. arXiv 2020, arXiv:2006.15505.
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12697–12705.
- Mao, Z.; Yoshida, K.; Kim, J.W. A micro vertically-allocated SU-8 check valve and its characteristics. Microsyst. Technol. 2019, 25, 245–255.
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7345–7353.
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927.
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337.
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2022; pp. 11040–11048.
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1951–1960.
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361.
- Wang, D.Z.; Posner, I. Voting for voting in online point cloud object detection. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–15 July 2015; Volume 1, pp. 10–15.
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499.
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3d semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232.
- Socher, R.; Huval, B.; Bath, B.; Manning, C.D.; Ng, A. Convolutional-recursive deep learning for 3d object classification. Adv. Neural Inf. Process. Syst. 2012, 25, 656–664.
- Grilli, E.; Menna, F.; Remondino, F. A review of point clouds segmentation and classification algorithms. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 339.
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199.
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268.
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615.
- Mao, Z.; Shimamoto, G.; Maeda, S. Conical frustum gel driven by the Marangoni effect for a motor without a stator. Colloids Surf. A Physicochem. Eng. Asp. 2021, 608, 125561.
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2022; pp. 5589–5598.
- Yu, X.; Tang, L.; Rao, Y.; Huang, T.; Zhou, J.; Lu, J. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19313–19322.
- Gao, Y.; Liu, X.; Li, J.; Fang, Z.; Jiang, X.; Huq, K.M.S. LFT-Net: Local feature transformer network for point clouds analysis. IEEE Trans. Intell. Transp. Syst. 2022, 24, 2158–2168.
- Cui, Y.; Fang, Z.; Shan, J.; Gu, Z.; Zhou, S. 3d object tracking with transformer. arXiv 2021, arXiv:2110.14921.
- Funabora, Y. Flexible fabric actuator realizing 3D movements like human body surface for wearable devices. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1 October 2018; pp. 6992–6997.
- Zhou, C.; Luo, Z.; Luo, Y.; Liu, T.; Pan, L.; Cai, Z.; Zhao, H.; Lu, S. Pttr: Relational 3d point cloud object tracking with transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8531–8540.
- Li, Y.; Snavely, N.; Huttenlocher, D.P.; Fua, P. Worldwide pose estimation using 3d point clouds. In Large-Scale Visual Geo-Localization; Springer: Berlin/Heidelberg, Germany, 2016; pp. 147–163.
- Sanchez, J.; Denis, F.; Coeurjolly, D.; Dupont, F.; Trassoudaine, L.; Checchin, P. Robust normal vector estimation in 3D point clouds through iterative principal component analysis. ISPRS J. Photogramm. Remote Sens. 2020, 163, 18–35.
- Vock, R.; Dieckmann, A.; Ochmann, S.; Klein, R. Fast template matching and pose estimation in 3D point clouds. Comput. Graph. 2019, 79, 36–45.
- Guo, J.; Xing, X.; Quan, W.; Yan, D.M.; Gu, Q.; Liu, Y.; Zhang, X. Efficient center voting for object detection and 6D pose estimation in 3D point cloud. IEEE Trans. Image Process. 2021, 30, 5072–5084.
- Funabora, Y.; Song, H.; Doki, S.; Doki, K. Position based impedance control based on pressure distribution for wearable power assist robots. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 1874–1879.
- Wu, W.; Wang, Z.; Li, Z.; Liu, W.; Fuxin, L. Pointpwc-net: A coarse-to-fine network for supervised and self-supervised scene flow estimation on 3d point clouds. arXiv 2019, arXiv:1911.12408.
- Zhou, J.; Huang, H.; Liu, B.; Liu, X. Normal estimation for 3D point clouds via local plane constraint and multi-scale selection. Comput.-Aided Des. 2020, 129, 102916.
- Xu, G.; Cao, H.; Zhang, Y.; Ma, Y.; Wan, J.; Xu, K. Adaptive channel encoding transformer for point cloud analysis. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2022: 31st International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–13.
- Wang, Z.; Wang, Y.; An, L.; Liu, J.; Liu, H. Local Transformer Network on 3D Point Cloud Semantic Segmentation. Information 2022, 13, 198.
- Malinverni, E.S.; Pierdicca, R.; Paolanti, M.; Martini, M.; Morbidoni, C.; Matrone, F.; Lingua, A. Deep learning for semantic segmentation of 3D point cloud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 735–742.
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230.
- He, Y.; Yu, H.; Liu, X.; Yang, Z.; Sun, W.; Wang, Y.; Fu, Q.; Zou, Y.; Mian, A. Deep learning based 3D segmentation: A survey. arXiv 2021, arXiv:2103.05423.
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547.
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184.
- Wu, L.; Liu, X.; Liu, Q. Centroid transformers: Learning to abstract with attention. arXiv 2021, arXiv:2102.08606.
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep learning on point clouds and its application: A survey. Sensors 2019, 19, 4188.
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S.Z.; Mian, A. Point attention network for semantic segmentation of 3D point clouds. Pattern Recognit. 2020, 107, 107446.
- Zermas, D.; Izzat, I.; Papanikolopoulos, N. Fast segmentation of 3d point clouds: A paradigm on lidar data for autonomous vehicle applications. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5067–5073.
- Douillard, B.; Underwood, J.; Kuntz, N.; Vlaskine, V.; Quadros, A.; Morton, P.; Frenkel, A. On the segmentation of 3D LIDAR point clouds. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2798–2805.
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2626–2635.


