Three-dimensional single object tracking necessitates an abundance of datasets, typically collected from a myriad of experiments, for the assessment of performance and other characteristics. These datasets serve as a common benchmark for evaluating the efficiency of deep learning algorithms. Various 3D operations such as 3D shape classification, 3D object detection, and object tracking utilize the datasets listed in
Table 1 [
8]. There exist two categories of datasets for 3D shape classification, synthetic datasets [
13,
14] and real-world datasets [
8,
15,
16]. Likewise, datasets for 3D object detection and tracking are divided into two types, indoor scenes [
15,
17] and outdoor urban scenes [
8,
18,
19,
20,
21]. Various sensors, including Terrestrial Laser Scanners (TLS) [
22], Aerial Laser Scanners (ALS) [
23,
24], RGBD cameras [
15], Mobile Laser Scanners (MLS) [
25,
26,
27], and other 3D scanners [
8,
28], are employed to gather these datasets for 3D point segmentation.
1.2. 3D Datasets
S3DIS [
28]: A widely used dataset for semantic segmentation and scene understanding in indoor environments. The Stanford Large-Scale 3D Indoor Space (S3DIS) dataset is an extensive collection of over 215 million points scanned from three office buildings, covering six large indoor areas totaling 6000 square meters. It constitutes a detailed point cloud representation, complete with point-by-point semantic labels from 13 object categories. S3DIS is a widely-used dataset for semantic segmentation and scene understanding in indoor environments. It provides realistic 3D spatial information, making it suitable for recreating real spaces in cloud-based applications.
ScanNet-V2 [
15]: A large-scale dataset of annotated 3D indoor scenes. The ScanNet-V2 dataset emerges from the compilation of more than 2.5 million views from over 1500 RGB-D video scans. Primarily capturing indoor scenes, such as bedrooms and classrooms, this dataset enables annotation through surface reconstruction, 3D camera poses, and semantic and instance labels to facilitate segmentation. ScanNet-V2 is a popular dataset that enables rich scene understanding and reconstruction in indoor environments. It provides a large-scale and comprehensive dataset for cloud-based real-space recreation.
SUN RGB-D [
17]: A dataset that focuses on indoor scene understanding and semantic parsing. The SUN RGB-D dataset comprises a collection of single-view RGB-D images harvested from indoor environments, encompassing residential and complex spaces. It features 10,335 RGB-D images and 37 categories of 3D oriented object bounding boxes. The KITTI dataset, a pioneer in outdoor datasets, provides a wealth of data, including over 200 k 3D boxes for object detection across more than 22 scenes, dense point clouds from LiDAR sensors, and additional modes, such as GPS/IMU data and frontal stereo images [
41]. SUN RGB-D is a benchmark dataset for various tasks, including scene understanding and object recognition in indoor environments. Its comprehensive annotations make it useful for recreating accurate real spaces in the cloud.
ONCE [
32]: A project focused on developing object-centric navigation algorithms using catadioptric omnidirectional vision. The ONCE dataset encompasses seven million corresponding camera images and one million LiDAR scenes. It contains 581 sequences, including 10 annotated sequences for testing and 560 unlabeled sequences for unsupervised learning, thereby offering a benchmark for unsupervised learning and outdoor object detection. ONCE dataset offers detailed annotations for part-level co-segmentation, making it valuable for cloud-based real-space recreation that requires accurate part-level understanding.
ModelNet10/ModelNet40 [
13]: A benchmark dataset for 3D object classification and shape recognition. ModelNet, a synthetic object-level dataset designed for 3D classification, offers CAD models represented by vertices and faces. ModelNet10 provides 3377 samples from 10 categories, divided into 2468 training samples and 909 test samples. ModelNet40, around four times the size of ModelNet10, contains 13,834 objects from 40 categories, with 9843 objects forming the training set and the remainder allocated for testing. ModelNet10/ModelNet40 dataset focuses on object recognition and classification rather than scene-level understanding or space reconstruction. It might not be directly applicable to recreating real spaces in the cloud.
ScanObjectNN [
16]: A dataset designed for object instance segmentation and semantic segmentation in large-scale 3D indoor scenes. ScanObjectNN is a real object-level dataset consisting of 2902 3D point cloud objects from 15 categories, created by capturing and scanning real indoor scenes. Distinct from synthetic object datasets, the point cloud objects in ScanObjectNN are not axis-aligned and contain noise. ScanObjectNN dataset specializes in object instance segmentation and might not be suitable for full scene reconstruction or real-space recreation in the cloud.
ShapeNet [
14]: A large-scale dataset of 3D shape models covering a wide range of object categories. ShapeNet comprises 55 categories of synthetic 3D objects, collected from online open-source 3D repositories. Similar to ModelNet, ShapeNet is complete, aligned, and devoid of occlusion or background. ShapeNet dataset is valuable for object-level understanding, but they may not directly address full scene reconstruction or real-space recreation in the cloud.
ShapeNetPart [
14]: A subset of the ShapeNet dataset that focuses on fine-grained object classification and semantic part segmentation. ShapeNetPart, an extension of ShapeNet, includes 16,881 objects from 16 categories, each represented by point clouds. Each object is divided into 2 to 6 parts, culminating in a total of 50 part categories in the datasets. ShapeNetPart dataset primarily focuses on part-level semantic segmentation of 3D models rather than real-world spatial reconstruction, limiting its applicability to cloud-based real-space recreation.
In summary, S3DIS, ScanNet-V2, and SUN RGB-D are datasets that are particularly well-suited for recreating real spaces in the cloud due to their realistic indoor scene captures and extensive annotations. ONCE dataset focuses on part-level co-segmentation, which can contribute to accurate 3D space recreation. However, datasets like ModelNet10/ModelNet40, ScanObjectNN, ShapeNet, and ShapeNetPart are more suitable for tasks like object recognition, instance segmentation, and part-level semantic segmentation in 3D models rather than full-scale real-space recreation.
1.3. Point Clouds Imaging
In this part, the imaging resolutions of the three methods are introduced and compared which are LiDAR, Photogrammetry, and Structured Light.
LiDAR systems typically provide high-resolution point clouds. The resolution is determined by factors such as the laser pulse rate, laser beam width, and scanning pattern. Higher pulse rates and narrower beam widths generally result in higher imaging resolution. The benefit of LiDAR is that LiDAR point clouds have high accuracy and can capture detailed geometric information with fine resolution. They are particularly useful for capturing complex scenes and structures. The limitations of LiDAR is that LiDAR systems can be expensive and require sophisticated equipment. They may have limitations in capturing color or texture information [
42].
The imaging resolution in Photogrammetric point clouds is influenced by factors like camera sensor resolution, image overlap, and the quality of feature matching algorithms. Higher-resolution cameras and a larger number of high-quality images generally result in higher imaging resolution. The benefits of Photogrammetry are that Photogrammetry is a cost-effective technique, widely accessible through cameras and drones. It can provide detailed and accurate point clouds with good resolution, color information, and texture mapping. The limitations of Photogrammetry are that Photogrammetry may have challenges in capturing accurate depth information, especially in scenes with low texture or occlusions. It may require careful camera calibration and image processing [
43].
Structured light systems project known patterns onto a scene and use cameras to capture the deformations. The imaging resolution depends on factors such as the number and complexity of projected patterns, camera sensor resolution, and the accuracy of calibration. Higher-resolution cameras and more detailed patterns can increase the imaging resolution. The benefits of Structured light are that Structured light techniques can provide accurate and detailed point clouds with relatively good resolution. They can capture color and texture information alongside geometric data. The limitations of Structured light are that Structured light requires careful system setup and calibration. The resolution and accuracy can be affected by factors like ambient lighting conditions and the presence of reflective or glossy surfaces [
44,
45].
1.4. Point Cloud Transformation Algorithms
ICP is an iterative algorithm used for point cloud registration and alignment [
46]. The computational time of ICP depends on the number of iterations required to converge and the complexity of distance calculations, typically between
(𝑁2)
and
(𝑁3), where N is the number of points. ICP can be time-consuming, especially for large point clouds, and may require initial alignment estimates for convergence. However, there are variants and optimizations available, such as parallelization and approximate nearest neighbor search, to improve efficiency [
47].
NDT is a technique used for point cloud registration by estimating a probability distribution of the point data. The computational time of NDT depends on the voxel grid resolution, typically between (𝑁)
and
(𝑁2), where
N is the number of points. NDT can be computationally efficient, especially for large point clouds, as it uses voxel grids to accelerate computations. However, higher grid resolutions increase memory requirements and may impact processing time [
48].
MLS is a method used for point cloud smoothing and surface reconstruction. The computational time of MLS depends on the radius used for local computations and the number of neighbors, typically between (𝑁𝑙𝑜𝑔𝑁)
and
(𝑁2), where
N is the number of points. Efficiency Considerations: MLS can be relatively efficient, especially with optimized data structures like kd-trees for nearest neighbor searches. However, larger radii and denser neighborhood computations can impact processing time [
49].
Voxel grid downsampling is a technique used to reduce the density of point clouds by grouping points within voxel volumes [
50]. The computational time of voxel grid downsampling is typically
(𝑁), where
N is the number of points. Voxel grid downsampling is efficient as it involves spatial partitioning, enabling faster processing of large point clouds. The processing time is influenced by the size of the voxel grid used.
PCA is a statistical method used for feature extraction and dimensionality reduction in point clouds [
51]. The computational time of PCA depends on the number of dimensions and the number of points, typically between
(𝐷𝑁2)
and
(𝐷𝑁3), where
D is the number of dimensions and
N is the number of points. PCA can be computationally efficient for moderate-sized point clouds, but for high-dimensional data, dimensionality reduction techniques may be required to maintain efficiency [
52].
2. The Representation of 3D Model
Multi-view Representation: This method is the simplest way to show a 3D model. As we know, 2D model have less representation, also it is easy for observers describing a 3D model with a single viewpoint. Therefore, a series of 2D capturing from different viewpoints can be used to show a 3D shape. Because of reducing one dimension, it is relatively convenient and efficient for the observers to record a 3D shape while shrinking the size of the data [
11,
53].
Depth Images: The use of depth images can provide the distance between the camera and the scene to each pixel. First, depth images can be obtained from multi-view or stereo images, where a disparity map is calculated for each pixel in the image, but we usually use the form of RGB-D data to represent such images. Because RGB-D data are composed of color images and corresponding depth images, depth sensors such as kinect can easily obtain RGB-D data [
54]. Since the object can only be seen from one side, the depth image cannot describe the shape entirely because the depth image is captured from a viewpoint. Fortunately, thanks to huge advances in 2D processing, many 2D algorithms can use these data directly [
55].
Point Cloud: A point cloud is a group of unordered points in 3D space, which are represented by coordinates on the
x,
y, and
z axes, and from which a specific 3D shape can be formed [
56]. The coordinates of these points can be obtained from one or more views using a 3D scanner, such as the RGB-D cameras or LiDAR mentioned earlier. At the same time, RGB cameras can capture color information. These color information can be selectively superimposed on the point cloud as additional information to enrich the content expressed by the point cloud. A point cloud is an unordered set, so it differs from the image usually represented by a matrix. Therefore, a permutation invariant method is crucial for processing such data, so as to ensure that the results do not change with the order of the points in the cloud.
Voxels: For a picture, pixels are made up of small squares of an image. These squares have a clear position and specific color. The color and position of the small squares determine the appearance of the image. Therefore, we can also define a similar concept named “voxels” as the pixels. In 3D space, a voxel representation provides information on regular grid [
57,
58]. Voxels can be obtained from point clouds in the voxelization process, in which all features of 3D points within a voxel are grouped for subsequent processing. The structure of 3D voxels is similar to that of 2D. For example, convolution, in 2D convolution the kernel slides in 2D, while in 3D convolution the kernel slides in 3D instead of 2D as in 2D convolution. Since voxels contain a large number of empty volumes corresponding to the space around the object, in general, the voxel representation is relatively sparse. In addition, since most capture sensors can only collect information on the surface of an object, the interior of the object is also represented by empty volume.
Meshes: Unlike voxels, a mesh incorporates more elements and is a collection of vertices, edges, and faces (polygons) [
59]. Its basic components are polygons and planar shapes defined by the connection of a set of 3D vertices. Point clouds, in contrast, can only provide vertex locations, but because grids incorporate more elements, they can contain information about the surface of an object. This way of representing 3D models is very common in computer graphics applications. Nonetheless, surface information is difficult to process directly using deep learning methods, and in order to transform the mesh representation into a point cloud, many techniques pursue sampling points from the surface [
60].
3. 3D Transformer
3.1. 3D Transformer Architecture
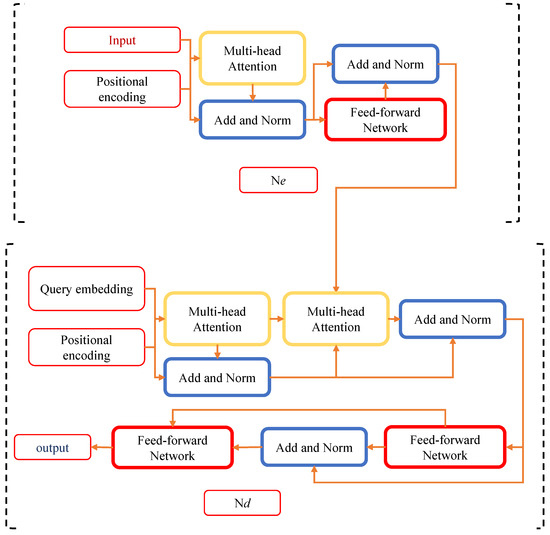
The archetypal Transformer model, which employs an encoder–decoder framework, is illustrated here, where the encoder represents the upper module, and the decoder, the lower. This section provides a comprehensive introduction to both the encoder and decoder.
The decoder follows a similar pattern, with each block adding a multi-head cross-attention sublayer compared to its encoder counterpart. This decoder block includes a multi-head cross-attention sub-layer, multi-head self-attention sub-layer, and a feed-forward network. The multi-head self-attention sublayer is designed to capture the relationship between different decoder elements, while using the encoder output as the key and value of the multi-head cross-attention sublayer to attend to the encoder output. Similarly to the encoder, a multilayer perceptron can transform the features of each input element via the feedforward network in the decoder. Moreover, a normalization operation and a residual connection follow each sublayer in the decoder, mirroring the encoder’s structure.
The architecture of the model is illustrated in Figure 3.
Figure 3. The transformer model.
3.2. Classification of 3D Transformers
Point-based Transformers: Initially, it should be noted that points follow an irregular format, unlike the regular structure of voxels. Therefore, during the process of point-to-voxel conversion, due to the constraints imposed by this regimented format, geometric information may be inevitably lost to some extent [
71,
72]. Conversely, given that the point cloud is the most raw representation, formed by the aggregation of points, comprehensive geometric information is inherent in the point cloud. Consequently, the majority of Transformer-based point cloud processing frameworks fall under the category of point Transformer-based.
Voxel-based Transformers: 3D point clouds are typically unstructured, which starkly contrasts with the structure of images. Therefore, conventional convolution operators cannot process this kind of data directly. However, by simply converting the 3D point cloud into 3D voxels, this challenge can be easily addressed. The 3D voxel structure bears similarities to images.
4. Applications
4.1. 3D Object Detection
The objective of 3D object detection is to predict the rotation bounding box of a 3D object [
18,
96,
97,
98,
99,
100,
101,
102,
103]. Three-dimensional object detectors demonstrate distinct differences when compared to 2D detectors. For instance, Vote3Deep [
104] leverages feature-centric voting [
105] to efficiently process sparse 3D point clouds on evenly spaced 3D voxels. A unified feature representation can be produced through the combination of 3D sparse convolutions and 2D convolutions in the detection head, a requirement that necessitates VoxelNet [
106] to use PointNet [
72] within each voxel. Building upon this, SECOND [
101] simplifies the VoxelNet process and makes the 3D convolution sparse [
107].
In the realm of outdoor 3D object detection, 3D object detection plays a pivotal role in autonomous driving. The KITTI dataset [
18] is one of the most frequently used datasets in this field due to its precise and clear provision of 3D object detection annotations. The KITTI dataset encompasses 7518 test samples and 7481 training samples, with standard average precision being used for easy, medium, and hard difficulty levels. The KITTI dataset enables the use of either LiDAR or RGB as input, or both.
4.2. 3D Object Classification
Object classification in deep learning pertains to the identification of an object’s category or class present in data sources such as images, videos, or other types of data [117]. This involves training a neural network model on a substantial dataset of labeled images, with each image being associated with a distinct object class. The trained model can subsequently be employed to predict the class of objects in novel, unseen images [72,118].
Point cloud classification [65,69,123,124] strives to classify each point in the cloud into a predefined set of categories or classes [66,75,125]. This task frequently arises in the fields of robotics, autonomous vehicles, and other computer vision applications where sensor data are represented in the form of point clouds. In order to classify a given 3D shape into a specific category, certain unique characteristics must be identified.
4.3. 3D Object Tracking
Three-dimensional object tracking in deep learning refers to the detection and tracking of the 3D position and movement of one or multiple objects within a scene over time. This process involves training a neural network model on an extensive dataset of labeled 3D objects or scenes, each annotated with its corresponding 3D position and movement over a period of time [
128,
129].
The purpose of 3D object tracking is to precisely track the movement of one or multiple objects in real-world environments, a crucial component in various computer vision applications, such as robotics, autonomous vehicles, and surveillance.
A deep learning model is trained on a large dataset of labeled 3D objects or scenes for 3D object tracking, with each object or scene annotated according to its respective 3D position and movement over time. The model learns to extract pertinent features from the 3D data and to track the object’s or objects’ movement in real time. During inference, the trained model is applied to new, unseen 3D data to track the object’s or objects’ movement in the scene over time. The model output comprises a set of 3D coordinates and trajectories, representing the movement of the object or objects in 3D space over time.
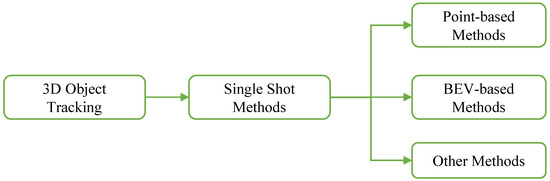
Figure 9 illustrates various methods for 3D object tracking [
130].
Figure 9. Various methods for 3D object tracking.
4.4. 3D Estimation
Three-dimensional pose estimation in deep learning pertains to estimating the 3D position and orientation of an object or scene from a 2D image or set of 2D images [
131]. This process involves training a neural network model on an extensive dataset of labeled images and their corresponding 3D poses, with each pose representing the position and orientation of the object or scene in 3D space [
132].
Three-dimensional pose estimation aims to accurately estimate the 3D pose of an object or scene in real-world settings, a key aspect in various computer vision applications, such as robotics, augmented reality, and autonomous vehicles [
133,
134,
135].
To perform 3D pose estimation, a deep learning model is trained on an extensive dataset of labeled images and their corresponding 3D poses [
136]. The model learns to extract pertinent features from the 2D images and estimate the 3D pose of the object or scene. During inference, the trained model is applied to new, unseen images to estimate the 3D pose of the object or scene in real-time. The model output comprises a set of 3D coordinates and orientations, representing the position and orientation of the object or scene in 3D space [
137].
4.5. 3D Segmentation
Three-dimensional segmentation [
138,
139] in deep learning involves dividing a 3D object or scene into meaningful parts or regions [
118,
140,
141]. This process necessitates training a neural network model on an extensive dataset of labeled 3D objects or scenes, with each object or scene segmented into its constituent parts or regions. The trained model can then predict segmentation labels for new, unseen 3D data [
72,
142,
143,
144].
In point cloud 3D segmentation [
145], the goal is to partition a 3D point cloud into distinct regions based on their semantic meaning. This task is vital in robotics, autonomous vehicles, and other computer vision applications where sensor data are represented in the form of point clouds [
92,
146,
147,
148].
4.6. 3D Point Cloud Completion
Three-dimensional point cloud completion in deep learning pertains to reconstructing missing or incomplete 3D point cloud data. This process involves training a neural network model on a comprehensive dataset of incomplete point clouds, where each point cloud lacks some points or possesses incomplete information. The trained model can then generate complete point clouds from new, incomplete point cloud data [
151].
The purpose of 3D point cloud completion is to recover the missing information within the point cloud and create a comprehensive 3D representation of the object or scene. This task holds significant importance in robotics, autonomous vehicles, and other computer vision applications where sensor data may be incomplete or noisy. For instance, point cloud completion can generate a comprehensive 3D map of a scene, even when some parts of the scene are obscured or missing due to sensor limitations.