 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Adham H. El Sherbini | -- | 3964 | 2023-06-03 22:19:31 | | | |
| 2 | Wendy Huang | Meta information modification | 3964 | 2023-06-05 09:56:16 | | |
Video Upload Options
Artificial intelligence (AI) is a field of study that attempts to replicate natural human intelligence in machines. The machines can then independently perform activities that would otherwise require human intelligence. AI can be broken down into several subsets, such as machine learning (ML) and deep learning (DL). Primary care has the potential to be transformed by artificial intelligence (AI) and, in particular, machine learning (ML). Healthcare professionals can identify diseases at an early and curable stage by using ML models to examine medical pictures, diagnostic modalities, and spot patterns that may suggest disease or anomalies. Before the onset of symptoms, ML can be used to identify people at an increased risk of developing specific disorders or diseases. ML algorithms can assess patient data such as medical history, genetics, and lifestyle factors to identify those at higher risk. This enables targeted interventions such as lifestyle adjustments or early screening.
1. Introduction
Primary care and preventive medicine, otherwise expressed as day-to-day healthcare practices including outpatient settings, are a growing sector in the realms of AI and computer science. Although AI has endless applications in healthcare, particular sectors of primary care have been more progressive and accepting of AI and its potential. For instance, the Forward clinic is a primary care service incorporating standard doctor-led programs with technology to provide a more inclusive and long-term care [1]. The addition of the technology allows for 24/7 monitoring, skin cancer screening, testing of genes, and biometric monitoring. As with all AI interventions, the Forward clinic endures multiple challenges, such as additional physician training and fees. Although the Forward clinic is just a singular example of how AI can be integrated into primary care, AI’s implementation into primary care can be further broken down into sections of healthcare, such as pre-operative care and screening.
2. Hypertension
3. Hypercholesterolemia
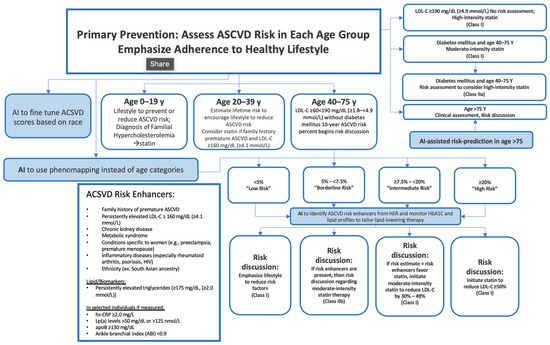
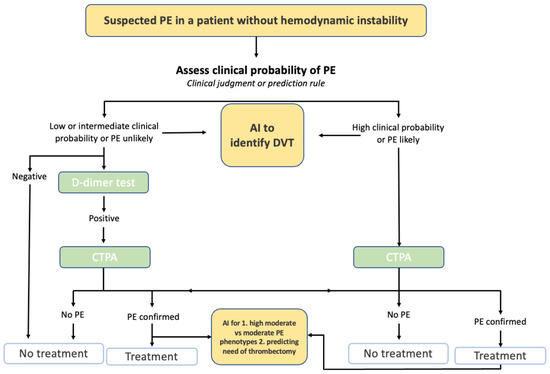
4. Cardiovascular Disease
5. Eye Disorders and Diseases
6. Diabetes
7. Cancer
8. Human Immunodeficiency Virus and Sexually Transmitted Diseases
9. Obstructive Sleep Apnea Syndrome
10. Osteoporosis
11. Chronic Conditions
12. Detecting COVID-19 and Influenza
13. Detecting Atrial Fibrillation
References
- Ghuwalewala, S.; Kulkarni, V.; Pant, R.; Kharat, A. Levels of Autonomous Radiology. Interact. J. Med. Res. 2022, 11, e38655.
- Zhao, H.; Zhang, X.; Xu, Y.; Gao, L.; Ma, Z.; Sun, Y.; Wang, W. Predicting the Risk of Hypertension Based on Several Easy-to-Collect Risk Factors: A Machine Learning Method. Front. Public Health 2021, 9, 619429.
- Alkaabi, L.A.; Ahmed, L.S.; Al Attiyah, M.F.; Abdel-Rahman, M.E. Predicting hypertension using machine learning: Findings from Qatar Biobank Study. PLoS ONE 2020, 15, e0240370.
- Ye, C.; Fu, T.; Hao, S.; Zhang, Y.; Wang, O.; Jin, B.; Xia, M.; Liu, M.; Zhou, X.; Wu, Q.; et al. Prediction of Incident Hypertension Within the Next Year: Prospective Study Using Statewide Electronic Health Records and Machine Learning. J. Med. Internet Res. 2018, 20, e22.
- LaFreniere, D.; Zulkernine, F.; Barber, D.; Martin, K. Using machine learning to predict hypertension from a clinical dataset. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7.
- Khalid, S.G.; Zhang, J.; Chen, F.; Zheng, D. Blood Pressure Estimation Using Photoplethysmography Only: Comparison between Different Machine Learning Approaches. J. Healthc. Eng. 2018, 2018, 1548647.
- Myers, K.D.; Knowles, J.W.; Staszak, D.; Shapiro, M.D.; Howard, W.; Yadava, M.; Zuzick, D.; Williamson, L.; Shah, N.H.; Banda, J.; et al. Precision screening for familial hypercholesterolaemia: A machine learning study applied to electronic health encounter data. Lancet Digit. Health 2019, 1, e393–e402.
- Pina, A.; Helgadottir, S.; Mancina, R.M.; Pavanello, C.; Pirazzi, C.; Montalcini, T.; Henriques, R.; Calabresi, L.; Wiklund, O.; Macedo, M.P.; et al. Virtual genetic diagnosis for familial hypercholesterolemia powered by machine learning. Eur. J. Prev. Cardiol. 2020, 27, 1639–1646.
- Liu, Y.; Zhang, Q.; Zhao, G.; Liu, G.; Liu, Z. Deep Learning-Based Method of Diagnosing Hyperlipidemia and Providing Diagnostic Markers Automatically. Diabetes Metab. Syndr. Obes. Targets Ther. 2020, 13, 679–691.
- Tsigalou, C.; Panopoulou, M.; Papadopoulos, C.; Karvelas, A.; Tsairidis, D.; Anagnostopoulos, K. Estimation of low-density lipoprotein cholesterol by machine learning methods. Clin. Chim. Acta 2021, 517, 108–116.
- Çubukçu, H.C.; Topcu, D.I. Estimation of Low-Density Lipoprotein Cholesterol Concentration Using Machine Learning. Lab. Med. 2022, 53, 161–171.
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944.
- Zhao, J.; Feng, Q.; Wu, P.; Lupu, R.A.; Wilke, R.A.; Wells, Q.S.; Denny, J.C.; Wei, W.-Q. Learning from Longitudinal Data in Electronic Health Record and Genetic Data to Improve Cardiovascular Event Prediction. Sci. Rep. 2019, 9, 717.
- Kusunose, K.; Hirata, Y.; Tsuji, T.; Kotoku, J.; Sata, M. Deep learning to predict elevated pulmonary artery pressure in patients with suspected pulmonary hypertension using standard chest X-ray. Sci. Rep. 2020, 10, 19311.
- Madani, A.; Moradi, M.; Karargyris, A.; Syeda-Mahmood, T. Chest X-ray generation and data augmentation for cardiovascular abnormality classification. In Medical Imaging 2018: Image Processing; Angelini, E.D., Landman, B.A., Eds.; SPIE: Houston, TX, USA, 2018; p. 57.
- Ambale-Venkatesh, B.; Yang, X.; Wu, C.O.; Liu, K.; Hundley, W.G.; McClelland, R.; Gomes, A.S.; Folsom, A.R.; Shea, S.; Guallar, E.; et al. Cardiovascular Event Prediction by Machine Learning: The Multi-Ethnic Study of Atherosclerosis. Circ. Res. 2017, 121, 1092–1101.
- Alaa, A.M.; Bolton, T.; Di Angelantonio, E.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS ONE 2019, 14, e0213653.
- Pfohl, S.; Marafino, B.; Coulet, A.; Rodriguez, F.; Palaniappan, L.; Shah, N.H. Creating Fair Models of Atherosclerotic Cardiovascular Disease Risk. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019.
- Al’aref, S.J.; Maliakal, G.; Singh, G.; van Rosendael, A.R.; Ma, X.; Xu, Z.; Alawamlh, O.A.H.; Lee, B.; Pandey, M.; Achenbach, S.; et al. Machine learning of clinical variables and coronary artery calcium scoring for the prediction of obstructive coronary artery disease on coronary computed tomography angiography: Analysis from the CONFIRM registry. Eur. Heart J. 2020, 41, 359–367.
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images From Multiethnic Populations With Diabetes. JAMA 2017, 318, 2211–2223.
- Poplin, R.; Varadarajan, A.V.; Blumer, K.; Liu, Y.; McConnell, M.V.; Corrado, G.S.; Peng, L.; Webster, D.R. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2018, 2, 158–164.
- Kim, Y.D.; Noh, K.J.; Byun, S.J.; Lee, S.; Kim, T.; Sunwoo, L.; Lee, K.J.; Kang, S.-H.; Park, K.H.; Park, S.J. Effects of Hypertension, Diabetes, and Smoking on Age and Sex Prediction from Retinal Fundus Images. Sci. Rep. 2020, 10, 4623.
- Ravaut, M.; Harish, V.; Sadeghi, H.; Leung, K.K.; Volkovs, M.; Kornas, K.; Watson, T.; Poutanen, T.; Rosella, L.C. Development and Validation of a Machine Learning Model Using Administrative Health Data to Predict Onset of Type 2 Diabetes. JAMA Netw. Open 2021, 4, e2111315.
- Ravaut, M.; Sadeghi, H.; Leung, K.K.; Volkovs, M.; Kornas, K.; Harish, V.; Watson, T.; Lewis, G.F.; Weisman, A.; Poutanen, T.; et al. Predicting adverse outcomes due to diabetes complications with machine learning using administrative health data. Npj Digit. Med. 2021, 4, 24.
- Deberneh, H.M.; Kim, I. Prediction of Type 2 Diabetes Based on Machine Learning Algorithm. Int. J. Environ. Res. Public Health 2021, 18, 3317.
- Alhassan, Z.; McGough, A.S.; Alshammari, R.; Daghstani, T.; Budgen, D.; Al Moubayed, N. Type-2 Diabetes Mellitus Diagnosis from Time Series Clinical Data Using Deep Learning Models. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11141, pp. 468–478.
- Boutilier, J.J.; Chan, T.C.Y.; Ranjan, M.; Deo, S. Risk Stratification for Early Detection of Diabetes and Hypertension in Resource-Limited Settings: Machine Learning Analysis. J. Med. Internet Res. 2021, 23, e20123.
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249.
- Alharbi, F.; Vakanski, A. Machine Learning Methods for Cancer Classification Using Gene Expression Data: A Review. Bioengineering 2023, 10, 173.
- Ardila, D.; Kiraly, A.P.; Bharadwaj, S.; Choi, B.; Reicher, J.J.; Peng, L.; Tse, D.; Etemadi, M.; Ye, W.; Corrado, G.; et al. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nat. Med. 2019, 25, 954–961.
- Gould, M.K.; Huang, B.Z.; Tammemagi, M.C.; Kinar, Y.; Shiff, R. Machine Learning for Early Lung Cancer Identification Using Routine Clinical and Laboratory Data. Am. J. Respir. Crit. Care Med. 2021, 204, 445–453.
- Yeh, M.C.-H.; Wang, Y.-H.; Yang, H.-C.; Bai, K.-J.; Wang, H.-H.; Li, Y.-C.J. Artificial Intelligence–Based Prediction of Lung Cancer Risk Using Nonimaging Electronic Medical Records: Deep Learning Approach. J. Med. Internet Res. 2021, 23, e26256.
- Guo, Y.; Yin, S.; Chen, S.; Ge, Y. Predictors of underutilization of lung cancer screening: A machine learning approach. Eur. J. Cancer Prev. 2022, 31, 523–529.
- Mehmood, M.; Rizwan, M.; Ml, M.G.; Abbas, S. Machine Learning Assisted Cervical Cancer Detection. Front. Public Health 2021, 9, 788376.
- Rahaman, M.; Li, C.; Yao, Y.; Kulwa, F.; Wu, X.; Li, X.; Wang, Q. DeepCervix: A deep learning-based framework for the classification of cervical cells using hybrid deep feature fusion techniques. Comput. Biol. Med. 2021, 136, 104649.
- Wentzensen, N.; Lahrmann, B.; Clarke, M.A.; Kinney, W.; Tokugawa, D.; Poitras, N.; Locke, A.; Bartels, L.; Krauthoff, A.; Walker, J.; et al. Accuracy and Efficiency of Deep-Learning–Based Automation of Dual Stain Cytology in Cervical Cancer Screening. JNCI J. Natl. Cancer Inst. 2020, 113, 72–79.
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep Learning to Improve Breast Cancer Detection on Screening Mammography. Sci. Rep. 2019, 9, 12495.
- Buda, M.; Saha, A.; Walsh, R.; Ghate, S.; Li, N.; Swiecicki, A.; Lo, J.Y.; Mazurowski, M.A. A Data Set and Deep Learning Algorithm for the Detection of Masses and Architectural Distortions in Digital Breast Tomosynthesis Images. JAMA Netw. Open 2021, 4, e2119100.
- Maghsoudi, O.H.; Gastounioti, A.; Scott, C.; Pantalone, L.; Wu, F.-F.; Cohen, E.A.; Winham, S.; Conant, E.F.; Vachon, C.; Kontos, D. Deep-LIBRA: An artificial-intelligence method for robust quantification of breast density with independent validation in breast cancer risk assessment. Med. Image Anal. 2021, 73, 102138.
- Ming, C.; Viassolo, V.; Probst-Hensch, N.; Dinov, I.D.; Chappuis, P.O.; Katapodi, M.C. Machine learning-based lifetime breast cancer risk reclassification compared with the BOADICEA model: Impact on screening recommendations. Br. J. Cancer 2020, 123, 860–867.
- Perera, M.; Mirchandani, R.; Papa, N.; Breemer, G.; Effeindzourou, A.; Smith, L.; Swindle, P.; Smith, E. PSA-based machine learning model improves prostate cancer risk stratification in a screening population. World J. Urol. 2021, 39, 1897–1902.
- Chiu, P.K.-F.; Shen, X.; Wang, G.; Ho, C.-L.; Leung, C.-H.; Ng, C.-F.; Choi, K.-S.; Teoh, J.Y.-C. Enhancement of prostate cancer diagnosis by machine learning techniques: An algorithm development and validation study. Prostate Cancer Prostatic Dis. 2021, 25, 672–676.
- Beinecke, J.M.; Anders, P.; Schurrat, T.; Heider, D.; Luster, M.; Librizzi, D.; Hauschild, A.-C. Evaluation of machine learning strategies for imaging confirmed prostate cancer recurrence prediction on electronic health records. Comput. Biol. Med. 2022, 143, 105263.
- Turbé, V.; Herbst, C.; Mngomezulu, T.; Meshkinfamfard, S.; Dlamini, N.; Mhlongo, T.; Smit, T.; Cherepanova, V.; Shimada, K.; Budd, J.; et al. Deep learning of HIV field-based rapid tests. Nat. Med. 2021, 27, 1165–1170.
- Bao, Y.; Medland, N.A.; Fairley, C.K.; Wu, J.; Shang, X.; Chow, E.P.; Xu, X.; Ge, Z.; Zhuang, X.; Zhang, L. Predicting the diagnosis of HIV and sexually transmitted infections among men who have sex with men using machine learning approaches. J. Infect. 2020, 82, 48–59.
- Marcus, J.L.; Hurley, L.B.; Krakower, D.S.; Alexeeff, S.; Silverberg, M.J.; Volk, J.E. Use of electronic health record data and machine learning to identify candidates for HIV pre-exposure prophylaxis: A modelling study. Lancet HIV 2019, 6, e688–e695.
- Elder, H.R.; Gruber, S.; Willis, S.J.; Cocoros, N.; Callahan, M.; Flagg, E.W.; Klompas, M.; Hsu, K.K. Can Machine Learning Help Identify Patients at Risk for Recurrent Sexually Transmitted Infections? Sex. Transm. Dis. 2020, 48, 56–62.
- Gadalla, A.A.H.; Friberg, I.M.; Kift-Morgan, A.; Zhang, J.; Eberl, M.; Topley, N.; Weeks, I.; Cuff, S.; Wootton, M.; Gal, M.; et al. Identification of clinical and urine biomarkers for uncomplicated urinary tract infection using machine learning algorithms. Sci. Rep. 2019, 9, 19694.
- Taylor, R.A.; Moore, C.L.; Cheung, K.-H.; Brandt, C. Predicting urinary tract infections in the emergency department with machine learning. PLoS ONE 2018, 13, e0194085.
- Tsai, C.-Y.; Liu, W.-T.; Lin, Y.-T.; Lin, S.-Y.; Houghton, R.; Hsu, W.-H.; Wu, D.; Lee, H.-C.; Wu, C.-J.; Li, L.Y.J.; et al. Machine learning approaches for screening the risk of obstructive sleep apnea in the Taiwan population based on body profile. Inform. Health Soc. Care 2021, 47, 373–388.
- Álvarez, D.; Cerezo-Hernández, A.; Crespo, A.; Gutiérrez-Tobal, G.C.; Vaquerizo-Villar, F.; Barroso-García, V.; Moreno, F.; Arroyo, C.A.; Ruiz, T.; Hornero, R.; et al. A machine learning-based test for adult sleep apnoea screening at home using oximetry and airflow. Sci. Rep. 2020, 10, 5332.
- Mencar, C.; Gallo, C.; Mantero, M.; Tarsia, P.; Carpagnano, G.E.; Barbaro, M.P.F.; Lacedonia, D. Application of machine learning to predict obstructive sleep apnea syndrome severity. Health Inform. J. 2020, 26, 298–317.
- Park, H.W.; Jung, H.; Back, K.Y.; Choi, H.J.; Ryu, K.S.; Cha, H.S.; Lee, E.K.; Hong, A.R.; Hwangbo, Y. Application of Machine Learning to Identify Clinically Meaningful Risk Group for Osteoporosis in Individuals Under the Recommended Age for Dual-Energy X-Ray Absorptiometry. Calcif. Tissue Int. 2021, 109, 645–655.
- Kim, S.K.; Yoo, T.K.; Oh, E.; Kim, D.W. Osteoporosis risk prediction using machine learning and conventional methods. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 188–191.
- Liu, L.; Si, M.; Ma, H.; Cong, M.; Xu, Q.; Sun, Q.; Wu, W.; Wang, C.; Fagan, M.J.; Mur, L.A.J.; et al. A hierarchical opportunistic screening model for osteoporosis using machine learning applied to clinical data and CT images. BMC Bioinform. 2022, 23, 63.
- Lim, H.K.; Ha, H.I.; Park, S.-Y.; Han, J. Prediction of femoral osteoporosis using machine-learning analysis with radiomics features and abdomen-pelvic CT: A retrospective single center preliminary study. PLoS ONE 2021, 16, e0247330.
- Wu, Q.; Nasoz, F.; Jung, J.; Bhattarai, B.; Han, M.V. Machine Learning Approaches for Fracture Risk Assessment: A Comparative Analysis of Genomic and Phenotypic Data in 5130 Older Men. Calcif. Tissue Int. 2020, 107, 353–361.
- Moslemi, A.; Kontogianni, K.; Brock, J.; Wood, S.; Herth, F.; Kirby, M. Differentiating COPD and asthma using quantitative CT imaging and machine learning. Eur. Respir. J. 2022, 60, 2103078.
- Zeng, S.; Arjomandi, M.; Tong, Y.; Liao, Z.C.; Luo, G. Developing a Machine Learning Model to Predict Severe Chronic Obstructive Pulmonary Disease Exacerbations: Retrospective Cohort Study. J. Med. Internet Res. 2022, 24, e28953.
- Nishat, M.; Faisal, F.; Dip, R.; Nasrullah, S.; Ahsan, R.; Shikder, F.; Asif, M.A. Hoque A Comprehensive Analysis on Detecting Chronic Kidney Disease by Employing Machine Learning Algorithms. EAI Endorsed Trans. Pervasive Health Technol. 2018, 7, 170671.
- Bai, Q.; Su, C.; Tang, W.; Li, Y. Machine learning to predict end stage kidney disease in chronic kidney disease. Sci. Rep. 2022, 12, 8377.
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. Machine learning applications for COVID-19 outbreak management. Neural Comput. Appl. 2022, 34, 15313–15348.
- Zhou, X.; Wang, Z.; Li, S.; Liu, T.; Wang, X.; Xia, J.; Zhao, Y. Machine Learning-Based Decision Model to Distinguish Between COVID-19 and Influenza: A Retrospective, Two-Centered, Diagnostic Study. Risk Manag. Healthc. Policy 2021, 14, 595–604.
- Zan, A.; Xie, Z.-R.; Hsu, Y.-C.; Chen, Y.-H.; Lin, T.-H.; Chang, Y.-S.; Chang, K.Y. DeepFlu: A deep learning approach for forecasting symptomatic influenza A infection based on pre-exposure gene expression. Comput. Methods Programs Biomed. 2021, 213, 106495.
- Nadda, W.; Boonchieng, W.; Boonchieng, E. Influenza, dengue and common cold detection using LSTM with fully connected neural network and keywords selection. BioData Min. 2022, 15, 5.
- Hogan, C.A.; Rajpurkar, P.; Sowrirajan, H.; Phillips, N.A.; Le, A.T.; Wu, M.; Garamani, N.; Sahoo, M.K.; Wood, M.L.; Huang, C.; et al. Nasopharyngeal metabolomics and machine learning approach for the diagnosis of influenza. EbioMedicine 2021, 71, 103546.
- Choo, H.; Kim, M.; Choi, J.; Shin, J.; Shin, S.-Y. Influenza Screening via Deep Learning Using a Combination of Epidemiological and Patient-Generated Health Data: Development and Validation Study. J. Med. Internet Res. 2020, 22, e21369.
- Lown, M.; Brown, M.; Brown, C.; Yue, A.M.; Shah, B.N.; Corbett, S.J.; Lewith, G.; Stuart, B.; Moore, M.; Little, P. Machine learning detection of Atrial Fibrillation using wearable technology. PLoS ONE 2020, 15, e0227401.
- Ali, F.; Hasan, B.; Ahmad, H.; Hoodbhoy, Z.; Bhuriwala, Z.; Hanif, M.; Ansari, S.U.; Chowdhury, D. Detection of subclinical rheumatic heart disease in children using a deep learning algorithm on digital stethoscope: A study protocol. BMJ Open 2021, 11, e044070.
- Kwon, S.; Hong, J.; Choi, E.-K.; Lee, E.; Hostallero, D.E.; Kang, W.J.; Lee, B.; Jeong, E.-R.; Koo, B.-K.; Oh, S.; et al. Deep Learning Approaches to Detect Atrial Fibrillation Using Photoplethysmographic Signals: Algorithms Development Study. JMIR mHealth uHealth 2019, 7, e12770.
- Tiwari, P.; Colborn, K.L.; Smith, D.E.; Xing, F.; Ghosh, D.; Rosenberg, M.A. Assessment of a Machine Learning Model Applied to Harmonized Electronic Health Record Data for the Prediction of Incident Atrial Fibrillation. JAMA Netw. Open 2020, 3, e1919396.
- Sekelj, S.; Sandler, B.; Johnston, E.; Pollock, K.G.; Hill, N.R.; Gordon, J.; Tsang, C.; Khan, S.; Ng, F.S.; Farooqui, U. Detecting undiagnosed atrial fibrillation in UK primary care: Validation of a machine learning prediction algorithm in a retrospective cohort study. Eur. J. Prev. Cardiol. 2021, 28, 598–605.


