1. Introduction
Primary care and preventive medicine, otherwise expressed as day-to-day healthcare practices including outpatient settings, are a growing sector in the realms of AI and computer science. Although AI has endless applications in healthcare, particular sectors of primary care have been more progressive and accepting of AI and its potential. For instance, the Forward clinic is a primary care service incorporating standard doctor-led programs with technology to provide a more inclusive and long-term care [1][3]. The addition of the technology allows for 24/7 monitoring, skin cancer screening, testing of genes, and biometric monitoring. As with all AI interventions, the Forward clinic endures multiple challenges, such as additional physician training and fees. Although the Forward clinic is just a singular example of how AI can be integrated into primary care, AI’s implementation into primary care can be further broken down into sections of healthcare, such as pre-operative care and screening.
The applications of AI in screening are by far the most precedented. PubMed and Google Scholar were searched from inception to December 2022, and the databases were searched for studies investigating the role of ML in screening for several diseases and disorders.
2. Hypertension
One of these leading domains is hypertension, where studies have assessed the risk of hypertension and predicted resistant hypertension while concurrently estimating blood pressure (BP). Zhao et al. compared four analytical models (RF, CatBoost, MLP neural network, and LR) in predicting the risk of hypertension based on data from physical examinations
[2][14]. RF was the best-performing model with an AUC of 0.92, an accuracy of 0.82, a sensitivity of 0.83, and a specificity of 0.81. In addition, no clinical or genetic data was utilized for training the models. Similarly, Alkaabi et al. utilized ML models (DT, RF, and LR) to assess the risk of developing hypertension in a more effective manner
[3][15]. RF was the best-performing model (accuracy (82.1%), PPV (81.4%), sensitivity (82.1%), and AUC (86.9)). Clinical factors, such as education level, tobacco use, abdominal obesity, age, gender, history of diabetes, consumption of fruits and vegetables, employment, physical activity, mother’s history of high BP, and history of high cholesterol, were all significant predictors of hypertension. Ye et al. investigated an XGBoost model that had AUC scores of 0.917 (retrospective) and 0.870 (prospective) in predicting hypertension. Similarly, LaFreniere et al. investigated an NN model which had 82% accuracy in predicting hypertension given the chosen risk factors
[4][5][16,17]. Regarding BP, Khalid et al. compared three ML models (regression tree, SVM, and MLR) in estimating BPs from pulse waveforms derived from photoplethysmogram (PPG) signals
[6][18]. The regression tree achieved the best systolic and diastolic BP accuracy, −0.1 ± 6.5 mmHg and −0.6 ± 5.2 mmHg, respectively. In summary, ML appears to be an effective tool for predicting hypertension and BP, though its clinical utility remains to be delineated, since hypertension can be diagnosed through non-invasive procedures.
3. Hypercholesterolemia
AI applications on hypercholesterolemia have outputted similar findings, as seen in Myers et al.
[7][19]. Using data on diagnostic and procedures codes, prescriptions, and laboratory findings, the FIND FH model was trained on large healthcare databases to diagnose familial hypercholesterolemia (FH). The model achieved a PPV of 0.85, a sensitivity of 0.45, an AURPC of 0.55, and an AUROC score of 0.89. This model effectively identified those with FH for individuals at high risk of early heart attack and stroke. Comparatively, Pina et al. evaluated the accuracy of three ML models (CT, GBM, and NN) when trained on genetic tests to detect FH-causative genetic mutations
[8][20]. All three models outperformed the clinical standard Dutch Lipid score in both cohorts. Similar findings have been produced for hyperlipidemia, where Liu et al. trained an LTSM network on 500 EHR samples
[9][21]. The model achieved an ACC score of 0.94, an AUC score of 0.974, a sensitivity of 0.96, and a specificity of 0.92. Regarding low-density lipoproteins (LDLs), Tsigalou et al. and Cubukcu et al. concluded that ML models were productive alternatives to direct determination and equations
[10][11][22,23]. In both studies, ML models (MLR, DNN, ANN, LR, and GB trees) outperformed the traditional equations: the Friedewald and Martin–Hopkins formulas. Although the researched algorithms show great potential, additional studies are warranted to validate these conclusions.
4. Cardiovascular Disease
Arguably, the largest field of primary care in which AI has made significant strides is predicting and assessing cardiovascular risk. As cardiovascular diseases are the leading cause of death globally, any advancements in risk prediction and early diagnosis are of substance. In 2017, Weng et al. compared four ML models (RF, LR, GB, and NN) in predicting cardiovascular risk through EHR
[12][24]. The AUC scores of RF, LR, GB, and NN were 0.745, 0.760, 0.761, and 0.764, respectively. The study concluded that the applications of ML in cardiovascular risk prediction significantly improved the accuracy. Zhao et al. reproduced a similar study with LR, RF, GBT, CNN, and LSTM trained on longitudinal EHR and genetic data
[13][25]. The event prediction was far better using the longitudinal feature for a 10-year CVD prediction. Kusunose et al. applied a CNN to identify those at risk of heart failure (HF) from a cohort of pulmonary hypertension (PH) patients using chest x-rays
[14][26]. The AUC scores of AI, chest x-rays, and human observers were 0.71, 0.60, and 0.63, respectively. In a unique perspective, Moradi et al. employed generative adversarial networks (GANs) for data augmentation on chest x-rays to assess its accuracy in detecting cardiovascular abnormalities when a CNN model was trained on it
[15][27]. The GAN data augmentation outperformed traditional and no data augmentation scenarios on normal and abnormal chest X-ray images with accuracies of 0.8419, 0.8312, and 0.8193, respectively. Studies have also compared ML models relative to traditional risk scores, such as a study by Ambale-Venkatesh et al.
[16][28]. A random survival forest model was assessed in its prediction of six cardiovascular outcomes compared with the Concordance index and Brier score. The model outperformed traditional risk scores (decreased Brier score by 10–25%), and age was the most significant predictor. Similarly, Alaa et al. compared an AutoPrognosis ML model with an established risk score (Framingham score), a Cox PH model with conventional risk factors, and a Cox PH model with all 473 variables (UK Biobank)
[17][29]. The AUROC scores were 0.774, 0.724, 0.734, and 0.758, respectively. Pfohl et al. developed a “fair” atherosclerotic cardiovascular disease (ACSVD) risk prediction tool through EHR data
[18][30]. The experiment ran through four experiments (standard, EQ
race, EQ
gender, and EQ
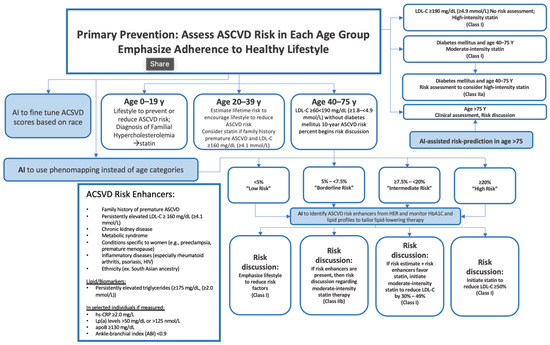
age) and achieved AUROC scores of 0.773, 0.742, 0.743, and 0.694, respectively. The tool has reduced discrepancies across races, genders, and ages in the prediction of ACSVD. Generally, AI can aid in mitigating gaps in ACSVD risk prevention guidelines, as observed in
Figure 1. In the United States alone, one in every three patients undergoing elective cardiac catheterization is diagnosed with obstructive coronary artery disease (CAD). This begs the question of new methodologies to better diagnose the population. Al’Afref et al. assessed how applying an XGBoost model on Coronary Computed Tomography Angiography can predict obstructive CAD using clinical factors
[19][31]. The ML model achieved an AUC score of 0.773, but more notably, when combined with the coronary artery calcium score (CACS), the AUC score was 0.881. Therefore, an ML model and CACS may accurately predict the presence of obstructive CAD. Based on the present literature, AI models screen effectively and predict cardiovascular risks while predominantly outperforming established risk scores.
Figure 1. Example of AI in ASCVD assessment. Figure Description: ASCVD risk assessment is exceptionally extensive and varies significantly based on age groups. Although the guidelines are thorough, AI has the potential to address potential gaps in the evaluation. For instance, AI can provide risk prediction for individuals > 75 and it could fine-tune ACSVD scores based on race. AI could also detect risk enhancers of ASCVD based on HbA1C monitoring, EHR, and lipid profiles. This may allow for appropriate adjustments to lipid-lowering therapy. AI also has the potential to use phenomapping instead of age categories, allowing for stronger classification.
5. Eye Disorders and Diseases
Another area of primary care that has used ML is vision-centric diseases, such as diabetic retinopathy, glaucoma, and age-related macular degeneration (AMD). Ting et al. assessed AI’s metrics in this sector by training a DL system on retinal images (76,370 images of diabetic retinopathy, 125,189 images of possible glaucoma, and 72,610 images of AMD)
[20][32]. For referable diabetic retinopathy, the model achieved an AUC of 0.936, a sensitivity of 0.905, and a specificity of 0.916. As for vision-threatening retinopathy, the AUC was 0.958, sensitivity was 1.00, and specificity was 0.911. For possible glaucoma images, the model achieved an AUC of 0.942, a sensitivity of 0.964, and a specificity of 0.872. Finally, the model on AMD testing retinal images achieved an AUC of 0.931, a sensitivity of 0.923, and a specificity of 0.887. Retinal fundus images can also be used by AI models to extract further information, such as predicting cardiovascular risk factors in the case of the study by Poplin et al.
[21][33]. After training the model on 284,445 and validating it on two datasets, the model could predict age (mean absolute error (MAE) within 3.26 years), gender (AUC 0.97), smoking status (AUC 0.71), systolic blood pressure (MAE within 11.23 mmHG), and major adverse cardiac events (AUC 0.70). In another study, Kim et al. utilized retinal fundus images for training a CNN model to predict age and sex
[22][34]. The MAE for patients, those with hypertension, those with diabetes mellitus (DM), and smokers were 3.06 years, 3.46 years, 3.55 years, and 2.65 years, respectively. Ultimately, well-trained ML models appear to be effective in predicting eye diseases.
6. Diabetes
More than 400 million individuals globally are diagnosed with DM. AI’s implementation into primary care has been shown to be effective when targeting this widespread disease’s risk prediction. In one study, Alghamdi et al. used medical records of cardiorespiratory fitness to train and compare five models (DT, naïve bayes, LR, logistic model tree, and RF) in predicting DM. When RF, logistic model tree, and naïve bayes were ensembled with the developed predictive model classifier, a maximum AUC (0.92) was achieved. Similarly, through administrative data, Ravaut et al. trained a GB decision tree on 1,657,395 patients to predict T2DM 5 years prior to onset
[23][35]. While validating the model on 243,442 patients and testing it on 236,506 patients, an AUC score of 0.8026 was achieved. In another study, Ravaut et al. also assessed if a GB decision tree can predict adverse complications of diabetes, including retinopathy, tissue infection, hyper/hypoglycemia, amputation, and cardiovascular events
[24][36]. After being trained (1,029,366 patients), validated (272,864 patients), and tested (265,406 patients) on administrative data, the model achieved an AUC score of 0.777. To support the conclusion on DM, Deberneh et al. found reasonably good accuracies in a Korean population, with DT (77.87%), LR (76.13%), and ANN having the lowest accuracy (73.23%)
[25][37]. In Alhassan et al., when predicting T2DM, the LTSM and gated-recurrent unit outperformed MLP models with a 97.3% accuracy
[26][38]. In India, Boutilier et al. attempted to find the best ML algorithm for predicting DM and hypertension in limited resource settings
[27][39]. RF models had a higher prediction accuracy than established UK and US scores, with an improved AUC score from 0.671 to 0.910 for diabetes and from 0.698 to 0.792 for hypertension. With the current evidence, ML methods appear to be exceptionally effective in predicting diabetes; however, there lacks discussion on the benefits of using ML over a simple blood draw.
7. Cancer
In 2020, cancer was responsible for nearly 10 million deaths globally, making it a hotspot for ML implementations and strategies in primary care
[28][40]. Fortunately, ML models have been proven to have potential in the early diagnosis and screening of lung, cervical, colorectal, breast, and prostate cancer
[29][41]. Regarding lung cancer, Ardilla et al. trained a DL algorithm on CT images to predict the risk of lung cancer in 6716 national trial cases
[30][42]. The model achieved an AUC score of 0.944. Similarly, Gould et al. compared an ML model in predicting a future lung cancer diagnosis with the 2012 Prostate, Lung, Colorectal and Ovarian Cancer Screening Trial risk model (mPLCOm2012)
[31][43]. The novel algorithm outperformed the mPLCOm2012 in AUC scores (0.86 vs. 0.79) and sensitivity (0.401 vs. 0.279). Using NNs, Yeh et al. developed a model to screen patients at risk of lung cancer on EHR data
[32][44]. For the overall population, the algorithm achieved an AUC score of 0.90 and 0.87 for patients over the age of 55 years. Guo et al. trained ML models on low-dose CT and found an accuracy of 0.6778, a F1 score of 0.6575, a sensitivity of 0.6252, and a specificity of 0.7357
[33][45]. More notably, the interactive pathways were BMI, DM, first smoke age, average drinks per month, years of smoking, year(s) since quitting smoking, sex, last dental visit, general health, insurance, education, last PAP test, and last sigmoidoscopy or colonoscopy. Concerning cervical cancer, CervDetect, a number of ML models that evaluate the risk of cervical cancer elements forming, has been a leader in this subject. In 2021, Mehmood et al. used cervical images to evaluate CervDetect and found a false negative rate of 100%, a false positive rate of 6.4%, an MSE error of 0.07111, and an accuracy of 0.936
[34][46]. Similarly, DeepCervix is another DL model that attempts to combat the high false-positive results in pap smear tests due to human error. Rahaman et al. trained DeepCervix, a hybrid deep fusion feature technique, on pap smear tests
[35][47]. The DL-based model achieved accuracies of 0.9985, 0.9938, and 0.9914 for 2-class, 3-class, and 5-class classifications, respectively. Considering that 90% of cervical cancer is found in low-middle income settings, Bae et al. set out to implement an ML model onto endoscopic visual inspection following an application of acetic acid images
[36][48]. Although resource-limited, the KNN model was the best performing, with an accuracy of 0.783, an AUC of 0.807, a specificity of 0.803, and a sensitivity of 0.75. In parallel, Wentzensen et al. developed a DL classifier with a cloud-based whole-slide imaging platform and trained it on P16/Ki-67 dual-stained (DS) slides for cervical cancer screening
[36][48]. The model achieved a better specificity and equal sensitivity to manual DS and pap, resulting in lower positivity than manual DS and cytology. With respect to breast cancer screening, multiple studies have been conducted to achieve better accuracy in its diagnosis. Using screening mammograms, Shen et al. trained a DL algorithm on 1903 images and achieved an AUC of 0.88, and the four-model averaging improved the AUC score to 0.91
[37][49]. Similarly, using digital breast tomosynthesis images, Buda et al. achieved a sensitivity of 65% with a DL model for breast cancer screening
[38][50]. Similarly, Haji Maghsoudi et al. developed Deep-LIBRA, an AI model trained on 15661 digital mammograms to estimate breast density and achieved an AUC of 0.612
[39][51]. The model had a strong agreement with the current gold standard. Another study by Ming et al. compared three ML models (MCMC GLMM, ADA, and RF) to the established BOADICEA model by training them on biennial mammograms
[40][52]. When screening for lifetime risk of breast cancer, all models (0.843 ≤ AUROC ≤ 0.889) outperformed BOADICEA (AUROC = 0.639. Similar findings have been concluded in prostate cancer, where three studies (Perera et al., Chiu et al., and Bienecke et al.) compared numerous ML models (DNN, XGBoost, LightGBM, CatBoost, SVM, LR, RF, and multiplayer perceptron)
[41][42][43][53,54,55]. Although all studies trained their respective models differently (PSA levels, prostate biopsy, or EHRs), all concluded that the ML algorithms were efficacious in predicting prostate cancer. Ultimately, there appears to be a substantial body of literature supporting the effectiveness of ML methods in predicting different types of cancer.
8. Human Immunodeficiency Virus and Sexually Transmitted Diseases
Another sector of primary care requiring additional applications to assist in its diagnosis and screening is the human immunodeficiency virus (HIV) and sexually transmitted diseases (STDs). In 2021, Turbe et al. trained a DL model on the rapid diagnostic test to classify rapid HIV in rural South Africa
[44][56]. Relative to traditional reports of accuracy varying between 80 and 97%, this model achieved an accuracy of 98.9%. Similarly, Bao et al. compared 5 mL models predicting HIV and STIs
[45][57]. GBM was the best performing, with AUROC scores of 0.763, 0.858, 0.755, and 0.68 for HIV, syphilis, gonorrhea, and chlamydia, respectively. Another study, Marcus et al., developed and assessed an HIV prediction model to find potential pre-exposure prophylaxis (PrEP) patients
[46][58]. Using EHR data to train the model, the study reported an AUC score of 0.84. In terms of future predictions, Elder et al. compared 6 mL algorithms when determining patients at risk of additional STIs within the next 24–48 months through previous EHR data
[47][59]. The Bayesian Additive RT was the best-performing model with an AUROC score of 0.75 and a sensitivity of 0.915. A number of studies have also reported plausible applications of AI on urinary tract infections (UTIs). Gadalla et al. have assessed how AI models can identify predictors for a UTI diagnosis through training on potential biomarkers and clinical data from urine
[48][60]. The study concluded that clinical information was the strongest predictor, with an AUC score of 0.72, a PPV of 0.65, an NPV of 0.79, and an F1 score of 0.69. Comparatively, in Taylor et al., vitals, lab results, medication, chief complaints, physical exam findings, and demographics were all utilized for training, validating, and testing a number of ML algorithms to predict UTIs in ED patients
[49][61]. The AUC scores ranged from 0.826 to 0.904, with XGBoost being the best-performing algorithm. Therefore, the benefits of using ML models to predict and screen for HIV and STDs are evident.
9. Obstructive Sleep Apnea Syndrome
There are a number of studies that have reported the use of ML for detecting obstructive sleep apnea syndrome (OSAS). For OSAS, findings have generally been positive, as in the case of a study by Tsai et al.
[50][62]. LR, k-nearest neighbor, CNN, naïve Bayes, RF, and SVM were all compared for screening moderate-to-severe OSAS by being trained on demographic and information-based questionnaires. The study found that BMI was the most influential parameter, and RF achieved the highest accuracy in screening for both types. In another study, Alvarez et al. trained and tested a regression SVM on polysomnography and found that the dual-channel approach was a better performer than oximetry and airflow
[51][63]. Mencar et al. used demographic and information questionaries again to predict OSAS severity
[52][64]. SVM and RF were the best in classification, with the strongest average in classification being 44.7%. This study demonstrates some variability in studies attempting to define a conclusion between AI and OSAS. Overall, there is lack of literature to make a comprehensive conclusion regarding the use of ML for OSAS.
10. Osteoporosis
Regarding osteoporosis and related diseases, four studies have compared a number of AI models (XGBoost, LR, multiplayer perceptron, SVM, RF, ANN, extreme GB, stacking with five classifiers, and SVM with radial basis function kernel)
[53][54][55][56][65,66,67,68]. Models were trained on EHR, CT and clinical data, or abdomen-pelvic CT. All studies concluded that ML methods were valid and presented great potential in screening for osteoporosis. An additional study trained ML models (RF, GB, NN, and LR) on genomic data for fracture prediction
[57][69]. The study found that GB was the best-performing model, with an AUC score of 0.71 and an accuracy of 0.88. Ultimately, more studies are required to confirm the effectiveness of ML for predicting osteoporosis.
11. Chronic Conditions
Chronic obstructive pulmonary disease (COPD) is characterized by permanent lung damage and airway blockage. To enhance life quality and lower mortality rates, COPD must be diagnosed and treated early. The early identification, diagnosis, and prognosis of COPD can be aided by ML methods
[58][70]. The likelihood of hospitalization, mortality, and COPD exacerbations have all been predicted using ML algorithms. These algorithms create predictive models using a variety of data sources, including patient demographics, clinical symptoms, and imaging data. For instance, Zeng et al. developed an ML algorithm trained on 278 candidate features
[59][71]. The model achieved an AUROC of 0.866. Another chronic condition, chronic kidney disease (CKD), is characterized by a progressive decline in kidney function over time. Kidney failure can be prevented, and patient outcomes can be enhanced by early detection and care of CKD. The early detection, diagnosis, and management of CKD can be helped by ML algorithms. For instance, Nishat et al. developed an ML system to predict the probability of CKD. Eight supervised algorithms were developed, and RF was the best-performing mode reporting an accuracy of 99.75%
[60][72]. At the final stage of CKD, known as ESKD, patients require dialysis or a kidney transplant. The early detection, diagnosis, and management of ESKD can be facilitated by ML algorithms. ML algorithms have been used to forecast mortality and the risk of ESKD in CKD patients. These algorithms create predictive models using a variety of data sources, including medical records, test results, and demographic information. For instance, Bai et al. trained five ML models on a longitudinal CKD cohort to predict ESKD
[61][73]. LR, naive Bayes, and RF achieved similar predictability and sensitivity and outperformed the Kidney Failure Risk Equation. Since chronic conditions are a critical aspect of primary care, more studies involving a variety of ML models are needed to confirm MLs’ potential.
12. Detecting COVID-19 and Influenza
ML has shown great promise in detecting and differentiating between common conditions, propagating more effective recommendations and guidelines (
Figure 2). Specifically, detection research has rocketed with the rise and timeline of the COVID-19 virus
[62][74]. Zhou et al. developed an XGBoost algorithm to distinguish between influenza and COVID-19 in case there are no laboratory results of pathogens
[63][75]. The model used EHR data to achieve AUC scores of 0.94, 0.93, and 0.85 in the training, testing, and external validation datasets. Similarly, in Zan et al., a DL model, titled
DeepFlu, was utilized to predict individuals at risk of symptomatic flu based on gene expression data of influenza A viruses (IAV) or the infection subtypes H1N1 or H3N2
[64][76]. The DeepFlu achieved an accuracy score of 0.70 and an AUROC of 0.787. In another study, Nadda et al. combined LSTM with an NN model to interpret patients’ symptoms for disease detection
[65][77]. For dengue and cold patients, the combination of models achieved AUCs of 0.829 and 0.776 for flu, dengue, and cold, and 0.662 for flu and cold. For influenza, Hogan et al. and Choo et al. trained multiple ML models on nasopharyngeal swab samples and the mHealth app, respectively, for influenza diagnosis and screening
[66][67][78,79]. Both studies concluded that ML methods are capable of being utilized for infectious disease testing. Similar findings were presented for chronic coughs in Luo et al., where a DL model, BERT, could accurately detect chronic coughs through diagnosis and medication data
[67][79]. Additionally, in Yoo et al., severe pharyngitis could be detected through the training of smartphone-based DL algorithms on self-taken throat images (AUROC 0.988)
[68][80]. In summary, ML appears to be effective in screening and distinguishing between COVID-19, influenza, and related illnesses.
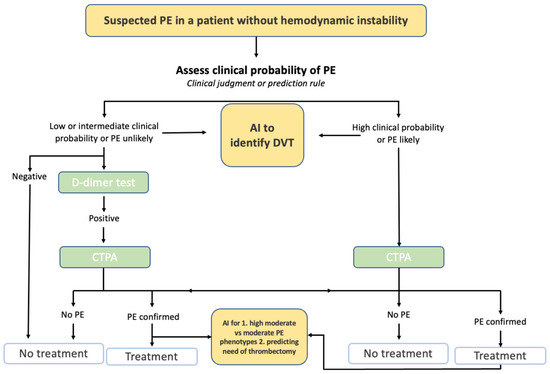
Figure 2. Example of AI in Pulmonary Embolism Evaluation. Figure Description: Current guidelines for a suspected pulmonary embolism (PE) in a patient without hemodynamic instability requires a clinical probability assessment of the PE. Based on the clinical judgment and a potential D-dimer test, a CT pulmonary angiogram is conducted to determine whether treatment or no treatment will occur. AI has the potential to be integrated into this process by potentially detecting deep vein thrombosis, detecting high moderate vs. moderate PE phenotypes, and predicting the risk of thrombectomy.
13. Detecting Atrial Fibrillation
Another large center for AI detection is atrial fibrillation (AF). Six studies have evaluated unique ways to detect AF through ML models
[68][69][70][71][72][80,81,82,83,84]. Through wearable devices, countless algorithms (SVM, DNN, CNN, ENN, naïve Bayesian, LR, RF, GB, and W-PPG algorithm combined with W-ECG algorithm) have been trained on primary care data, RR intervals, W-PPG and W-ECG, electrocardiogram and pulse oximetry data, or waveform data. All studies concluded that ML is capable and has the potential to detect AF through wearable devices and through a number of different information. However, more studies to confirm these findings are required.