Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Chao Xie | -- | 1885 | 2023-05-04 07:29:08 | | | |
| 2 | Conner Chen | Meta information modification | 1885 | 2023-05-06 02:35:25 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Tang, H.; Zhu, H.; Fei, L.; Wang, T.; Cao, Y.; Xie, C. Classification of Low Illumination Image Enhancement Methods. Encyclopedia. Available online: https://encyclopedia.pub/entry/43734 (accessed on 25 July 2026).
Tang H, Zhu H, Fei L, Wang T, Cao Y, Xie C. Classification of Low Illumination Image Enhancement Methods. Encyclopedia. Available at: https://encyclopedia.pub/entry/43734. Accessed July 25, 2026.
Tang, Hao, Hongyu Zhu, Linfeng Fei, Tingwei Wang, Yichao Cao, Chao Xie. "Classification of Low Illumination Image Enhancement Methods" Encyclopedia, https://encyclopedia.pub/entry/43734 (accessed July 25, 2026).
Tang, H., Zhu, H., Fei, L., Wang, T., Cao, Y., & Xie, C. (2023, May 04). Classification of Low Illumination Image Enhancement Methods. In Encyclopedia. https://encyclopedia.pub/entry/43734
Tang, Hao, et al. "Classification of Low Illumination Image Enhancement Methods." Encyclopedia. Web. 04 May, 2023.
Copy Citation
As a critical preprocessing technique, low-illumination image enhancement has a wide range of practical applications. It aims to improve the visual perception of a given image captured without sufficient illumination. Conventional low-illumination image enhancement methods are typically implemented by improving image brightness, enhancing image contrast, and suppressing image noise simultaneously. According to the learning method used, people can classify existing low-illumination enhancement methods into four categories, i.e., supervised learning, unsupervised learning, semi-supervised learning, and zero-shot learning methods.
deep learning
low-illumination image enhancement
Retinex theory
1. Supervised Learning Methods
The most crucial feature of supervised learning is that the required data sets are labeled. Supervised learning is learning the model from labeled training data and then using the model to predict its label for some new data. Meanwhile, the more similar the predicted tags are to the given tags, the better the supervised learning algorithm is. Low illumination image enhancement methods based on supervised learning can be roughly divided into end-to-end methods and Retinex theory methods.
1.1. End-to-End Methods
Back in 2017, a deep encoder-based method (LLNet) was first proposed [1], which used a variant of stacked sparse denoising autoencoder to identify features from the low-light image, adaptively enhance and denoise the image. This method is the first end-to-end low illumination enhancement method based on deep learning. Lv et al. [2] proposed a multi-branch image enhancement network MBLLEN. The MBLLEN consists of three types of modules, i.e., the feature extraction module (FEM), the enhancement module (EM), and the fusion module (FM). In this method, different image features are extracted from different levels, which can be enhanced by multiple sub-networks. Finally, the output image is generated by multi-channel fusion. The image noise and artifacts in the low-light area can be suppressed well by this method. At the same time, 3D convolution can be used instead of 2D convolution for low-illumination video enhancement. Wang et al. [3] proposed a Global Awareness and Detail Retention network (GLADNet), which put the input image into the encoder-decoder structure to generate a global illumination estimate and finally used a convolutional network to reconstruct images based on the global care estimate and the original days. To prove the effectiveness of this method, the target recognition performance test is tested on Google Cloud Vision API2. The results show that compared with the original image, Google Cloud Vision can detect more details in the enhanced image and label them. Lu et al. [4] proposed a multi-exposure fusion network, which transferred functions in two sub-networks to generate two enhanced images. Then the noise is further reduced by the simple average fusion method, and the effect is further refined by the refinement element. PRIEN [5] is a progressive enhancement network that is able to continuously extract features from low-illumination images using recursive units composed of recursive layers and residual blocks. This method is the first to directly input low-illumination images into the dual-attention model to extract features. In order to better ensure the network performance, the method reduces the number of parameters by recursively operating a single residual block. Although the network structure of this method is relatively simple, the enhancement effect is also more obvious. C-LIENet [6] includes an encoder-decoder structure composed of convolutional layers, and introduces a unique multi-context feature extraction module, which can extract context features in layers. This method proposes a three-part loss function, which has advantages in local features, structural similarity, and details. Lim et al. [7] proposed a deep Laplacian Restorer (DSLR) for low-illumination image enhancement, which can adjust the global luminance and local details from the input image and gradually fuse them in the image space. The proposed multi-scale Laplacian residuals block makes the training phase more efficient through rich connections of higher-order residuals defined in the multi-scale structure embedded in the feature space.
1.2. Deep Retinex-Based Methods
Compared with the result of end-to-end network learning directly, the method based on deep learning and the Retinex theory sometimes has a better enhancement effect. Wei et al. [8] proposed the first deep learning network based on a data-driven strategy and Retinex theory, which decomposed an image into a reflectance image of independent light rays and a structure-aware illumination image through a decomposition network. Then, a large area of illumination was enhanced by the enhancement network. Finally, the overall image effect was improved by clipping local distribution and BM3D noise reduction. A brief flow diagram of this algorithm is shown in Figure 1. Liang et al. [9] modeled MSR (Multi-Scale Retinex) and proposed the MSR-Net, which includes three modules: multi-scale logarithmic transformation, convolution difference, and color restoration. It directly learns the end-to-end mapping from low-illumination to the true image by training the synthesized low-illumination pair adjusted by Photoshop. Zhang et al. [10] constructed a deep network based on Retinex theory, which is divided into two branch networks, one for regulating illumination and one for removing degradation. It includes three modules: layer decomposition, reflectance restoration, and illuminance adjustment. Multi-scale illuminance enhancement module is used to avoid noise and distortion of enhanced image. R2RNet [11] is a new real-normal network based on the Retinex theory. It includes a decomposition module, a noise reduction module, and a brightness enhancement module and presents a large real-world image pair dataset (LSRW). Wei et al. [12] proposed a novel module, namely NCBC, based on Retinex theory to simultaneously suppress noise and control color deviation, which consists of a convolutional neural network and two loss functions. Its characteristic is that the NCBC module only calculates the loss function in the training stage, which makes the method faster than other algorithms in the test stage.
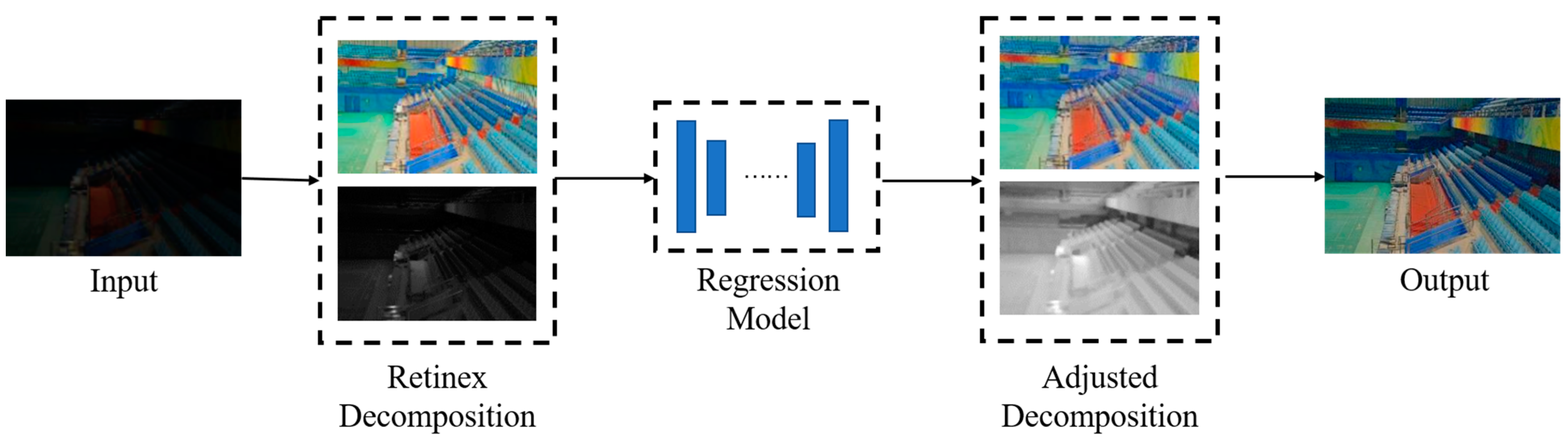
Figure 1. Flowchart of the RetinexNet algorithm. There are three parts: decomposition, adjustment, and reconstruction.
1.3. Deep Transformer-Based Methods
Vision Transformer is currently a research hotspot with supervision tasks. Cui et al. [13] proposed Illumination-Adaptive Transformer (IAT) network, which is a full supervision and training mode and belongs to an ultra-lightweight network. Different from the above solutions, this network adopts the idea of a target detection network DETR (Detection Transformer) [14] and designs an end-to-end transformer to overcome the impact of low illumination on visual effects. The performance of this method is very good, and the speed is the most important feature. Wang et al. [15] proposed a Low-Light Transformer based Network (LLFormer). The core components of the LLFormer are the axis-based multi-head self-attention and cross-layer attention fusion block, which reduces the computational complexity. Meanwhile, Wang et al. built a benchmark dataset of 4K and 8K UHD images (UHD-LOL) to evaluate the proposed LLFormer, which was also the first method to try to solve the UHD-LLIE task.
2. Unsupervised Learning Methods
There are two limitations to the aforementioned methods as mentioned above. First, the pairwise pictures in the datasets are limited. Second, training models on pairwise datasets would cause the over-fitting problem. To solve the above issues, scholars began to use unsupervised learning methods for enhancement. Unsupervised learning is characterized by a learning environment of unlabeled data. Jiang et al. [16] proposed the first unsupervised learning method called EnlightenGAN. A brief flow diagram of this algorithm is shown in Figure 2. EnlightenGAN is the first to introduce non-matching training to this field successfully. The proposed method has two improved parts. Firstly, the global-local discriminator structure deals with spatially varying illumination conditions in the input image. Secondly, the self-feature retention loss and self-regularization attention mechanism are used to keep the image content features unchanged before and after enhancement. Fu et al. [17] proposed a low-illumination enhancement network (LE-GAN) using an invariant identity loss and attention module. They used an illumination sensing attention module to enhance image feature extraction, which improved visual quality while realizing noise reduction and detail enhancement. At the same time, constant loss of identity can solve the problem of overexposure. This paper also established and released a sizeable unpaired low-illumination/normal-illumination image dataset called PNLI. Ni et al. [18] proposed an unsupervised enhancement method called UEGAN. The model is based on a single deep GAN incorporating an attention mechanism to capture more global and local features. The model proposes fidelity loss and quality loss to handle unsupervised image enhancement assurance loss is used to ensure that the content between the enhanced image and the input image is the same, and quality loss is used to assign the desired features to the image. Zhang et al. [19] proposed an unsupervised low-illumination image enhancement method (HEP) using histogram equalization. This method introduced the noise separation module (NDM), which separates the noise and content in the reflectance map with unmatched image pairs. Through histogram equalization and the NDM module, the texture information and brightness details of the image can be well enhanced, and the noise in the dark and yellow area of the image can be well suppressed.
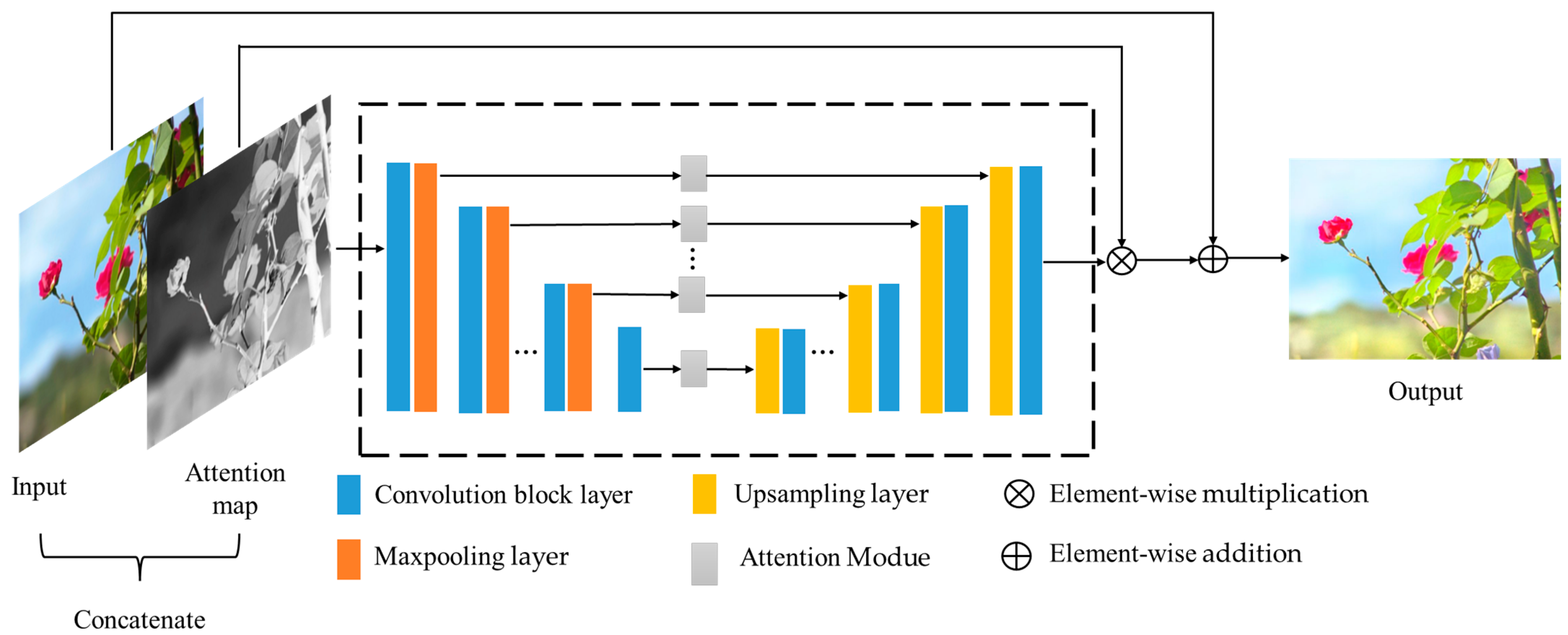
Figure 2. Flowchart of the EnlightenGAN algorithm.
3. Semi-Supervised Learning Methods
Semi-supervised learning was proposed not long ago. It combines the advantages of supervised learning and unsupervised learning. Semi-supervised learning requires labeled data as well as unlabeled data. The characteristic of the semi-supervised learning method is to use many unlabeled samples and a small number of labeled samples to train the classifier, which can solve the problem of more labeled samples and less unlabeled samples. Yang et al. [20] proposed a semi-supervised low-illumination image enhancement method (DRBN) based on frequency band representation. A brief flow diagram of this algorithm is shown in Figure 3. The network is a deep recursive band network, which first restores the linear band representation of the enhanced image based on pairwise low/standard light images, and obtains the improved band representation by relocating the given band. This band can remove not only noise but also correct image details. A semi-supervised learning network called HybirdNet was proposed by Robert et al. [21]. The network is divided into two branches. The first branch is responsible for receiving the supervised signals and is used to extract the invariant components. The second branch is entirely unsupervised and is used to reconstruct the model information discarded by the first branch as input data.
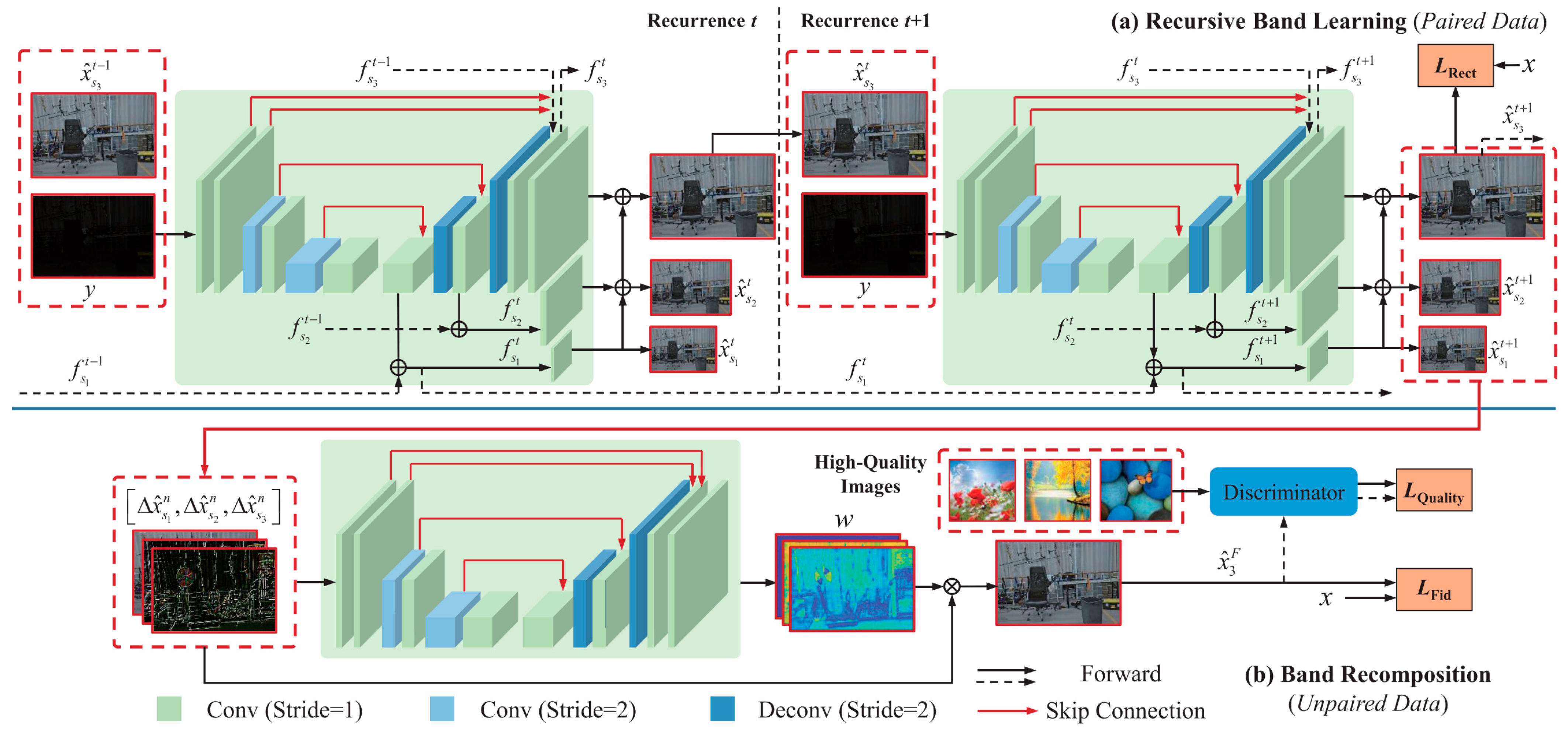
Figure 3. Flowchart of the DRBN algorithm, which consists of two stages: recursive band learning and band recomposition.
4. Zero-Shot Learning Methods
The advantage of zero-short learning is that training data is not required. This method does not need to be trained in advance and can directly take the low-light image to be enhanced as the input. Zhu et al. [22] proposed a new three-branch fully convolutional neural network called RRDNet. The input image is decomposed into three components: illumination, reflection, and noise. By iterating the loss function, the noise is estimated, and the lighting is effectively restored, allowing the noise to be predicted clearly, making it possible to eliminate image noise. RRDNet proposes a new loss algorithm to optimize the image decomposition effect, which can estimate the noise in the dark area according to the image brightness distribution to avoid the noise in the dark area being over-amplified. A brief flow diagram of this algorithm is shown in Figure 4. Inspired by the super-resolution model, Zhang et al. [23] proposed a CNN network (ExCNet) specifically for testing. In the test, the network estimates a parametric curve most suitable for the test backlight image, which can be used to enhance the image directly. The advantages of ExCNet are that it is ideal for complex shooting environments and severe backlight environments. In the video enhancement process, the following structure is guided by the parameters of the previous frame to avoid the phenomenon of artifacts.
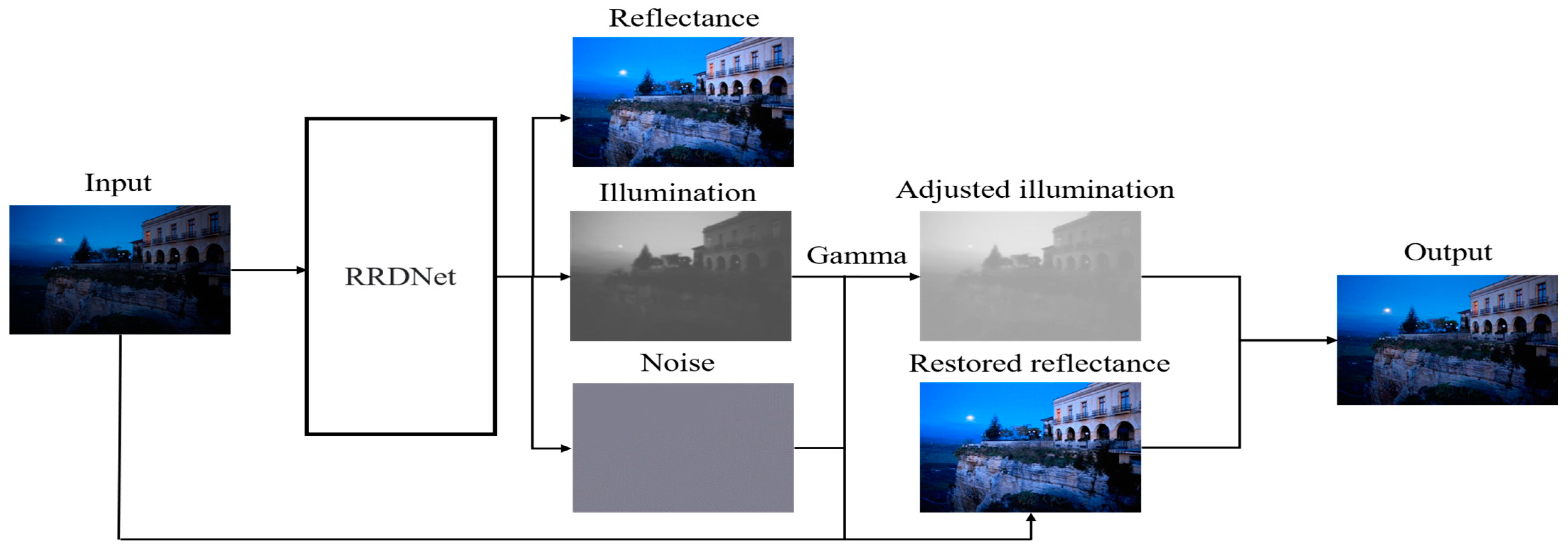
Figure 4. Flowchart of the RRDNet algorithm.
References
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662.
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the the BMVC, Newcastle, UK, 3–6 September 2018; p. 4.
- Wang, W.; Wei, C.; Yang, W.; Liu, J. Gladnet: Low-light enhancement network with global awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 751–755.
- Lu, K.; Zhang, L. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4093–4105.
- Li, J.; Feng, X.; Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4227–4240.
- Ravirathinam, P.; Goel, D.; Ranjani, J.J. C-LIENet: A multi-context low-light image enhancement network. IEEE Access 2021, 9, 31053–31064.
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284.
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560.
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:1711.02488.
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640.
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.; Zou, F.; Lin, F.; Han, S. R2rnet: Low-light image enhancement via real-low to real-normal network. arXiv 2021, arXiv:2106.14501.
- Wei, X.; Zhang, X.; Wang, S.; Cheng, C.; Huang, Y.; Yang, K.; Li, Y. BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration. arXiv 2021, arXiv:2106.15953.
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. Illumination Adaptive Transformer. arXiv 2022, arXiv:2205.14871.
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. pp. 213–229.
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method. arXiv 2022, arXiv:2212.11548.
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349.
- Fu, Y.; Hong, Y.; Chen, L.; You, S. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl. -Based Syst. 2022, 240, 108010.
- Ni, Z.; Yang, W.; Wang, S.; Ma, L.; Kwong, S. Towards unsupervised deep image enhancement with generative adversarial network. IEEE Trans. Image Process. 2020, 29, 9140–9151.
- Zhang, F.; Shao, Y.; Sun, Y.; Zhu, K.; Gao, C.; Sang, N. Unsupervised low-light image enhancement via histogram equalization prior. arXiv 2021, arXiv:2112.01766.
- Qiao, Z.; Xu, W.; Sun, L.; Qiu, S.; Guo, H. Deep Semi-Supervised Learning for Low-Light Image Enhancement. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 23–25 October 2021; pp. 1–6.
- Robert, T.; Thome, N.; Cord, M. HybridNet: Classification and Reconstruction Cooperation for Semi-supervised Learning. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 158–175.
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6.
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1623–1631.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
997
Revisions:
2 times
(View History)
Update Date:
06 May 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No