 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Li Yu | -- | 2726 | 2022-07-26 09:37:02 | | | |
| 2 | Lindsay Dong | -22 word(s) | 2704 | 2022-07-27 04:00:54 | | |
Video Upload Options
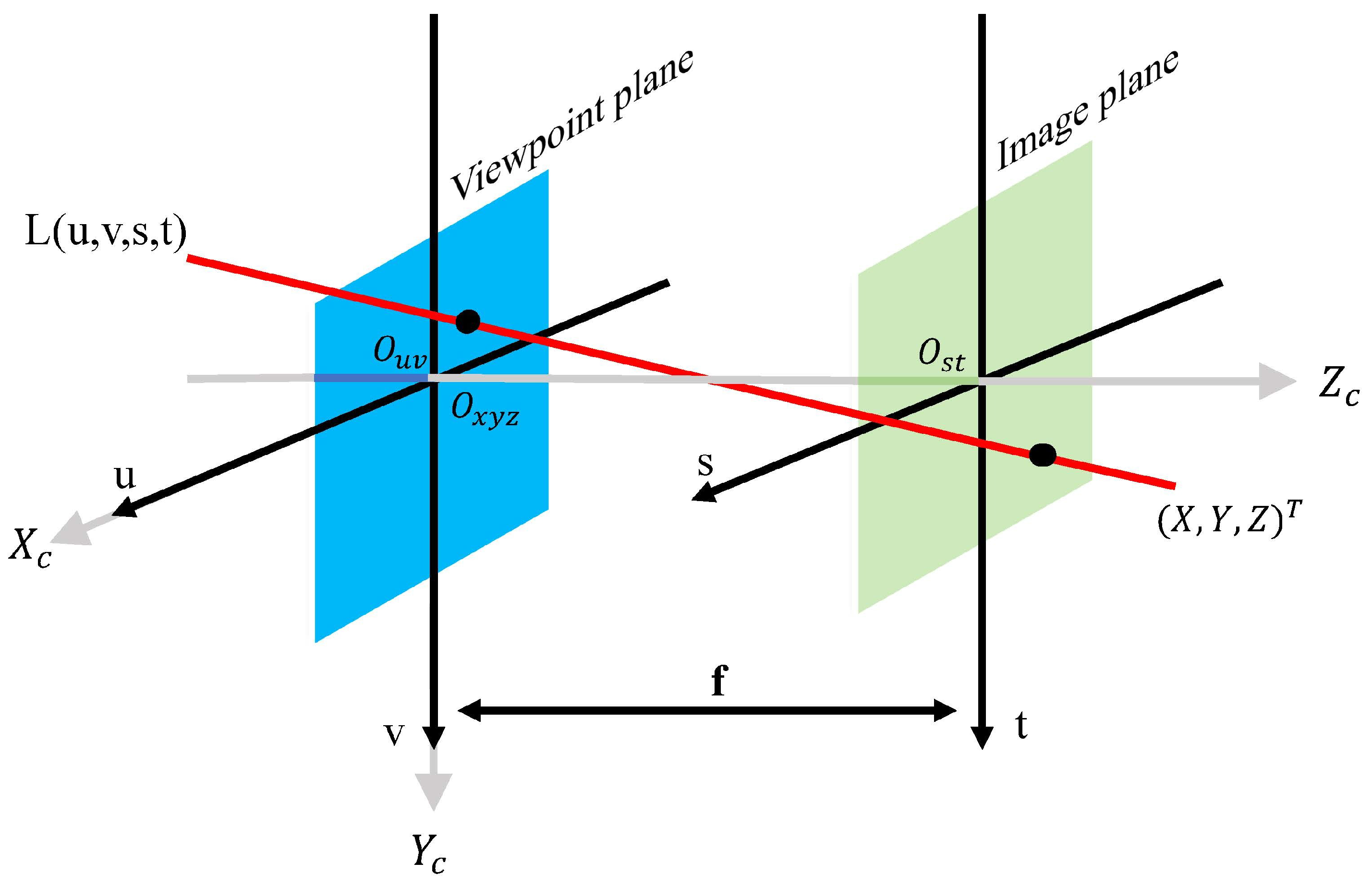
Light fields play important roles in industry, including in 3D mapping, virtual reality and other fields. However, as a kind of high-latitude data, light field images are difficult to acquire and store. Compared with traditional 2D planar images, 4D light field images contain information from different angles in the scene, and thus the super-resolution of light field images needs to be performed not only in the spatial domain but also in the angular domain. In the early days of light field super-resolution research, many solutions for 2D image super-resolution, such as Gaussian models and sparse representations, were also used in light field super-resolution. With the development of deep learning, light field image super-resolution solutions based on deep-learning techniques are becoming increasingly common and are gradually replacing traditional methods.
1. Introduction
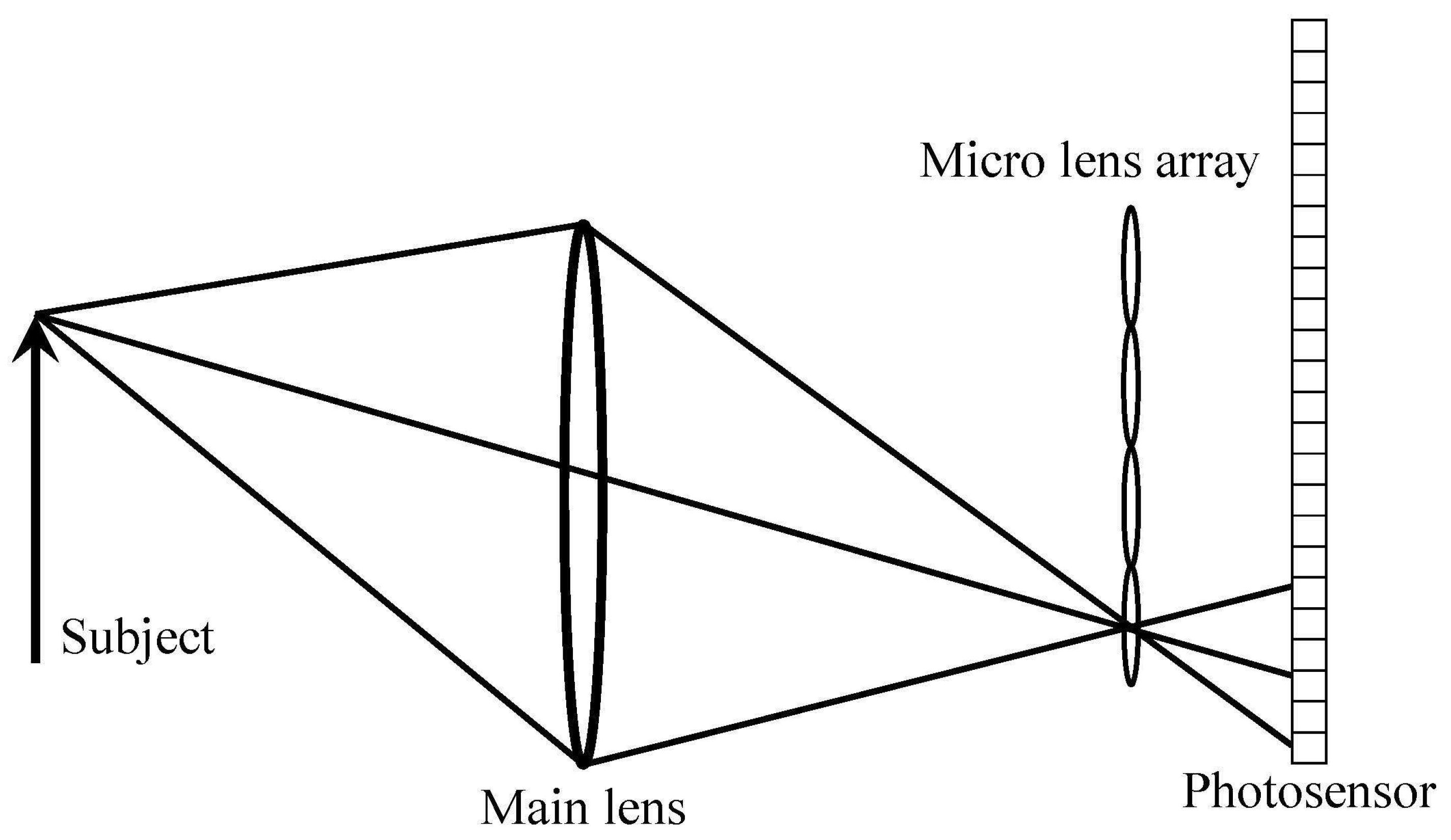
2. Traditional Method
2.1. Projection-Based LFSR
2.2. Priori-Knowledge Based LFSR
3. Deep-Learning-Based Method
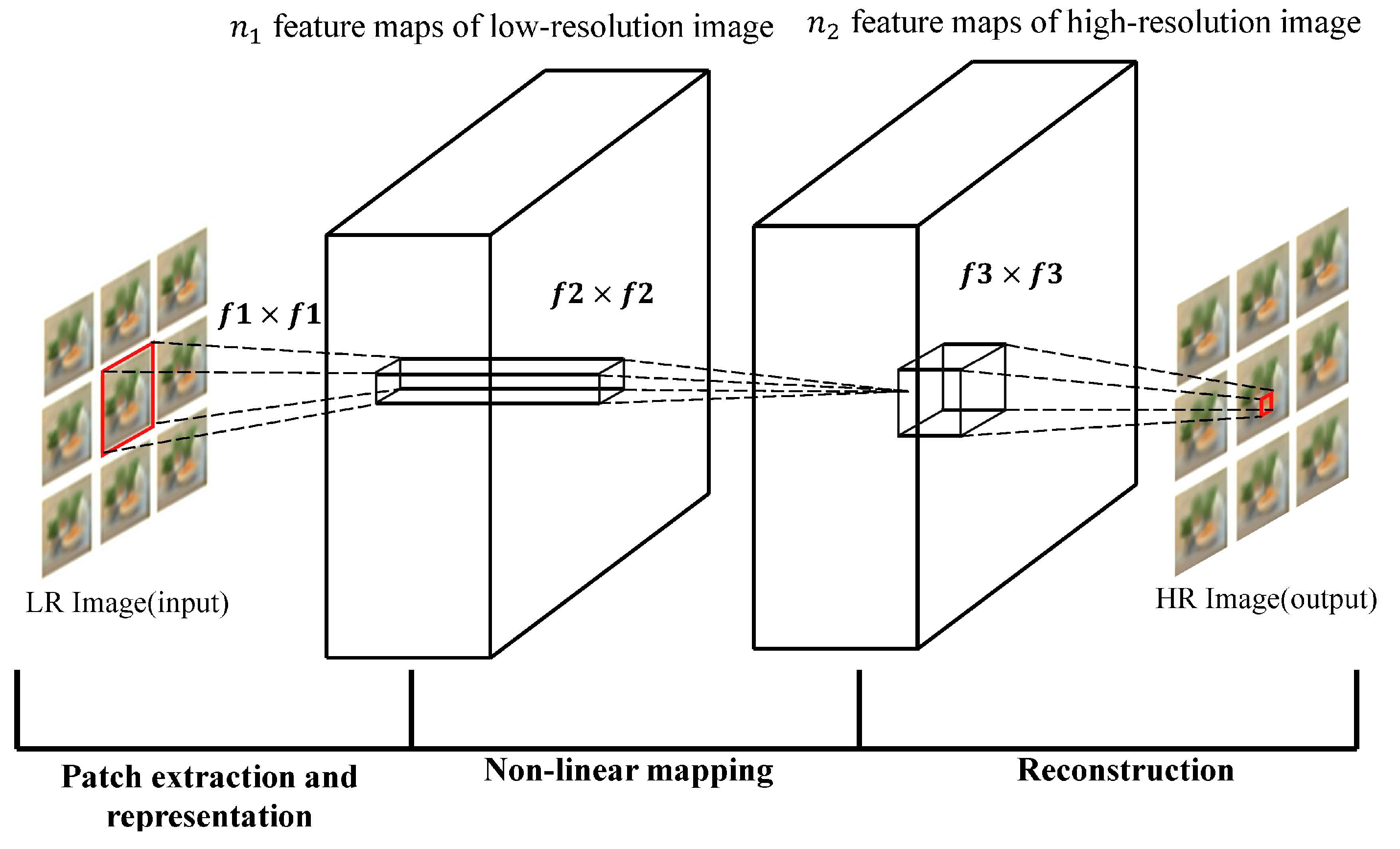
- 1.
-
Patch extraction and representation: This operation extracts patches from low-resolution images and expresses them as high-dimensional vectors. The dimensionality of the vector is equal to the number of feature maps.
- 2.
-
Non-linear mapping: This operation can non-linearly map the high-dimensional vector extracted in 1 to another high-dimensional vector, and each mapping vector can conceptually represent a high-resolution patch; these mapping vectors form another set of feature maps.
- 3.
-
Reconstruction: This operation will operate the high-resolution patch set obtained in Step 2 to generate the final high-resolution image.
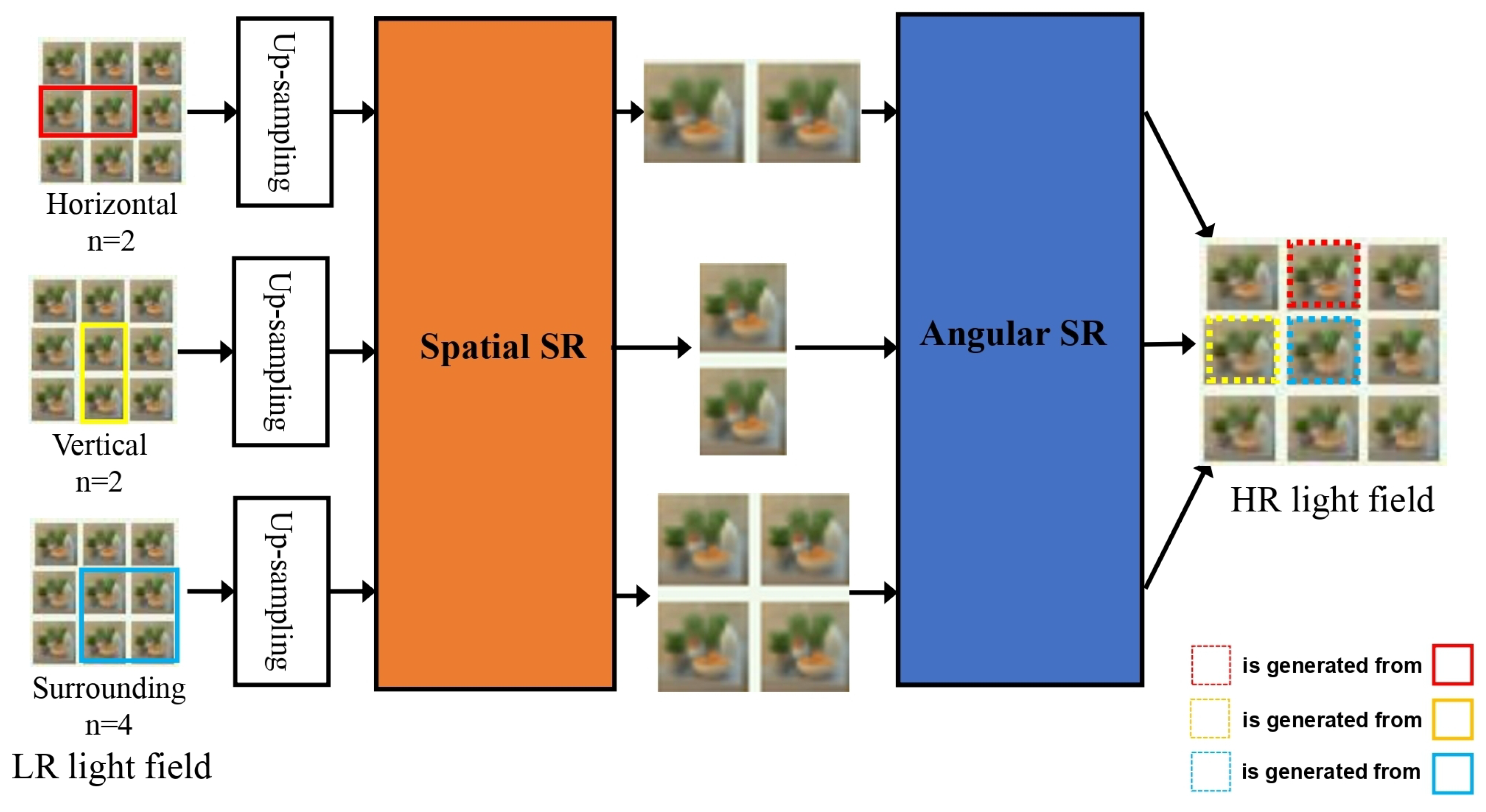
3.1. Sub-Aperture-Image-Based LFSR
3.1.1. Intra-Image-Similarity-Based LFSR
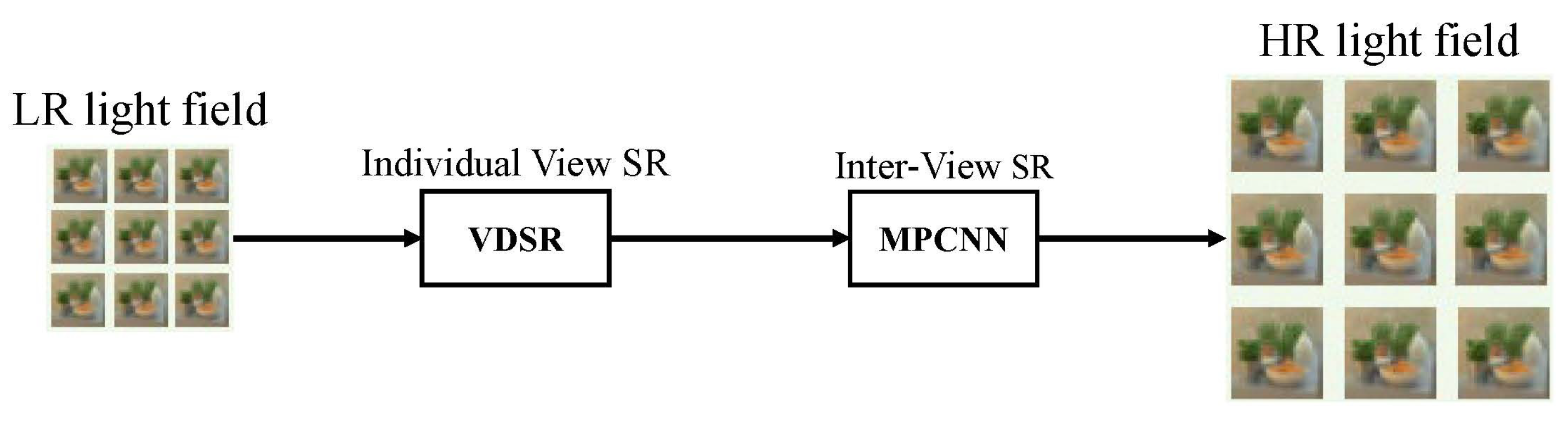
3.1.2. Inter-Image-Similarity-Based LFSR
3.2. Epipolar-Plane-Image-Based LFSR
4. Data Set and Comparison
4.1. Data Set
| Data Set | Years | Number of Scenes | Shooting Method |
|---|---|---|---|
| HCI old [39] | 2013 | 13 | Blender Synthesis |
| STFlytro [40] | 2016 | 9 | Lytro Illum |
| EPFL [41] | 2016 | 10 | Lytro Illum |
| HCI [42] | 2016 | 24 | Blender Synthesis |
| 30scenes [43] | 2016 | 30 | CNN Synthesis |
4.2. Comparison
| Traditional Method | Deep-Learning-Based Method | |
|---|---|---|
| Reconstruction Quality | Good detail but poor overall quality |
Good detail and overall quality |
| Advantages | No training required. Process explainable. |
Automatic feature extraction. Parallel processing. |
| Disadvantages | Relying on expert experience. Weak generalization ability. Poor robustness. |
High computational complexity. Relying on dataset. |
As for performance, several traditional and deep-learning-based LFSR works are selected for comparison, as shown in Table 3. The ×2 SR ratio is chosen. PSNR and SSIM are evaluation metrics.
| Dataset | HCI Old (PSNR/SSIM) |
HCI (PSNR/SSIM) | EPFL (PSNR/SSIM) | STF Lytro (PSNR/SSIM) | |
|---|---|---|---|---|---|
| Method | |||||
| Mitra [44] | 29.60/0.899 | - | - | 25.70/0.724 | |
| Wanner [45] | 30.22/0.901 | - | - | - | |
| Wang [46] | 35.14/0.951 | - | - | - | |
| farrugia [47] | 30.57/- | - | - | 32.13/- | |
| Pendu [24] | 38.64/- | 36.77/- | - | - | |
| Yoon [18] | 37.47/0.974 | - | - | 29.50/0.796 | |
| Wang [48] | 36.46/0.964 | 33.63/0.932 | 32.70/0.935 | 30.31/0.815 | |
| Zhang [49] | 41.09/0.988 | 36.45/0.979 | 35.48/0.973 | - | |
| Kim [27] | 40.34/0.985 | 34.37/0.956 | 32.01/0.959 | 29.99/0.803 | |
| Ko [31] | 42.06/0.989 | 37.21/0.977 | 36.00/0.982 | - | |
| Jin [32] | - | 38.52/0.959 | - | 41.96/0.979 | |
| Yeung [33] | - | - | - | 40.50/0.977 | |
| Wang [50] | 44.65/0.995 | 37.20/0.976 | 34.76/0.976 | 38.81/0.983 | |
| Zhang [51] | 42.14/0.981 | 37.01/0.963 | 35.81/0.961 | - | |
| Fan [34] | 40.77/0.968 | - | - | - | |
| Cheng [52] | 36.10/- | - | 30.41/- | - | |
| Ma [53] | 43.90/0.993 | 40.49/0.986 | 41.38/0.989 | - | |
| Jin [54] | - | - | - | 34.39/0.951 | |
| Cheng [55] | 40.03/- | 37.94/- | 34.78/- | 38.05/- | |
| Ribeiro [56] | 45.49/0.964 | 38.22/0.956 | 34.41/0.953 | - | |
| Farrugia [57] | - | - | - | 32.41/0.884 | |
| Meng [58] | - | 32.45/- | 34.20/- | - | |
| Wu [59] | - | - | - | 42.48/- | |
| Zhu [60] | - | - | - | 33.04/0.958 | |
| Wafa [35] | 39.76/0.968 | - | - | 44.45/0.995 | |
| Yuan [36] | 38.63/0.954 | - | - | 40.61/0.984 | |
| Meng [61] | 33.12/0.913 | 34.64/0.933 | 35.97/0.947 | 38.30/0.969 | |
| Kim [62] | - | - | - | 39.25/0.990 | |
| Jin [63] | 41.80/0.974 | 37.14/0.966 | - | - | |
References
- Faraday, M. LIV. Thoughts on ray-vibrations. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1846, 28, 345–350.
- Gershun, A. The light field. J. Math. Phys. 1939, 18, 51–151.
- Bergen, J.R.; Adelson, E.H. The plenoptic function and the elements of early vision. Comput. Model. Vis. Process. 1991, 1, 8.
- Levoy, M.; Hanrahan, P. Light field rendering. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, New York, NY, USA, 4–9 August 1996; pp. 31–42.
- Georgiev, T.; Yu, Z.; Lumsdaine, A.; Goma, S. Lytro camera technology: Theory, algorithms, performance analysis. Multimed. Content Mob. Devices 2013, 8667, 458–467.
- Guillo, L.; Jiang, X.; Lafruit, G.; Guillemot, C. Light Field Video Dataset Captured by a R8 Raytrix Camera (with Disparity Maps); International Organisation for Standardisation ISO/IEC JTC1/SC29/WG1 & WG11; ISO: Geneva, Switzerland, 2018.
- Bishop, T.E.; Zanetti, S.; Favaro, P. Light field superresolution. In Proceedings of the 2009 IEEE International Conference on Computational Photography (ICCP), San Francisco, CA, USA, 16–17 April 2009; pp. 1–9.
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Model. Image Process. 1991, 53, 231–239.
- Nava, F.P.; Luke, J. Simultaneous estimation of super-resolved depth and all-in-focus images from a plenoptic camera. In Proceedings of the 2009 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; pp. 1–4.
- Bishop, T.E.; Favaro, P. The light field camera: Extended depth of field, aliasing, and superresolution. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 972–986.
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387.
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27.
- Wang, X.; Chen, S.; Liu, J.; Wei, G. High Edge-Quality Light-Field Salient Object Detection Using Convolutional Neural Network. Electronics 2022, 11, 1054.
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188.
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244.
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. arXiv 2019, arXiv:1912.00271.
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear Recognition Based on Deep Unsupervised Active Learning. IEEE Sens. J. 2021, 21, 20704–20713.
- Yoon, Y.; Jeon, H.G.; Yoo, D.; Lee, J.Y.; So Kweon, I. Learning a deep convolutional network for light-field image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Washington, DC, USA, 7–13 December 2015; pp. 24–32.
- Lim, J.; Ok, H.; Park, B.; Kang, J.; Lee, S. Improving the spatail resolution based on 4D light field data. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1173–1176.
- Stark, H.; Oskoui, P. High-resolution image recovery from image-plane arrays, using convex projections. JOSA A 1989, 6, 1715–1726.
- Ng, R. Fourier slice photography. In ACM Siggraph 2005 Papers; ACM: New York, NY, USA, 2005; pp. 735–744.
- Pérez, F.; Pérez, A.; Rodríguez, M.; Magdaleno, E. Fourier slice super-resolution in plenoptic cameras. In Proceedings of the 2012 IEEE International Conference on Computational Photography (ICCP), Seattle, WA, USA, 28–29 April 2012; pp. 1–11.
- Boominathan, V.; Mitra, K.; Veeraraghavan, A. Improving resolution and depth-of-field of light field cameras using a hybrid imaging system. In Proceedings of the 2014 IEEE International Conference on Computational Photography (ICCP), Santa Clara, CA, USA, 2–4 May 2014; pp. 1–10.
- Le Pendu, M.; Smolic, A. High resolution light field recovery with fourier disparity layer completion, demosaicing, and super-resolution. In Proceedings of the 2020 IEEE International Conference on Computational Photography (ICCP), Saint Louis, MO, USA, 24–26 April 2020; pp. 1–12.
- Le Pendu, M.; Guillemot, C.; Smolic, A. A fourier disparity layer representation for light fields. IEEE Trans. Image Process. 2019, 28, 5740–5753.
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307.
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654.
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144.
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 184–199.
- Gul, M.S.K.; Gunturk, B.K. Spatial and angular resolution enhancement of light fields using convolutional neural networks. IEEE Trans. Image Process. 2018, 27, 2146–2159.
- Ko, K.; Koh, Y.J.; Chang, S.; Kim, C.S. Light field super-resolution via adaptive feature remixing. IEEE Trans. Image Process. 2021, 30, 4114–4128.
- Jin, J.; Hou, J.; Chen, J.; Kwong, S. Light field spatial super-resolution via deep combinatorial geometry embedding and structural consistency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 13–19 June 2020; pp. 2260–2269.
- Yeung, H.W.F.; Hou, J.; Chen, X.; Chen, J.; Chen, Z.; Chung, Y.Y. Light field spatial super-resolution using deep efficient spatial-angular separable convolution. IEEE Trans. Image Process. 2018, 28, 2319–2330.
- Fan, H.; Liu, D.; Xiong, Z.; Wu, F. Two-stage convolutional neural network for light field super-resolution. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1167–1171.
- Wafa, A.; Pourazad, M.T.; Nasiopoulos, P. A deep learning based spatial super-resolution approach for light field content. IEEE Access 2020, 9, 2080–2092.
- Yuan, Y.; Cao, Z.; Su, L. Light-field image superresolution using a combined deep CNN based on EPI. IEEE Signal Process. Lett. 2018, 25, 1359–1363.
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803.
- Wu, G.; Wang, Y.; Liu, Y.; Fang, L.; Chai, T. Spatial-angular attention network for light field reconstruction. IEEE Trans. Image Process. 2021, 30, 8999–9013.
- Wanner, S.; Meister, S.; Goldluecke, B. Datasets and benchmarks for densely sampled 4D light fields. In Proceedings of the Vision, Modeling, and Visualization, Lugano, Switzerland, 11–13 September 2013; Volume 13, pp. 225–226.
- Raj, A.S.; Lowney, M.; Shah, R. Light-Field Database Creation and Depth Estimation; Stanford University: Palo Alto, CA, USA, 2016.
- Rerabek, M.; Ebrahimi, T. New light field image dataset. In Proceedings of the Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016.
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A dataset and evaluation methodology for depth estimation on 4D light fields. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, China, 20–24 November 2016; pp. 19–34.
- Kalantari, N.K.; Wang, T.C.; Ramamoorthi, R. Learning-based view synthesis for light field cameras. ACM Trans. Graph. (TOG) 2016, 35, 1–10.
- Mitra, K.; Veeraraghavan, A. Light field denoising, light field superresolution and stereo camera based refocussing using a GMM light field patch prior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 22–28.
- Wanner, S.; Goldluecke, B. Variational light field analysis for disparity estimation and super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 606–619.
- Wang, Y.; Hou, G.; Sun, Z.; Wang, Z.; Tan, T. A simple and robust super resolution method for light field images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1459–1463.
- Farrugia, R.A.; Galea, C.; Guillemot, C. Super resolution of light field images using linear subspace projection of patch-volumes. IEEE J. Sel. Top. Signal Process. 2017, 11, 1058–1071.
- Wang, Y.; Liu, F.; Zhang, K.; Hou, G.; Sun, Z.; Tan, T. LFNet: A novel bidirectional recurrent convolutional neural network for light-field image super-resolution. IEEE Trans. Image Process. 2018, 27, 4274–4286.
- Zhang, S.; Lin, Y.; Sheng, H. Residual networks for light field image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11046–11055.
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-angular interaction for light field image super-resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 290–308.
- Zhang, S.; Chang, S.; Lin, Y. End-to-end light field spatial super-resolution network using multiple epipolar geometry. IEEE Trans. Image Process. 2021, 30, 5956–5968.
- Cheng, Z.; Xiong, Z.; Liu, D. Light field super-resolution by jointly exploiting internal and external similarities. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2604–2616.
- Ma, D.; Lumsdaine, A.; Zhou, W. Flexible Spatial and Angular Light Field Super Resolution. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 25–28 October 2020; pp. 2970–2974.
- Jin, J.; Hou, J.; Chen, J.; Yeung, H.; Kwong, S. Light Field Spatial Super-resolution via CNN Guided by A Single High-resolution RGB Image. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5.
- Cheng, Z.; Xiong, Z.; Chen, C.; Liu, D.; Zha, Z.J. Light field super-resolution with zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 10010–10019.
- Ribeiro, D.A.; Silva, J.C.; Lopes Rosa, R.; Saadi, M.; Mumtaz, S.; Wuttisittikulkij, L.; Zegarra Rodriguez, D.; Al Otaibi, S. Light field image quality enhancement by a lightweight deformable deep learning framework for intelligent transportation systems. Electronics 2021, 10, 1136.
- Farrugia, R.A.; Guillemot, C. Light field super-resolution using a low-rank prior and deep convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1162–1175.
- Meng, N.; Ge, Z.; Zeng, T.; Lam, E.Y. LightGAN: A deep generative model for light field reconstruction. IEEE Access 2020, 8, 116052–116063.
- Wu, G.; Zhao, M.; Wang, L.; Dai, Q.; Chai, T.; Liu, Y. Light field reconstruction using deep convolutional network on EPI. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6319–6327.
- Zhu, H.; Guo, M.; Li, H.; Wang, Q.; Robles-Kelly, A. Breaking the spatio-angular trade-off for light field super-resolution via lstm modelling on epipolar plane images. arXiv 2019, arXiv:1902.05672.
- Meng, N.; Thus, H.K.H.; Sun, X.; Lam, E.Y. High-dimensional dense residual convolutional neural network for light field reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 873–886.
- Kim, D.M.; Kang, H.S.; Hong, J.E.; Suh, J.W. Light field angular super-resolution using convolutional neural network with residual network. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Split, Croatia, 2–5 July 2019; pp. 595–597.
- Jin, J.; Hou, J.; Chen, J.; Zeng, H.; Kwong, S.; Yu, J. Deep coarse-to-fine dense light field reconstruction with flexible sampling and geometry-aware fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1819–1836.

