1.Extended definition
Innovation and digitalisation of newsrooms are needed to increase the quality and lower the cost of news production, changing how journalists and readers interact with news content and background information [1]. Newsrooms are therefore embracing big data and artificial intelligence (AI) techniques such as knowledge graphs and machine learning (ML) to manage and support the knowledge work needed in all stages of news production. The result is an emerging type of intelligent information system called the Journalistic Knowledge Platform (JKP). JKPs can be described from a functional, an organisational and a technical perspective. From a functional point of view JKPs automate the process of annotating metadata and support daily workflows like news production [2][3], archiving [4][5], management [6][7] and distribution [8][9][10][11]. JKPs harvest and analyse news and social media information over the net in real time [12], leverage encyclopaedic sources [13], and provide journalists with both meaningful background knowledge [14] and newsworthy information [15]. From an organisational viewpoint: JKPs are deployed in newsrooms to manage the knowledge needed to support journalists with creativity and discovery tasks. These are tailored to the particular digital strategies and editorial lines to improve news broadcast. JKPs also follow media standards to facilitate communication with customers and providers, and are subject to legal regulations such as data privacy. From a technical perspective JKPs implement state-of-the-art AI technologies such as machine learning, natural language processing (NLP) and knowledge representation and reasoning. News-relevant information is represented in knowledge bases which are exploited with data analysis, reasoning and information retrieval techniques to help journalists and readers dive more deeply into information, events and storylines.
2. State of Research on JKPs
1.1. Stakeholders
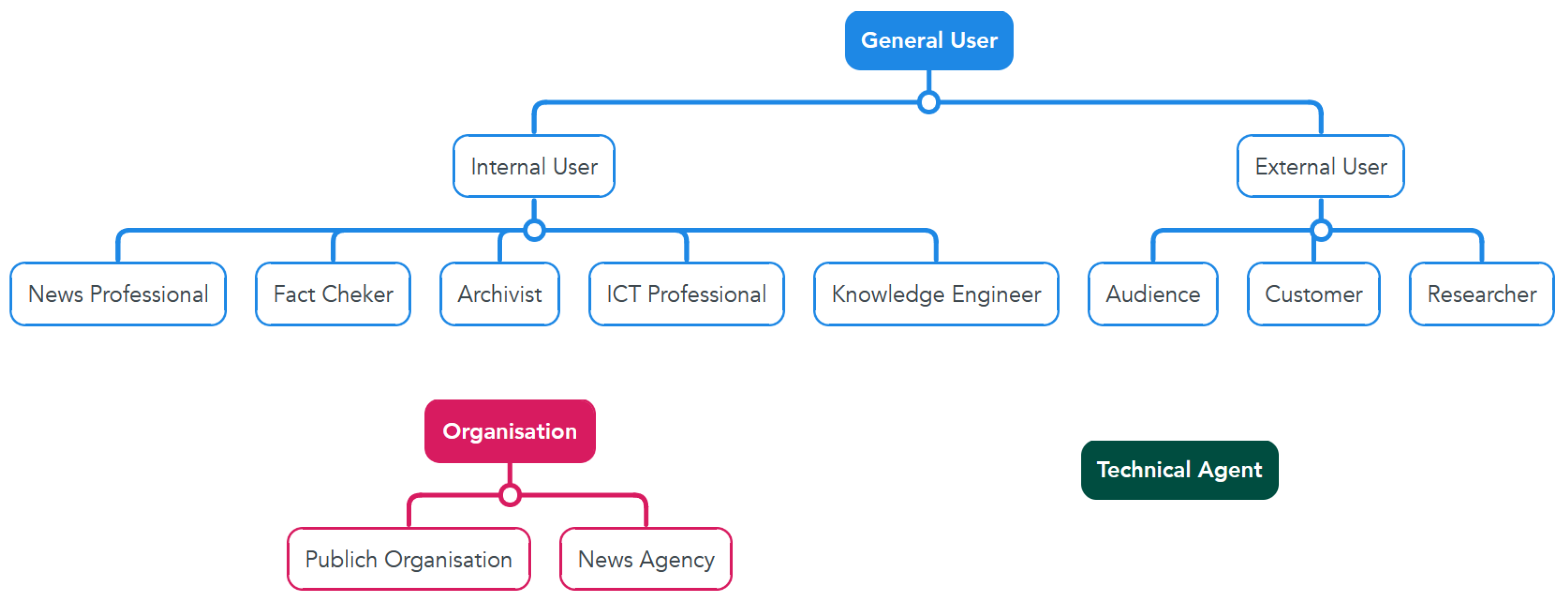
JKPs provide services to and interact with a large variety of stakeholders. Figure 1 shows the identified stakeholders and their three top-level categories: general user, organisation and technical agent.
Figure 1. Stakeholder categories.
The general users can be divided between the internal users that belong to newsrooms and the external ones. The internal users are news professionals like journalists who use JKPs for creating histories
[16][17]; fact-checkers who conduct an essential task in combating with fake news and misinformation
[7]; archivists who maintain up-to-date the schemas and news archives
[4]; ICT professionals and knowledge engineers who develop and maintain JKPs
[2]. Whereas, the external users are the audience
[11]; the customers to whom new agencies offer services and researchers who investigate JKPs or use JKP to analyse data.
JKPs support organisations in different ways: The most direct is in news agencies and news organisations where JKPs are deployed and adapted to particular digital strategies and purposes, but also to other news organisations that consume services from external JKPs. Moreover, JKPs provide services to both private and public organisations like governmental agencies that interact with or consume services from newsrooms. JKPs also interact indirectly with the organisations responsible for controlling news media standards, vocabulary and ontologies (e.g., the IPTC organisation). This impacts how JKPs are designed because the work of many news agencies depends on those standards, and JKPs often need to build on and comply with them. However, the media standards may not cover or fit the use cases of newsrooms. Hence, JKPs need to adapt or expand the media standards according to their needs.
Last but not least, the technical agent represents the JKPs and any system or technical infrastructure in newsrooms that support or interact with JKPs. A sub-type of the technical agent is the external system that communicates with newsroom services, like the customers’ information systems
[16].
1.2. Information
JKPs cover the whole news production pipeline from gathering information and news creation to knowledge exploitation and distribution. Table 1 lists the identified categories of information.
Table 1. The most common types of information managed by JKPs.
News content is annotated and enriched with metadata using LOD, semantic vocabularies and ontologies. Metadata can describe different types of basic information like the authorship, language, creation time, ownership, media type, priority, status, version, keywords and categories; as well as inferred information like provenance, tone and sentiment, and the relevant persons, stories, locations, organisations and events
[4][19][20].
Journalists and customers of newsrooms are highly interested in current events and their related information
[2]. In addition, JKPs are designed to support additional information needs: General users want to have access to details about the stories (i.e., who, what, why, where and when), identify networks of actors and implications, search the events based on their type or place, obtain facts, and retrieve evidences
[5][6][14]. News professionals need access to news archives and knowledge bases for documentation purposes, finding connections from past events, following histories and identifying emerging topics
[4][16][21][22]. Additionally, customers have different information needs depending on their business or interests.
1.3. Functionalities
JKPs provide different functionalities to their users. Table 2 lists the identified main functionalities.
Table 2. Most common type of functionalities and services provided in JKPs.
News professionals use JKPs for news creation. This creative process involves different tasks such as discovering, collecting, organising, contextualising and publishing
[23][24]. JKPs guide news professionals in writing up their stories
[25], support them with contextual background knowledge
[2][3][25], provide the means for comparing current events with other events
[13] and facilitate access to previous work for creating similar content for a different audience, region or language
[22]. JKPs also support news professionals with verification
[26] tasks like fact-checking
[9][27], provenance
[5], rights and authorship management
[16]. These are typically time-consuming tasks for journalists and fact-checkers that JKPs automate
[7].
Source selection and monitoring functionalities are common across the studied JKPs that harvest and store content from internal and external sources and monitor them in real-time
[9][11][21][22]. These functionalities allow journalists to automatically follow and distil news and social media of interest and relieve them from these time-consuming tasks.
Knowledge discovery
[28] is one of the most attractive functionalities of JKPs. It allows users to obtain news insights, analysis and relevant information. Other interesting functionalities among the studied JKPs are the trends identification used to discover emerging topics, long-term developments and changes in events over time
[11][20]; alerts to keep users up-to-date with the last incoming items
[9][29][30]; summarisation
[31] of news histories and events to provide additional insights
[11]; clustering of story lines and events
[13][22].
JKPs can be used as business support systems to manage and monitor internal newsrooms production, news coverage and broadcast decisions
[22][29]. This helps managers and editors in allocating resources, avoiding duplicate work and detecting news that can be relevant to different audiences. JKPs are also used for content management that allows newsrooms to store, organise and distribute the daily produced content and metadata
[4][6][16].
Most of these functionalities should be personalised and tailored to the stakeholders’ needs. Hence, JKPs allow the personalisation of their functionalities according to users’ preferences and profiles
[2][8][32].
1.4. Techniques
JKPs implement and combine different IT techniques to fulfil their functionalities. Table 3 lists the IT techniques that identified.
Table 3. The most common IT techniques used in JKPs.
Semantic technologies
[33] and similar semantic representation techniques are widely utilised in all the studied JKPs. They use semantic technologies for automating annotation, disambiguating, enriching and leveraging news items with information from external knowledge bases
[2][4][9][20]. The semantic representations provide neutral language, explicit relations and facilitate structural matching and lingual independence. They are used for clustering news items and events
[13] and detecting trends and story lines
[5]. These semantic representations together with fact extraction techniques are used to obtain factual claims from news items and link them to their sources and facts in external knowledge bases (e.g., Wikidata, Wikipedia)
[5][9][22].
Conceptual models provide vocabularies, schemas and ontologies. These are often implemented using semantic technologies and represent news stories, events and related information. In addition, conceptual models can define users’ interests and preferences
[8][10][16], and provide shared resources and formats to facilitate content management and semantic interoperability
[4][6][14][20].
Conceptual models and semantic technologies are also used for reasoning, network analysis and event analysis. Reasoning techniques abstract and infer new knowledge from news items, events and temporal aspects
[20]. Network analysis is used to find networks of actors, organisations and their implications
[5]. Event analysis is applied to detect, identify, cluster and annotate the events described in the news
[11][13][16].
The aforementioned techniques are supported by NLP tasks such as named entity recognition, relation extraction and temporal expression normalisation
[9][10][11][20][34]. These NLP tasks, among others, are used in many of the components and functionalities of JKPs. In order to obtain optimal results from the NLP tasks, near-continuous training on extensive news corpora
[13] is needed to always keep the machine learning models up-to-date.
1.5. Components
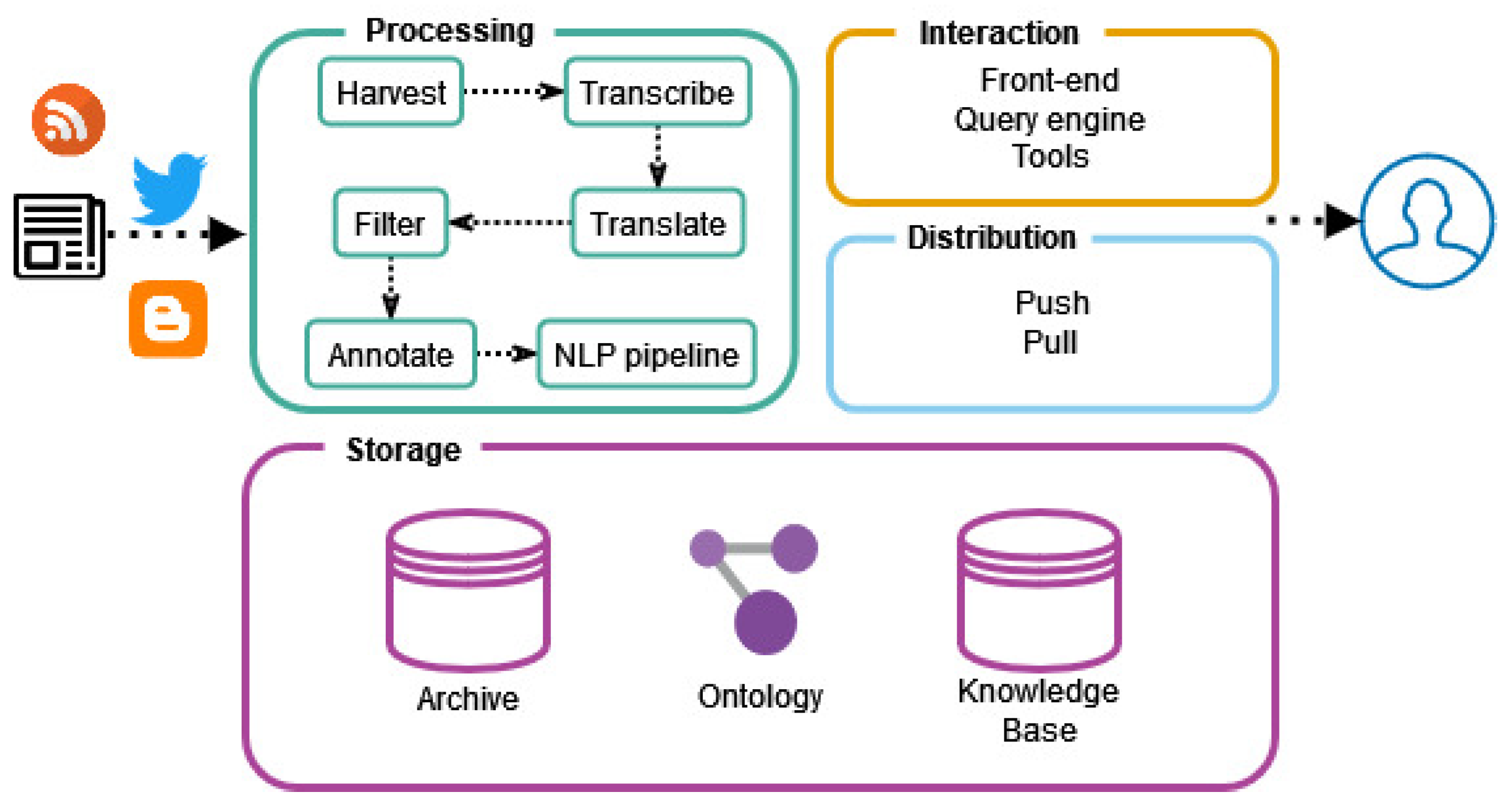
JKPs rely on different components to fulfil their functionalities and support users (see Figure 2).
Figure 2. JKP components.
The processing components cover tasks from data gathering to transforming input sources into knowledge representations. The textual and multimedia sources are continuously harvested. However, not all contents receive the same interest from news professionals. Thus, the harvested content is also translated
[22] and filtered according with the different stakeholders’ interests and needs. In the studied JKPs, spoken content is transcribed
[22] and images are textually described
[2] to be able further process them.
The harvested content is automatically annotated with metadata (e.g., authorship, categories and topics) to support functionalities like business support, content management and personalisation
[4][16][29][32]. The annotated content is often processed by a NLP pipeline using state-of-the-art NLP and natural language understanding modules to perform linguistic tasks such as co-reference resolution, named entity recognition, relation extraction and sentiment analysis
[5][9][35]. Both the results of the NLP pipeline and the annotated content are represented semantically following a predefined schema or ontology. These representations link the annotations to a knowledge base (e.g., an RDF-based knowledge graph)
[10][20] and enrich the news items with facts from external knowledge bases (e.g., the LOD cloud, DBpedia and Wikidata)
[5][13].
The storage infrastructure of a JKP can be composed of an archive, an ontology and a knowledge base. The archive can store millions of historical news articles, biographies, reports
[4][20] and other relevant textual and multimedia items. The knowledge base is where the annotated semantic representations of news items are stored and enriched with external information
[4][5][14]. The ontology is used to represent the structure of the news items, leveraged information, metadata and vocabulary
[4][14][16][29]. Most recent JKPs also include dedicated storage for real-time news-related feeds
[22].
1.6. Concerns
Stakeholders, information, functionalities, techniques and components are influenced or affected by additional concerns of various types. Table 4 lists the identified concerns.
Table 4. Concerns related to JKPs.
The customers of JKPs are heterogeneous. They cover diverse sectors and industries, from other newsrooms to companies and institutions, and use different systems to interact with JKPs
[16][22]. To improve the interoperability between news agencies and stakeholders, JKPs utilise standards like the IPTC news codes, media topics, semantic vocabularies and RDF
[4][16], and keep track of information related to ownership, such as authorship, copyrights, privacy and sources
[2][37]. JKPs can also use the ownership information to control the information provenance and reliability
[5] by, for example, tracking back the information to its original source and identifying trustworthy providers.
JKPs attempt to address different human factors in newsrooms. JKPs automate error-prone and time-consuming processes that were performed manually like news tagging, source monitoring, information filtering, verification, fact-checking and finding related articles and relevant information
[4][7][9][11][16]. Hence, JKPs free journalists from these tedious tasks and improve their results. As a result, JKPs facilitate high-quality information to meet the standards of their stakeholders
[2].
On the technical side, JKPs deal with big data requirements like volume, velocity, variety. Hence, the components of JKPs are designed considering their performance to minimise the processing and distribution times
[2][5]. JKPs also integrate legacy components and facilitate interoperability with other systems and external services
[6][14][16][20][30]. All these factors make the software architecture of JKPs complex and difficult to maintain without guidance.
2. Future Directions for Research on JKPs
2.1. Implications for Research
2.1.1. Stakeholders
Studies on understanding how journalists embrace digital tools can aid in better adapting JKPs to the way journalists work. Such studies should consider the journalists’ perceptions on using intelligent systems for creating news, how journalists process and use background information and the journalists’ experiences working with AI, etc. Along these lines, related studies have been proposed, but not limited to, the journalists’ usage of social media for gathering and verifying information
[38][39] and the relation of the journalism practices and AI
[40][41]. Similar user-oriented studies should be conducted on readers and younger and future generations of news consumers to identify what new forms of interaction and consumption are more appealing to them. These studies could consider, for example, the readers’ perceptions of automated journalism
[42][43] and young people’s engagement with news recommendations
[44].
2.1.2. Information
To date, the knowledge extraction and recognition of entities from images and videos remain limited. Due to that, JKPs are not able to capture enough information from multimedia news. Promising directions for extracting knowledge from multimedia sources are multimodal machine learning approaches
[45] that combine different types of data such as visual and text representations
[46][47] and spoken language understanding tasks that analyse and detect audio speech
[48]. Another limitation for knowledge extraction is the dark entities (i.e., those entities that do not exist yet in the knowledge base)
[49][50]. Fresh stories about newer facts are the most attractive news, therefore, the chances of finding entity representations for those newer facts in knowledge bases are low. Therefore, research on knowledge extraction from multimedia news and dark entities can improve news representation in JKPs.
2.1.3. Functionalities
Non-technical users find it difficult to perform complex searches in knowledge bases, archives and background information due to their lack of expertise. The usage of chatbots can aid user interaction using natural language
[22][51]. Additional solutions that can support journalists’ interaction with knowledge and information, and automate news production are text summarisation
[31], automated reporting or story generation
[52][53] and automatic data visualisation
[54]. Augmented reality may also bring new possibilities for assisting the exploration of information using knowledge representations and LOD
[55].
2.1.4. Techniques
Due to the increase in misinformation and propaganda, it is crucial for journalists and readers to detect and distinguish trustworthy information from fake and biased news. Hence, research on JKPs should include automating the detection of fake news, political bias and rumours across social media platforms and news sources
[26][56]. Techniques for such purposes can benefit from research on automating fact-checking
[7][27], detecting derived or copied works
[11], and media and audio forensics to identify manipulated or tempered multimedia files
[57][58]. In addition, identifying misinformation items before they are stored in the knowledge base can improve the data quality of JKPs. Another promising direction is the inclusion of neural-symbolic AI
[59] techniques as part of the different components of JKPs. Neural-symbolic AI combines neural networks with reasoning and logic. This can facilitate the inference and deductive reasoning over the data in the JKPs and reduce the computational cost of reasoning over knowledge graphs
[60].
2.1.5. Components
In addition to automatic techniques for verification and fact-checking, promising collaborative tools for news and social media verification that involve journalists and readers
[61] should be considered. Some of these tools such as WeVerify employ blockchain and knowledge graphs services for recording debunked claims and news. These collaborative repositories could be considered as additional information sources from which JKPs can obtain checked claims and provenance information but also contribute with verified information. Apart from this, the current JKPs are focused on in-house platforms that are typically accessed through a computer and oriented to print journalism. However, there is limited research on components that can facilitate access to the services offered by JKPs for mobile journalism
[62] (i.e., journalism edited and published through smartphones and oriented towards audio-visual storytelling).
2.1.6. Concerns
There are no gold standards or methodologies to evaluate JKPs. Accordingly, research needs to include the design and study of evaluation methods for JKPs. Moreover, readers and journalists may perceive results from JKPs as less transparent and difficult to understand
[63] as they are driven by AI. To improve their perception of trustworthiness and transparency, research on JKPs should consider explainable AI methods
[64].
2.2. Implications for Practice
2.2.1. Stakeholders
To date, there have not been any studies on the implementation of JKPs in newsrooms. Such studies should evaluate the effectiveness, adoption and demand of JKPs. The experiences in implementing JKPs can help to draw a digitalisation path for newsrooms by providing best practices and identifying the main obstacles and solutions. This can support newsrooms with the definition of their roadmaps towards the adoption of JKPs, as it facilitates the identification of the most relevant aspects of JKPs and particular needs according to their current stage. Related studies have considered and provided guidelines for the utilisation of AI in news creation processes in a broader sense
[65].
2.2.2. Information
The literature is unclear on how JKPs should best represent events and there is no general agreement on what constitutes an event
[11]. Events can range from fine-grained actions like a shot, injury or a handshake between two actors
[5] to bigger and broader events like the Spanish Civil War and the COVID-19 pandemic
[13] or events in between like a trial process. Therefore, research on JKPs needs to define and discuss how different types of events at different granularity can co-exist in a JKP and what conceptualisations of the event are useful for specific use cases.
2.2.3. Functionalities
A better understanding of how to represent events and news items can bring new possibilities for JKPs, for example, on data analysis like measuring the popularity of people and companies
[5], finding cause and effect relations
[11], and identifying newsworthy events for specific audiences and particular user’ interests
[8][32][66].
2.2.4. Techniques
One of the main limitations of the studied JKPs is the extraction of enough and precise information from text and multimedia to represent news stories in high detail
[9][29]. JKPs use relation extraction models to extract the textual relations between the entities in news text
[5][35]. However, these models are in an early research stage and the extracted relations are basic and limited for representing news
[67]. Therefore, the functionalities that are based on these models must be considered for the longer term.
2.2.5. Components
Current open-source large triple-stores are not scalable and their reasoning services are time-consuming and use too many computing resources. This limits the possibilities for JKPs to exploit reasoning capabilities and analyse large knowledge graphs. Hence, scalable triple-stores and mechanisms for better reasoning over large knowledge graphs can ease the incorporation of such solutions and bring new possibilities for JKPs. A promising approach is the inclusion of entity spaces
[68]. These are vector spaces that represent the different entities of a knowledge graph and also capture their semantic information. They can be used to speed up processes that require complex graph explorations like inferring and disambiguating knowledge for unseen entities. Another promising approach for integrating and managing information from different types of databases is the usage of virtual knowledge graph
[69]. Virtual knowledge graphs represent the schema of the different databases and provide mechanisms for querying the databases using SPARQL, hence, it integrates databases on the schema level and reduces data replication.
2.2.6. Concerns
Only the most recent projects proposed systems to deal with big data
[17][20][22]. Their architectures must also keep the machine learning models up-to-date and replace them for future best-of-breed, facilitate the schema evolution of knowledge bases and ease the expansion, distribution and independence of services
[70]. Research on software reference architectures
[71] for JKPs can assist in better designing and implementing them, as well as establishing a vocabulary and a framework to compare JKPs.
 +1 credit
+1 credit