A Journalistic Knowledge Platform (JKP) is an information system that employ artificial intelligence and big data techniques such as machine learning and knowledge graphs to manage and support the knowledge work needed in all stages of news production. JKPs automate the process of annotating metadata and support daily workflows like news production, archiving, monitoring, management and distribution. JKPs harvest and analyse news and social media information over the net in real time, leverage encyclopaedic sources, and provide journalists with both meaningful background knowledge and newsworthy information. JKPs can provide a digitalisation path towards reduced production costs and improved information quality while adapting the current workflows of newsrooms to new forms of journalism and readers’ demands.
- journalistic knowledge platform
- artificial intelligence
- knowledge graph
- journalism
- newsroom
- information system
1.Extended definition
Innovation and digitalisation of newsrooms are needed to increase the quality and lower the cost of news production, changing how journalists and readers interact with news content and background information [1]. Newsrooms are therefore embracing big data and artificial intelligence (AI) techniques such as knowledge graphs and machine learning (ML) to manage and support the knowledge work needed in all stages of news production. The result is an emerging type of intelligent information system called the Journalistic Knowledge Platform (JKP). JKPs can be described from a functional, an organisational and a technical perspective. From a functional point of view JKPs automate the process of annotating metadata and support daily workflows like news production [2][3], archiving [4][5], management [6][7] and distribution [8][9][10][11]. JKPs harvest and analyse news and social media information over the net in real time [12], leverage encyclopaedic sources [13], and provide journalists with both meaningful background knowledge [14] and newsworthy information [15]. From an organisational viewpoint: JKPs are deployed in newsrooms to manage the knowledge needed to support journalists with creativity and discovery tasks. These are tailored to the particular digital strategies and editorial lines to improve news broadcast. JKPs also follow media standards to facilitate communication with customers and providers, and are subject to legal regulations such as data privacy. From a technical perspective JKPs implement state-of-the-art AI technologies such as machine learning, natural language processing (NLP) and knowledge representation and reasoning. News-relevant information is represented in knowledge bases which are exploited with data analysis, reasoning and information retrieval techniques to help journalists and readers dive more deeply into information, events and storylines.
2. State of Research on JKPs
1.1. Stakeholders
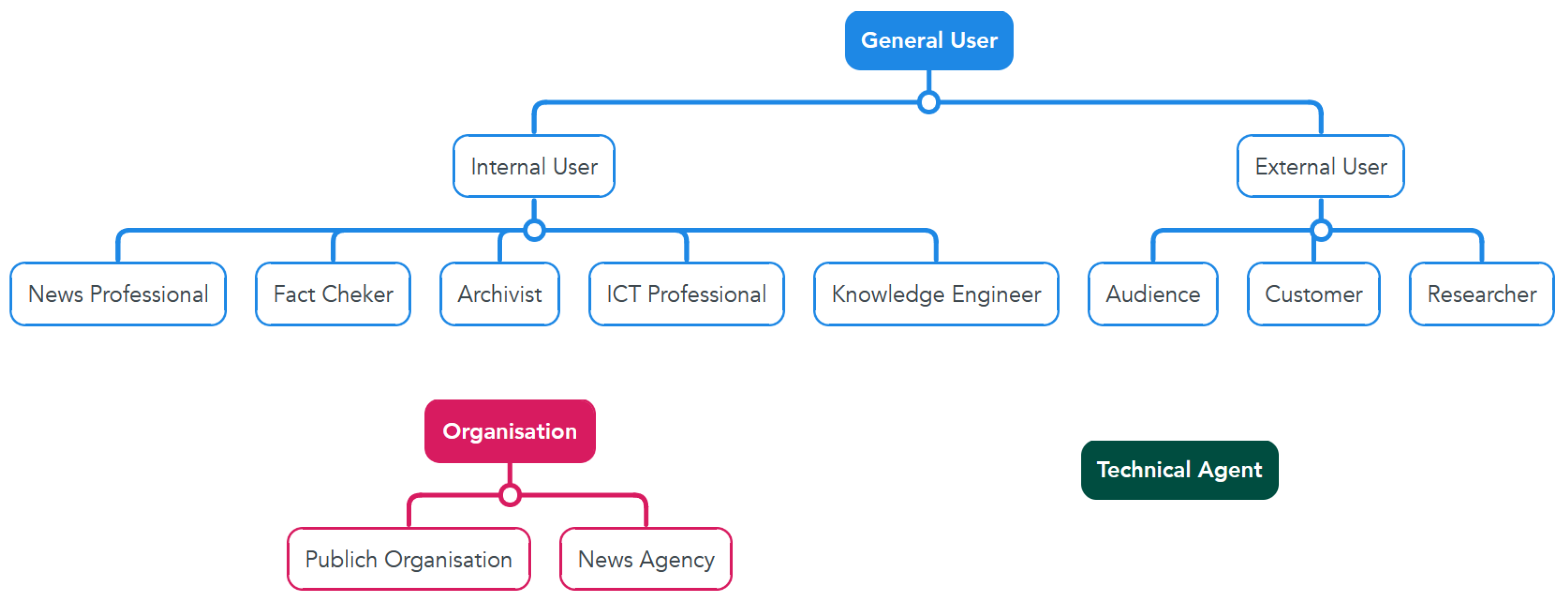
1.2. Information
| Information | Explanation |
|---|---|
| News content | The reported story or event. |
| Textual data | Textual information. |
| Multimedia data | Images, videos and audio information. |
| Data format | The format in which the data is stored or structured. |
| Metadata | Data about or that describe the news content. |
| Linked Open Data (LOD) | Structured and open available data on the Internet (e.g., data from Wikidata and DBpedia) [18] |
| Events | Newsworthy happenings. |
| Information needs | Different information types and categories of interest. |
1.3. Functionalities
| Functionality | Explanation |
|---|---|
| News creation | The process to create a news story. |
| Verification | The process of checking the facts and claims. |
| Source selection | The ability to select the information sources of interest. |
| Monitoring | The ability to continuously distil information from source. |
| Knowledge discovery | Functionalities for exploring relevant information. |
| Trends | The current newsworthy developments. |
| Alert | A notification. |
| Summarisation | Extracting and representing the key information from a larger text or group of text. |
| Clustering | Grouping similar stories or events. |
| Business support | Functionalities to support management workflows. |
| Content management | Functionalities oriented to store, organise and distribute information. |
| Personalisation | Providing information according to the user’s interests. |
1.4. Techniques
| Technique | Explanation |
|---|---|
| Semantic technologies | Set of technologies designed to work with LOD and semantic data [33]. |
| Fact extraction | The techniques used to identify factual claims. |
| Conceptual model | A representations of the world or a part of. |
| Reasoning | The techniques used to infer knowledge. |
| Network analysis | The techniques used to analyse networks of things. |
| Event analysis | The techniques used to analyse events. |
| Natural Language Processing (NLP) | A set of techniques intended to work and process language. |
| AI training | The process of creating and tuning an AI model to perform on a given dataset or scenario. |
1.5. Components
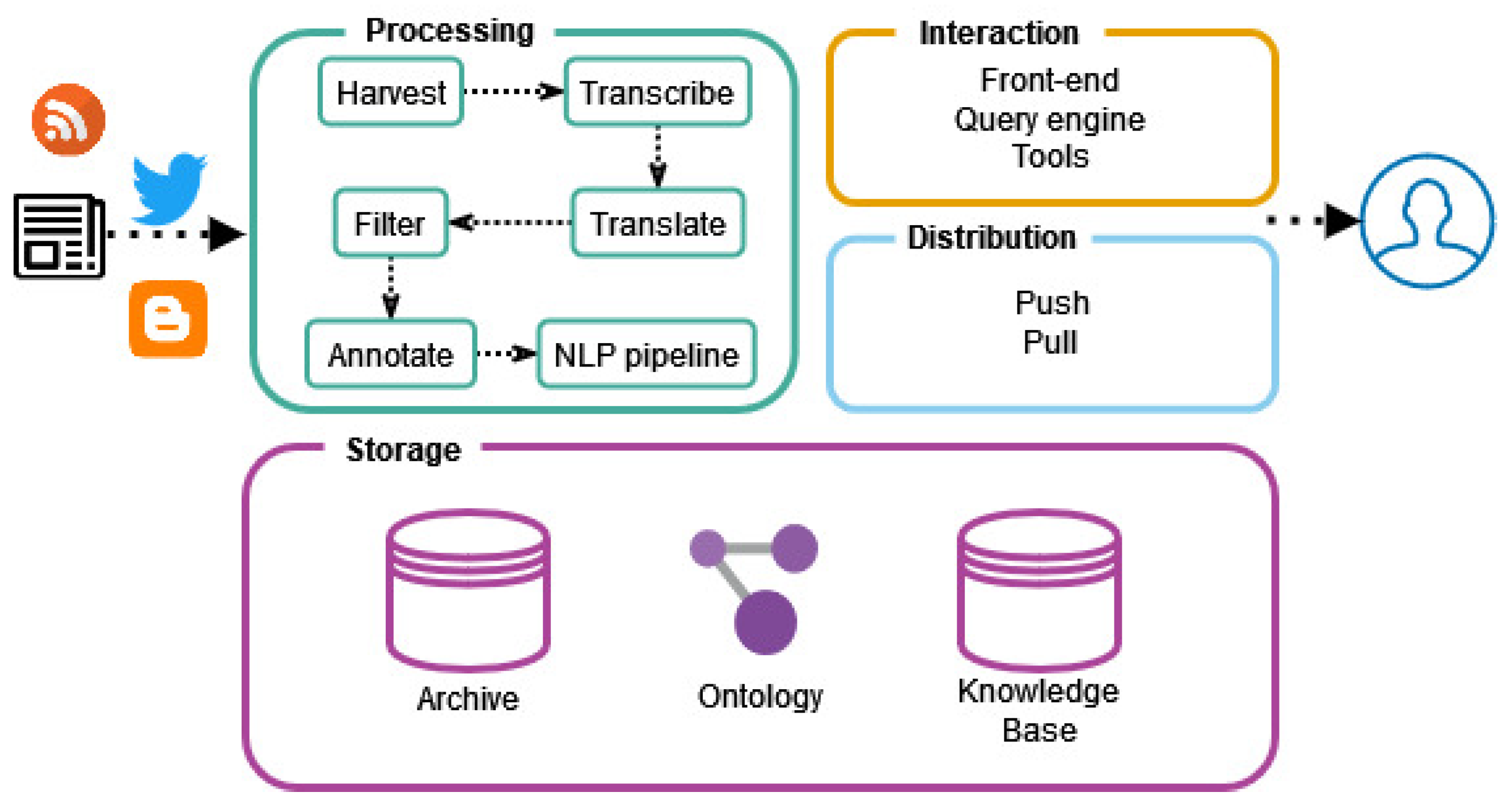
1.6. Concerns
| Aspect | Explanation |
|---|---|
| Customers heterogeneity | The diversity of newsroom customers. |
| Standards | Standards like IPTC topics or RDF. |
| Ownership | Copyrights, authorship and licensing information. |
| Multilingual content | Content produced in various languages. |
| Timeliness | The temporal aspect of news, when they are published and when the stories happen. |
| Human factors | Human-related aspects that affect newsroom and JKPs. |
| Quality | The information and data quality. |
| Big data | Aspects related to the large volume of data, variety of data and velocity in which data is produced. |
| Performance | The ability to provide results with the expected quality and on time. |
| Legacy | Old systems or repositories. |
| Software architecture | The structure and components of a software system [36]. |
| Maintenance | The ability to reuse, fix and update existing systems. |
2. Future Directions for Research on JKPs
2.1. Implications for Research
2.1.1. Stakeholders
2.1.2. Information
2.1.3. Functionalities
2.1.4. Techniques
2.1.5. Components
2.1.6. Concerns
2.2. Implications for Practice
2.2.1. Stakeholders
2.2.2. Information
2.2.3. Functionalities
2.2.4. Techniques
2.2.5. Components
2.2.6. Concerns
References
- Beckett, C. New Powers, New Responsibilities: A Global Survey of Journalism and Artificial Intelligence; Technical Report; Polis, London School of Economics and Political Science: London, UK, 2019.
- Fernández, N.; Blázquez, J.M.; Fisteus, J.A.; Sánchez, L.; Sintek, M.; Bernardi, A.; Fuentes, M.; Marrara, A.; Ben-Asher, Z. NEWS: Bringing Semantic Web Technologies into News Agencies. In Proceedings of the Semantic Web—ISWC 2006, Athens, GA, USA, 5–9 November 2006; pp. 778–791.
- Maiden, N.; Zachos, K.; Brown, A.; Brock, G.; Nyre, L.; Nygård Tonheim, A.; Apsotolou, D.; Evans, J. Making the News: Digital Creativity Support for Journalists. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–11.
- Castells, P.; Perdrix, F.; Pulido, E.; Rico, M.; Benjamins, R.; Contreras, J.; Lorés, J. Neptuno: Semantic Web Technologies for a Digital Newspaper Archive. In Proceedings of the Semantic Web: Research and Applications, ESWS 2004, Heraklion, Crete, Greece, 10–12 May 2004.
- Rospocher, M.; van Erp, M.; Vossen, P.; Fokkens, A.; Aldabe, I.; Rigau, G.; Soroa, A.; Ploeger, T.; Bogaard, T. Building Event-Centric Knowledge Graphs from News. J. Web Semant. 2016, 37–38, 132–151.
- Raimond, Y.; Scott, T.; Oliver, S.; Sinclair, P.; Smethurst, M. Use of Semantic Web technologies on the BBC Web Sites. In Linking Enterprise Data; Springer: New York, NY, USA, 2010.
- Miranda, S.A.; Nogueira, D.; Mendes, A.; Vlachos, A.; Secker, A.; Garrett, R.; Mitchel, J.; Marinho, Z. Automated Fact Checking in the News Room. In Proceedings of the World Wide Web Conference, WWW ’19, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA; pp. 3579–3583.
- Kalfoglou, Y.; Domingue, J.; Motta, E.; Vargas-Vera, M.; Buckingham Shum, S. myPlanet: An ontology driven Web based personalised news service. In Proceedings of the International Joint Conference on Artificial Intelligence, Washington, DC, USA, 4–10 August 2001; Volume 2001, pp. 44–52.
- Java, A.; Finin, T.; Nirenburg, S. SemNews: A Semantic News Framework. In Proceedings of the Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, Boston, MA, USA, 16–20 July 2006.
- Borsje, J.; Levering, L.; Frasincar, F. Hermes: A Semantic Web-Based News Decision Support System. In Proceedings of the 2008 ACM Symposium on Applied Computing, SAC ’08, Fortaleza, Brazil, 16–20 March 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 2415–2420.
- Leban, G.; Fortuna, B.; Brank, J.; Grobelnik, M. Event Registry: Learning about World Events from News. In Proceedings of the 23rd International Conference on World Wide Web, WWW’14 Companion, Seoul, Korea, 7–11 April 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 107–110.
- Liu, X.; Nourbakhsh, A.; Li, Q.; Shah, S.; Martin, R.; Duprey, J. Reuters tracer: Toward automated news production using large scale social media data. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1483–1493.
- Rudnik, C.; Ehrhart, T.; Ferret, O.; Teyssou, D.; Troncy, R.; Tannier, X. Searching News Articles Using an Event Knowledge Graph Leveraged by Wikidata. In Proceedings of the Companion Proceedings of The 2019 World Wide Web Conference, WWW ’19, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1232–1239.
- Ramagem, D.B.; Margerin, B.; Kendall, J. AnnoTerra: Building an integrated earth science resource using semantic Web technologies. IEEE Intell. Syst. 2004, 19, 48–57.
- Al-Moslmi, T.; Gallofré Ocaña, M.; Opdahl, A.L.; Tessem, B. Detecting Newsworthy Events in a Journalistic Platform. In Proceedings of the 3rd European Data and Computational Journalism Conference, Malaga, Spain, 1–2 July 2019; pp. 3–5.
- Fernández, N.; Fuentes, D.; Sánchez, L.; Fisteus, J.A. The NEWS ontology: Design and applications. Expert Syst. Appl. 2010, 37, 8694–8704.
- Liu, X.; Li, Q.; Nourbakhsh, A.; Fang, R.; Thomas, M.; Anderson, K.; Kociuba, R.; Vedder, M.; Pomerville, S.; Wudali, R.; et al. Reuters Tracer: A Large Scale System of Detecting & Verifying Real-Time News Events from Twitter. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, CIKM ’16, Indianapolis, IN, USA, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 207–216.
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2011; pp. 205–227.
- Kobilarov, G.; Scott, T.; Raimond, Y.; Oliver, S.; Sizemore, C.; Smethurst, M.; Bizer, C.; Lee, R. Media Meets Semantic Web – How the BBC Uses DBpedia and Linked Data to Make Connections. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5554.
- Vossen, P.; Agerri, R.; Aldabe, I.; Cybulska, A.; van Erp, M.; Fokkens, A.; Laparra, E.; Minard, A.L.; Aprosio, A.P.; Rigau, G.; et al. NewsReader: Using knowledge resources in a cross-lingual reading machine to generate more knowledge from massive streams of news. Spec. Issue Knowl.-Based Syst. Elsevier 2016, 110, 60–85.
- Kattenberg, M.; Beloki, Z.; Soroa, A.; Artola, X.; Fokkens, A.; Huygen, P.; Verstoep, K. Two architectures for parallel processing for huge amounts of text. In Proceedings of the Language Resources and Evaluation Conference (LREC). European Language Resources Association (ELRA), Portorož, Slovenia, 23–28 May 2016; pp. 4513–4519.
- Germann, U.; Liepins, R.; Barzdins, G.; Gosko, D.; Miranda, S.; Nogueira, D. The SUMMA Platform: A Scalable Infrastructure for Multi-lingual Multi-media Monitoring. In Proceedings of the ACL 2018, System Demonstrations, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 99–104.
- Gutierrez Lopez, M.; Makri, S.; MacFarlane, A.; Porlezza, C.; Cooper, G.; Missaoui, S. Making newsworthy news: The integral role of creativity and verification in the human information behavior that drives news story creation. J. Assoc. Inf. Sci. Technol. 2022; online version of record.
- Deuze, M. On creativity. Journalism 2019, 20, 130–134.
- Berven, A.; Christensen, O.A.; Moldeklev, S.; Opdahl, A.L.; Villanger, K.J. A knowledge-graph platform for newsrooms. Comput. Ind. 2020, 123, 103321.
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986.
- Guo, Z.; Schlichtkrull, M.; Vlachos, A. A Survey on Automated Fact-Checking. Trans. Assoc. Comput. Linguist. 2022, 10, 178–206.
- Diakopoulos, N. Computational News Discovery: Towards Design Considerations for Editorial Orientation Algorithms in Journalism. Digit. J. 2020, 8, 945–967.
- Domingue, J.; Motta, E. PlanetOnto: From news publishing to integrated knowledge management support. IEEE Intell. Syst. Their Appl. 2000, 15, 26–32.
- Germann, U.; Liepins, R.; Gosko, D.; Barzdins, G. Integrating Multiple NLP Technologies into an Open-source Platform for Multilingual Media Monitoring. In Proceedings of the Workshop for NLP Open Source Software (NLP-OSS), Melbourne, Australia, 19–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 47–51.
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679.
- Schouten, K.; Ruijgrok, P.; Borsje, J.; Frasincar, F.; Levering, L.; Hogenboom, F. A semantic web-based approach for personalizing news. In Proceedings of the 2010 ACM Symposium on Applied Computing—SAC ’10, Sierre, Switzerland, 22–26 March 2010; ACM Press: Sierre, Switzerland, 2010; p. 854.
- Shadbolt, N.; Berners-Lee, T.; Hall, W. The Semantic Web Revisited. IEEE Intell. Syst. 2006, 21, 96–101.
- Paikens, P.; Barzdins, G.; Mendes, A.; Ferreira, D.C.; Broscheit, S.; Almeida, M.S.; Miranda, S.; Nogueira, D.; Balage, P.; Martins, A.F. SUMMA at TAC Knowledge Base Population Task 2016. In Proceedings of the Ninth Text Analysis Conference (TAC), Gaithersburg, MA, USA, 14–15 November 2016.
- Al-Moslmi, T.; Gallofré Ocaña, M. Lifting News into a Journalistic Knowledge Platform. In Proceedings of the CIKM 2020 Workshops, Galway, Ireland, 19–23 October 2020.
- Garlan, D. Software Architecture. In Encyclopedia of Software Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2008.
- Gallofré Ocaña, M.; Al-Moslmi, T.; Opdahl, A.L. Data Privacy in Journalistic Knowledge Platforms. In Proceedings of the CIKM 2020 Workshops, Galway, Ireland, 19–23 October 2020.
- Neuberger, C.; Nuernbergk, C.; Langenohl, S. Journalism as Multichannel Communication. J. Stud. 2019, 20, 1260–1280.
- Zhang, X.; Li, W. From Social Media with News: Journalists’ Social Media Use for Sourcing and Verification. J. Pract. 2020, 14, 1193–1210.
- Stray, J. Making Artificial Intelligence Work for Investigative Journalism. Digit. J. 2019, 7, 1076–1097.
- Broussard, M.; Diakopoulos, N.; Guzman, A.L.; Abebe, R.; Dupagne, M.; Chuan, C.H. Artificial Intelligence and Journalism. J. Mass Commun. Q. 2019, 96, 673–695.
- Graefe, A.; Bohlken, N. Automated Journalism: A Meta-Analysis of Readers’ Perceptions of Human-Written in Comparison to Automated News. Media Commun. 2020, 8, 50–59.
- Tandoc, E.C., Jr.; Yao, L.J.; Wu, S. Man vs. Machine? The Impact of Algorithm Authorship on News Credibility. Digit. J. 2020, 8, 548–562.
- Swart, J. Experiencing Algorithms: How Young People Understand, Feel About, and Engage with Algorithmic News Selection on Social Media. Soc. Media Soc. 2021, 7, 20563051211008828.
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394.
- Mogadala, A.; Kalimuthu, M.; Klakow, D. Trends in integration of vision and language research: A survey of tasks, datasets, and methods. J. Artif. Intell. Res. 2021, 71, 1183–1317.
- Chen, S.; Aguilar, G.; Neves, L.; Solorio, T. Can images help recognize entities? A study of the role of images for Multimodal NER. In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), Online, 11 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 87–96.
- Shon, S.; Pasad, A.; Wu, F.; Brusco, P.; Artzi, Y.; Livescu, K.; Han, K.J. SLUE: New Benchmark Tasks For Spoken Language Understanding Evaluation on Natural Speech. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7927–7931.
- van Erp, M.; Ilievski, F.; Rospocher, M.; Vossen, P. Missing Mr. Brown and buying an Abraham Lincoln—Dark entities and DBpedia. In Proceedings of the Third NLP & DBpedia Workshop, Bethlehem, PA, USA, 11 October 2015; pp. 81–86.
- Al-Moslmi, T.; Gallofré Ocaña, M.; Opdahl, A.L.; Veres, C. Named entity extraction for knowledge graphs: A literature overview. IEEE Access 2020, 8, 32862–32881.
- Luo, B.; Lau, R.Y.; Li, C.; Si, Y.W. A critical review of state-of-the-art chatbot designs and applications. WIREs Data Min. Knowl. Discov. 2022, 12, e1434.
- Miroshnichenko, A. AI to Bypass Creativity. Will Robots Replace Journalists? (The Answer Is “Yes”). Information 2018, 9, 183.
- Alhussain, A.I.; Azmi, A.M. Automatic Story Generation: A Survey of Approaches. ACM Comput. Surv. 2021, 54, 1–38.
- Zhu, S.; Sun, G.; Jiang, Q.; Zha, M.; Liang, R. A survey on automatic infographics and visualization recommendations. Vis. Inform. 2020, 4, 24–40.
- Lampropoulos, G.; Keramopoulos, E.; Diamantaras, K. Enhancing the functionality of augmented reality using deep learning, semantic web and knowledge graphs: A review. Vis. Inform. 2020, 4, 32–42.
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53, 1–40.
- Pasquini, C.; Amerini, I.; Boato, G. Media forensics on social media platforms: A survey. EURASIP J. Inf. Secur. 2021, 2021, 1–19.
- Bhagtani, K.; Yadav, A.K.S.; Bartusiak, E.R.; Xiang, Z.; Shao, R.; Baireddy, S.; Delp, E.J. An Overview of Recent Work in Media Forensics: Methods and Threats. arXiv 2022, arXiv:2204.12067.
- Hitzler, P.; Bianchi, F.; Ebrahimi, M.; Sarker, M.K. Neural-symbolic integration and the Semantic Web. Semant. Web 2020, 11, 3–11.
- Hitzler, P.; Krotzsch, M.; Rudolph, S. Foundations of Semantic Web Technologies; CRC Press: Boca Raton, FL, USA, 2010.
- Thomson, T.; Angus, D.; Dootson, P.; Hurcombe, E.; Smith, A. Visual Mis/disinformation in Journalism and Public Communications: Current Verification Practices, Challenges, and Future Opportunities. J. Pract. 2020, 16, 1–25.
- Salzmann, A.; Guribye, F.; Gynnild, A. “We in the Mojo Community”—Exploring a Global Network of Mobile Journalists. J. Pract. 2021, 15, 620–637.
- Shin, D. Why Does Explainability Matter in News Analytic Systems? Proposing Explainable Analytic Journalism. J. Stud. 2021, 22, 1047–1065.
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy Artificial Intelligence: A Review. ACM Comput. Surv. 2022, 55, 1–38.
- Lopez, M.G.; Porlezza, C.; Cooper, G.; Makri, S.; MacFarlane, A.; Missaoui, S. A Question of Design: Strategies for Embedding AI-Driven Tools into Journalistic Work Routines. Digit. J. 2022, 10, 1–20.
- Motta, E.; Daga, E.; Opdahl, A.L.; Tessem, B. Analysis and Design of Computational News Angles. IEEE Access 2020, 8, 120613–120626.
- Yan, Y.; Sun, H.; Liu, J. A Review and Outlook for Relation Extraction. In Proceedings of the 5th International Conference on Computer Science and Application Engineering, CSAE 2021, Sanya, China, 19–21 October 2021; Association for Computing Machinery: New York, NY, USA, 2021.
- van Erp, M.; Groth, P. Towards Entity Spaces. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Marseille, France, 2020; pp. 2129–2137.
- Xiao, G.; Ding, L.; Cogrel, B.; Calvanese, D. Virtual Knowledge Graphs: An Overview of Systems and Use Cases. Data Intell. 2019, 1, 201–223.
- Gallofré Ocaña, M.; Opdahl, A.L. Developing a Software Reference Architecture forJournalistic Knowledge Platforms. In Proceedings of the ECSA2021 Companion Volume, Växjö, Sweden, 13–17 September 2021.
- Martínez-Fernández, S.; Ayala, C.P.; Franch, X.; Marques, H.M. Benefits and drawbacks of software reference architectures: A case study. Inf. Softw. Technol. 2017, 88, 37–52.