Maximizing device usage time is an important goal and, focusing on this objective, researchers investigate an adaptive ‘big–little’ neural network system which consists of a big network and multiple little networks to achieve energy-saving inference by limiting the number of big network executions without degrading accuracy. Researchers call this organization ‘big–little’ since it draws inspiration from the ‘big–little’ technology popularized by ARM that combines complex and light processors in a single SoC. Big network has better accuracy but with a longer inference time, while the little networks have a faster inference speed. Most of the time, the big network remains in sleeping mode and it is only activated when the little network determines that it cannot handle the work at the required level of confidence.
Here, researchers focus on establishing and deploying the complete adaptive neural network system on the edge device. researchers investigate how to manage the primary and secondary networks to have a faster, more accurate, and more energy-efficient performance using a human activity recognition (HAR) application as a popular example of an edge application.
2. Background and Related Work
In this section, researchers present an overview of current state-of-the-art hardware with power profiles in the order of 1 watt or less for edge AI and then algorithmic techniques and frameworks optimized to target this hardware.
2.1. Hardware for Low-Power Edge AI
The high demand for AI applications at the edge has resulted in a significant increase in hardware optimized for low-power levels. For example, Google has delivered a light version of the Tensor Processing Unit (TPU) called Edge TPU which is able to provide power-efficient inference at 2 trillion MAC operations per second per watt (2TMAC/s/W)
[3]. This state-of-the-art device is able to execute mobile version models such as MobileNet V2 at almost 400 FPS. The Cloud TPU focuses on training complex models, while the Edge TPU is designed to perform inference in low-power systems. Targeting significantly lower power than the Edge TPU, Ambiq released the Apollo family of near-threshold processors based on the 32-bit ARM Cortex-M4F processor. These devices can reach much lower energy usage measured at only 6 µA/MHz at 3.3 V under the working mode, and 1 µA/MHz at 3.3 V under sleep mode. The Apollo3 device present in the SparkFun board has 1 MB of flash memory and 384 KB of low-leakage RAM
[4]. Similarly, Eta Compute has targeted energy-efficient endpoint AI solutions with the ECM3532 processor. This device is based on an ARM Cortex-M3 32-bit CPU and a separate CoolFlux DSP to speed up machine learning operations in an energy-efficient manner. The ECM3532 available in the AI vision board consumes less than 5 µA/MHz in normal working mode and 1 µA/MHz in sleep mode. According to Eta Compute, its implementation of self-timed continuous voltage and frequency scaling technology (CVFS) achieves a power profile of just 1 mW
[5][6]. A characteristic of these near-threshold devices is that voltage scaling is applied to the core but it is not applied to the device’s SRAM/flash due to the limited margining possible in memory cells.
Both Apollo3 and ECM3532 are based on the popular ARM architecture but, lately, the open-source instruction set architecture RISC-V has also received significant attention in this field. For example, GAP8 developed by GreenWaves Technologies features an 8-core compute cluster of RISC-V processors and an additional CNN accelerator
[7]. The compute cluster is coupled with an additional ultra-low power MCU with 30 µW state-retentive sleep power for control and communication functions. For CNN inference (90 MHz, 1.0 V), GAP8 delivers an energy efficiency of 600 GMAC/s/W and a worst-case power envelope of 75 mW
[7].
Other examples of companies exploring the near-threshold regime include Minima who has been involved in designs demonstrating achievable power savings
[8]. Minima offers ultra-wide dynamic voltage and frequency scaling (DVFS) which is able to scale frequency and/or operating voltage based on the workload. This approach, combined with the dynamic margining approach from both Minima and ARM, is able to save energy by up to
15× to
20× [9]. The interest for adaptive voltage scaling hardware has resulted in a €100 m European project led by STMicroelectronics to develop the next generation of edge AI microcontrollers and software using low-power FD-SOI and phase change technology. This project aims to deliver the chipset and solutions for the automotive and industrial markets with a very high computing capacity of 10 TOPS per watt, which is significantly more powerful than existing microcontrollers
[10].
2.2. Algorithmic Techniques for Low-Power Edge AI
Over the years, different algorithmic approaches have appeared to optimize inference on edge devices with a focus on techniques such as quantization, pruning, heterogeneous models and early termination. The deep quantization of network weights and activations is a well-known approach to optimize network models for edge deployments
[11][12]. Examples include
[13], which uses extremely low precision (e.g., 1-bit or 2-bits) of weights and activations achieving 51% top-1 accuracy and seven times the speedup in AlexNet
[13]. The authors of
[14] demonstrate a binarized neural network (BNN) where both weights and activations are binarized. During the forward pass, a BNN drastically reduces memory accesses and replaces most arithmetic operations with bit-wise operations. Ref.
[14] has proven that, by using their binary matrix multiplication kernel, the results achieve 32 times the compression ratio and improves performance by seven times with MNIST, CIFAR-10 and SVHN data sets. However, substantial accuracy loss (up to 28.7%) has been observed by
[15]. The research in
[15] has addressed this drawback by deploying a full-precision norm layer before each Conv layer in XNOR-Net. XNOR-Net applies binary values to both inputs and convolutional layer weights and it is capable of reducing the computation workload by approximately 58 times, with 10% accuracy loss in ImageNet
[15]. Overall, these networks can free edge devices from the heavy workload caused by computations using integer numbers, but the loss of accuracy needs to be properly managed. This reduction in accuracy loss has been improved in CoopNet
[16]. Similar to the concept of multi-precision CNN in
[17], CoopNet
[16] applies two convolutional models: a binary net BNN with faster inference speed and an integer net INT8 with relatively high accuracy to balance the model’s efficiency and accuracy. On low-power Cortex-M MCUs with limited RAM (≤1 MB), Ref.
[16] achieved around three times the compression ratio and 60% of the speed-up while maintaining an accuracy level higher than the CIFAR-10, GSC and FER13 datasets. In contrast to CoopNet which applies the same network structures for primary and secondary networks, researchers apply a much simpler structure for secondary networks in which each of them is trained to identify one category in the HAR task. This optimization results in a configuration that can achieve around 80% speed-up and energy-saving with a similar accuracy level across all the evaluated MCU platforms. Based on XNOR-Net, Ref.
[18] constructed a pruned–permuted–packed network that combines binarization with sparsity to push model size reduction to very low limits. On the Nucleo platforms and Raspberry Pi, 3PXNet achieves a reduction in the model size by up to
38× and an improvement in runtime and energy of
25× compared to already compact conventional binarized implementations with a reduction in accuracy of less than 3%. TF-Net is an alternative method that chooses ternary weights and four-bit inputs for DNN models. Ref.
[19] provides this configuration to achieve the optimal balance between model accuracy, computation performance, and energy efficiency on MCUs. They also address the issue that ternary weights and four-bit inputs cannot be directly accessed due to memory being byte-addressable by unpacking these values from the bitstreams before computation. On the STM32 Nucleo-F411RE MCU with an ARM Cortex-M4, Ref.
[19] achieved improvements in computation performance and energy efficiency of
1.83× and
2.28×, respectively. Thus, 3PXNet/TF-Net can be considered orthogonal to researchers' ‘big–little’ research since they could be used as alternatives to the 8-bit integer models considered in this research. A related architecture to researchers' approach called BranchyNet with early exiting was proposed in
[20]. This architecture has multiple exits to reduce layer-by-layer weight computation and I/O costs, leading to fast inference speed and energy saving. However, due to the existence of multiple branches, it suffers from a huge number of parameters, which would significantly increase the memory requirements in edge devices.
The configuration of primary and secondary neural networks has been proposed for accelerating the inference process on edge devices in recent years. Refs.
[17][21] constructed ‘big’ and ‘little’ networks with the same input and output data structure. The ‘big’ network is triggered by their score metric generated from the ‘little’ network. A similar configuration has also been proposed by
[22], but their ‘big’ and ‘little’ networks are trained independently. ‘Big’ and ‘little’ networks do not share the same input and output data structure. Ref.
[22] proposed a heterogeneous setup deploying a ‘big’ network on state-of-the-art edge neural accelerators such as NCS2, with a ‘little’ network on near-threshold processors such as ECM3531 and Apollo3. Ref.
[22] has successfully achieved 93% accuracy and low energy consumption of around 4 J on human activity classification tasks by switching this heterogeneous system between ‘big’ and ‘little’ networks. Ref.
[22] considers heterogeneous hardware, whereas researchers' approach uses the ‘big–little’ concept but focuses on deploying all the models on a single MCU device. In contrast to how
[22] deployed ‘big’ and ‘little’ models on the NCS2 hardware accelerator and near-threshold processors separately, researchers deploy both neural network models on near-threshold MCU for activity classification tasks. A switching algorithm is set up to switch between ‘big’ and ‘little’ network models to achieve much lower energy costs but maintain a similar accuracy level. A related work
[23] has performed activity recognition tasks with excellent accuracy and performance by using both convolutional and long short-term memory (LSTM) layers. Due to the flash memory size of MCU, researchers decided not to use the LSTM layers which have millions of parameters as shown in
[23]. The proposed adaptive system is suitable for real-world tasks such as human activity classification in which activities do not change at very high speeds. A person keeps performing one action for a period of time, typically in the order of tens of seconds
[24], which means that to maintain the system at full capacity (using the primary ‘big’ network to perform the inference) is unnecessary. Due to the additional inference time and computation consumed by the primary network, the fewer the number of times the primary network gets invoked, the faster the inference process will be and the lower the energy requirements
[16][17][21][22].
2.3. Frameworks for Low-Power Edge AI
Over the last few years, a number of frameworks have appeared to ease the deployment of neural network models on edge devices with limited resources. In
[25], a framework is provided called FANN-on-MCU specifically for the fast deployment of multi-layer perceptrons (MLPs) on low-power MCUs. This framework supports not only the very popular ARM Cortex-M series MCUs, but also the RISC-V parallel ultra-low power (PULP) processors. The results in
[25] show that the PULP-based ‘Mr.Wolf’ SoC can reach up to
7.1× the speedup with respect to a single core implementation and
13.5× the speedup over the ARM Cortex-M4. Moreover, by using FANN-on-MCU, a relatively big neural network with 103,800 MAC operations can be executed within 17.6 ms with an energy consumption of 183 µJ on a Nordic nRF52832 MCU with one ARM Cortex-M4. The same neural network applied on ‘Mr.Wolf’ with eight RISC-V-based RI5CY cores takes less than 1ms to consume around 50 µJ
[25]. Similar to FANN-on-MCU, Ref.
[26] delivers a fast deployment on the MCU framework called the neural network on microcontroller (
NNoM) which supports more complex model topologies such as ResNet and DenseNet from Keras. A user-friendly API and high-performance backend selections have been built for embedded developers to deploy Keras models on low-power MCU devices. There are also deployment frameworks developed by commercial companies targeting low-power edge devices. For example, Google focuses on low-power edge AI with the popular
TensorFlow Lite framework
[27]. Coupled with the model training framework
TensorFlow, Google can provide a single solution from neural network model training to model deployment on edge devices.
STM32Cube.AI from STMicroelectronics
[28] is also an AI deployment framework but it is only designed around the STM family devices such as STM32 Nucleo-L4R5ZI and STM32 Nucleo-F411RE. Eta Compute has created the
TENSAIFlow deployment framework to provide performance and efficiency optimizations for Eta-series MCU products such as ECM3531 and ECM3532
[29]. In researchers' methodology, the lack of support for certain devices in some frameworks means that researchers have combined tools from different vendors. Researchers have applied frameworks from
[26][27][29] for model deployments on MCUs such as ECM3532 and STM32L4.
3. Low-Power Microcontroller Evaluation
Four commercially available microcontroller devices designed for energy-efficient applications from STMicroelectronics, Ambiq and Eta Compute are considered in this comparison.
Table 1 shows the technical details of these four MCUs. Three of them (STM32L4R5ZI, Apollo2 Blue and SparkFun Edge (Apollo3 Blue)) are based on the Cortex-M4 microarchitecture with floating-point units (FPU)
[4][30][31], while the ECM3532 is based on the Cortex-M3 microarchitecture with a ‘CoolFlux’ 16-bit DSP
[5]. The 32-bit ARM Cortex-M3 and M4 are comparable microarchitectures both having a three-stage pipeline and implementing the Thumb-2 instruction set with some differences in the number of instructions available. For example, additional 16/32-bit MAC instructions and single-precision FPU are only available on the Cortex M4.
The STM32 Nucleo-144 development board with the STM32L4R5ZI MCU is used as a comparison point; the main difference between this STM device and the other three is the power optimization method. The core supply voltage of 1 V for the STM device is significantly higher than the core voltage for the near-threshold devices of Ambiq and Eta Compute at only around 0.5 V. Theoretically, the sub-threshold core supply voltage can be as low as 0.3 V which should be more power-efficient. However, at 0.3 V, the transistor switching time will be longer, which leads to a higher leakage current. The leakage can exceed 50% of the total power consumption for a threshold voltage level of around 0.2 V
[32]. Therefore, in practice, choosing near-threshold voltage points instead of sub-threshold voltage points has been shown to be a more energy-efficient solution
[32]. In order to optimize the energy usage based on the task requirements, STM32L4 uses standard dynamic voltage and frequency scaling (DVFS) with predefined pair sets of voltage and frequency, while the devices from Ambiq and Eta Compute apply adaptive voltage scaling (AVS) which is able to determine the voltage at a given frequency to handle the tasks at run-time using a feedback loop
[33].
Comparing the datasheets, the STM32L4 has the highest clock frequency which results in an advantage in processing speed. Ambiq and Eta Compute’s near-threshold devices only require about half of the core supply voltage of STM32L4. All considered processors are equipped with limited flash sizes from 0.5 MB to 1 MB and a size of around 300 KB SRAM. That means that the neural network model deployed must be small enough to fit within the limited memory size. Therefore, researchers use the
TensorFlow framework and
TensorFlow Lite converter to create a simple pre-trained CNN model designed for human activity recognition (HAR) from UCI
[34] (as shown in
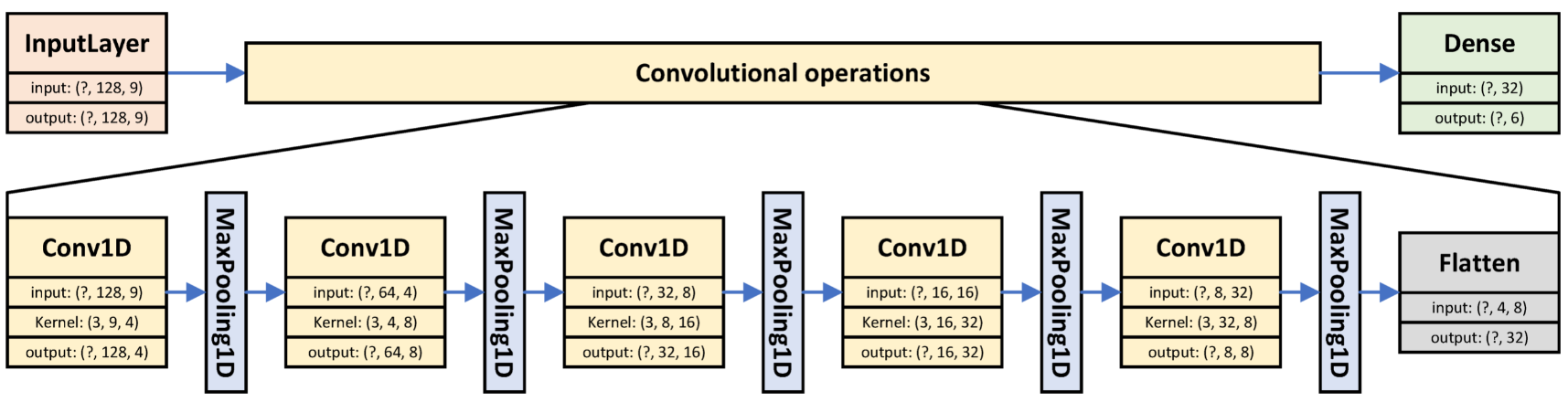
Figure 1) to perform the initial energy evaluation of the four MCU devices.
Figure 1. Convolutional neural network for the initial performance and energy evaluation of the MCU.
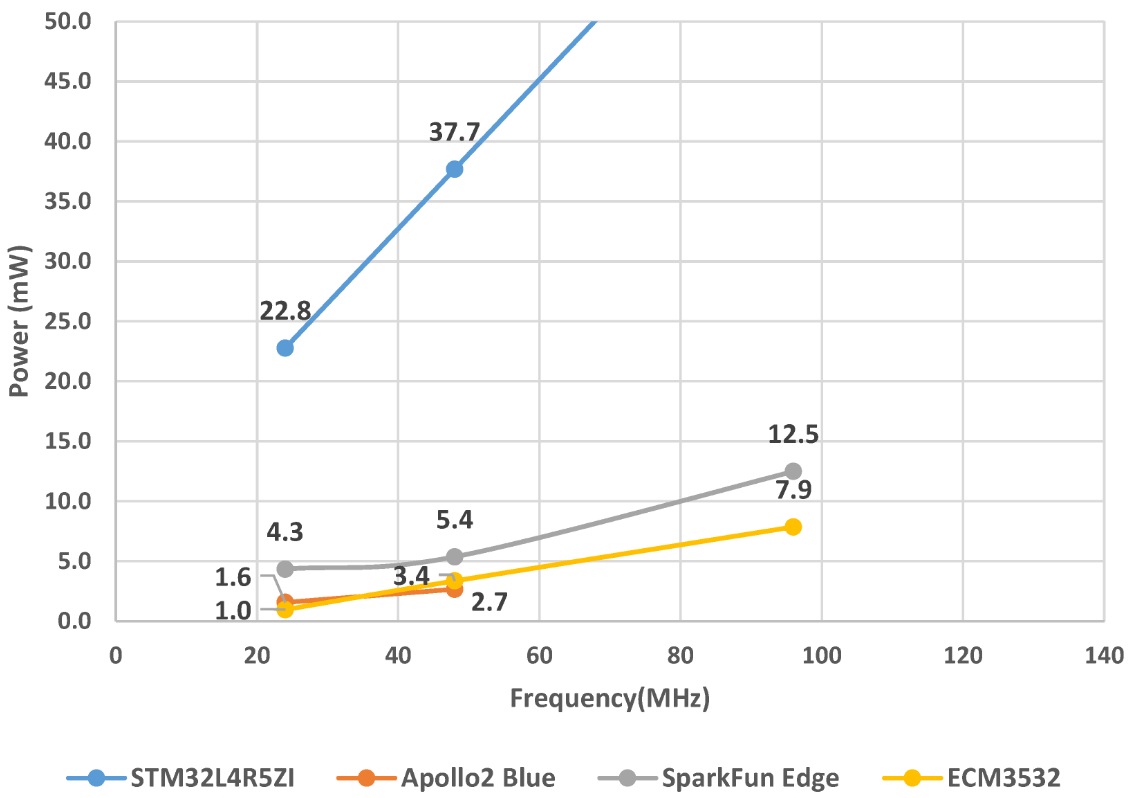
The energy board X-NUCLEO-LPM01A from STMicroelectronics is used to evaluate the performance and energy consumption measuring the current used by the target board under a given supply voltage of 3.3 V (lower core voltages are regulated internally in the device). The power consumption of the four tested boards is shown in Figure 2. STM32L4 operates at a much higher power level which is around six times that of the near-threshold processors. The near-threshold processors Apollo2, Apollo3 and ECM offer significantly lower power, consuming less than 5 mW at the normal frequency of 48MHz and around 10 mW in the burst mode of 96 MHz. The reason why SparkFun Edge (Apollo3) consumes more power than Apollo2 is that the Apollo3 core is highly integrated into the SparkFun Edge board with peripheral sensors and ports which cannot be disabled during the power evaluation. Therefore, the peripheral devices on SparkFun Edge (Apollo3) are responsible for a component of the power consumption, which leads to a higher power than Apollo2 at each frequency level. Apollo2 and ECM3532 share a similar level of power consumption at 24 and 48 MHz. Apollo2 does not support running at a frequency higher than 48 MHz; therefore, there is no value for Apollo2 at the 96 MHz frequency point.
Figure 2. MCU initial evaluation in terms of power consumption.
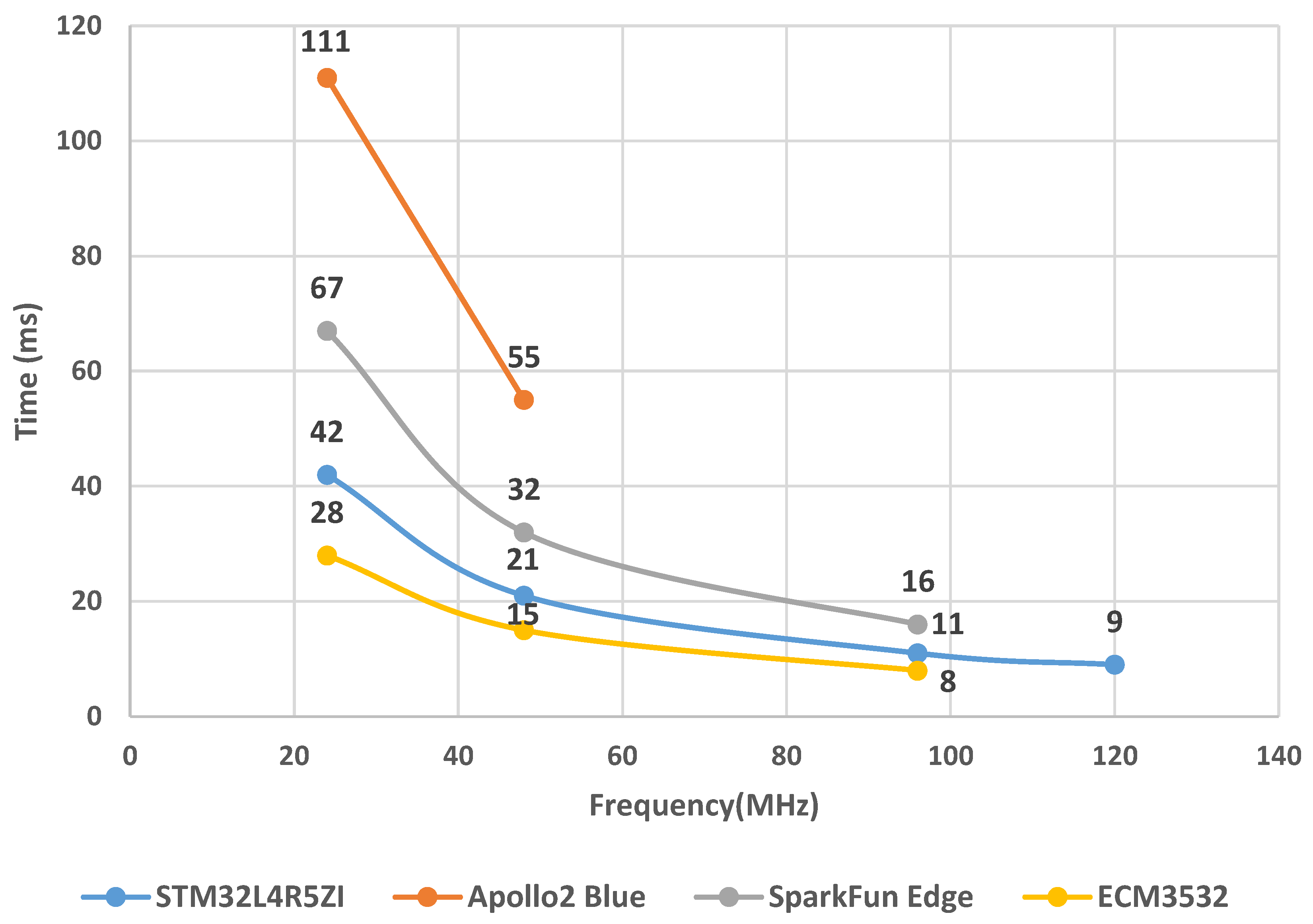
Figure 3 shows the execution time of the four tested processors for one inference of the pre-trained CNN model in Figure 1. Apollo2 is the slowest one and finishes inference using the longest amount of time at above 100 ms at 24 MHz frequency and around 50 ms at 48 MHz. The SparkFun Edge board (Apollo3) reduces the execution time by approximately 40% compared to Apollo2. It can even drop below 20 ms when operating in burst mode (96 MHz). STM32L4 is the second fastest among all devices due to its higher core supply voltage in Table 1 which enables faster transistor switching and processing speed. ECM3532 has the lowest execution times which are 28 ms at 24 MHz, 15 ms at 48 MHz and 8 ms at 96 MHz. The TENSAIFlow compiler is responsible for significant optimization in the ECM3532 device.
Figure 3. MCU initial evaluation in terms of time cost.
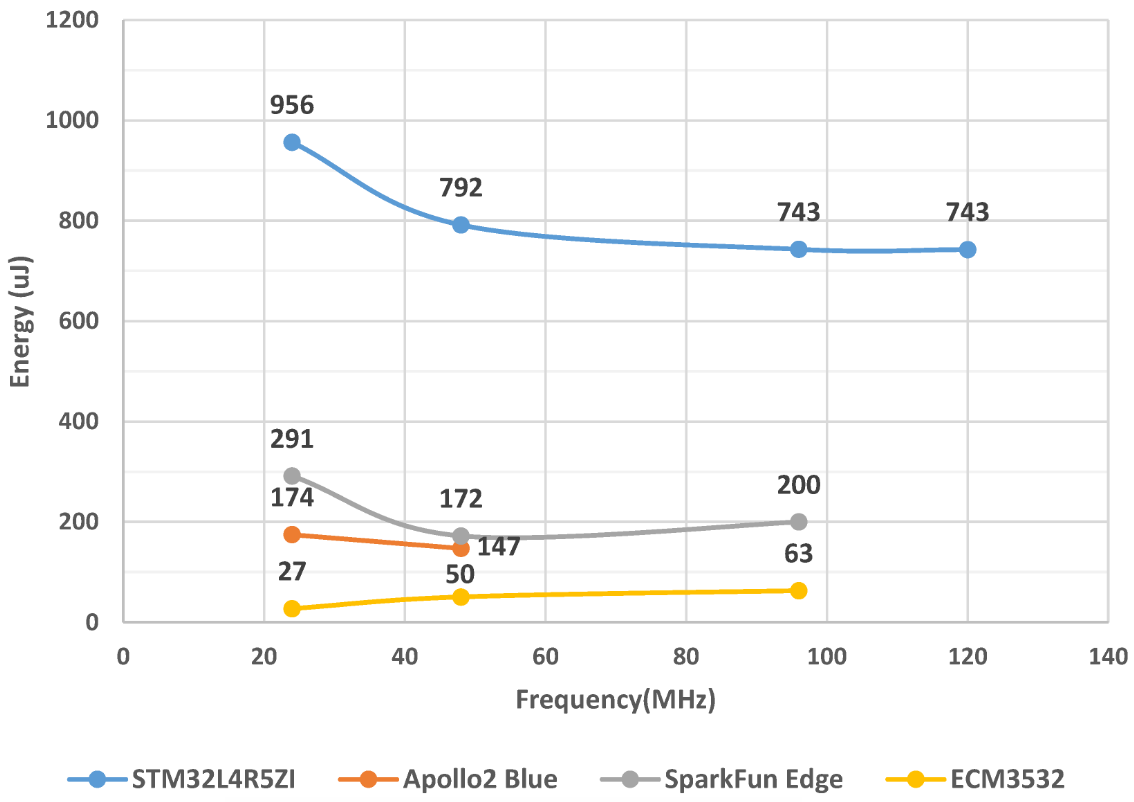
Figure 4 indicates the energy consumption values observed using the X-NUCLEO-LPM01A energy measurement board. Since the power consumption of the standard MCU STM32L4 in Figure 2 is six times higher compared to the near-threshold MCUs and there is no obvious advantage in processing speed at the same frequency, STM32L4 is the worst device in terms of energy consumption for all operating frequencies from 24 to 96 MHz. SparkFun Edge (Apollo3) is slightly higher than Apollo2 at 24 and 48 MHz due to the energy consumed by the peripheral equipment on board. ECM3532 achieves the minimum energy consumption at normal frequency points (24 and 48 MHz) in the energy test because it has better results in both power and time evaluations. However, when operating in the 96 MHz burst mode, ECM3532 requires more power to obtain a higher processing speed, resulting in a slight increase in energy consumption, and the same situation can be seen for the SparkFun Edge board.
Figure 4. MCU initial evaluation in terms of energy consumption.
Overall, compared to the STM32L4 reference point all three near-threshold MCUs have a significant advantage in power and energy consumption which is around 80% to 85% lower. Although the near-threshold MCUs are comparable with the standard MCU STM32L4 in terms of inference time, their lower core voltage supplies (Table 1) result in lower power (Figure 2) at the same frequency level. Therefore, in researchers' model inference evaluation, the near-threshold MCU devices can achieve better results in energy consumption compared to STM32L4 at 24, 48 and 96 MHz. Thanks to the additional model optimization obtained with the TENSAIFlow compiler provided by Eta Compute, ECM3532 offers a good balance between performance and energy efficiency to reach a lower execution time, enabling the lowest energy consumption for model inference from 24 to 96 MHz. In contrast, Apollo2, with a relatively slow processing speed, needs more time for model inference, which leads to higher values in energy consumption at 24 and 48 MHz. Due to the energy consumed by the inaccessible peripheral equipment on SparkFun Edge (Apollo3), this device consumes higher energy than Apollo2 (Figure 4).
 +1 credit
+1 credit