+1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Goh Kian Mau | + 3550 word(s) | 3550 | 2022-02-08 03:38:17 | | | |
| 2 | Dean Liu | -3 word(s) | 3547 | 2022-03-04 03:09:38 | | |
Video Upload Options
Starch and pullulan degrading enzymes are essential industrial biocatalysts. Pullulan-degrading enzymes are grouped into pullulanases (types I and type II) and pullulan hydrolase (types I, II and III).
1. Classification and Action of Pullulan-Degrading Enzymes
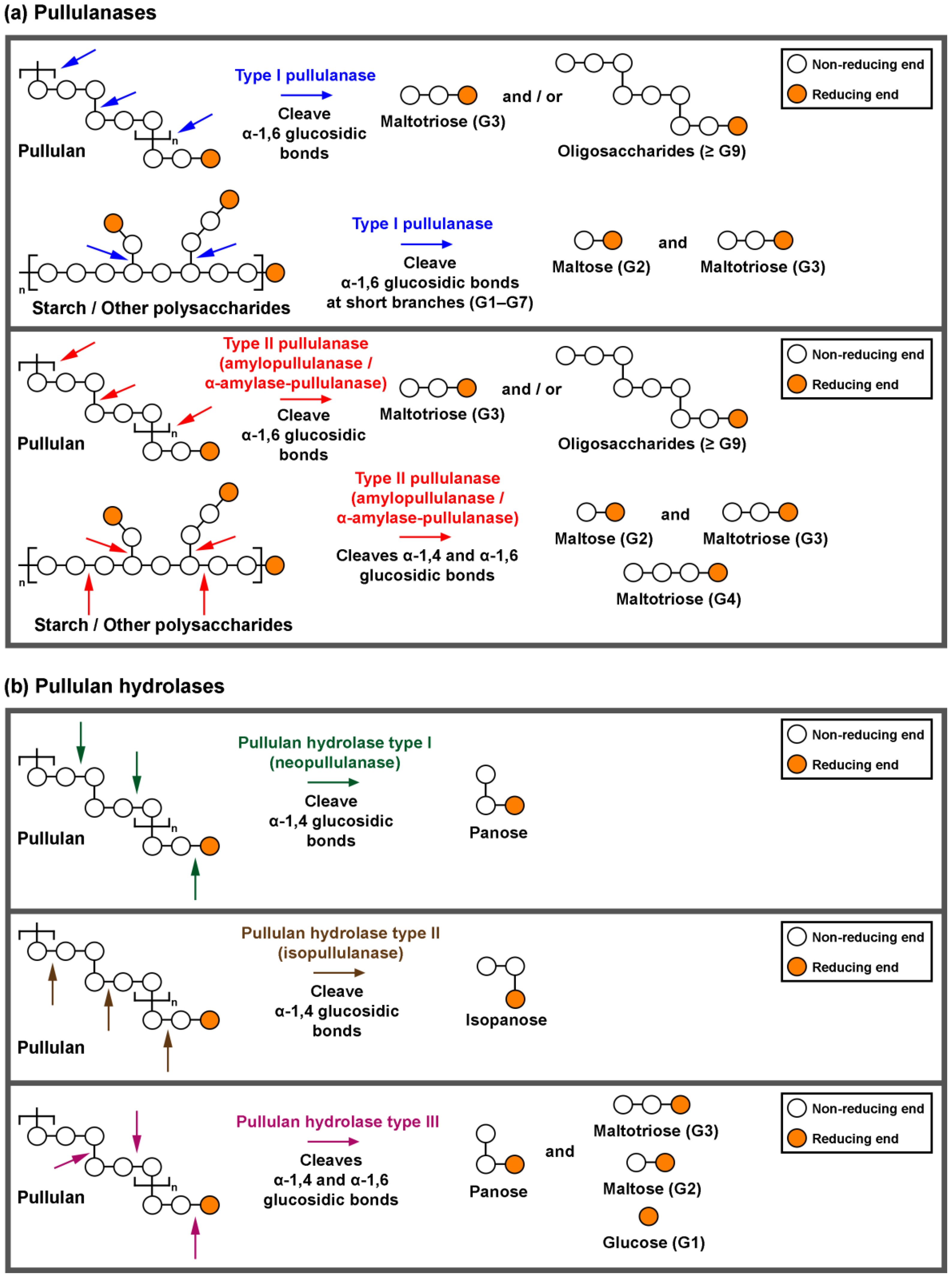
2. Domains, Structures and Properties of Pullulan-Degrading Enzymes

3. Single Immobilisation of Pullulan-Degrading Enzyme
4. Co-Immobilisation of Pullulan-Degrading Enzymes
- (i) free enzymes mixture (PulASK+TASKA)
- (ii) individual immobilised enzymes mixture (HFA403/M–PulASK+ HFA403/M–TASKA)
- (iii) co-immobilised enzymes (PulASK–HFA403/M–TASKA).
5. Protein Engineering for Improving the Performance of Pullulan-Degrading Enzymes
More predictors apply protein structural datasets and evolutional information to train machine learning. A few years ago, a research team noticed several problems with ProTherm, and they later cleaned the database before developing the PON-tstab predictor [148]. To overcome other limitations of ProTherm, the developers for DDGun and DDGun3D used a method that combines anti-symmetric features for predicting the ΔΔG upon variation, and claimed that this untrained and straightforward method has excellent performance. So far, only a few predictors address the anti-symmetric issue, and examples of these programs include PROTS-RF, INPS, SDM, ProTstab and a few others [149]. Predictor DeepDDG, a neural network approach, was trained using ProTherm, and manually curated literature data. The developer suggested that DeepDDG outperformed the other eleven commonly used predictors [146]. The identical research group that created PON-tstab later proposed a new platform, ProTstab, which used a >3500 proteolysis and mass spectrometry (LiP-MS) dataset to train the gradient-boosting based machine learning platform. Different algorithms may suggest contradictory suggestions, and it is time-consuming to try one predictor at a time. One may consider iStable 2.0, an integrated platform consisting of eleven structure- and sequence-based tools [147]. Readers can refer to the excellent review that compares the limitations and challenges of each predictor from the angle of future applications in precision medicine [149]. researchers observed that not many pullulanase protein engineers use the tools mentioned above; therefore, keywords stated in this subsection will not appear in bibliometric records (Figure 1c).
6. Influence of Next-Generation Metagenome Sequencing on Novel Pullulan-Degrading Enzymes Discovery