Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Daniel Kostrzewa | + 1167 word(s) | 1167 | 2022-01-18 09:55:47 | | | |
| 2 | Catherine Yang | -8 word(s) | 1159 | 2022-01-25 02:59:23 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Kostrzewa, D. Singing Voice Detection. Encyclopedia. Available online: https://encyclopedia.pub/entry/18717 (accessed on 23 July 2026).
Kostrzewa D. Singing Voice Detection. Encyclopedia. Available at: https://encyclopedia.pub/entry/18717. Accessed July 23, 2026.
Kostrzewa, Daniel. "Singing Voice Detection" Encyclopedia, https://encyclopedia.pub/entry/18717 (accessed July 23, 2026).
Kostrzewa, D. (2022, January 24). Singing Voice Detection. In Encyclopedia. https://encyclopedia.pub/entry/18717
Kostrzewa, Daniel. "Singing Voice Detection." Encyclopedia. Web. 24 January, 2022.
Copy Citation
Singing voice detection or vocal detection is a classification task that determines whether there is a singing voice in a given audio segment. This process is a crucial preprocessing step that can improve the performance of other tasks such as automatic lyrics alignment, singing melody transcription, singing voice separation, vocal melody extraction, and many more.
singing voice detection
vocal detection
1. Introduction
The singing voice is an essential component of music, serving as a communication channel for lyrics and rich emotions. A high level of expressiveness of human singing is even considered ideal for the instrument player to aspire toward. The human vocal apparatus generates sound by moving air forced by the diaphragm through the vocal folds, causing them to vibrate. Modulating airflow through the vibrating vocal folds produces a wealth of different timbres. Timbre is independent of the perceived pitch of a tone. It allows us to distinguish between vowels and consonants in words and the distinct sound qualities of various musical instruments.
Since human voice detection in music tracks is the basis for many advanced applications, it has been studied for several years. In the field of music information retrieval, singing voice detection (SVD) is the preprocessing step that can be used to improve the performance of other tasks such as automatic lyrics alignment [1][2][3], singing melody transcription [4][5], singing voice separation [6][7][8], vocal melody extraction [9], lyric transcription [10][11], singer identification [12], etc.
In order to locate vocal segments, researchers usually extract one or more types of features from the audio signals and then use the classifier to detect them [13]. There are various types of attributes, but MFCCs and the spectrum obtained with short-time Fourier transform (STFT) were the most commonly used features for the SVD task. The features and statistical classification methods used in speech recognition have some limitations in detecting singing voices. Deep learning, with its powerful feature representation as well as time and space modeling capabilities, has recently begun to be used in singing voice detection [14].
To detect the singing voice in music tracks, researchers usually split the speech signal into three portions: voiced (a strong sound in which the vocal cords vibrate), unvoiced, and silent parts. There are several voiced and unvoiced regions in speech. If the system’s input excitation is a nearly periodic impulse sequence, the corresponding speech appears visually nearly periodic and is referred to as voiced speech. While the excitation is random noise-like, the resulting speech signal is random noise-like as well, with no periodic nature, and is referred to as unvoiced speech. The classification of speech signals as voiced or unvoiced provides a preliminary acoustic segmentation for speech processing applications such as speech synthesis, speech enhancement, and speech recognition [15].
2. Feature Extraction
Singing voice detection is a crucial task that can be used to improve other tasks such as automatic lyrics alignment, singing melody transcription, vocal melody extraction, lyric transcription, singer identification, etc. To analyze music presence in a recorded audio signal, a representation that roughly corresponds to how people perceive sound through their auditory system has to be created. At a fundamental level, such audio representations aid in determining when events occur in time [16].
In order to locate vocal segments, researchers usually extract one or more types of features from the audio signals and then use a classifier to detect these audio features. The feature extraction stage is therefore critical for the subsequent classification process. Using a feature set (combining multiple features) usually results in better performance. Audio features provide the description of the sound that helps capture different aspects of sounds and build intelligent audio systems.
Audio features can be applied to feature extraction linked to audio effects [17], data classification [18], similarity measures [19], data mining [16], and feature-based synthesis [20], etc. Audio features can be categorized into three levels of abstraction: low-level such as spectral centroid, spectral flux, energy, zero-crossing rate; mid-level such as MFCCs; and high-level audio features such as lyrics, melody, and rhythm [21].
-
Short-Time Fourier Transform Spectrum
The Fourier transform is a mathematical formula for decomposing a signal into its individual frequencies and amplitudes. To put it another way, it converts the signal from the time domain to the frequency domain to create a spectrum. Perhaps short-time Fourier transform (STFT) spectrum is the most common time-frequency representation and has been widely used in various domains other than music processing. The STFT is also used to represent other audio features such as Mel-frequency cepstral coefficients (MFCCs) and chroma features [16].
-
Mel-spectrogram
The Mel-scale is a perceptual scale of pitches. A spectrogram is a visual image of a signal’s frequency spectrum as it changes over time. A spectrogram is obtained by applying STFT on overlapping windowed segments of the signal. This spectrogram is a graphical way of representing STFT data. Mel-spectrogram is often used when applying deep learning approaches because it is more efficient than STFT spectrum [22].
-
Temporal Features
Temporal features describe a music signal’s relatively long-term dynamics over time [23]. They are basically time-domain features, such as amplitude envelope, the energy of the signal, root mean square energy, zero-crossing rate (ZCR), etc., which are easy to extract. ZCR counts how many times the signal changes sign from negative to positive or vice versa in a specified time frame (in seconds). In the process of speech recognition and music information retrieval, ZCR is an essential feature in voice/noise classification. Speech can be unvoiced, and voiced fricatives (speech) have higher ZCR.
-
Spectral features
Spectral features, such as band energy ratio, spectral centroid, bandwidth, spectral roll-off, Mel-frequency cepstral coefficients (MFCC), perceptive linear prediction (PLP), linear prediction cepstral coefficients (LPCCs) [24], etc., are frequency domain features that are derived by converting the time domain into the frequency domain using the Fourier transform. The spectral features can be used to determine the rhythm, notes, pitch, and melody. Spectral centroid calculated as the weighted average of the frequencies in the signal is determined by a Fourier transformation with their magnitudes as weights. The spectral centroid is used to calculate a sound’s brightness, and it is an important factor in describing musical timbre.
MFCCs are widely used in SVD [25] and were first introduced by Davis and Mermelstein in 1980 [26]. Kim et al. [27] compared MFCC and audio spectrum projection features, and they mentioned that MFCCs were better for feature extraction. The use of MFCCs has proven to be a powerful tool in music and voice recognition, and sound recognition in general. The MFCCs are calculated as follows:
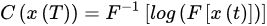
where x(t) is the time-domain signal. Figure 1 shows the steps to compute MFCC features.
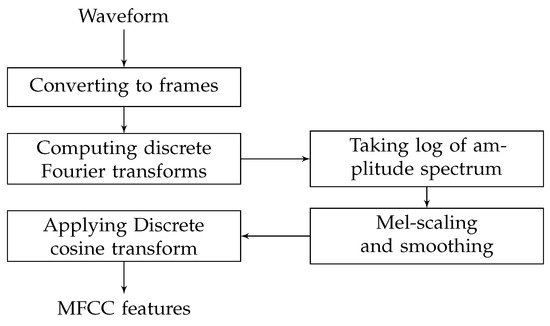
Figure 1. Calculation steps for MFCC features [28].
Calculation of the MFCC includes the following steps:
-
Division of the speech signals into frames, usually by applying a windowing function at fixed intervals [28];
-
Computing the coefficients of the discrete Fourier transform on each segment of windowed signal to convert the time domain into the frequency domain;
-
Taking the logarithm of the amplitude spectrum;
-
Smoothing the spectrum and emphasizing perceptually meaningful frequencies [28];
-
Taking the discrete cosine transform (DCT) of the list of mel log powers;
-
Generating cepstrum.
References
- Wong, C.H.; Szeto, W.M.; Wong, K.H. Automatic lyrics alignment for Cantonese popular music. Multimed. Syst. 2007, 12, 307–323.
- Fujihara, H.; Goto, M. Lyrics-to-audio alignment and its application. In Dagstuhl Follow-Ups; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2012; Volume 3.
- Kan, M.Y.; Wang, Y.; Iskandar, D.; Nwe, T.L.; Shenoy, A. LyricAlly: Automatic synchronization of textual lyrics to acoustic music signals. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 338–349.
- Rigaud, F.; Radenen, M. Singing Voice Melody Transcription Using Deep Neural Networks. In Proceedings of the 17th ISMIR Conference, New York, NY, USA, 7–11 August 2016; pp. 737–743.
- Bittner, R.M.; McFee, B.; Salamon, J.; Li, P.; Bello, J.P. Deep Salience Representations for F0 Estimation in Polyphonic Music. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR 2017), Suzhou, China, 23–27 October 2017; pp. 63–70.
- Pardo, B.; Rafii, Z.; Duan, Z. Audio source separation in a musical context. In Springer Handbook of Systematic Musicology; Springer: Berlin/Heidelberg, Germany, 2018; pp. 285–298.
- Li, Y.; Wang, D. Separation of singing voice from music accompaniment for monaural recordings. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1475–1487.
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing voice separation with deep u-net convolutional networks. In Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017.
- Rao, V.; Rao, P. Vocal melody extraction in the presence of pitched accompaniment in polyphonic music. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 2145–2154.
- Hosoya, T.; Suzuki, M.; Ito, A.; Makino, S.; Smith, L.A.; Bainbridge, D.; Witten, I.H. Lyrics Recognition from a Singing Voice Based on Finite State Automaton for Music Information Retrieval. In Proceedings of the 6th International Conference on Music Information Retrieval (ISMIR 2005), London, UK, 11–15 September 2005; pp. 532–535.
- McVicar, M.; Ellis, D.P.; Goto, M. Leveraging repetition for improved automatic lyric transcription in popular music. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3117–3121.
- Zhang, T. Automatic singer identification. In Proceedings of the 2003 International Conference on Multimedia and Expo. ICME’03. Proceedings (Cat. No. 03TH8698), Baltimore, MD, USA, 6–9 July 2003.
- You, S.D.; Liu, C.H.; Chen, W.K. Comparative study of singing voice detection based on deep neural networks and ensemble learning. Hum.-Centric Comput. Inf. Sci. 2018, 8, 34.
- Zhang, X.; Yu, Y.; Gao, Y.; Chen, X.; Li, W. Research on Singing Voice Detection Based on a Long-Term Recurrent Convolutional Network with Vocal Separation and Temporal Smoothing. Electronics 2020, 9, 1458.
- Rani, B.; Rani, A.J.; Ravi, T.; Sree, M.D. Basic fundamental recognition of voiced, unvoiced, and silence region of a speech. Int. J. Eng. Adv. Technol. 2014, 4, 83–86.
- Li, T.; Ogihara, M.; Tzanetakis, G. Music Data Mining; CRC Press: Boca Raton, FL, USA, 2011.
- Stables, R.; Enderby, S.; De Man, B.; Fazekas, G.; Reiss, J.D. Safe: A System for Extraction and Retrieval of Semantic Audio Descriptors. In Electronic Engineering and Computer Science; Queen Mary University of London: London, UK, 2014.
- McKinney, M.; Breebaart, J. Features for audio and music classification. In Proceedings of the ISMIR2003, Baltimore, MD, USA, 27–30 October 2003.
- Gygi, B.; Kidd, G.R.; Watson, C.S. Similarity and categorization of environmental sounds. Percept. Psychophys. 2007, 69, 839–855.
- Hoffman, M.D.; Cook, P.R. Feature-Based Synthesis: A Tool for Evaluating, Designing, and Interacting with Music IR Systems. In Proceedings of the ISMIR 2006, 7th International Conference on Music Information Retrieval, Victoria, BC, Canada, 8–12 October 2006; pp. 361–362.
- Knees, P.; Schedl, M. Music Similarity and Retrieval: An Introduction to Audio-and Web-Based Strategies; The Information Retrieval Series; Springer: Berlin/Heidelberg, Germany, 2016.
- Lee, K.; Choi, K.; Nam, J. Revisiting Singing Voice Detection: A quantitative review and the future outlook. In Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, 23–27 September 2018; pp. 506–513.
- Jeong, I.Y.; Lee, K. Learning Temporal Features Using a Deep Neural Network and its Application to Music Genre Classification. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 434–440.
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502.
- Rocamora, M.; Herrera, P. Comparing audio descriptors for singing voice detection in music audio files. In Proceedings of the Brazilian Symposium on Computer Music, 11th, São Paulo, Brazil, 1–3 September 2007; Volume 26, p. 27.
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366.
- Kim, H.G.; Sikora, T. Comparison of MPEG-7 audio spectrum projection features and MFCC applied to speaker recognition, sound classification and audio segmentation. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 5.
- Logan, B. Mel frequency cepstral coefficients for music modeling. In Proceedings of the International Symposium on Music Information Retrieval, Plymouth, MA, USA, 23–25 October 2000.
More
Information
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
2.0K
Revisions:
2 times
(View History)
Update Date:
25 Jan 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No