Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Daniel Kostrzewa and Version 2 by Catherine Yang.
Singing voice detection or vocal detection is a classification task that determines whether there is a singing voice in a given audio segment. This process is a crucial preprocessing step that can improve the performance of other tasks such as automatic lyrics alignment, singing melody transcription, singing voice separation, vocal melody extraction, and many more.
- singing voice detection
- vocal detection
1. Introduction
The singing voice is an essential component of music, serving as a communication channel for lyrics and rich emotions. A high level of expressiveness of human singing is even considered ideal for the instrument player to aspire toward. The human vocal apparatus generates sound by moving air forced by the diaphragm through the vocal folds, causing them to vibrate. Modulating airflow through the vibrating vocal folds produces a wealth of different timbres. Timbre is independent of the perceived pitch of a tone. It allows us to distinguish between vowels and consonants in words and the distinct sound qualities of various musical instruments.
Since human voice detection in music tracks is the basis for many advanced applications, it has been studied for several years. In the field of music information retrieval, singing voice detection (SVD) is the preprocessing step that can be used to improve the performance of other tasks such as automatic lyrics alignment [1][2][3][1,2,3], singing melody transcription [4][5][4,5], singing voice separation [6][7][8][6,7,8], vocal melody extraction [9], lyric transcription [10][11][10,11], singer identification [12], etc.
In order to locate vocal segments, researchers usually extract one or more types of features from the audio signals and then use the classifier to detect them [13][18]. There are various types of attributes, but MFCCs and the spectrum obtained with short-time Fourier transform (STFT) were the most commonly used features for the SVD task. The features and statistical classification methods used in speech recognition have some limitations in detecting singing voices. Deep learning, with its powerful feature representation as well as time and space modeling capabilities, has recently begun to be used in singing voice detection [14][21].
To detect the singing voice in music tracks, researchers usually split the speech signal into three portions: voiced (a strong sound in which the vocal cords vibrate), unvoiced, and silent parts. There are several voiced and unvoiced regions in speech. If the system’s input excitation is a nearly periodic impulse sequence, the corresponding speech appears visually nearly periodic and is referred to as voiced speech. While the excitation is random noise-like, the resulting speech signal is random noise-like as well, with no periodic nature, and is referred to as unvoiced speech. The classification of speech signals as voiced or unvoiced provides a preliminary acoustic segmentation for speech processing applications such as speech synthesis, speech enhancement, and speech recognition [15][22].
2. Feature Extraction
Singing voice detection is a crucial task that can be used to improve other tasks such as automatic lyrics alignment, singing melody transcription, vocal melody extraction, lyric transcription, singer identification, etc. To analyze music presence in a recorded audio signal, a representation that roughly corresponds to how people perceive sound through their auditory system has to be created. At a fundamental level, such audio representations aid in determining when events occur in time [16][23].
In order to locate vocal segments, researchers usually extract one or more types of features from the audio signals and then use a classifier to detect these audio features. The feature extraction stage is therefore critical for the subsequent classification process. Using a feature set (combining multiple features) usually results in better performance. Audio features provide the description of the sound that helps capture different aspects of sounds and build intelligent audio systems.
Audio features can be applied to feature extraction linked to audio effects [17][24], data classification [18][25], similarity measures [19][26], data mining [16][23], and feature-based synthesis [20][27], etc. Audio features can be categorized into three levels of abstraction: low-level such as spectral centroid, spectral flux, energy, zero-crossing rate; mid-level such as MFCCs; and high-level audio features such as lyrics, melody, and rhythm [21][28].
- Smoothing the spectrum and emphasizing perceptually meaningful frequencies
- [
-
Taking the discrete cosine transform (DCT) of the list of mel log powers;
- Short-Time Fourier Transform Spectrum
The Fourier transform is a mathematical formula for decomposing a signal into its individual frequencies and amplitudes. To put it another way, it converts the signal from the time domain to the frequency domain to create a spectrum. Perhaps short-time Fourier transform (STFT) spectrum is the most common time-frequency representation and has been widely used in various domains other than music processing. The STFT is also used to represent other audio features such as Mel-frequency cepstral coefficients (MFCCs) and chroma features [16][23].
- Mel-spectrogram
The Mel-scale is a perceptual scale of pitches. A spectrogram is a visual image of a signal’s frequency spectrum as it changes over time. A spectrogram is obtained by applying STFT on overlapping windowed segments of the signal. This spectrogram is a graphical way of representing STFT data. Mel-spectrogram is often used when applying deep learning approaches because it is more efficient than STFT spectrum [22][29].
- Temporal Features
Temporal features describe a music signal’s relatively long-term dynamics over time [23][30]. They are basically time-domain features, such as amplitude envelope, the energy of the signal, root mean square energy, zero-crossing rate (ZCR), etc., which are easy to extract. ZCR counts how many times the signal changes sign from negative to positive or vice versa in a specified time frame (in seconds). In the process of speech recognition and music information retrieval, ZCR is an essential feature in voice/noise classification. Speech can be unvoiced, and voiced fricatives (speech) have higher ZCR.
- Spectral features
Spectral features, such as band energy ratio, spectral centroid, bandwidth, spectral roll-off, Mel-frequency cepstral coefficients (MFCC), perceptive linear prediction (PLP), linear prediction cepstral coefficients (LPCCs) [24][31], etc., are frequency domain features that are derived by converting the time domain into the frequency domain using the Fourier transform. The spectral features can be used to determine the rhythm, notes, pitch, and melody. Spectral centroid calculated as the weighted average of the frequencies in the signal is determined by a Fourier transformation with their magnitudes as weights. The spectral centroid is used to calculate a sound’s brightness, and it is an important factor in describing musical timbre.
MFCCs are widely used in SVD [25][32] and were first introduced by Davis and Mermelstein in 1980 [26][33]. Kim et al. [27][34] compared MFCC and audio spectrum projection features, and they mentioned that MFCCs were better for feature extraction. The use of MFCCs has proven to be a powerful tool in music and voice recognition, and sound recognition in general. The MFCCs are calculated as follows:
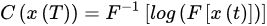
C(x(T))=F−1[log(F[x(t)])]
where x(t) is the time-domain signal. Figure 1 shows the steps to compute MFCC features.
C(x(T))=F−1[log(F[x(t)])]
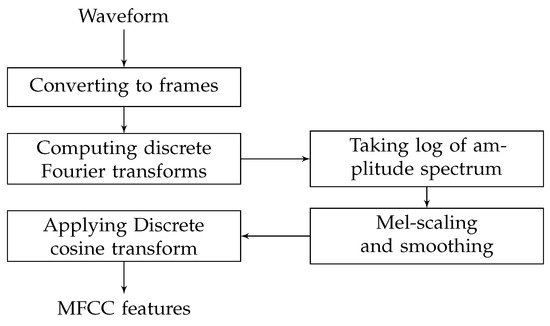
Calculation of the MFCC includes the following steps:
-
Computing the coefficients of the discrete Fourier transform on each segment of windowed signal to convert the time domain into the frequency domain;
-
Taking the logarithm of the amplitude spectrum;
- Generating cepstrum.