 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Michael Nugent | + 2482 word(s) | 2482 | 2021-09-13 08:33:20 | | | |
| 2 | Jessie Wu | Meta information modification | 2482 | 2021-09-17 03:37:18 | | |
Video Upload Options
In the last few decades, hot-melt extrusion (HME) has emerged as a rapidly growing technology in the pharmaceutical industry, due to its various advantages over other fabrication routes for drug delivery systems. After the introduction of the ‘quality by design’ (QbD) approach by the Food and Drug Administration (FDA), many research studies have focused on implementing process analytical technology (PAT), including near-infrared (NIR), Raman, and UV–Vis, coupled with various machine learning algorithms, to monitor and control the HME process in real time. This review gives a comprehensive overview of the application of machine learning algorithms for HME processes, with a focus on pharmaceutical HME applications. The main current challenges in the application of machine learning algorithms for pharmaceutical processes are discussed, with potential future directions for the industry.
1. Introduction
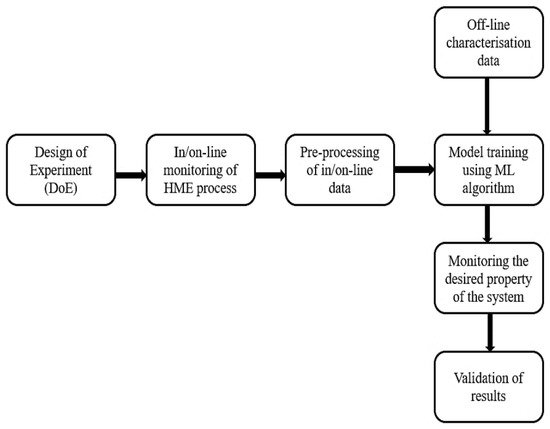
2. Machine Learning
2.1. Supervised Machine Learning
2.2. Unsupervised Machine Learning
2.3. Reinforcement Learning
3. Pre-Processing Techniques for In-Process Spectral Data
4. Application of PCA for In-ProcessMonitoring of Critical Quality Attributes (CQAs)
PCA is a technique for dimensionality reduction, which falls under unsupervised machine learning [65,77,78]. Details on how PCA works with PAT tools for monitoring pharmaceutical processes (other than HME) can be found in [79–81], and the detail of the algorithm is not repeated here. PCA has mostly been utilised in the HME literature to monitor the effect of varying processing conditions on the solid state of the drug. The drug solid state significantly influences the dissolution rate and bioavailability of the drug, with an amorphous form of the drug exhibiting a higher dissolution rate than the crystalline form.
5. Application of PLS for In-Process Monitoring of Critical Quality Attributes (CQAs)
PLS regression is a multivariate linear regression method that is suitable for highly collinear data. Analogous to PCA, it involves a linear transformation of the data set, allowing for dimensionality reduction to a reduced number of ‘latent variables’ (LV), which are linear combinations of the original variables. General details on the workings of the PLS algorithm applied to PAT data for pharmaceutical process monitoring can be found in [79–81,84]. In pharmaceutical processes, PLS is primarily used to predict the concentration of the drug, although it has also been used to predict polymer blend contents, degradation of the polymer, the particle size of fillers in the polymer matrix, and mechanical properties of the polymer extrudate in non-pharma HME processes.
6. Conclusions
The application of machine learning in pharmaceutical processing is a rapidly developing field, with many potential benefits for process optimisation and control. A well-designed machine learning model can speed up the development process, aid optimisation of the process, reduce the process cost, enhance product consistency, reduce process faults, and enable rapid validation of product quality. However, the use of machine learning algorithms for pharmaceutical HME is relatively new and is as yet underdeveloped. Most of the works reported in the literature have been conducted to predict/monitor the solid state of the polymer–drug extrudate and the API concentration. Few works have been published to date on predicting the final properties of the product such as, degradation of the polymer–drug matrix, mechanical properties and rate of loss of mechanical properties, drug release profile, etc., from in-process data. Recent works examining the application of more-complex ML models, both in HME and more widely in pharmaceutical processing, indicate that with careful design of the sensing system, the experimental procedures, and the modelling algorithms that prediction of such properties from in-process data may be possible in the future. Further, the application of machine learning for automating process control, for example, by using reinforcement learning, has not yet been explored in the literature. Future work should be in the direction of examining the suitability of different machine learning methods, their robustness, and limitations to predict and control the final properties of the polymer–drug matrix. It is stressed that if such models are to meet the industrial requirements for product validation that appropriately rigorous model validation procedures should be applied
References
- Tiwari, R.V.; Patil, H.; Repka, M.A. Contribution of hot-melt extrusion technology to advance drug delivery in the 21st century. Expert Opin. Drug Deliv. 2016, 13, 451–464.
- Saerens, L.; Ghanam, D.; Raemdonck, C.; Francois, K.; Manz, J.; Krüger, R.; Krüger, S.; Vervaet, C.; Remon, J.P.; De Beer, T. In-line solid state prediction during pharmaceutical hot-melt extrusion in a 12 mm twin screw extruder using Raman spectroscopy. Eur. J. Pharm. Biopharm. 2014, 87, 606–615.
- Van Renterghem, J.; Kumar, A.; Vervaet, C.; Remon, J.P.; Nopens, I.; Vander Heyden, Y.; De Beer, T. Elucidation and visualization of solid-state transformation and mixing in a pharmaceutical mini hot melt extrusion process using in-line Raman spectroscopy. Int. J. Pharm. 2017, 517, 119–127.
- Psimadas, D.; Georgoulias, P.; Valotassiou, V.; Loudos, G. Molecular Nanomedicine towards Cancer. J. Pharm. Sci. 2012, 101, 2271–2280.
- Thiry, J.; Lebrun, P.; Vinassa, C.; Adam, M.; Netchacovitch, L.; Ziemons, E.; Hubert, P.; Krier, F.; Evrard, B. Continuous production of itraconazole-based solid dispersions by hot melt extrusion: Preformulation, optimization and design space determination. Int. J. Pharm. 2016, 515, 114–124.
- Huang, S.; O’Donnell, K.P.; Delpon de Vaux, S.M.; O’Brien, J.; Stutzman, J.; Williams, R.O. Processing thermally labile drugs by hot-melt extrusion: The lesson with gliclazide. Eur. J. Pharm. Biopharm. 2017, 119, 56–67.
- Li, Y.; Pang, H.; Guo, Z.; Lin, L.; Dong, Y.; Li, G.; Lu, M.; Wu, C. Interactions between drugs and polymers influencing hot melt extrusion. J. Pharm. Pharmacol. 2014, 66, 148–166.
- Crowley, M.M.; Zhang, F.; Koleng, J.J.; McGinity, J.W. Stability of polyethylene oxide in matrix tablets prepared by hot-melt extrusion. Biomaterials 2002, 23, 4241–4248.
- Backes, E.H.; Pires, L.D.N.; Costa, L.C.; Passador, F.R.; Pessan, L.A. Analysis of the Degradation During Melt Processing of PLA/Biosilicate® Composites. J. Compos. Sci. 2019, 3, 52.
- Guo, Z.; Lu, M.; Li, Y.; Pang, H.; Lin, L.; Liu, X.; Wu, C. The utilization of drug-polymer interactions for improving the chemical stability of hot-melt extruded solid dispersions. J. Pharm. Pharmacol. 2014, 66, 285–296.
- Huang, S.; O’Donnell, K.P.; Keen, J.M.; Rickard, M.A.; McGinity, J.W.; Williams, R.O. A New Extrudable Form of Hypromellose: AFFINISOLTM HPMC HME. AAPS PharmSciTech 2016, 17, 106–119.
- Haser, A.; Huang, S.; Listro, T.; White, D.; Zhang, F. An Approach for Chemical Stability during Melt Extrusion of a Drug Substance with a High Melting Point; Elsevier: Amsterdam, The Netherlands, 2017; Volume 524, ISBN 5124710942.
- Hengsawas Surasarang, S.; Keen, J.M.; Huang, S.; Zhang, F.; McGinity, J.W.; Williams, R.O. Hot melt extrusion versus spray drying: Hot melt extrusion degrades albendazole. Drug Dev. Ind. Pharm. 2017, 43, 797–811.
- Liu, X.; Lu, M.; Guo, Z.; Huang, L.; Feng, X.; Wu, C. Improving the chemical stability of amorphous solid dispersion with cocrystal technique by hot melt extrusion. Pharm. Res. 2012, 29, 806–817.
- Haser, A.; Cao, T.; Lubach, J.; Listro, T.; Acquarulo, L.; Zhang, F. Melt Extrusion vs. Spray Drying: The Effect of Processing Methods on Crystalline Content of Naproxen-Povidone Formulations; Elsevier: Amsterdam, The Netherlands, 2017; Volume 102, ISBN 5124710942.
- Repka, M.A.; McGinity, J.W. Influence of Vitamin E TPGS on the properties of hydrophilic films produced by hot-melt extrusion. Int. J. Pharm. 2000, 202, 63–70.
- Saerens, L.; Dierickx, L.; Lenain, B.; Vervaet, C.; Remon, J.P.; Beer, T. De Raman spectroscopy for the in-line polymer-drug quantification and solid state characterization during a pharmaceutical hot-melt extrusion process. Eur. J. Pharm. Biopharm. 2011, 77, 158–163.
- Saerens, L.; Vervaet, C.; Remon, J.P.; De Beer, T. Visualization and process understanding of material behavior in the extrusion barrel during a hot-melt extrusion process using raman spectroscopy. Anal. Chem. 2013, 85, 5420–5429.
- Saerens, L.; Dierickx, L.; Quinten, T.; Adriaensens, P.; Carleer, R.; Vervaet, C.; Remon, J.P.; De Beer, T. In-line NIR spectroscopy for the understanding of polymer-drug interaction during pharmaceutical hot-melt extrusion. Eur. J. Pharm. Biopharm. 2012, 81, 230–237.
- Aho, J.; Syrjälä, S. Shear viscosity measurements of polymer melts using injection molding machine with adjustable slit die. Polym. Test. 2011, 30, 595–601.
- Dealy, J.M.; Broadhead, T.O. Process rheometers for molten plastics: A survey of existing technology. Polym. Eng. Sci. 1993, 33, 1513–1523.
- Ponrajan, A.; Tonner, T.; Okos, M.; Campanella, O.; Narsimhan, G. Comparing inline extrusion viscosity for different operating conditions to offline capillary viscosity measurements. J. Food Process Eng. 2019, e13199.
- Chen, Z.L.; Chao, P.Y.; Chiu, S.H. Proposal of an empirical viscosity model for quality control in the polymer extrusion process. Polym. Test. 2003, 22, 601–607.
- Yang, Z.; Peng, H.; Wang, W.; Liu, T. Crystallization behavior of poly(ε-caprolactone)/layered double hydroxide nanocomposites. J. Appl. Polym. Sci. 2010, 116, 2658–2667.
- Repka, M.A.; Gerding, T.G.; Repka, S.L.; McGinity, J.W. Influence of plasticizers and drugs on the physical-mechanical properties of hydroxypropylcellulose films prepared by hot melt extrusion. Drug Dev. Ind. Pharm. 1999, 25, 625–633.
- Low, A.Q.J.; Parmentier, J.; Khong, Y.M.; Chai, C.C.E.; Tun, T.Y.; Berania, J.E.; Liu, X.; Gokhale, R.; Chan, S.Y. Effect of type and ratio of solubilising polymer on characteristics of hot-melt extruded orodispersible films. Int. J. Pharm. 2013, 455, 138–147.
- Vo, A.Q.; Feng, X.; Morott, J.T.; Pimparade, M.B.; Tiwari, R.V.; Zhang, F.; Repka, M.A. A novel floating controlled release drug delivery system prepared by hot-melt extrusion. Eur. J. Pharm. Biopharm. 2016, 98, 108–121.
- Patil, H.; Feng, X.; Ye, X.; Majumdar, S.; Repka, M.A. Continuous Production of Fenofibrate Solid Lipid Nanoparticles by Hot-Melt Extrusion Technology: A Systematic Study Based on a Quality by Design Approach. AAPS J. 2015, 17, 194–205.
- Food and Drug Administration (FDA). Guidance for Industry, PAT-A Framework for Innovative Pharmaceutical Development, Manufacturing and Quality Assurance. In FDA/RPSGB Guidance Workshop; No. September; 2004. Available online: http://www.fda.gov/downloads/Drugs/GuidanceComplianceRegulatoryInformation/Guidances/ucm070305.pdf (accessed on 14 October 2020).
- Chirkot, T.; Halsey, S.; Swanborough, A. Monitoring the Output of Pharmaceutical Hot Melt Extruders with near Infrared Spectroscopy. NIR News 2014, 25, 15–18.
- Whitaker, D.A.; Buchanan, F.; Billham, M.; McAfee, M. A UV-Vis spectroscopic method for monitoring of additive particle properties during polymer compounding. Polym. Test. 2018, 67, 392–398.
- Kelly, A.L.; Gough, T.; Isreb, M.; Dhumal, R.; Jones, J.W.; Nicholson, S.; Dennis, A.B.; Paradkar, A. In-process rheometry as a PAT tool for hot melt extrusion. Drug Dev. Ind. Pharm. 2018, 44, 670–676.
- Mulrennan, K.; Donovan, J.; Creedon, L.; Rogers, I.; Lyons, J.G.; McAfee, M. A soft sensor for prediction of mechanical properties of extruded PLA sheet using an instrumented slit die and machine learning algorithms. Polym. Test. 2018, 69, 462–469.
- Vo, A.Q.; He, H.; Zhang, J.; Martin, S.; Chen, R.; Repka, M.A. Application of FT-NIR Analysis for In-line and Real-Time Monitoring of Pharmaceutical Hot Melt Extrusion: A Technical Note. AAPS PharmSciTech 2018, 19, 3425–3429.
- Almeida, J.; Bezerra, M.; Markl, D.; Berghaus, A.; Borman, P.; Schlindwein, W. Development and validation of an in-line API quantification method using AQbD principles based on UV-vis spectroscopy to monitor and optimise continuous hot melt extrusion process. Pharmaceutics 2020, 12, 150.
- Guo, X.; Lin, Z.; Wang, Y.; He, Z.; Wang, M.; Jin, G. In-line monitoring the degradation of polypropylene under multiple extrusions based on Raman spectroscopy. Polymers 2019, 11, 1698.
- Montano-herrera, L.; Pratt, S.; Arcos-hernandez, M.V.; Halley, P.J.; Lant, P.A.; Werker, A.; Laycock, B. In-line monitoring of thermal degradation of PHA during melt-processing by Near-Infrared spectroscopy. New Biotechnol. 2013, 31, 357–363.
- Abeykoon, C.; Martin, P.J.; Li, K.; Kelly, A.L. Dynamic modelling of die melt temperature profile in polymer extrusion: Effects of process settings, screw geometry and material. Appl. Math. Model. 2014, 38, 1224–1236.
- Abeykoon, C.; Li, K.; Martin, P.J.; Kelly, A.L. Monitoring and modelling of the effects of process settings and screw geometry on melt pressure generation in polymer extrusion. Int. J. Syst. Control Inf. Process. 2012, 1, 71.
- Liu, X.; Li, K.; McAfee, M.; Deng, J. “Soft-sensor” for real-time monitoring of melt viscosity in polymer extrusion process. In Proceedings of the 49th IEEE conference on decision and control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 3469–3474.
- Tahir, F.; Islam, M.T.; Mack, J.; Robertson, J.; Lovett, D. Process monitoring and fault detection on a hot-melt extrusion process using in-line Raman spectroscopy and a hybrid soft sensor. Comput. Chem. Eng. 2019, 125, 400–414.
- Vynckier, A.K.; Dierickx, L.; Voorspoels, J.; Gonnissen, Y.; Remon, J.P.; Vervaet, C. Hot-melt co-extrusion: Requirements, challenges and opportunities for pharmaceutical applications. J. Pharm. Pharmacol. 2014, 66, 167–179.
- Stanković, M.; Frijlink, H.W.; Hinrichs, W.L.J. Polymeric formulations for drug release prepared by hot melt extrusion: Application and characterization. Drug Discov. Today 2015, 20, 812–823.
- Shah, S.; Maddineni, S.; Lu, J.; Repka, M.A. Melt extrusion with poorly soluble drugs. Int. J. Pharm. 2013, 453, 233–252.
- Saerens, L.; Vervaet, C.; Remon, J.P.; De Beer, T. Process monitoring and visualization solutions for hot-melt extrusion: A review. J. Pharm. Pharmacol. 2014, 66, 180–203.
- Repka, M.A.; Bandari, S.; Kallakunta, V.R.; Vo, A.Q.; McFall, H.; Pimparade, M.B.; Bhagurkar, A.M. Melt extrusion with poorly soluble drugs—An integrated review. Int. J. Pharm. 2018, 535, 68–85.
- Maniruzzaman, M.; Boateng, J.S.; Snowden, M.J.; Douroumis, D. A Review of Hot-Melt Extrusion: Process Technology to Pharmaceutical Products. ISRN Pharm. 2012, 2012, 1–9.
- Netchacovitch, L.; Thiry, J.; De Bleye, C.; Chavez, P.F.; Krier, F.; Sacré, P.Y.; Evrard, B.; Hubert, P.; Ziemons, E. Vibrational spectroscopy and microspectroscopy analyzing qualitatively and quantitatively pharmaceutical hot melt extrudates. J. Pharm. Biomed. Anal. 2015, 113, 21–33.
- Patil, H.; Tiwari, R.V.; Repka, M.A. Hot-Melt Extrusion: From Theory to Application in Pharmaceutical Formulation. AAPS PharmSciTech 2016, 17, 20–42.
- Lang, B.; McGinity, J.W.; Williams, R.O. Hot-melt extrusion-basic principles and pharmaceutical applications. Drug Dev. Ind. Pharm. 2014, 40, 1133–1155.
- Maniruzzaman, M. Pharmaceutical applications of hot-melt extrusion: Continuous manufacturing, twin-screw granulations, and 3D printing. Pharmaceutics 2019, 11, 218.
- LaFountaine, J.S.; McGinity, J.W.; Williams, R.O. Challenges and Strategies in Thermal Processing of Amorphous Solid Dispersions: A Review. AAPS PharmSciTech 2016, 17, 43–55.
- Chokshi, R.; Zia, H. Hot-Melt Extrusion Technique: A review. Iran. J. Pharm. Res. 2011, 5, 1–21.
- Jani, R.; Patel, D. Hot melt extrusion: An industrially feasible approach for casting orodispersible film. Asian J. Pharm. Sci. 2014, 10, 292–305.
- Kalepu, S.; Nekkanti, V. Insoluble drug delivery strategies: Review of recent advances and business prospects. Acta Pharm. Sin. B 2015, 5, 442–453.
- Bhairav, B.A.; Kokane, P.A.; Saudagar, R.B. Hot Melt Extrusion Technique—A Review. Res. J. Sci. Technol. 2016, 8, 155.
- Crowley, M.M.; Zhang, F.; Repka, M.A.; Thumma, S.; Upadhye, S.B.; Battu, S.K.; McGinity, J.W.; Martin, C. Pharmaceutical applications of hot-melt extrusion: Part I. Drug Dev. Ind. Pharm. 2007, 33, 909–926.
- Breukelaar, A.H.B. Hot Melt Extrusion Technique. WebmedCentral Pharm. Sci. 2011, 2, 135–139.
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent advances and applications of machine learning in solid-state materials science. NPJ Comput. Mater. 2019, 5, 83.
- Dey, A. Machine Learning Algorithms: A Review. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 1174–1179.
- Wosiak, A.; Zamecznik, A.; Niewiadomska-Jarosik, K. Supervised and unsupervised machine learning for improved identification of intrauterine growth restriction types. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; Volume 8, pp. 323–329.
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281.
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190.
- Partheniadis, I.; Toskas, M.; Stavras, F.M.; Menexes, G.; Nikolakakis, I. Impact of hot-melt-extrusion on solid-state properties of pharmaceutical polymers and classification using hierarchical cluster analysis. Processes 2020, 8, 1208.
- López del Val, J.A.; Alonso Pérez de Agreda, J.P. Principal components analysis. Aten. Primaria 1993, 12, 333–338.
- Hammoudeh, A. A Concise Introduction to Reinforcement Learning; Princess Suamaya University for Technology: Amman, Jordan, 2018.
- Morales, E.F.; Zaragoza, J.H. An introduction to reinforcement learning. Decis. Theory Model. Appl. Artif. Intell. Concepts Solut. 2011, 63–80.
- Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222.
- Xu, L.; Zhou, Y.P.; Tang, L.J.; Wu, H.L.; Jiang, J.H.; Shen, G.L.; Yu, R.Q. Ensemble preprocessing of near-infrared (NIR) spectra for multivariate calibration. Anal. Chim. Acta 2008, 616, 138–143.
- Almeida, A.; Saerens, L.; De Beer, T.; Remon, J.P.; Vervaet, C. Upscaling and in-line process monitoring via spectroscopic techniques of ethylene vinyl acetate hot-melt extruded formulations. Int. J. Pharm. 2012, 439, 223–229.
- Zeaiter, M.; Roger, J.M.; Bellon-Maurel, V. Robustness of models developed by multivariate calibration. Part II: The influence of pre-processing methods. TrAC Trends Anal. Chem. 2005, 24, 437–445.
- Bi, Y.; Yuan, K.; Xiao, W.; Wu, J.; Shi, C.; Xia, J.; Chu, G.; Zhang, G.; Zhou, G. A local pre-processing method for near-infrared spectra, combined with spectral segmentation and standard normal variate transformation. Anal. Chim. Acta 2016, 909, 30–40.
- De Maesschalck, R.; Estienne, F.; Verdú-Andrés, J.; Candolfi, A.; Centner, V.; Despagne, F.; Jouan-Rimbaud, D.; Walczak, B.; Massart, D.; De Jong, S. The development of calibration models for spectroscopic data using principal component regression. Internet J. Chem. 1999, 2, 1.
- Blazhko, U.; Shapaval, V.; Kovalev, V.; Kohler, A. Comparison of augmentation and pre-processing for deep learning and chemometric classification of infrared spectra. Chemom. Intell. Lab. Syst. 2021, 215, 104367.
- Fearn, T.; Riccioli, C.; Garrido-Varo, A.; Guerrero-Ginel, J.E. On the geometry of SNV and MSC. Chemom. Intell. Lab. Syst. 2009, 96, 22–26.

