 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Wei Chen | + 3511 word(s) | 3511 | 2021-08-26 10:53:43 | | | |
| 2 | Lindsay Dong | + 1 word(s) | 3512 | 2021-09-02 05:36:33 | | | | |
| 3 | Lindsay Dong | Meta information modification | 3512 | 2021-09-02 05:40:09 | | | | |
| 4 | Lindsay Dong | Meta information modification | 3512 | 2021-09-02 05:42:49 | | | | |
| 5 | Lindsay Dong | Meta information modification | 3512 | 2021-09-02 06:07:21 | | | | |
| 6 | Lindsay Dong | Meta information modification | 3512 | 2021-09-03 11:20:37 | | |
Video Upload Options
Caching has attracted much attention recently because it holds the promise of scaling the service capability of radio access networks (RANs). To realize caching, the physical layer and higher layers have to function together, with the aid of prediction and memory units, which substantially broadens the concept of cross-layer design to a multi-unit collaboration methodology.
1. Introduction
Modern radio access networks are capable of achieving data rates of Gbps, while they may still fail to meet the predicted bandwidth requirements of future networks. A recent report from Cisco [1] forecasts that mobile data traffic will grow to 77.49 EB per month in 2022. In theory, a human brain may process up to 100T bits per second [2]. As a result, a huge gap may exist between the future bandwidth demand and provision in next generation radio access networks (RANs). Unfortunately, on-demand transmission that dominates current RAN architectures has almost achieved its performance limits revealed by Shannon in 1948, given extensive development of physical layer techniques in the past decades. On the other hand, the radio spectrum has been over-allocated, while the overall energy consumption is explosive. Since the potential of on-demand transmission has been fully exploited, it is time to conceive novel transmission architectures for sixth generation (6G) networks [3] so as to scale its service capability. The cache-empowered RAN is one of the potential solutions that hold the promise of scaling service capability [4].
Caching techniques were originally developed for computer systems in the 1960s. Web caching was conceived for the Internet due to the explosively increasing number of websites in the 2000s. In contrast to on-demand transmission, caching allows proactive content placement before being requested, which has motivated some novel infrastructures such as information-centric networks (ICNs) and content delivery networks (CDNs).
More recently, caching has been found to substantially benefit data transmissions over harsh wireless channels and meet growing demands with restrained radio resources in various ways [5][6][7][8].
Though considerable literature on the subject of wireless caching exists, there is a need to revisit it from a cross-layer perspective, as shown in Figure 1.
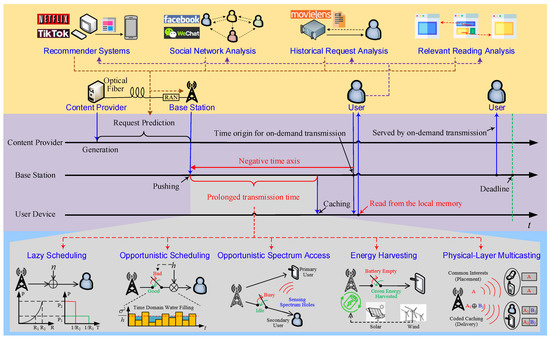
| Transmission Techniques | Application Scenarios | How Is SE or EE Gain Attained? | Why Is Delay Increased? |
|---|---|---|---|
| Lazy Scheduling | Additive White Gaussian Noise Channels | Due to the convexity of Shannon capacity, EE is a decreasing function of the transmission power/rate. | Low data rate |
| Opportunistic Scheduling | Fading Channels | EE/SE is increased by time domain water-filling, or simply accessing good channels only. | Channel states remaining poor |
| Opportunistic Spectrum Access | Secondary Users | SE is increased by sensing and accessing idle timeslots or spectrum holes. | Spectrum remaining busy |
| Energy Harvesting | Renewable Energy Powered BSs/UEs | The renewable energy harvested from solar panels, wind turbines, or even the RF environment helps to save grid power. | No or little energy harvested |
| Physical-Layer Multicasting | Users with Common Interests | Multiple users located in the same cell are served by broadcasting a common signal to them. | Waiting for common requests |
2. Proactive Service: Gains, Costs, and Needs
Without waiting for users’ orders, a cache-empowered RAN provides proactive services.
2.1. Caching Gains: A Time-Domain Perspective
-
Caching enables physical layer multicasting [9]. In theory, caching is capable of serving infinitely many users with a common request, thereby making RANs scalable. Classic on-demand transmission can seldom benefit from the multicasting gain because users seldom ask for a common message simultaneously. Aligning common requests in the time domain may, however, cause severe delay and damage Quality-of-Service (QoS). Proactive caching brings a solution to attain multicasting gain without inducing delay in data services. Even when users have different requests, judiciously designed coded caching strategies [10][11] allow RANs to enjoy the multicasting gain.
-
Caching extends the tolerable transmission time, thereby bringing spectral efficiency (SE) or energy efficiency (EE) gains. Lazy scheduling [12], opportunistic scheduling [13][14], opportunistic spectrum access (OSA) [15], and energy harvesting (EH) [16] may increase the SE and EE. However, their applications are usually prohibited or limited due to their random transmission delay. Caching enables content transmission before user requests and hence substantially prolongs the delay tolerance.
-
Caching enables low-complexity interference mitigation or alignment [17]. It is well known that a user can cancel a signal’s interference based on prior knowledge about the message that the signal bears. Classic successive interference cancellation (SIC) decodes the interference first by treating the desired signal as noise. However, SIC can suffer from high complexity and error propagation. By contrast, caching provides reliable prior knowledge on the interfering signal, which significantly reduces the complexity of interference cancellation.
2.2. Memory Cost to Be Paid for Caching
3. Request Time Prediction: Beyond Content Popularity
Request time prediction is potentially highly beneficial in proactive caching. Unfortunately, conventional popularity based models, either static or time-varying, are content-specific. They mainly focus on the content popularity distribution among users.3.1. Characterization of Random Request Time
Request time prediction relies on the fact, also observed in [4], that a content item is usually requested by a user at most once. We set a content item’s generation time to be the time origin. The item can be requested by a user at a random time after its generation, denoted by X, also referred to as the request delay. If it is never requested by the user, we regard the request delay to be X=0−. Otherwise, the user will ask for it at X≥0. The accurate request delay X can hardly be predicted, but its probability density function (p.d.f.), denoted by p(x), is predictable. We shall refer to p(x) as the statistical request delay information (RDI), which characterizes our prediction about the request time [20].3.2. RDI Estimation Methods
Artificial Intelligence (AI) and big data technologies provide powerful tools for understanding user behaviors in the time domain [21][22][23]. A time-varying popularity prediction for video clips can be found in [24][25], in which real data from YouTube and Facebook are used. In practice, the request time is also affected by one’s environments, activities, social connections, etc. For instance, one tends to watch video clips to kill time in the subway or during leisure time, but internet surfing is strictly prohibited while driving. Consequently, user-specific prediction brings together human behavior analysis, natural language processing (NLP), social networks, etc., leading to many cross-disciplinary research opportunities that include but are not limited to
-
Learning a user’s historical requests and data rating [26][27],
-
Exploiting the impact of social networks, recommendation systems, and search engines,
-
Discovering relevant content using NLP,
-
Analyzing a user behaviors, e.g., activities, mobilities, and localizations.

4. Fundamental Limits of Caching: A Cross-Layer Perspective
4.1. Communication Gains
Proactive caching prolongs the transmission time, which enables many possible energy- and/or spectral-efficient physical layer techniques. We are interested in how a content item is pushed given its RDI and what its EE/SE limit is. Quantitative case studies on the EE of pushing over additive white Gaussian noise (AWGN), multiple-input single-output (MISO), and fading channels are presented in [12][13][14], respectively. A user that tolerates a maximal delay of T seconds may request a content item having B bits. The AWGN channel has a normalized bandwidth and power spectral density of noise.
4.2. Memory Costs
5. Pricing: Creating Incentive for Caching
5.1. Pricing Caching Service Using a Hierarchical Architecture
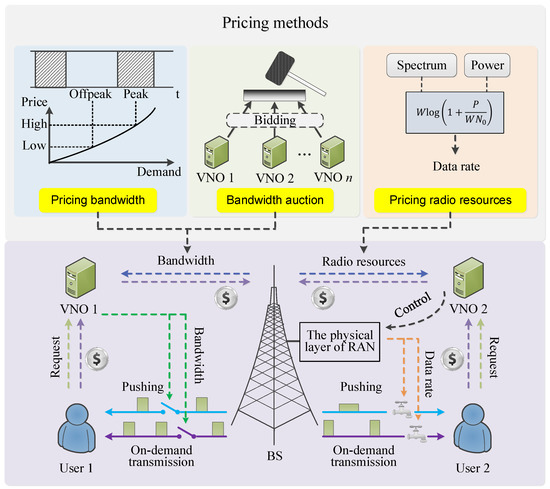
5.2. Pricing User Cooperation
5.3. Competition and Evolution
5.4. Pricing Radio Resources, Memory, and Privacy
6. Recommendation: Making RANs More Proactive
6.1. Joint Caching and Recommendation
6.2. After-Request Recommendation and Soft Hit
References
- Cisco. Cisco Visual Networking Index: Forecast and Trends, 2017–2022 White Paper, 2019. Available online: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-741490.pdf (accessed on 17 May 2020).
- Rappaport, T.S.; Xing, Y.; Kanhere, O.; Ju, S.; Madanayake, A.; Mandal, S.; Alkhateeb, A.; Trichopoulos, G.C. Wireless communications and applications above 100 GHz: Opportunities and challenges for 6G and beyond. IEEE Access 2019, 7, 78729–78757.
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.-J.A. The roadmap to 6G–AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90.
- Paschos, G.; Baştuğ, E.; Land, I.; Caire, G.; Debbah, M. Wireless caching: Technical misconceptions and business barriers. IEEE Commun. Mag. 2016, 54, 16–22.
- Paschos, G.S.; Iosifidis, G.; Tao, M.; Towsley, D.; Caire, G. The role of caching in future communication systems and networks. IEEE J. Sel. Areas Commun. 2018, 36, 1111–1125.
- Bai, B.; Wang, L.; Han, Z.; Chen, W.; Svensson, T. Caching based socially-aware D2D communications in wireless content delivery networks: A hypergraph framework. IEEE Wirel. Commun. 2016, 23, 74–81.
- Wang, L.; Wu, H.; Ding, Y.; Chen, W.; Poor, H.V. Hypergraph-based wireless distributed storage optimization for cellular D2D underlays. IEEE J. Sel. Areas Commun. 2016, 34, 2650–2666.
- Yan, Q.; Chen, W.; Poor, H.V. Big data driven wireless communications: A human-in-the-loop pushing technique for 5G systems. IEEE Wirel. Commun. 2018, 25, 64–69.
- Lu, Y.; Chen, W.; Poor, H.V. Multicast pushing with content request delay information. IEEE Trans. Commun. 2018, 66, 1078–1092.
- Lu, Y.; Chen, W.; Poor, H.V. Coded joint pushing and caching with asynchronous user requests. IEEE J. Sel. Areas Commun. 2018, 36, 1843–1856.
- Lu, Y.; Chen, W.; Poor, H.V. A unified framework for caching in arbitrary networks. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5.
- Huang, W.; Chen, W.; Poor, H.V. Energy efficient pushing in AWGN channels based on content request delay information. IEEE Trans. Commun. 2018, 66, 3667–3682.
- Lin, Z.; Chen, W. Content pushing over multiuser MISO downlinks with multicast beamforming and recommendation: A cross-layer approach. IEEE Trans. Commun. 2019, 67, 7263–7276.
- Xie, Z.; Lin, Z.; Chen, W. Power and rate adaptive pushing over fading channels. IEEE Trans. Wirel. Commun. 2021. early access.
- Li, C.; Chen, W. Content pushing over idle timeslots: Performance analysis and caching gains. IEEE Trans. Wirel. Commun. 2021. early access.
- Zhou, S.; Gong, J.; Zhou, Z.; Chen, W.; Niu, Z. GreenDelivery: Proactive content caching and push with energy-harvesting-based small cells. IEEE Commun. Mag. 2015, 53, 142–149.
- Maddah-Ali, M.A.; Niesen, U. Cache-aided interference channels. IEEE Trans. Inf. Theory 2019, 65, 1714–1724.
- Chen, W.; Poor, H.V. Caching with time domain buffer sharing. IEEE Trans. Commun. 2019, 67, 2730–2745.
- Xie, Z.; Chen, W. Storage-efficient edge caching with asynchronous user requests. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 229–241.
- Chen, W.; Poor, H.V. Content pushing with request delay information. IEEE Trans. Commun. 2017, 65, 1146–1161.
- Bharath, B.N.; Nagananda, K.G.; Gündxuxz, D.; Poor, H.V. Caching with time-varying popularity profiles: A learning-theoretic perspective. IEEE Trans. Communn. 2018, 66, 3837–3847.
- Lee, M.-C.; Molisch, A.F.; Sastry, N.; Raman, A. Individual preference probability modeling and parameterization for video content in wireless caching networks. IEEE/ACM Trans. Netw. 2019, 27, 676–690.
- Yang, L.; Guo, X.; Wang, H.; Chen, W. A video popularity prediction scheme with attention-based LSTM and feature embedding. In Proceedings of the 2020 IEEE Global Communications Conference (GLOBECOM 2020), Taipei, Taiwan, 7–11 December 2020; pp. 1–6.
- Yang, P.; Zhang, N.; Zhang, S.; Yu, L.; Zhang, J.; Shen, X. Content Popularity Prediction Towards Location-Aware Mobile Edge Caching. IEEE Trans. Multimed. 2019, 21, 915–929.
- Tang, L.; Huang, Q.; Puntambekar, A.; Vigfusson, Y.; Lloyd, W.; Li, K. Popularity prediction of facebook videos for higher quality streaming. In Proceedings of the USENIX Annual Technical Conference (USENIX ATC), Santa Clara, CA, USA, 12–14 July 2017; pp. 111–123.
- Wu, J.; Yang, C.; Chen, B. Proactive caching and bandwidth allocation in heterogeneous network by learning from historical number of requests. IEEE Trans. Commun. 2020, 68, 4394–4410.
- Cheng, P.; Ma, C.; Ding, M.; Hu, Y.; Lin, Z.; Li, Y.; Vucetic, B. Localized small cell caching: A machine learning approach based on rating data. IEEE Trans. Commun. 2019, 67, 1663–1676.
- Hui, H.; Chen, W.; Wang, L. Caching with finite buffer and request delay information: A markov decision process approach. IEEE Trans. Wirel. Commun. 2020, 19, 5148–5161.
- Li, L.; Xu, Y.; Yin, J.; Liang, W.; Li, X.; Chen, W.; Han, Z. Deep reinforcement learning approaches for content caching in cache-enabled D2D networks. IEEE Internet Things J. 2020, 7, 544–557.
- Li, L.; Cheng, Q.; Tang, X.; Bai, T.; Chen, W.; Ding, Z.; Han, Z. Resource allocation for NOMA-MEC systems in ultra-dense networks: A learning aided mean-field game approach. IEEE Trans. Wirel. Commun. 2021, 20, 1487–1500.
- Chen, Q.; Wang, W.; Chen, W.; Yu, F.R.; Zhang, Z. Cache-enabled multicast content pushing with structured deep learning. IEEE J. Sel. Areas Commun. 2021, 39, 2135–2149.
- Huang, W.; Chen, W.; Poor, H.V. Request delay-based pricing for proactive caching: A stackelberg game approach. IEEE Trans. Wirel. Commun. 2019, 18, 2903–2918.
- Lin, Z.; Huang, W.; Chen, W. Bandwidth and storage efficient caching based on dynamic programming and reinforcement learning. IEEE Wirel. Commun. Lett. 2020, 9, 206–209.
- Hui, H.; Chen, W. A pricing-based joint scheduling of pushing and on-demand transmission over shared spectrum. In Proceedings of the 2020 IEEE Global Communications Conference (GLOBECOM 2020), Taipei, Taiwan, 7–11 December 2020; pp. 1–5.
- Chatzieleftheriou, L.E.; Karaliopoulos, M.; Koutsopoulos, I. Jointly optimizing content caching and recommendations in small cell networks. IEEE Trans. Mob. Comput. 2019, 18, 125–138.
- Zhu, B.; Chen, W. Coded caching with moderate recommendation: Balancing delivery rate and quality of experience. IEEE Wirel. Commun. Lett. 2019, 8, 1456–1459.
- Sermpezis, P.; Giannakas, T.; Spyropoulos, T.; Vigneri, L. Soft cache hits: Improving performance through recommendation and delivery of related content. IEEE J. Sel. Areas Commun. 2018, 36, 1300–1313.


