Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Chen, W. Heart Sounds Classification. Encyclopedia. Available online: https://encyclopedia.pub/entry/10501 (accessed on 28 June 2026).
Chen W. Heart Sounds Classification. Encyclopedia. Available at: https://encyclopedia.pub/entry/10501. Accessed June 28, 2026.
Chen, Wei. "Heart Sounds Classification" Encyclopedia, https://encyclopedia.pub/entry/10501 (accessed June 28, 2026).
Chen, W. (2021, June 04). Heart Sounds Classification. In Encyclopedia. https://encyclopedia.pub/entry/10501
Chen, Wei. "Heart Sounds Classification." Encyclopedia. Web. 04 June, 2021.
Copy Citation
The automated classification of heart sounds plays a significant role in the diagnosis of cardiovascular diseases (CVDs).
CVDs
CNN
deep learning
heart sounds classification
RNN
1. Introduction
With increasing industrialization, urbanization, and globalization, cardiovascular diseases (CVDs) are posing a serious threat to human health, causing the death of increasing numbers of people globally. Approximately 17.9 million people died from CVDs in 2016, accounting for 31% of all global deaths. Of these deaths, 85% resulted from heart attack and stroke [1]. CVDs exert a heavy burden on the finances of sufferers in low- and middle-income countries, and early detection and diagnosis are very significant to reducing the mortality rate. Cardiac auscultation is a simple, essential, and efficient method for examining CVDs and has a history of more than 180 years [2]. It is crucial to the early diagnosis of CVDs because of its noninvasiveness and good performance for reflecting the mechanical motion of the heart and cardiovascular system. However, cardiac auscultation requires substantial clinical experience and skill, and the human ear is not sensitive to sounds within all frequency ranges. The use of computers for the automatic analysis and classification of heart sound signals promises to afford substantial improvements in this area of human health management.
A heart sound is a kind of physiological signal, and its measurement is known as phonocardiography (PCG). It is produced by the heart systole and diastole and can reflect physiological information regarding body components such as the atria, ventricles, and large vessels, as well as their functional states [3]. In general, fundamental heart sounds (FHSs) can be classified as the first heart sounds and the second heart sounds, referred to as S1 and S2, respectively. S1 usually occurs at the beginning of isovolumetric ventricular contraction, when the already closed mitral and tricuspid valves suddenly reach their elastic limit due to the rapid pressure increase within the ventricles. S2 occurs at the beginning of the diastole when the aortic and pulmonic valves close.
It is important to segment the FHSs accurately and locate the state sequence of S1, the systole, S2, and the diastole. Figure 1 illustrates a PCG process with simultaneous electrocardiogram (ECG) recording and the four states of the PCG recording: S1, the systole, S2, and the diastole. The correspondence between the QRS waveform of the ECG and the heart sound signal is used to locate the S1 and S2 locations. FHSs provide important initial clues for heart disease evaluation in the process of further diagnostic examination. It is very important to extract the features from all parts of the FHS for quantitative analysis in the diagnosis of cardiac diseases. Within this framework, automatic heart sounds classification has attracted increased attention over the past few decades.
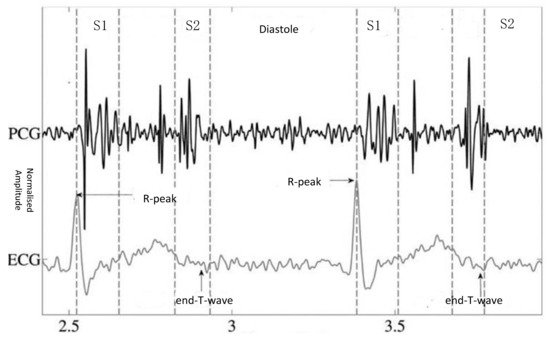
Figure 1. PCG with simultaneous ECG recording and the four states of the PCG recording: S1, the systole, S2, and the diastole [4].
Achieving high accuracy in automatic heart sounds classification algorithms has long been a pursuit of researchers. Popular heart sound signals classification methods can be divided into two major categories: traditional machine learning-based methods and deep learning-based methods. With the recent development of medical big data and artificial intelligence technology, there has been increased focus on the development of deep learning methods for heart sounds classification [5]. However, despite the significant achievements in the field, there are still challenges that require the development of more robust methods with higher performance for early CVD diagnosis.
The purpose of the present study was to perform an in-depth and systematic review and analysis of the latest deep learning-based heart sounds classification methods and provide a reference for future research in the field. To this end, we used keywords such as heart sounds, PCG, deep learning, classification, neural network, and phonocardiogram to download relevant publications related to heart sounds classification from the databases of ScienceDirect, SpringerLink, IEEEXplore, and Web of Science. Thirty-three of the studies obtained in this manner were shortlisted and considered for review. To the best of our knowledge, these studies included all the essential contributions to the application of deep learning to heart sounds classification. These studies are summarized in Table 1, and some of them are discussed in more detail in this paper. Their distribution, including the numbers of articles and conference papers, is also shown in Figure 2. It was observed that most of the deep learning-based methods for heart sounds classification were published within the last three years, and that the number of published papers had drastically increased in the last five years, reflecting the increasing popularity of deep learning in the field. To the best of our knowledge, this is the first review report that consolidates the findings on deep learning technologies for heart sounds classification.
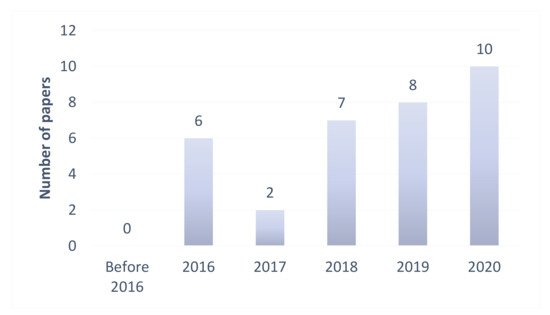
Figure 2. Previous studies on deep learning-based methods for heart sounds classification.
2. Process of Heart Sounds Classification
As illustrated in Figure 3, the automatic heart sounds classification process generally consists of four steps: denoising, segmentation, feature extraction, and classification.

Figure 3. Four steps of automatic heart sounds classification.
2.1. Denoising
The heart sounds acquisition process is easily affected by environmental interferences such as interference due to friction between the equipment and human skin, electromagnetic interference, and random noises such as breath sounds, lung sounds, and environment sounds [6]. The heart sound signals are usually coupled with these interference signals, and this necessitates the elimination of the out-of-band noise. The denoising significantly influences the segmentation, feature extraction, and final classification performances. The commonly used denoising methods are wavelet denoising, empirical mode decomposition denoising, and digital filter denoising [7]. Based on prior knowledge of heart sound signals, the construction of a wavelet basis function for heart sound signals is a new research direction in the area of heart sounds feature extraction [8].
2.2. Segmentation
The aim of the segmentation is the division of the PCG signals into four parts or segments: the first heart sounds (S1), systole, second heart sounds (S2), and diastole. Each segment contains efficient features that contribute to distinguishing the different categories of heart sounds. However, the duration of the heart beat cycle, the number of heart sounds, and the types of heart murmurs vary between individuals, and this causes the inaccurate segmentation of PCG signals. The segmentation of the FHSs is thus an essential step in automatic PCG analysis. The most commonly used heart sounds segmentation methods in recent years include envelope-based methods [9][10], ECG or carotid signal methods [11], probabilistic model methods [12][13][14][15], feature-based methods [16], and time–frequency analysis methods [17]. The utilized algorithms are based on the assumption that the diastolic period is longer than the systolic period. In fact, this assumption is not always true for an abnormal heart sound, especially in infants and cardiac patients [18]. Among these methods, those that utilize the cardiac cycle and an ECG signal, based on the correspondence between the ECG QRS waveform and the heart sound signals, have been found to yield better segmentation performance. However, their hardware and software requirements are greater. In addition, public heart sound databases rarely include synchronized ECG signals, which makes it difficult to segment the heart sound signals based on ECG signals.
2.3. Feature Extraction
Feature extraction is used to convert the raw high-dimensional heart sound signals into low-dimensional features through various mathematical transformations to facilitate the analysis of the heart sound signals. A variety of handcrafted features and machine learning-based methods have been applied for feature extraction, with the most common involving the use of Mel frequency cepstrum coefficients (MFCCs) [19][20], Mel domain filter coefficients (MFSCs), and heart sound spectra (spectrograms) [21], which are based on the short-time Fourier transform (STFT) and discrete wavelet transform (DWT) coefficients [18], and time and frequency features [22][23] from the time-domain, frequency-domain, and time–frequency or scale domain in the S1 and S2 components. The features extracted by STFT are difficult to balance with the time and frequency resolutions of the heart sound signals because the length of the window size impacts the resolution of the signals in both the time and frequency domains. Compared with these methods, the wavelet transform is more effective for the extraction of the main features of the heart sounds. Wavelet analysis has also been shown to afford high time and frequency resolutions and better representations of the S1 and S2 components [24].
2.4. Classification
Classification is used to divide the PCG signals into normal and abnormal categories. The utilized algorithms are of two main types: the first type of employed algorithms uses traditional machine learning methods such as artificial neural networks (ANNs), Gaussian mixture models, random forests, support vector machines (SVMs), and hidden Markov models (HMMs), which are applied to the extracted features to identify different heart sound signals symptomatic of different heart problems [5]; the other type of employed algorithms uses the latest popular deep learning methods such as deep CNNs and RNNs.
References
- WHO. Cardiovascular Diseases (CVDs) [EB/OL]. Available online: (accessed on 1 May 2020).
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213.
- Liu, C.; Murray, A. Applications of Complexity Analysis in Clinical Heart Failure. Complexity and Nonlinearity in Cardiovascular Signals; Springer: Berlin/Heidelberg, Germany, 2017.
- Springer, D.B.; Tarassenko, L.; Clifford, G.D. Logistic Regression-HSMM-Based Heart Sound Segmentation. IEEE Trans. Biomed. Eng. 2016, 63, 822.
- Dwivedi, A.K.; Imtiaz, S.A.; Rodriguez-Villegas, E. Algorithms for Automatic Analysis and Classification of Heart Sounds—A Systematic Review. IEEE Access 2019, 7, 8316–8345.
- Li, S.; Li, F.; Tang, S.; Xiong, W. A Review of Computer-Aided Heart Sound Detection Techniques. BioMed Res. Int. 2020, 2020, 1–10.
- Thalmayer, A.; Zeising, S.; Fischer, G.; Kirchner, J. A Robust and Real-Time Capable Envelope-Based Algorithm for Heart Sound Classification: Validation under Different Physiological Conditions. Sensors 2020, 20, 972.
- Kapen, P.T.; Youssoufa, M.; Kouam, S.U.K.; Foutse, M.; Tchamda, A.R.; Tchuen, G. Phonocardiogram: A robust algorithm for generating synthetic signals and comparison with real life ones. Biomed. Signal Process. Control 2020, 60, 101983.
- Giordano, N.; Knaflitz, M. A Novel Method for Measuring the Timing of Heart Sound Components through Digital Phonocardiography. Sensors 2019, 19, 1868.
- Wei, W.; Zhan, G.; Wang, X.; Zhang, P.; Yan, Y. A Novel Method for Automatic Heart Murmur Diagnosis Using Phonocardiogram. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing, AIAM, Dublin, Ireland, 16–18 October 2019; Volume 37, pp. 1–6.
- Malarvili, M.; Kamarulafizam, I.; Hussain, S.; Helmi, D. Heart sound segmentation algorithm based on instantaneous energy of electrocardiogram. Comput. Cardiol. 2003, 2003, 327–330.
- Oliveira, J.H.; Renna, F.; Mantadelis, T.; Coimbra, M.T. Adaptive Sojourn Time HSMM for Heart Sound Segmentation. IEEE J. Biomed. Health Inform. 2018, 23, 642–649.
- Kamson, A.P.; Sharma, L.; Dandapat, S. Multi-centroid diastolic duration distribution based HSMM for heart sound segmentation. Biomed. Signal Process. Control. 2019, 48, 265–272.
- Renna, F.; Oliveira, J.H.; Coimbra, M.T. Deep Convolutional Neural Networks for Heart Sound Segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 2435–2445.
- Liu, C.; Springer, D.; Clifford, G.D. Performance of an open-source heart sound segmentation algorithm on eight independent databases. Physiol. Meas. 2017, 38, 1730–1745.
- Chen, T.E.; Yang, S.I.; Ho, L.T.; Tsai, K.H.; Chen, Y.H.; Chang, Y.F.; Wu, C.C. S1 and S2 heart sound recognition using deep neural networks. IEEE Trans. Biomed. Eng. 2017, 64, 372–380.
- Liu, Q.; Wu, X.; Ma, X. An automatic segmentation method for heart sounds. Biomed. Eng. Online 2018, 17, 22–29.
- Deng, S.-W.; Han, J.-Q. Towards heart sound classification without segmentation via autocorrelation feature and diffusion maps. Future Gener. Comput. Syst. 2016, 60, 13–21.
- Abduh, Z.; Nehary, E.A.; Wahed, M.A.; Kadah, Y.M. Classification of Heart Sounds Using Fractional Fourier Transform Based Mel-Frequency Spectral Coefficients and Stacked Autoencoder Deep Neural Network. J. Med. Imaging Health Inf. 2019, 9, 1–8.
- Nogueira, D.M.; Ferreira, C.A.; Gomes, E.F.; Jorge, A.M. Classifying Heart Sounds Using Images of Motifs, MFCC and Temporal Features. J. Med Syst. 2019, 43, 168.
- Soeta, Y.; Bito, Y. Detection of features of prosthetic cardiac valve sound by spectrogram analysis. Appl. Acoust. 2015, 89, 28–33.
- Chakir, F.; Jilbab, A.; Nacir, C.; Hammouch, A. Phonocardiogram signals processing approach for PASCAL Classifying Heart Sounds Challenge. Signal Image Video Process. 2018, 12, 1149–1155.
- Potes, C.; Parvaneh, S.; Rahman, A.; Conroy, B. Ensemble of feature based and deep learning-based classifiers for detection of abnormal heart sounds. Proc. Comput. Cardiol. Conf. 2016, 621–624.
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw. 2020, 130, 22–32.
More
Information
Subjects:
Pharmacology & Pharmacy
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
988
Revisions:
2 times
(View History)
Update Date:
04 Jun 2021
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No