 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Thyago Celso Cavalcante Nepomuceno | + 696 word(s) | 696 | 2021-03-05 23:58:10 |
Video Upload Options
Data Envelopment Analysis (DEA) is a non-parametric methodology for measuring the efficiency of Decision Making Units (DMUs) using multiple inputs to outputs configurations. This is the most commonly used tool for frontier estimations in assessments of productivity and efficiency applied to all fields of economic activities.
Introduction[1]
Since the introduction of the CCR model by professors Abraham Charnes, William Cooper and Edwardo Rhodes in 1978[2], the way scholars investigate the efficiency and productivity of organizations shifted drastically. The so-called Data Envelopment Analysis (DEA) was different from statistical procedures comparing measures of performance based on an average observation. Based on Farrell's seminal work [3] on the measurement of productive efficiency, the problem of measuring the technical efficiency of Decision Making Units (DMUs) became a matter of how far production is expanded without using additional resources. Measuring the technical efficiency is made by comparing the DMU performance with a hypothetical unit constructed as a weighted average of other observed firms. The interpretation behind Farrell concepts is that if a decision unit can transform input resources into output production in a Pareto-efficient way (i.e. in such a way that there is no other configuration with more production at the same level of resources, or fewer resources resulting in the same level of production) then another unit with similar scale must be capable of producing similar results.
Data Envelopment Analysis is a very dynamic field, which importance has increased more and more over the past decades. Back in the 80s, the first decade of the DEA expansion was timid, restricted to basically two options: the constant [2] and (later) variable return to scale [4] models. Today, thousands of important models and empirical applications can be traced over several repositories. Daraio et al. (2020) [5] offer an interesting review on the many surveys of DEA empirical applications based on the UN standard classification for all the economic activities combined with the economic literature relevant concepts. According to the authors, the topics Banking, Investment, Financial Institutions, Health, Transportation and Agriculture are some of the fields having the greatest coverage by surveys of empirical assessments. In addition, computational developments are in continuous expansion. In addition, Daraio et al (2019) [6] investigate the 53 most used packages, software, solvers, web programs, libraries and language-based routines used to perform frontier models (DEA and SFA – Stochastic Frontier Analysis) of the productivity and efficiency analysis. This systematic survey highlights an increasing availability of open-source toolboxes and software for the implementation of many alternative DEA models. Other motivating and recent bibliometric reviews in the field can be found in Cook & Seiford (2009) [7],Lampe & Hilgers (2015) [8], Zhou & Xu (2020) [9] and Peykani et al. (2020) [10].
Methodology[1][7][11]
The Data Envelopment Analysis (DEA) methodology introduced by Abraham Charnes and colleagues estimates an efficiency frontier by considering the best performance observations (extreme points) which “envelop” the remaining observations using mathematical programming techniques. The concept of efficiency can be defined as a ratio of produced outputs to the used inputs:
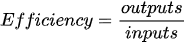
So that an inefficient unit can become efficient by expanding products (output) keeping the same level of used resources, or by reducing the used resources keep the same production level, or by a combination of both [11][12][13]
Considering j = 1, 2, 3, . m Decision Making Units (DMUs) using 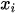
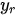
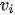
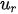
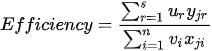
In Charnes et al. (1978) [2] DEA methodology the multipliers, and a measure for the technical efficiency for a specific DMU can be estimated by solving the fractional programming problem [7]:
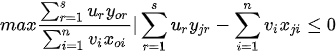
For all j, r and i, and strict positive
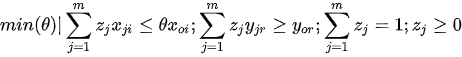
As a result, we have an efficiency score θ which varies from 0 to 1 designating the efficiency for each decision making unit. We can obtain the marginal contribution of each input and output in the multiplier model of (3), the peers of efficiency and respective weights in the primal (or envelopment) form of (4), and also the potential for improvements and slacks in an extension form of (4).
This entry refers to 10.1504/ijor.2020.10035180.
References
- Thyago Celso C. Nepomuceno; Ana Paula C. S. Costa; Cinzia Daraio; Theoretical and Empirical Advances in the Assessment of Productive Efficiency since the introduction of DEA: A Bibliometric Analysis. International Journal of Operational Research 2021, 1, xxx, 10.1504/ijor.2020.10035180.
- A. Charnes; W. W. Cooper; E. Rhodes; Measuring the efficiency of decision making units. European Journal of Operational Research 1978, 2, 429-444, 10.1016/0377-2217(78)90138-8.
- M. J. Farrell; The Measurement of Productive Efficiency. Journal of the Royal Statistical Society. Series A (General) 1956, 120, 253, 10.2307/2343100.
- R. D. Banker; A. Charnes; W. W. Cooper; Some Models for Estimating Technical and Scale Inefficiencies in Data Envelopment Analysis. Management Science 1984, 30, 1078-1092, 10.1287/mnsc.30.9.1078.
- Cinzia Daraio; Kristiaan Kerstens; Thyago Nepomuceno; Robin C. Sickles; Empirical surveys of frontier applications: a meta-review. International Transactions in Operational Research 2020, 27, 709-738, 10.1111/itor.12649.
- Cinzia Daraio; Kristiaan H.J. Kerstens; Thyago Celso Cavalcante Nepomuceno; Robin Sickles; PRODUCTIVITY AND EFFICIENCY ANALYSIS SOFTWARE: AN EXPLORATORY BIBLIOGRAPHICAL SURVEY OF THE OPTIONS. Journal of Economic Surveys 2019, 33, 85-100, 10.1111/joes.12270.
- Wade D. Cook; Larry M. Seiford; Data envelopment analysis (DEA) – Thirty years on. European Journal of Operational Research 2009, 192, 1-17, 10.1016/j.ejor.2008.01.032.
- Hannes W. Lampe; Dennis Hilgers; Trajectories of efficiency measurement: A bibliometric analysis of DEA and SFA. European Journal of Operational Research 2015, 240, 1-21, 10.1016/j.ejor.2014.04.041.
- Wei Zhou; Zeshui Xu; An Overview of the Fuzzy Data Envelopment Analysis Research and Its Successful Applications. International Journal of Fuzzy Systems 2020, 22, 1037-1055, 10.1007/s40815-020-00853-6.
- Pejman Peykani; Emran Mohammadi; Reza Farzipoor Saen; Seyed Jafar Sadjadi; Mohsen Rostamy-Malkhalifeh; Data envelopment analysis and robust optimization: A review. Expert Systems 2020, 37, e12534, 10.1111/exsy.12534.
- Sherman, H. D., & Zhu, J.; Data Envelopment Analysis Explained. Service Productivity Management 2006, 1, 49-89, 10.1007/0-387-33231-6_2.
- Thyago Celso Cavalcante Nepomuceno; Cinzia Daraio; Ana Paula Cabral Seixas Costa; Combining multi-criteria and directional distances to decompose non-compensatory measures of sustainable banking efficiency. Applied Economics Letters 2020, 27, 329-334, 10.1080/13504851.2019.1616051.
- Thyago Celso Cavalcante Nepomuceno; Katarina Tatiana Marques Santiago; Cinzia Daraio; Ana Paula Cabral Seixas Costa; Exogenous crimes and the assessment of public safety efficiency and effectiveness. Annals of Operations Research 2020, 1, 1-34, 10.1007/s10479-020-03767-6.

