Autonomous navigation is a very important area in the huge domain of mobile autonomous vehicles. Sensor integration is a key concept that is critical to the successful implementation of navigation. As part of this publication, we review the integration of Laser sensors like LiDAR with vision sensors like cameras. The past decade, has witnessed a surge in the application of sensor integration as part of smart-autonomous mobility systems. Such systems can be used in various areas of life like safe mobility for the disabled, disinfecting hospitals post Corona virus treatments, driver-less vehicles, sanitizing public areas, smart systems to detect deformation of road surfaces, to name a handful. These smart systems are dependent on accurate sensor information in order to function optimally. This information may be from a single sensor or a suite of sensors with the same or different modalities. We review various types of sensors, their data, and the need for integration of the data with each other to output the best data for the task at hand, which in this case is autonomous navigation. In order to obtain such accurate data, we need to have optimal technology to read the sensor data, process the data, eliminate or at least reduce the noise and then use the data for the required tasks. We present a survey of the current data processing techniques that implement integration of multimodal data from different types of sensors like LiDAR that use light scan technology, various types of Red Green Blue (RGB) cameras that use optical technology and review the efficiency of using fused data from multiple sensors rather than a single sensor in autonomous navigation tasks like mapping, obstacle detection, and avoidance or localization. This survey will provide sensor information to researchers who intend to accomplish the task of motion control of a robot and detail the use of LiDAR and cameras to accomplish robot navigation
- fusion
- information fusion
- data integration
- survey
- review
- RGB
- SLAM
- localization
- obstacle avoidance
- navigation
- deep learning
- neural networks
- LiDAR
- optical
- vision
- stereo vision
- autonomous systems
- data alignment
- robot
- mobile robot
- path planning
Introduction
Autonomous systems can play a vital role in assisting humans in a variety of problem areas. This could potentially be in a wide range of applications like driver-less cars, humanoid robots, assistive systems, domestic systems, military systems, and manipulator systems, to name a few. Presently, the world is at a bleeding edge of technologies that can enable this even in our daily lives. Assistive robotics is a crucial area of autonomous systems that helps persons who require medical, mobility, domestic, physical, and mental assistance. This research area is gaining popularity in applications like autonomous wheelchair systems [1,2], autonomous walkers [3], lawn movers [4,5], vacuum cleaners [6], intelligent canes [7], and surveillance systems in places like assisted living [8,9,10,11]. Data are one of the most important components to optimally start, continue, or complete any task. Often, these data are obtained from the environment that the autonomous system functions in; examples of such data could be the system’s position and location coordinates in the environment, the static objects, speed/velocity/acceleration of the system or its peers or any moving object in its vicinity, vehicle heading, air pressure, and so on. Since this is obtained directly from the operational environment, the information is up-to-date and can be accessed through either built-in or connected sensing equipment/devices. This survey is focused on the vehicle navigation of an autonomous vehicle. We review the past and present research using Light Imaging Detection and Ranging (LiDAR) and Imaging systems like a camera, which are laser and vision-based sensors, respectively. The autonomous systems use sensor data for tasks like object detection, obstacle avoidance, mapping, localization, etc. As we will see in the upcoming sections, these two sensors can complement each other and hence are being used extensively for detection in autonomous systems. The LiDAR market alone is expected to reach $52.5 Billion by the year 2032, as given in a recent survey by the Yole group, documented by the “First Sensors” group [12].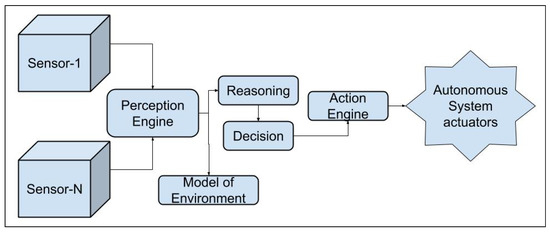
Data fusion
Sensors and their Input to Perception
Multiple Sensors vs. Single Sensor
Need for Sensor Data Fusion
Data Fusion Techniques
K-Means
Probabilistic Data Association (PDA)
PDA was proposed by Bar-Shalom and Tse, and it is also known by the "modified filter of all neighbors" [86]. The functionality is to assign an association probability to each hypothesis from the correct measurement of a destination/target and then process it. PDA is mainly good for tracking targets that do not make abrupt changes in their movement patternDistributed Multiple Hypothesis Test
State Estimation
Also known as tracking techniques, they assist with calculating the moving target's state, when measurements are given. These measurements are obtained using the sensors [87]. This is a fairly common technique in data fusion mainly for two reasons: (1) measurements are usually obtained from multiple sensors; and there could be noise in the measurements. Some examples are Kalman Filters, Extended Kalman Filters, Particle Filters, etcCovariance Consistency Methods
These methods were proposed initially by Uhlmann et al[84,87]. This is a distributed technique that maintains covariance estimations and means in a distributed system. They comprise of estimation-fusion techniques.Distributed Data Fusion
As the name suggests, this is a distributed fusion system and is often used in multi-agent systems, multisensor systems, and multimodal systems[84,94,95]. Efficient when distributed and decentralized systems are present. An optimum fusion can be achieved by adjusting the decision rules. However, there are difficulties in finalizing decision uncertainties.Decision Fusion Techniques
Hardware
LiDAR
Light Detection and Ranging (LiDAR) is a technology that is used in several autonomous tasks and functions as follows: an area is illuminated by a light source. The light is scattered by the objects in that scene and is detected by a photo-detector. The LiDAR can provide the distance to the object by measuring the time it takes for the light to travel to the object and back [104, 105, 106, 107, 108, 109 ].Camera
The types of cameras are Conventional color cameras like USB/web camera; RGB [115], RGB-mono, and RGB cameras with depth information; RGB-Depth (RGB-D), 360 degree camera [28,116,117,118], and Time-of-Flight (TOF)camera[119,120,121].Implementation of Data Fusion using a LiDAR and camera
- Geometric Alignment of the Sensor Data
- Resolution Match between the Sensor Data
Geometric Alignment of the Sensor Data
Resolution Match between the Sensor Data
Challenges with Sensor Data Fusion
Sensor data noise and rectification
Autonomous Navigation
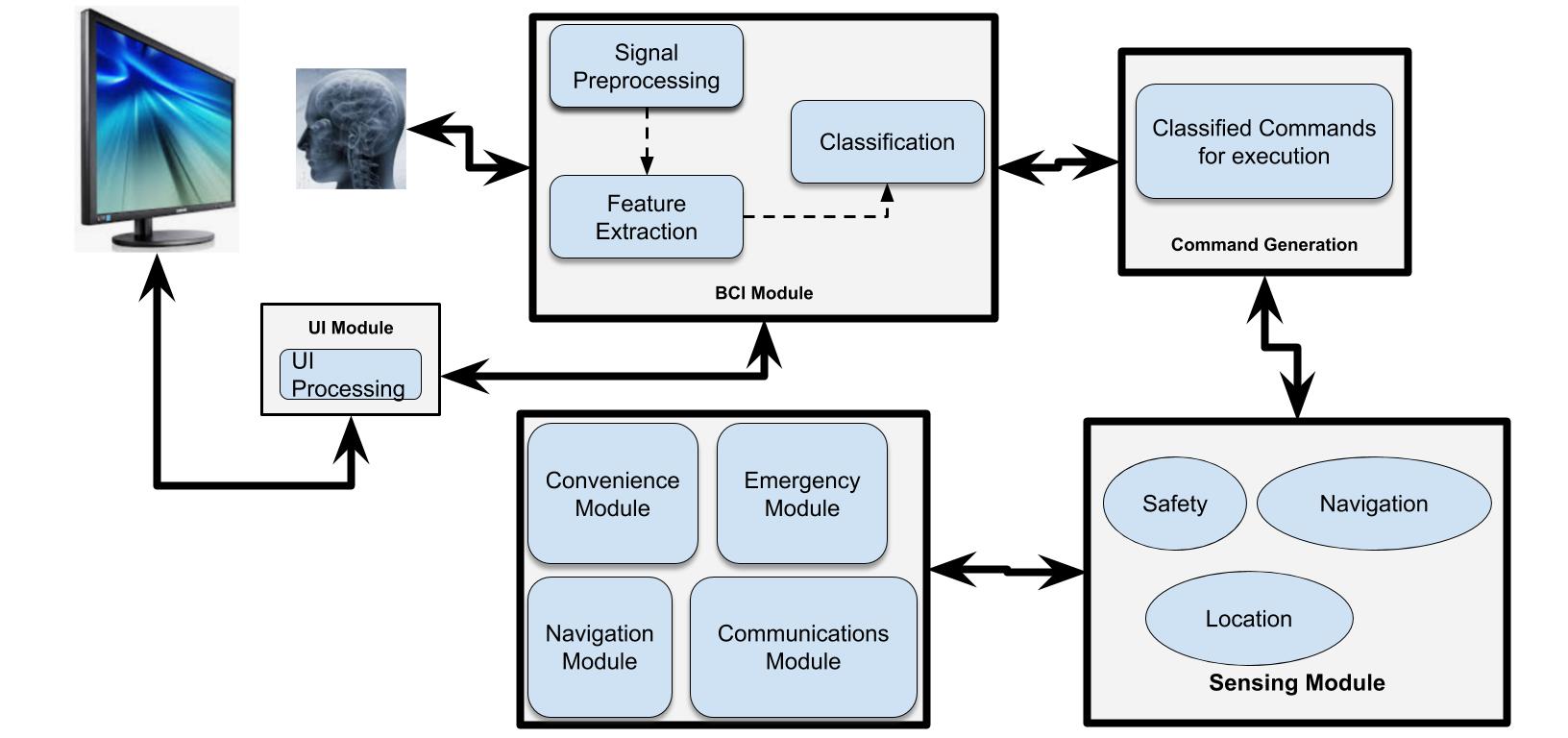
Robot navigation has been extensively studied in the community for several decades [161,162,163,164,165,166,167]. It can be termed as the safe mobility of the robot from a source location to a target location, without hurting people or properties in its environment, and without damaging itself, and these tasks are performed with no or limited need for a human operator. This means that the navigation system is also responsible for decision-making capability when the system faces situations (critical or otherwise) that demand negotiation with humans and/or other robots. Autonomous navigation is a task that takes in the output from a sensor data fusion module. Autonomous navigation means that a vehicle can plan its path and execute its plan without human intervention. An autonomous robot is one that not only can maintain its stability as it moves, but also can plan its movements. They use navigation aids when possible, but can also rely on visual, auditory, and olfactory cues. Decision-making relies on data fusion which comprises combining inputs from various sources to get a more accurate combined sensor data as output [35,38,44,51]. Figure 2 gives a simple sensor data fusion and its implementation in an autonomous dynamic model genrator. Sub-systems mapping, localization, path planning, and obstacle avoidance is detailed below.
Mapping
Localization
Path planning
Obstacle avoidance
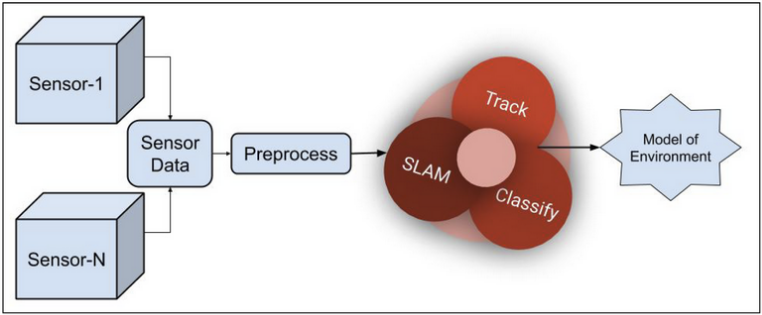
Integration of Sensor Data for Autonomous Navigation
 Figure 3. High-level Perception Architecture.
Figure 3. High-level Perception Architecture.Mapping
Localization
Path planning
Obstacle detection
In addition to cameras, LiDARs can be used to detect objects. A 3D point cloud is an output from the LiDAR. For efficient operation, the autonomous vehicle needs accurate data from each of its sensors. The reliability of the operation of an autonomous vehicle is hence proportional to the accuracy and hence the quality of the associated sensors. Each type of sensor has its limitations. Table \ref{fig:sensor_character} gives a comparison of the sensor types and their properties that are useful for navigation tasks [30,32,33,35,170].Applications of data fusion
Autonomous mobility systems
Pedestrian detection during autonomous vehicle navigation
Intelligent Agriculture
Conclusion
This entry is adapted from the peer-reviewed paper 10.3390/s20082180
References
- Kolar, Prasanna and Benavidez, Patrick and Jamshidi, Mo; Survey of Datafusion Techniques for Laser and Vision Based Sensor Integration for Autonomous Navigation. Sensors 2020, 20, 2180, .
- 2, Fehr, L.; Langbein, W.E.; Skaar, S.B. Adequacy of power wheelchair control interfaces for persons with severe disabilities: A clinical survey. J. Rehabil. Res. Dev. 2000, 37, 353–360. [Google Scholar] [PubMed]
- 3, Martins, M.M.; Santos, C.P.; Frizera-Neto, A.; Ceres, R. Assistive mobility devices focusing on smart walkers: Classification and review. Robot. Auton. Syst. 2012, 60, 548–562. [Google Scholar] [CrossRef]
- 4, Noonan, T.H.; Fisher, J.; Bryant, B. Autonomous Lawn Mower. U.S. Patent 5,204,814, 20 April 1993. [Google Scholar]
- 5, Bernini, F. Autonomous Lawn Mower with Recharge Base. U.S. Patent 7,668,631, 23 February 2010. [Google Scholar]
- 6, Ulrich, I.; Mondada, F.; Nicoud, J. Autonomous Vacuum Cleaner. Robot. Auton. Syst. 1997, 19. [Google Scholar] [CrossRef]
- 7, Mutiara, G.; Hapsari, G.; Rijalul, R. Smart guide extension for blind cane. In Proceedings of the 4th International Conference on Information and Communication Technology, Bandung, Indonesia, 25–27 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- 8, Bharucha, A.J.; Anand, V.; Forlizzi, J.; Dew, M.A.; Reynolds, C.F., III; Stevens, S.; Wactlar, H. Intelligent assistive technology applications to dementia care: current capabilities, limitations, and future challenges. Am. J. Geriatr. Psychiatry 2009, 17, 88–104. [Google Scholar] [CrossRef]
- 9, Cahill, S.; Macijauskiene, J.; Nygård, A.M.; Faulkner, J.P.; Hagen, I. Technology in dementia care. Technol. Disabil. 2007, 19, 55–60. [Google Scholar] [CrossRef]
- 10, Furness, B.W.; Beach, M.J.; Roberts, J.M. Giardiasis surveillance–United States, 1992–1997. MMWR CDC Surveill. Summ. 2000, 49, 1–13. [Google Scholar]
- 11, Topo, P. Technology studies to meet the needs of people with dementia and their caregivers: A literature review. J. Appl. Gerontol. 2009, 28, 5–37. [Google Scholar] [CrossRef]
- 12, First Sensors. Impact of LiDAR by 2032, 1. Available online: https://www.first-sensor.com/cms/upload/investor_relations/publications/First_Sensors_LiDAR_and_Camera_Strategy.pdf (accessed on 1 August 2019).
- 13, Crowley, J.L.; Demazeau, Y. Principles and techniques for sensor data fusion. Signal Process. 1993, 32, 5–27. [Google Scholar] [CrossRef]
- 14, Steinberg, A.N.; Bowman, C.L. Revisions to the JDL data fusion model. In Handbook of Multisensor Data Fusion; CRC Press: Boca Raton, FL, USA, 2017; pp. 65–88. [Google Scholar]
- 15, McLaughlin, D. An integrated approach to hydrologic data assimilation: interpolation, smoothing, and filtering. Adv. Water Resour. 2002, 25, 1275–1286. [Google Scholar] [CrossRef]
- 16, Van Mechelen, I.; Smilde, A.K. A generic linked-mode decomposition model for data fusion. Chemom. Intell. Lab. Syst. 2010, 104, 83–94. [Google Scholar] [CrossRef]
- 17, McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef] [PubMed]
- 18, Caputo, M.; Denker, K.; Dums, B.; Umlauf, G.; Konstanz, H. 3D Hand Gesture Recognition Based on Sensor Fusion of Commodity Hardware. In Mensch & Computer; Oldenbourg Verlag: München, Germany, 2012. [Google Scholar]
- 19, Lanckriet, G.R.; De Bie, T.; Cristianini, N.; Jordan, M.I.; Noble, W.S. A statistical framework for genomic data fusion. Bioinformatics 2004, 20, 2626–2635. [Google Scholar] [CrossRef] [PubMed]
- 20, Aerts, S.; Lambrechts, D.; Maity, S.; Van Loo, P.; Coessens, B.; De Smet, F.; Tranchevent, L.C.; De Moor, B.; Marynen, P.; Hassan, B.; et al. Gene prioritization through genomic data fusion. Nat. Biotechnol. 2006, 24, 537–544. [Google Scholar] [CrossRef] [PubMed]
- 21, Hall, D.L.; Llinas, J. An introduction to multisensor data fusion. Proc. IEEE 1997, 85, 6–23. [Google Scholar] [CrossRef]
- 22, Webster Sensor Definition. Merriam-Webster Definition of a Sensor. Available online: https://www.merriam-webster.com/dictionary/sensor (accessed on 9 November 2019).
- 27, Chavez-Garcia, R.O. Multiple Sensor Fusion for Detection, Classification and Tracking of Moving Objects in Driving Environments. Ph.D. Thesis, Université de Grenoble, Grenoble, France, 2014. [Google Scholar]
- 28, De Silva, V.; Roche, J.; Kondoz, A. Fusion of LiDAR and camera sensor data for environment sensing in driverless vehicles. arXiv 2018, arXiv:1710.06230v2. [Google Scholar]
- 30, Rövid, A.; Remeli, V. Towards Raw Sensor Fusion in 3D Object Detection. In Proceedings of the 2019 IEEE 17th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 24–26 January 2019; pp. 293–298. [Google Scholar] [CrossRef]
- 32, Wu, B.; Nevatia, R. Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors. In Proceedings of the Tenth IEEE International Conference on Computer Vision, ICCV 2005, Beijing, China, 17–20 October 2005; Volume 1, pp. 90–97. [Google Scholar]
- 33, Borenstein, J.; Koren, Y. Obstacle avoidance with ultrasonic sensors. IEEE J. Robot. Autom. 1988, 4, 213–218. [Google Scholar] [CrossRef]
- 35, Chavez-Garcia, R.O.; Aycard, O. Multiple Sensor Fusion and Classification for Moving Object Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2016, 17, 525–534. [Google Scholar] [CrossRef]
- 37, Baltzakis, H.; Argyros, A.; Trahanias, P. Fusion of laser and visual data for robot motion planning and collision avoidance. Mach. Vis. Appl. 2003, 15, 92–100. [Google Scholar] [CrossRef]
- 38, Luo, R.C.; Yih, C.C.; Su, K.L. Multisensor fusion and integration: Approaches, applications, and future research directions. IEEE Sens. J. 2002, 2, 107–119. [Google Scholar] [CrossRef]
- 39, Lahat, D.; Adali, T.; Jutten, C. Multimodal Data Fusion: An Overview of Methods, Challenges, and Prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef]
- 40, Shafer, S.; Stentz, A.; Thorpe, C. An architecture for sensor fusion in a mobile robot. In Proceedings of the 1986 IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 7–10 April 1986; Volume 3, pp. 2002–2011. [Google Scholar]
- 44, Waltz, E.; Llinas, J. Multisensor Data Fusion; Artech House: Boston, MA, USA, 1990; Volume 685. [Google Scholar]
- 45, Hackett, J.K.; Shah, M. Multi-sensor fusion: A perspective. In Proceedings of the 1990 IEEE International Conference on Robotics and Automation, Cincinnati, OH, USA, 13–18 May 1990; pp. 1324–1330. [Google Scholar]
- 46, Grossmann, P. Multisensor data fusion. GEC J. Technol. 1998, 15, 27–37. [Google Scholar]
- 47, Brooks, R.R.; Rao, N.S.; Iyengar, S.S. Resolution of Contradictory Sensor Data. Intell. Autom. Soft Comput. 1997, 3, 287–299. [Google Scholar] [CrossRef]
- 48, Vu, T.D. Vehicle Perception: Localization, Mapping with dEtection, Classification and Tracking of Moving Objects. Ph.D. Thesis, Institut National Polytechnique de Grenoble-INPG, Grenoble, France, 2009. [Google Scholar]
- 50, Bosse, E.; Roy, J.; Grenier, D. Data fusion concepts applied to a suite of dissimilar sensors. In Proceedings of the 1996 Canadian Conference on Electrical and Computer Engineering, Calgary, AL, Canada, 26–29 May 1996; Volume 2, pp. 692–695. [Google Scholar]
- 51, Jeon, D.; Choi, H. Multi-sensor fusion for vehicle localization in real environment. In Proceedings of the 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea, 13–16 October 2015; pp. 411–415. [Google Scholar]
- 57, Crowley, J.L. A Computational Paradigm for Three Dimensional Scene Analysis; Technical Report CMU-RI-TR-84-11; Carnegie Mellon University: Pittsburgh, PA, USA, 1984. [Google Scholar]
- 58, Crowley, J. Navigation for an intelligent mobile robot. IEEE J. Robot. Autom. 1985, 1, 31–41. [Google Scholar] [CrossRef]
- 59, Herman, M.; Kanade, T. Incremental reconstruction of 3D scenes from multiple, complex images. Artif. Intell. 1986, 30, 289–341. [Google Scholar] [CrossRef]
- 70, Ou, S.; Fagg, A.H.; Shenoy, P.; Chen, L. Application of reinforcement learning in multisensor fusion problems with conflicting control objectives. Intell. Autom. Soft Comput. 2009, 15, 223–235. [Google Scholar] [CrossRef]
- 84, Uhlmann, J.K. Covariance consistency methods for fault-tolerant distributed data fusion. Inf. Fusion 2003, 4, 201–215. [Google Scholar] [CrossRef]
- 86, Bar-Shalom, Y.; Willett, P.K.; Tian, X. Tracking and Data Fusion; YBS Publishing: Storrs, CT, USA, 2011; Volume 11. [Google Scholar]
- 87, Castanedo, F. A review of data fusion techniques. Sci. World J. 2013, 2013. [Google Scholar] [CrossRef]
- 90, Goeman, J.J.; Meijer, R.J.; Krebs, T.J.P.; Solari, A. Simultaneous control of all false discovery proportions in large-scale multiple hypothesis testing. Biometrika 2019, 106, 841–856. [Google Scholar] [CrossRef]
- 91, Olfati-Saber, R. Distributed Kalman filtering for sensor networks. In Proceedings of the 2007 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, 12–14 December 2007; pp. 5492–5498. [Google Scholar]
- 92, Zhang, Y.; Huang, Q.; Zhao, K. Hybridizing association rules with adaptive weighted decision fusion for personal credit assessment. Syst. Sci. Control Eng. 2019, 7, 135–142. [Google Scholar] [CrossRef]
- 93, Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef]
- 94, Chen, L.; Cetin, M.; Willsky, A.S. Distributed data association for multi-target tracking in sensor networks. In Proceedings of the IEEE Conference on Decision and Control, Plaza de España Seville, Spain, 12–15 December 2005. [Google Scholar]
- 95, Dwivedi, R.; Dey, S. A novel hybrid score level and decision level fusion scheme for cancelable multi-biometric verification. Appl. Intell. 2019, 49, 1016–1035. [Google Scholar] [CrossRef]
- 96, Dasarathy, B.V. Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc. IEEE 1997, 85, 24–38. [Google Scholar] [CrossRef]
- 104, NOAA. What Is LiDAR? Available online: https://oceanservice.noaa.gov/facts/lidar.html (accessed on 19 March 2020).
- 105, Yole Developpement, W. Impact of LiDAR by 2032, 1. The Automotive LiDAR Market. Available online: http://www.woodsidecap.com/wp-content/uploads/2018/04/Yole_WCP-LiDAR-Report_April-2018-FINAL.pdf (accessed on 23 March 2020).
- 106, Kim, W.; Tanaka, M.; Okutomi, M.; Sasaki, Y. Automatic labeled LiDAR data generation based on precise human model. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 43–49. [Google Scholar]
- 107, Miltiadou, M.; Michael, G.; Campbell, N.D.; Warren, M.; Clewley, D.; Hadjimitsis, D.G. Open source software DASOS: Efficient accumulation, analysis, and visualisation of full-waveform lidar. In Proceedings of the Seventh International Conference on Remote Sensing and Geoinformation of the Environment (RSCy2019), International Society for Optics and Photonics, Paphos, Cyprus, 18–21 March 2019; Volume 11174, p. 111741. [Google Scholar]
- 108, Hu, P.; Huang, H.; Chen, Y.; Qi, J.; Li, W.; Jiang, C.; Wu, H.; Tian, W.; Hyyppä, J. Analyzing the Angle Effect of Leaf Reflectance Measured by Indoor Hyperspectral Light Detection and Ranging (LiDAR). Remote Sens. 2020, 12, 919. [Google Scholar] [CrossRef]
- 109, Warren, M.E. Automotive LIDAR technology. In Proceedings of the 2019 Symposium on VLSI Circuits, Kyoto, Japan, 9–14 June 2019; pp. C254–C255. [Google Scholar]
- 115, igi global. RGB Camera Details. Available online: https://www.igi-global.com/dictionary/mobile-applications-for-automatic-object-recognition/60647 (accessed on 2 February 2020).
- 116, Sigel, K.; DeAngelis, D.; Ciholas, M. Camera with Object Recognition/data Output. U.S. Patent 6,545,705, 8 April 2003. [Google Scholar]
- 117, De Silva, V.; Roche, J.; Kondoz, A. Robust fusion of LiDAR and wide-angle camera data for autonomous mobile robots. Sensors 2018, 18, 2730. [Google Scholar] [CrossRef] [PubMed]
- 118, Guy, T. Benefits and Advantages of 360° Cameras. Available online: https://www.threesixtycameras.com/pros-cons-every-360-camera/ (accessed on 10 January 2020).
- 119, Myllylä, R.; Marszalec, J.; Kostamovaara, J.; Mäntyniemi, A.; Ulbrich, G.J. Imaging distance measurements using TOF lidar. J. Opt. 1998, 29, 188–193. [Google Scholar] [CrossRef]
- 120, Nair, R.; Lenzen, F.; Meister, S.; Schäfer, H.; Garbe, C.; Kondermann, D. High accuracy TOF and stereo sensor fusion at interactive rates. In Proceedings of the ECCV: European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Volume 7584, pp. 1–11. [Google Scholar] [CrossRef]
- 121, Hewitt, R.A.; Marshall, J.A. Towards intensity-augmented SLAM with LiDAR and ToF sensors. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1956–1961. [Google Scholar] [CrossRef]
- 126, Maddern, W.; Newman, P. Real-time probabilistic fusion of sparse 3d lidar and dense stereo. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2181–2188. [Google Scholar]
- 133, Crowley, J.; Ramparany, F. Mathematical tools for manipulating uncertainty in perception. In Proceedings of the AAAI Workshop on Spatial Reasoning and Multi-Sensor Fusion, St. Charles, IL, USA, 5–7 October 1987. [Google Scholar]
- 134, Jing, L.; Wang, T.; Zhao, M.; Wang, P. An adaptive multi-sensor data fusion method based on deep convolutional neural networks for fault diagnosis of planetary gearbox. Sensors 2017, 17, 414. [Google Scholar] [CrossRef]
- 161, Waxman, A.; Moigne, J.; Srinivasan, B. Visual navigation of roadways. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 862–867. [Google Scholar]
- 162, Delahoche, L.; Pégard, C.; Marhic, B.; Vasseur, P. A navigation system based on an ominidirectional vision sensor. In Proceedings of the 1997 IEEE/RSJ International Conference on Intelligent Robot and Systems, Innovative Robotics for Real-World Applications, IROS’97, Grenoble, France, 11 September1997; Volume 2, pp. 718–724. [Google Scholar]
- 163, Zingaretti, P.; Carbonaro, A. Route following based on adaptive visual landmark matching. Robot. Auton. Syst. 1998, 25, 177–184. [Google Scholar] [CrossRef]
- 164, Research, B. Global Vision and Navigation for Autonomous Vehicle.
- 165, Thrun, S. Robotic Mapping: A Survey; CMU-CS-02–111; Morgan Kaufmann Publishers: Burlington, MA, USA, 2002. [Google Scholar]
- 166, Thorpe, C.; Hebert, M.H.; Kanade, T.; Shafer, S.A. Vision and navigation for the Carnegie-Mellon Navlab. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 362–373. [Google Scholar] [CrossRef]
- 167, Zimmer, U.R. Robust world-modelling and navigation in a real world. Neurocomputing 1996, 13, 247–260. [Google Scholar] [CrossRef]
- 170, Danescu, R.G. Obstacle detection using dynamic Particle-Based occupancy grids. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, QLD, Australia, 6–8 December 2011; pp. 585–590. [Google Scholar]
- 171, Leibe, B.; Seemann, E.; Schiele, B. Pedestrian detection in crowded scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 878–885. [Google Scholar]
- 172, Lwowski, J.; Kolar, P.; Benavidez, P.; Rad, P.; Prevost, J.J.; Jamshidi, M. Pedestrian detection system for smart communities using deep Convolutional Neural Networks. In Proceedings of the 2017 12th System of Systems Engineering Conference (SoSE), Waikoloa, HI, USA, 18–21 June 2017; pp. 1–6. [Google Scholar]
- 173, Kortenkamp, D.; Weymouth, T. Topological mapping for mobile robots using a combination of sonar and vision sensing. Proc. AAAI 1994, 94, 979–984. [Google Scholar]
- 176, Thrun, S.; Bücken, A. Integrating grid-based and topological maps for mobile robot navigation. In Proceedings of the National Conference on Artificial Intelligence, Oregon, Portland, 4–8 August 1996; pp. 944–951. [Google Scholar]
- 180, Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef]
- 188, Fernández-Madrigal, J.A. Simultaneous Localization and Mapping for Mobile Robots: Introduction and Methods: Introduction and Methods; IGI Global: Philadelphia, PA, USA, 2012. [Google Scholar]
- 190, Leonard, J.J.; Durrant-Whyte, H.F.; Cox, I.J. Dynamic map building for an autonomous mobile robot. Int. J. Robot. Res. 1992, 11, 286–298. [Google Scholar] [CrossRef]
- 198, Huang, S.; Dissanayake, G. Robot Localization: An Introduction. In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons: New York, NY, USA, 1999; pp. 1–10. [Google Scholar]
- 199, Huang, S.; Dissanayake, G. Convergence and consistency analysis for extended Kalman filter based SLAM. IEEE Trans. Robot. 2007, 23, 1036–1049. [Google Scholar] [CrossRef]
- 200, Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of wireless indoor positioning techniques and systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- 201, Leonard, J.J.; Durrant-Whyte, H.F. Mobile robot localization by tracking geometric beacons. IEEE Trans. Robot. Autom. 1991, 7, 376–382. [Google Scholar] [CrossRef]
- 202, Betke, M.; Gurvits, L. Mobile robot localization using landmarks. IEEE Trans. Robot. Autom. 1997, 13, 251–263. [Google Scholar] [CrossRef]
- 205, Ojeda, L.; Borenstein, J. Personal dead-reckoning system for GPS-denied environments. In Proceedings of the IEEE International Workshop on Safety, Security and Rescue Robotics, SSRR 2007, Rome, Italy, 27–29 September 2007; pp. 1–6. [Google Scholar]
- 206, Levi, R.W.; Judd, T. Dead Reckoning Navigational System Using Accelerometer to Measure Foot Impacts. U.S. Patent 5,583,776, 1996. [Google Scholar]
- 207, Elnahrawy, E.; Li, X.; Martin, R.P. The limits of localization using signal strength: A comparative study. In Proceedings of the 2004 First Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, Santa Clara, CA, USA, 4–7 October 2004; pp. 406–414. [Google Scholar]
- 212, Howell, E.; NAV Star. Navstar: GPS Satellite Network. Available online: https://www.space.com/19794-navstar.html (accessed on 1 August 2019).
- 213, Robotics, A. Experience the New Mobius. Available online: https://www.asirobots.com/platforms/mobius/ (accessed on 1 August 2019).
- 214, Choi, B.S.; Lee, J.J. Sensor network based localization algorithm using fusion sensor-agent for indoor service robot. IEEE Trans. Consum. Electron. 2010, 56, 1457–1465. [Google Scholar] [CrossRef]
- 215, Ramer, C.; Sessner, J.; Scholz, M.; Zhang, X.; Franke, J. Fusing low-cost sensor data for localization and mapping of automated guided vehicle fleets in indoor applications. In Proceedings of the 2015 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), San Diego, CA, USA, 14–16 September 2015; pp. 65–70. [Google Scholar]
- 217, Wan, K.; Ma, L.; Tan, X. An improvement algorithm on RANSAC for image-based indoor localization. In Proceedings of the 2016 International Conference on Wireless Communications and Mobile Computing Conference (IWCMC), An improvement algorithm on RANSAC for image-based indoor localization, Paphos, Cyprus, 5–9 September 2016; pp. 842–845. [Google Scholar]
- 218, Biswas, J.; Veloso, M. Depth camera based indoor mobile robot localization and navigation. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 1697–1702. [Google Scholar]
- 219, Vive, W.H. HTC Vive Details. Available online: https://en.wikipedia.org/wiki/HTC_Vive (accessed on 1 August 2019).
- 220, Buniyamin, N.; Ngah, W.W.; Sariff, N.; Mohamad, Z. A simple local path planning algorithm for autonomous mobile robots. Int. J. Syst. Appl. Eng. Dev. 2011, 5, 151–159. [Google Scholar]
- 221, Popović, M.; Vidal-Calleja, T.; Hitz, G.; Sa, I.; Siegwart, R.; Nieto, J. Multiresolution mapping and informative path planning for UAV-based terrain monitoring. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1382–1388. [Google Scholar]
- 222, Laghmara, H.; Boudali, M.; Laurain, T.; Ledy, J.; Orjuela, R.; Lauffenburger, J.; Basset, M. Obstacle Avoidance, Path Planning and Control for Autonomous Vehicles. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 529–534. [Google Scholar]
- 223, Rashid, A.T.; Ali, A.A.; Frasca, M.; Fortuna, L. Path planning with obstacle avoidance based on visibility binary tree algorithm. Robot. Auton. Syst. 2013, 61, 1440–1449. [Google Scholar] [CrossRef]
- 244, Wang, C.C.; Thorpe, C.; Thrun, S.; Hebert, M.; Durrant-Whyte, H. Simultaneous localization, mapping and moving object tracking. Int. J. Robot. Res. 2007, 26, 889–916. [Google Scholar] [CrossRef]
- 245, Saunders, J.; Call, B.; Curtis, A.; Beard, R.; McLain, T. Static and dynamic obstacle avoidance in miniature air vehicles. In Infotech@ Aerospace; BYU ScholarsArchive; BYU: Provo, UT, USA, 2005; p. 6950. [Google Scholar]
- 246, Chu, K.; Lee, M.; Sunwoo, M. Local path planning for off-road autonomous driving with avoidance of static obstacles. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1599–1616. [Google Scholar] [CrossRef]
- 257, Zhang, X.; Rad, A.B.; Wong, Y.K. A robust regression model for simultaneous localization and mapping in autonomous mobile robot. J. Intell. Robot. Syst. 2008, 53, 183–202. [Google Scholar] [CrossRef]
- 260, Wang, X. A Driverless Vehicle Vision Path Planning Algorithm for Sensor Fusion. In Proceedings of the 2019 IEEE 2nd International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 22–24 November 2019; pp. 214–218. [Google Scholar]
- 261, Ali, M.A.; Mailah, M. Path planning and control of mobile robot in road environments using sensor fusion and active force control. IEEE Trans. Veh. Technol. 2019, 68, 2176–2195. [Google Scholar] [CrossRef]
- 264, Sabe, K.; Fukuchi, M.; Gutmann, J.S.; Ohashi, T.; Kawamoto, K.; Yoshigahara, T. Obstacle avoidance and path planning for humanoid robots using stereo vision. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA’04), New Orleans, LA, USA, 26 April–1 May 2004; Volume 1, pp. 592–597. [Google Scholar]
- 268, Dan, B.K.; Kim, Y.S.; Jung, J.Y.; Ko, S.J.; et al. Robust people counting system based on sensor fusion. IEEE Trans. Consum. Electron. 2012, 58, 1013–1021. [Google Scholar] [CrossRef]
- 269, Pacha, A. Sensor Fusion for Robust Outdoor Augmented Reality Tracking on Mobile Devices; GRIN Verlag: München, Germany, 2013. [Google Scholar]
- 270, Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Online multiperson tracking-by-detection from a single, uncalibrated camera. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1820–1833. [Google Scholar] [CrossRef]
- 271, Stein, G. Barrier and Guardrail Detection Using a Single Camera. U.S. Patent 9,280,711, 8 March 2016. [Google Scholar]
- 272, Boreczky, J.S.; Rowe, L.A. Comparison of video shot boundary detection techniques. J. Electron. Imag. 1996, 5, 122–129. [Google Scholar] [CrossRef]
- 273, Sheikh, Y.; Shah, M. Bayesian modeling of dynamic scenes for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1778–1792. [Google Scholar] [CrossRef] [PubMed]
- 274, John, V.; Long, Q.; Xu, Y.; Liu, Z.; Mita, S. Sensor Fusion and Registration of Lidar and Stereo Camera without Calibration Objects. IEICE TRANSACTIONS Fundam. Electron. Commun. Comput. Sci. 2017, 100, 499–509. [Google Scholar] [CrossRef]
- Kolar, Prasanna and Benavidez, Patrick and Jamshidi, Mo; Survey of Datafusion Techniques for Laser and Vision Based Sensor Integration for Autonomous Navigation. Sensors 2020, 20, 2180, .