Deep learning (DL) has been applied successfully in medical imaging [
10,
11] such as reconstruction [
12], classification [
13], segmentation [
14], and detection [
15]. Conventional feature-extraction approaches require human intervention, and DL directly analyzes the image data. DL-based MRI reconstruction strategies could enhance the flexibility without lessening the image quality. The advantages of deep learning in MRI image reconstruction include the improved reconstruction speed, reduced artifacts, and enhanced image quality, but there are still issues with speed and accuracy. It is also necessary to conduct more research to comprehend the underlying mechanisms of this method. This paper provides a thorough summary of current developments in deep MRI reconstruction to identify these difficulties. In addition, this study examines the field’s opportunities and problems and provides insights into its potential future growth. This review intends to improve knowledge of deep MRI reconstruction and provide an outline for potential studies in this area. However, few studies have reviewed DL-based applications for MRI. Ahishakiye et al. [
16] gathered records using DL, image reconstruction, medical imaging, open software, and open imaging data keywords. Montalt-Tordera et al. [
17] described existing machine learning (ML) algorithms and their clinical applications. Zhang et al. [
18] focused on the mathematical expression of DL algorithms. He et al. [
19] analyzed the performance of several contemporary unsupervised learning algorithms, and Knoll et al. [
20] reviewed the most significant ML algorithms for parallel imaging based on linear and non-linear approaches.
2. DL Architectures
Deep neural networks (DNNs) are used for medical-image reconstruction, quality enhancement, feature mapping, contrast transformation, classification of tumors or cancer types, and segmentation for detecting normal and abnormal tissues. Deep architectures can extract features from data in place of conventional hand-crafting feature extraction algorithms. DL can reconstruct high-quality images from undersampled data via discovering complex mappings using undersampled k-space data and fully sampled images. Several DL architectures used for MRI reconstruction are described below.
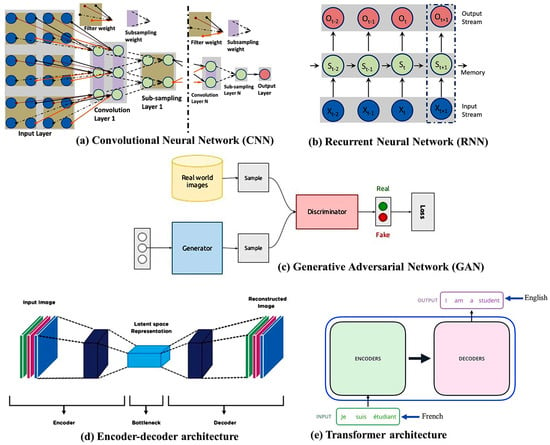
A convolutional neural network (CNN) [
23] (
Figure 1a) is an efficient approach to DNNs that is particularly effective in image processing and computer vision (CV) tasks. It consists of a set of convolutional layers and applies convolution operations to the input data. These operations involve sliding small filters (kernels) over the input image to learn local features. Through these convolution operations, the network captures low-level features (e.g., edges, textures) in the early layers and progressively more abstract and complex features in the deeper layers. The convolutional layers produce feature maps that represent learned patterns and features in the input data. Thus, CNNs automatically learn hierarchical representations of features in images, making them well-suited for tasks related to images and videos. CNNs have been widely successful in tasks such as image reconstruction, classification, object detection, and segmentation. Google, Microsoft, and Facebook have established research groups to examine novel CNN designs [
24]. A CNN deals with raw images and, in some cases, minimizes the data pre-processing tasks. The AlexNet [
25], ResNet [
26], Squeeze-MNet [
27], and Unet [
28] networks are typically used in computer vision tasks. However, a CNN needs a large dataset and several layers to understand the global context or relationships between latent features in an image [
29].
Figure 1. Several deep neural network architectures.
A recurrent neural network (RNN) [
30] (
Figure 1b) is a type of artificial neural network (ANN) in which the connections between nodes create a directed graph over time, which is used in sequential data processing. In general, RNNs are applied to sequential data, but they are not the primary choice for sequential image processing. Images are spatial data and the sequential dependencies in pixel values vary across an image. In this case, image data are treated as a time series (e.g., frames of a medical imaging sequence), and RNNs are applied to capture temporal dependencies and variations over time. In MRI reconstruction, RNNs are employed to dynamically adjust the sampling pattern during the acquisition process. However, RNNs are prone to vanishing and exploding gradient problems during training. Long sequences can result in vanishing gradients, where the gradients become very small and hinder learning. Conversely, exploding gradients can cause instability during training. Recently, advanced recurrent architectures, such as long short-term memory (LSTM) and gated recurrent units (GRUs) have been developed to address some of the issues associated with traditional RNNs. Deep RNNs [
31] and ConvLSTM [
32] models are typically used for image reconstruction and classification.
A generative adversarial network (GAN) [
33] (
Figure 1c) is more realistic than a CNN and does not require pre-processing. Conversely, this model is more complex than other models, e.g., CNNs and RNNs. A GAN comprises a discriminator and a generator. Given a random variable input, the generator produces data samples. The probability of a particular sample coming from the true dataset is estimated by the discriminator. In the context of MRI reconstruction, GANs can be used to generate realistic and high-quality images from undersampled or noisy MRI data. The generator learns to fill in missing information, generating images that closely resemble the fully sampled counterparts. The discriminator plays a crucial role in distinguishing between generated (reconstructed) images and real images. The discriminator’s objective is to minimize the binary cross-entropy loss function. It learns to assign high probabilities to real images and low probabilities to generated images. The loss is backpropagated through the discriminator to update its parameters. However, training GANs can be unstable, and finding the right balance between the generator and discriminator can be challenging. The training process is sensitive to hyperparameters, and achieving convergence can be difficult. RadialGAN [
34] and StarGAN [
35] are the most popular GAN architectures.
Encoder–decoder architectures [
36] (
Figure 1d) are indeed a common and powerful design pattern in various DL applications, including computer vision and natural language processing. These architectures are particularly prevalent in tasks that involve transforming one type of data into another, such as image-to-image translation, sequence-to-sequence tasks, and generative models. The general structure of an encoder–decoder architecture consists of two main components. These encoder–decoder architectures showcase the flexibility and adaptability of the framework for various image reconstruction tasks. Depending on the specific requirements of a task, researchers and practitioners choose or design architectures that best suit the characteristics of the data and the goals of the reconstruction. These architectures are designed to learn the mapping between undersampled or corrupted MRI data and fully sampled or high-quality images. Variations of these architectures [
37] are commonly used in the field of medical imaging for tasks like MRI denoising, super-resolution, and artifact correction. However, encoder–decoder architectures may lose fine details during the encoding and decoding process. This can be problematic for tasks that require precise details, such as fine-grained image generation. A variational autoencoder (VAE) [
38] is used for MRI reconstruction.
The transformer [
39] (
Figure 1e) was developed recently and is popular in natural language processing (NLP) based on its even-deeper mapping, sequence-to-sequence model design and adaptive self-attention. Unlike traditional RNN-based models, which process the input sequence sequentially, the transformer is able to process the entire sequence in parallel. The transformer consists of two main modules: the encoder and the decoder. The encoder discovers the input sequence and generates a set of hidden representations, while the decoder uses those representations to generate the output sequence. Both the encoder and the decoder consist of multiple layers of self-attention and feedforward neural networks. One of the key advantages of the transformer is its ability to handle long-range dependencies in the input sequence and its computational efficiency. It has been used for image analysis in terms of object detection [
40] and image recognition [
41]. The transformer is used in MRI in a variety of ways [
42], given its superior capability in image reconstruction and synthesis, as shown in natural images. However, transformers involve a quadratic self-attention mechanism, making them computationally expensive for large inputs. This complexity can be a limitation, particularly when dealing with high-resolution images.
3. DL Tools
DL tools are used to develop models for generating good results. Several popular open-access DL tools used in MRI processing are listed in Table 1. Among them, TensorFlow and PyTorch are widely used.
Table 1. Deep learning tools.
4. Network Training Strategies
4.1. Supervised and Unsupervised Learning
Supervised learning is a common technique used in medical image analysis, including the analysis of MRI data. In supervised learning, a machine learning model is trained on a labeled dataset, where each input (in this case, an MRI image) is associated with a corresponding output (typically, a label or annotation). The model learns to map inputs to outputs by identifying patterns and relationships in the training data. Supervised learning in MRI has been applied to a wide range of tasks, including tumor detection and segmentation, disease classification, image registration, and more. It has the potential to significantly enhance the accuracy and efficiency of medical image analysis. However, it also requires large and high-quality labeled datasets and careful validation to ensure its reliability in clinical practice.
Unlike supervised learning, where the algorithm is provided with labeled training data (input–output pairs), unsupervised learning [
56] involves working with unlabeled data. The goal of this learning is to find patterns, structures, or representations in the data without specific guidance regarding the output. Unsupervised learning methods [
57,
58] are particularly valuable when dealing with large and complex MRI datasets, as they can reveal hidden structures and patterns within the data without the need for extensive manual labeling. Real-time 3D MRI reconstruction from cine-MRI using unsupervised networks involves leveraging neural networks to reconstruct dynamic 3D MRI volumes from a sequence of 2D images acquired over time (cine-MRI) [
59]. However, the interpretation of the results obtained from unsupervised learning can be more challenging and often requires domain expertise to make meaningful clinical inferences. These methods are an essential part of the toolkit for researchers and clinicians working with MRI data.
Semi-supervised learning [
60] is a machine learning paradigm that combines elements of both supervised and unsupervised learning. It is particularly useful when you have access to a small amount of labeled data and a large amount of unlabeled data. It is especially valuable in scenarios where acquiring large amounts of labeled data is challenging. This learning can leverage the available labeled data to improve the model performance on tasks such as classification, segmentation, or regression. Semi-supervised learning in MRI analysis offers the advantage of leveraging both labeled and unlabeled data to enhance model performance. By combining the strengths of supervised and unsupervised learning, semi-supervised approaches have the potential to improve the accuracy and robustness of MRI-based diagnostic and analysis tasks.
Self-supervised learning [
61] is an emerging and powerful technique for training machine learning models, especially in scenarios where obtaining labeled data is challenging or expensive. Self-supervised learning is a type of unsupervised learning where the data itself provide supervision for training. This learning in MRI analysis leverages the inherent structure and properties of MRI data to guide the training process, making it a valuable approach for improving the quality of MRI images, enhancing data availability, and addressing various challenges in MRI research and clinical applications. It is an area of active research with the potential to significantly impact the field of medical imaging.
4.2. Transfer Learning
Transfer learning (TL) [
62] is the process of learning a new activity more effectively by transferring the knowledge acquired in one or more source tasks and applying it to the learning of a related target task. The development of methods for knowledge transfer is a step toward making ML as effective as human learning. Using information from the source task, TL aims to enhance learning in the target task. To improve DL network performance, the model complexity is typically increased by raising the architecture’s numbers of layers and nodes. Multiple model parameters must be accurately learned using a large amount of training data. The performance of a model’s reconstruction is typically improved by adding training data. However, because preserving k-space data is not part of the typical clinical flow, it is challenging to obtain patient raw data for training the network. Consequently, the generalizability of a network based on a few samples needs to be improved.
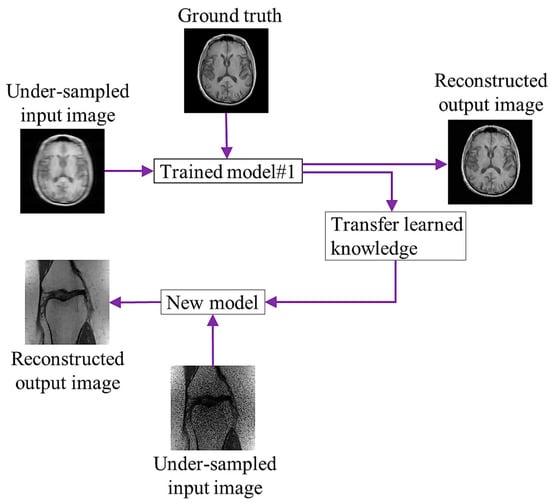
Figure 2 shows a diagram of TL, in which the trained model uses the input and reference brain images for learning. After training, it shares the learning knowledge (weights) with a different model to reconstruct an image of a knee.
Figure 2. Concept of transfer learning.
A TL strategy addresses the lack of data issues during network training for rapid MRI [
63]. For single-channel MRI reconstruction, Arshad et al. [
64] assessed a trained Unet on MRIs with different magnetic field strengths, anatomical variations, and undersampling masks. However, none of the studies described above have made use of the generalization ability of multi-channel MRI reconstruction models. The generalizability of a TL-based model for sub-sampled multi-channel MRI reconstruction using GAN has been evaluated [
65,
66]. Park et al. [
67] reported a blended TL technique for both the pre-training and target compressed cardiac cine MRI datasets to mitigate data-privacy concerns. Dynamic dictionaries based on the TL approach [
68] employed a limited number of training samples and prior knowledge about the unknown signal to precisely rebuild the image by transferring the existing sample information to the unknown sample. By learning the relationship between the navigator and data slices, Gulamhussene et al. [
69] suggested a unique time-resolved four-dimensional (4D) MRI framework based on the same acquisition scheme. In TL, network training is carried out in a domain with many accessible datasets, and information obtained by the trained network is subsequently transferred to a different domain with undersampled data. However, the performance of TL depends on the availability of diverse and representative data during pre-training. If the pre-training data lack diversity in terms of the imaging conditions, patient demographics, or pathology, the transferred knowledge may not effectively address the complexities of the target MRI reconstruction task.
4.3. Federated Learning
Deep networks frequently need large amounts of diversely matched data, which can be labor- and cost-intensive to obtain. Furthermore, retaining patients’ data raises privacy concerns, making it challenging to share the information with other institutions. This problem is addressed by the recently developed FL framework [
70], which enables the cooperative and distributed training of DL-based techniques. In FL, data are stored locally, and statistical models are trained across segmented data centers or remote devices, e.g., smartphones or hospitals. The training of diverse and possibly large networks poses unexpected problems that call for a fundamental change from conventional methods for large-scale DL, remote optimization, and confidentiality data analysis. To create a global model, a cloud server communicates explicitly with each institution on a regular basis before sharing the data with all the institutions. Each organization uses and maintains its own set of personal information. FL algorithms communicate only about model parameters or update gradients rather than sending actual training data, alleviating privacy concerns.
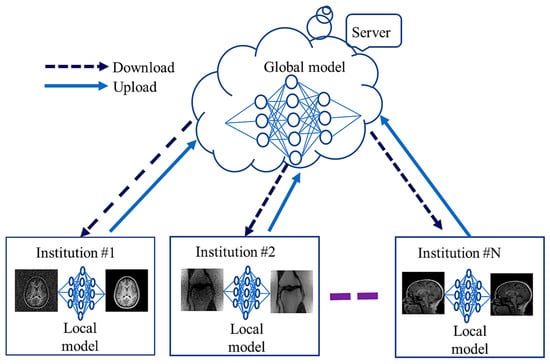
Figure 3 shows communication between global (server side) and local models among several institutions during training. Local models learn from local data and share their weights with the global model.
Figure 3. Federated learning for MRI reconstruction.
Li et al. [
71] proposed an FL strategy in which shared local model weights are adapted via a randomization procedure while a decentralized iterative optimization process is applied. Their FL framework encompasses two domain algorithms based on the systemic heterogeneity of functional MRI distributions from various sites. Domain shifts between sites in current FL-based MRI reconstruction efforts have not been investigated extensively. To increase the homogeneity of latent-space interpretations in reconstruction approaches, adversarial connectivity between the source and destination sites was suggested by Guo et al. [
72]. Feng et al. [
73] concentrated on the confidentiality of multi-institutional information in MRI image reconstruction by using the domain shift. Their reconstruction models were divided into a global encoder (used at all sites) and local decoders (individually trained at each site). Elmas et al. [
74] suggested a two-stage reconstruction method that involves relating the imaging operator input and cross-site adaptation of a generative MRI baseline. A continuous adversarial model that creates a high-quality image from low-dimensional dependent variables generated by a mapper captures global MRI knowledge. By allowing various institutions to collaborate without having to combine local data, FL can increase data privacy. However, the domain shift of MRI methods can markedly reduce the FL model performance. Levac et al. [
75] explored FL for MRI reconstruction by training global models across several clients (data sites) with local scans through employing end-to-end unrolled DL models. An algorithm, FedPR [
76], was presented to learn federated visual prompts in the global prompt null space for MRI reconstruction. The review article [
77] emphasized the difficulties of using FL in applications related to medical imaging and offered suggestions for future developments. The generalizability of models trained using FL is inadequate [
78]; its improvement is a focus of research.