In this paper, we carry out a scoping review that analyses synergies between the fields of Data Visualisation and Natural Language Interaction. Specifically, we focus on chatbot-based V-NLI approaches and explore and discuss three research questions. The first two research questions focus on studying how chatbot-based V-NLIs contribute to interactions with the Data and Visual Spaces of the visualisation pipeline, while the third seeks to know how chatbot-based V-NLIs enhance users’ interaction with visualisations. We identify challenges and possible research opportunities for the V-NLI community such as supporting high-level queries with complex data, integrating V-NLIs with more advanced systems such as Augmented Reality (AR) or Virtual Reality (VR), particularly for advanced visualisations, expanding guidance strategies beyond current limitations, adopting intelligent visual mapping techniques, and incorporating more sophisticated interaction methods.
- data visualisation
- natural language interface
- chatbot
1. Introduction
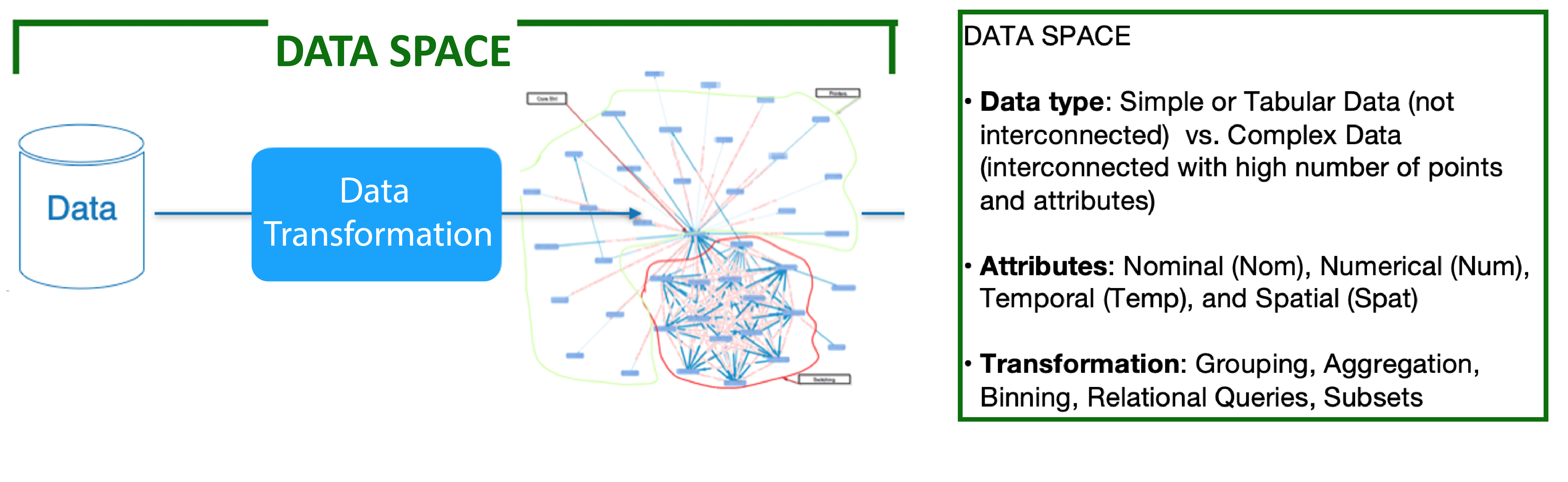
2. Data Visualisation
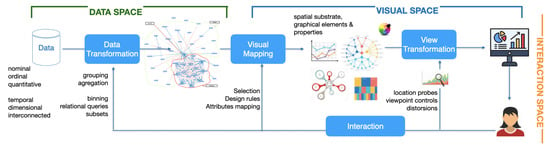
has transient data which is a data type that is relevant to a time period; in this case, it is the quality of software services over time.
2.2 Visual Space
-
The spatial substrate—i.e., the space and the layout used to map the data;
-
The graphical elements—i.e., marks such as points, lines, images, glyphs, lines, etc.;
-
The graphical properties—also called retinal properties, i.e., size, colour, orientation, etc. [2].

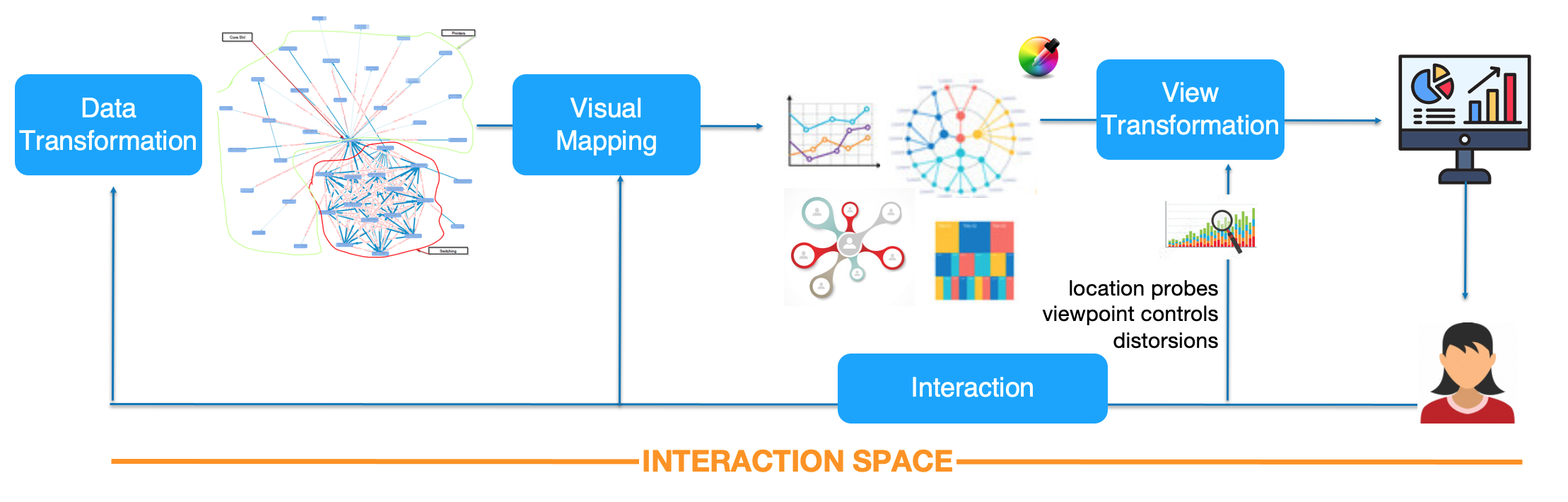
2.3 Interaction Space
3. Chatbot
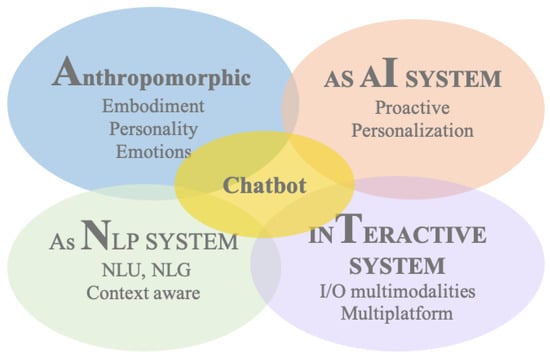
3.1 Interaction
3.2 Input
The types of inputs (analytical questions) that a V-NLI system deals with are low- and high-level queries. In Low-level queries, the users explicitly describe their intent, for example, “Show me action films that won an award in the past 10 years”. Therefore, these queries can be interpreted easily. When we explored different Query Types, we found that most of the previous research presented V-NLIs that support only low-level queries [24][18][23][11][25][15][27][21][12][26][14][22][8][16][17][9][20][19]. For instance, in works such as [25][14][17][9][26][20][19][23][22][12][21], users can ask direct queries and receive answers such as filtered or highlighted data points on visualisations or new visualisations. Moreover, there are V-NLIs that have more specific datasets and the chatbot is designed to ask users questions or give prompts to perform the analysis [15][16][27][11][18]. In contrast, High-level open-ended queries are naturally broader and their interpretation can be more complex [42][32]. There are two V-NLIs support both low and high level queries, Talk2Data, which is form-based [10] and Chat2Vis, which is chatbot-based [13].
3.3 Output
In addition to the requested visualisation, a V-NLI can consider Complementary Output such as Feedback, either text or visual: (i) to inform about the query’s success or failure, (ii) to justify relevant decisions taken by the system, (iii) to provide the users with additional explanations to better interpret the resulting visualisation (textual, oral, graphs, or statistics) and annotations, and (iv) to display changes in the User Interface (highlighting menus, buttons).
All of the works explored in this review give the users textual feedback and some of them give visual feedback as well. The only exception is Chat2Vis [13], which, probably due to its recentness, is not yet integrated into a visualisation platform. Basically, textual feedback is used to inform or justify chatbot decisions to the users. Works such as [23][24][9][19] inform users about the success or failure of their queries. Moreover, Refs. [11][15][18][16][27] provide the users with informative feedback, additional explanations and follow-up questions to users to carry on the analysis. Furthermore, we explored related work that provided users with additional visual feedback, such as supplementary graphs with main visualisation or changes on filters on the UI that have been applied by the chatbot. V-NLIs such as [17][9][19][20][14][21][26][27] have visual feedback on the UI.
4. Discussion
Figure 6 shows the contrasted the results of the input characteristics of V-NLIs with how these systems deal with the data space stage in the visualisation pipeline. We found that most of the works allow the users to express only low-level queries, and those that consider high-level queries do so with simple data types (see Figure 6, signal a and b) and attributes, i.e., tabular data with numerical and nominal attributes. Moreover, independently of the user’s intents (low or high queries), all the examined V-NLIs contemplate simple data transformations (i.e., simple aggregations and statistical analysis such as correlations and logistic regressions). Note also that those simple data transformations have normally been incorporated into V-NLI systems that consider followup queries [8][9]. Few works provide users with help or recommendations based on the data type, which is currently mainly tabular data [9][10][11][26]. Regarding multimodality, most systems allow user–chatbot interaction combined with WIMP, but few of them allow touching [26][17][14][24] and only one work uses gestures [21].

Figure 6. Spider chart displaying the relationship between data types and input V-NLI characteristics.
Figure 7 shows the scope of advanced and basic visualisations in both V-NLI and visualisation dimensions; see the borders in purple and green colour, respectively. As we can appreciate in the magenta- and blue-coloured polygons, V-NLIs that consider basic layouts embrace these dimensions in greater measure than those considering advanced layouts. Furthermore, the empty space of the spider reveals that there is a lot of room for research on different aspects of both basic and advanced visualisations in V-NLIs.

Figure 7. Spider chart displaying the relationship between Visual Space and V-NLI characteristics of analysed works.
Figure 8, both chatbot-based and form-based approaches cover a similar, short range of interactive methods—Filtering and Selecting being the most covered—including some values near zero, especially with chatbot-based approaches (see the complex interactions Abstract/Elaborate [27], Connect [23][24], Reconfigure [22], Explore [27] in yellow dots).
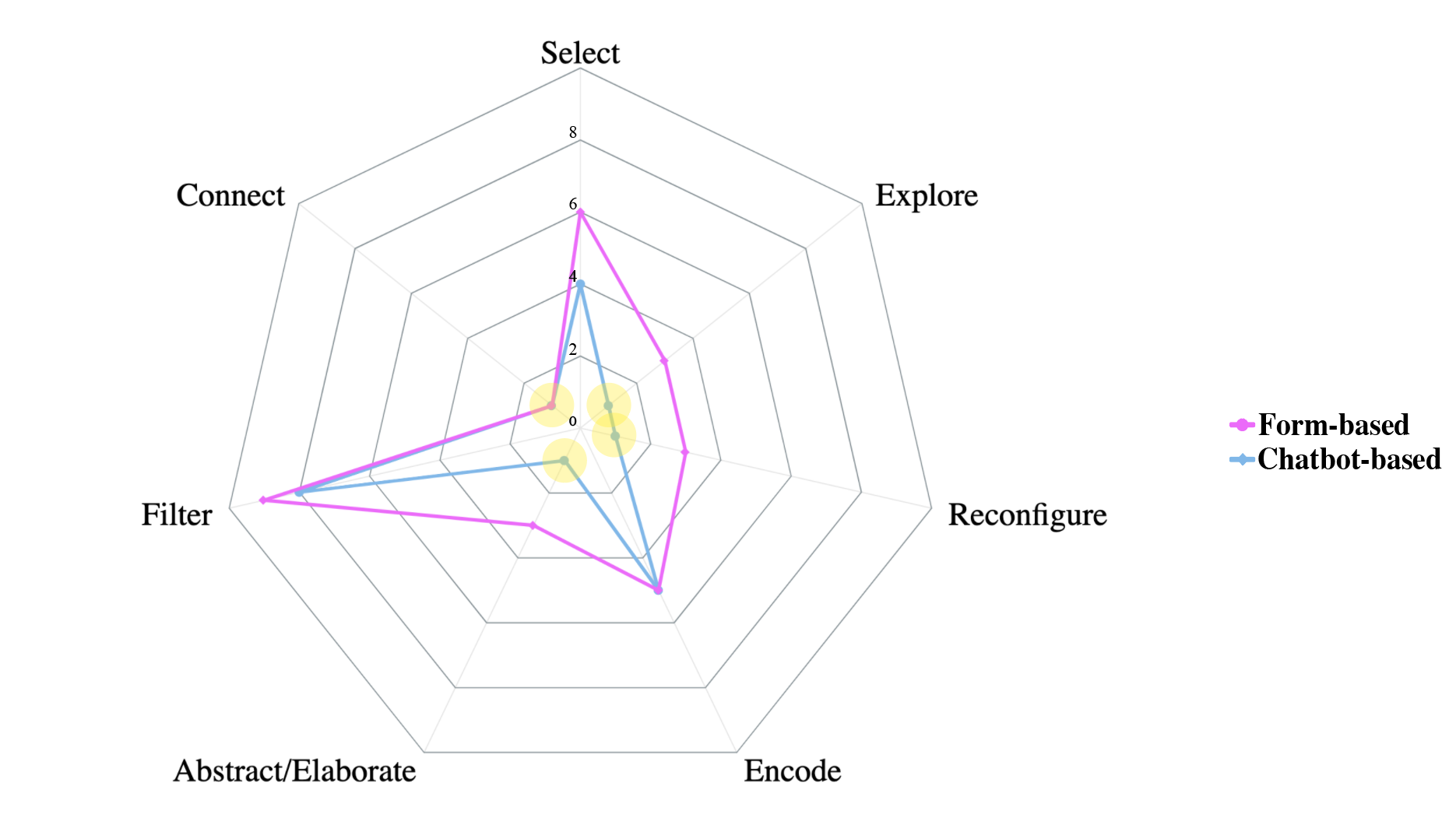
Figure 8. Spider chart displaying the relationship between the type of V-NLIs and interaction methods.
This entry is adapted from the peer-reviewed paper 10.3390/app13127025
References
- Shen, L.; Shen, E.; Luo, Y.; Yang, X.; Hu, X.; Zhang, X.; Tai, Z.; Wang, J. Towards natural language interfaces for data visualization:
- Card, M. Readings in Information Visualization: Using Vision to Think; Morgan Kaufmann: San Francisco, CA, USA, 1999.
- Qin, X.; Luo, Y.; Tang, N.; Li, G. Making data visualization more efficient and effective: A survey. VLDB J. 2020, 29, 93–117
- Hanrahan, P. Vizql: A language for query, analysis and visualization. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27-29 June 2006; pp. 721–721.
- Luo, Y.; Tang, N.; Li, G.; Tang, J.; Chai, C.; Qin, X. Natural Language to visualization by neural machine translation. IEEE Trans.Vis. Comput. Graph. 2021, 28, 217–226.
- Satyanarayan, A.; Russell, R.; Hoffswell, J.; Heer, J. Reactive vega: A streaming dataflow architecture for declarative interactive visualization. IEEE Trans. Vis. Comput. Graph. 2015, 22, 659–668.
- Kavaz, E.; Puig, A.; Rodríguez, I.; Chacón, R.; De-La-Paz, D.; Torralba, A.; Nofre, M.; Taule, M. Visualisation of hierarchical multivariate data: Categorisation and case study on hate speech. Inf. Vis. 2022, 22, 31–51.
- Hoque, E.; Setlur, V.; Tory, M.; Dykeman, I. Applying pragmatics principles for interaction with visual analytics. IEEE Trans. Vis.Comput. Graph. 2017, 24, 309–318.
- Srinivasan, A.; Setlur, V. Snowy: Recommending Utterances for Conversational Visual Analysis. In Proceedings of the The 34th Annual ACM Symposium on User Interface Software and Technology, Virtual Event, USA, 10-14 October 2021; pp. 864–880
- Shi, D.; Guo, Y.; Guo, M.; Wu, Y.; Chen, Q.; Cao, N. Talk2Data: High-Level Question Decomposition for Data-Oriented Question and Answering. arXiv 2021, arXiv:2107.14420.
- John, R.J.L.; Potti, N.; Patel, J.M. Ava: From Data to Insights through Conversations. In Proceedings of the CIDR, Chaminade, CA, USA; 8-11 January 2017.
- Lee, D.J.L.; Quamar, A.; Kandogan, E.; Özcan, F. Boomerang: Proactive insight-based recommendations for guiding conversational data analysis. In Proceedings of the 2021 International Conference on Management of Data, Virtual Event, China; 20-25 June 2021; pp. 2750–2754.
- Maddigan, P.; Susnjak, T. Chat2vis: Generating data visualisations via natural language using chatgpt, codex and gpt-3 large language models. arXiv 2023, arXiv:2302.02094.
- Srinivasan, A.; Lee, B.; Stasko, J. Interweaving multimodal interaction with flexible unit visualizations for data exploration. IEEE Trans. Vis. Comput. Graph. 2020, 27, 3519–3533.
- Zhi, Q.; Metoyer, R. Gamebot: A visualization-augmented chatbot for sports game. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA; 25-30 April 2020; pp. 1–7.
- Crovari, P.; Pidò, S.; Pinoli, P.; Bernasconi, A.; Canakoglu, A.; Garzotto, F.; Ceri, S. GeCoAgent: A conversational agent for empowering genomic data extraction and analysis. ACM Trans. Comput. Healthc. (HEALTH) 2021, 3, 1–29.
- Srinivasan, A.; Lee, B.; Henry Riche, N.; Drucker, S.M.; Hinckley, K. InChorus: Designing consistent multimodal interactions for data visualization on tablet devices. In Proceedings of the 2020 CHI conference on Human Factors in Computing Systems, Honolulu, Hawaii, USA; 25-30 April 2020; pp. 1–13.
- Fast, E.; Chen, B.; Mendelsohn, J.; Bassen, J.; Bernstein, M.S. Iris: A conversational agent for complex tasks. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada ;21-26 April 2018; pp. 1–12.
- Chowdhury, I.; Moeid, A.; Hoque, E.; Kabir, M.A.; Hossain, M.S.; Islam, M.M. MIVA: Multimodal interactions for facilitating visual analysis with multiple coordinated views. In Proceedings of the 2020 24th International Conference Information Visualisation (IV), Melbourne, Australia; 7-11 September 2020; pp. 714–717.
- Ruoff, M.; Myers, B.A.; Maedche, A. ONYX-User Interfaces for Assisting in Interactive Task Learning for Natural Language Interfaces of Data Visualization Tools. In Proceedings of the CHI Conference on Human Factors in Computing Systems Extended Abstracts, New Orleans, LA, USA; 29 April-5 May 2022; pp. 1–7.
- Kassel, J.F.; Rohs, M. Valletto: A multimodal interface for ubiquitous visual analytics. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada; 21-26 April 2018; pp. 1–6.
- Huang, J.; Xi, Y.; Hu, J.; Tao, J. FlowNL: Asking the Flow Data in Natural Languages. IEEE Trans. Vis. Comput. Graph. 2022, 29, 1200–1210.
- Bieliauskas, S.; Schreiber, A. A conversational user interface for software visualization. In Proceedings of the 2017 IEEE Working Conference on Software Visualization (Vissoft), Shanghai, China; 18-19 September 2017; pp. 139–143
- Srinivasan, A.; Stasko, J. Orko: Facilitating multimodal interaction for visual exploration and analysis of networks. IEEE Trans. Vis. Comput. Graph. 2017, 24, 511–521
- Siddiqui, N.; Hoque, E. ConVisQA: A Natural Language Interface for Visually Exploring Online Conversations. In Proceedings of the 2020 24th International Conference Information Visualisation (IV), Melbourne, Australia; 7-11 September 2020; pp. 440–447.
- Kim, Y.H.; Lee, B.; Srinivasan, A.; Choe, E.K. Data@ hand: Fostering visual exploration of personal data on smartphones leveraging speech and touch interaction. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan; 8-13 May 2021; pp. 1–17
- Beck, S.; Frank, S.; Hakamian, A.; Merino, L.; van Hoorn, A. TransVis: Using Visualizations and Chatbots for Supporting Transient Behavior in Microservice Systems. In Proceedings of the 2021 Working Conference on Software Visualization (VISSOFT), Luxembourg City, Luxembourg, 27-28 September 2021; pp. 65–75.
- Börner, K.; Bueckle, A.; Ginda, M. Data visualization literacy: Definitions, conceptual frameworks, exercises, and assessments. Proc. Natl. Acad. Sci. USA 2019, 116, 1857–1864.
- Khan, M.; Khan, S.S. Data and information visualization methods, and interactive mechanisms: A survey. Int. J. Comput. Appl. 2011, 34, 1–14.
- Stasko, J.; Zhang, E. Focus+ context display and navigation techniques for enhancing radial, space-filling hierarchy visualizations. In Proceedings of the IEEE Symposium on Information Visualization 2000, INFOVIS 2000 Proceedings, Salt Lake City, UT, USA, 9–10 October 2000; pp. 57–65.
- Dimara, E.; Perin, C. What is interaction for data visualization? IEEE Trans. Vis. Comput. Graph. 2019, 26, 119–129.
- Amar, R.; Eagan, J.; Stasko, J. Low-level components of analytic activity in information visualization. In Proceedings of the IEEE Symposium on Information Visualization, 2005—INFOVIS 2005, Minneapolis, MN, USA, 23–25 October 2005; pp. 111–117.
- Yi, J.S.; ah Kang, Y.; Stasko, J.; Jacko, J.A. Toward a deeper understanding of the role of interaction in information visualization. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1224–1231.
- Steinmetz, N.; Senthil-Kumar, B.; Sattler, K.U. Conversational Question Answering Using a Shift of Context. In Proceedings of the EDBT/ICDT Workshops, Nicosia, Cyprus; 23-26 March 2021.
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006.
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006
- Cassell, J. Embodied conversational interface agents. Commun. ACM 2000, 43, 70–78.
- Tellols, D.; Lopez-Sanchez, M.; Rodríguez, I.; Almajano, P.; Puig, A. Enhancing sentient embodied conversational agents with machine learning. Pattern Recognit. Lett. 2020, 129, 317–323
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2022, 82, 3713–3744.
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170.
- Gao, T.; Dontcheva, M.; Adar, E.; Liu, Z.; Karahalios, K.G. Datatone: Managing ambiguity in natural language interfaces for data visualization. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, Charlotte, NC, USA; 11-15 November 2015; pp. 489–500.
- Stasko, J.; Zhang, E. Focus+ context display and navigation techniques for enhancing radial, space-filling hierarchy visualizations. In Proceedings of the IEEE Symposium on Information Visualization 2000, INFOVIS 2000 Proceedings, Salt Lake City, UT, USA, 9–10 October 2000; pp. 57–65.
- Gao, T.; Dontcheva, M.; Adar, E.; Liu, Z.; Karahalios, K.G. Datatone: Managing ambiguity in natural language interfaces for data visualization. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, Charlotte, NC, USA, 11–15 November 2015; pp. 489–500.
- Setlur, V.; Battersby, S.E.; Tory, M.; Gossweiler, R.; Chang, A.X. Eviza: A natural language interface for visual analysis. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 365–377.
- Huang, Y.; Wang, Y.; Tam, Y.C. Uniter-based situated coreference resolution with rich multimodal input. arXiv 2021,arXiv:2112.03521.