JEM, the BEE is a Java, cloud-aware application which implements a Batch Execution Environment, to help and manage the execution of jobs, described by a Job Control Language (JCL). JEM, the BEE performs the following functions:
- jcl
- cloud-aware
- jem
1. Functions
Core applications are usually performed through batch processing,[1] which involves executing one or more batch jobs in a sequential flow.[2] The Job Entry Manager (JEM) helps receive jobs, schedule them for processing, and determine how job output is processed (like IBM JES2).
Many batch jobs are run in parallel and JCL is used to control the operation of each job. Correct use of JCL parameters allows parallel, asynchronous execution of jobs that may need access the same data sets. One goal of a JEM is to process work while making the best use of system resources. To achieve this goal, resource management is needed during key phases:
- Before job processing: to reserve input and output resources for jobs.
- During job processing: to control step execution and standardize output
- After job processing: to free all resources used by the completed jobs, making the resources available to other jobs.
2. Overview
2.1. Clustering
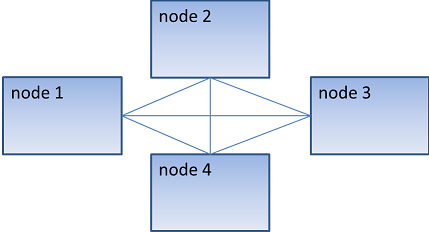
JEM clustering [3] is based on Hazelcast.[4] Each cluster member (called node) has the same rights and responsibilities of the others (with the exception of the oldest member, that we are going to see in details): this is because Hazelcast implements a peer-to-peer clustering, so that there's no "master" node.
When a node starts up, it checks to see if there's already a cluster in the network. There are two ways to find this out:
- Multicast discovery: if multicast discovery is enabled (this is the default), the node will send a join request in the form of a multicast datagram packet.
- Unicast discovery: if multicast discovery is disabled and TCP/IP join is enabled, the node will try to connect to the IPs defined. If it successfully connects to (at least) one node, then it will send a join request through the TCP/IP connection.
If no cluster is found, the node will be the first member of the cluster. If multicast is enabled, it starts a multicast listener so that it can respond to incoming join requests. Otherwise, it will listen for join request coming via TCP/IP.
If there is an existing cluster already, then the oldest member in the cluster will receive the join request and checks if the request is for the right group. If so, the oldest member in the cluster will start the join process.
In the join process, the oldest member will:
- send the new member list to all members
- tell members to synchronize data in order to balance the data load
Every member in the cluster has the same member list in the same order. First member is the oldest member so if the oldest member dies, second member in the list becomes the first member in the list and the new oldest member. The oldest member is considered as the JEM cluster coordinator: it will execute those actions that must be executed by a single member (i.e. locks releasing due to a member crash).
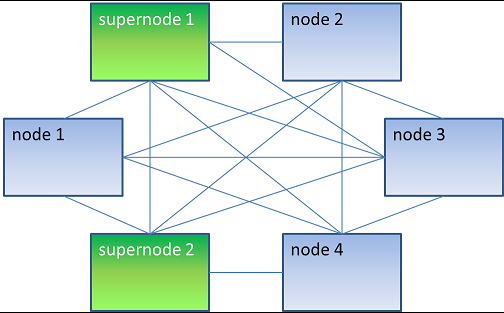
Aside the "normal" nodes, there's another kind of nodes in the cluster, called supernodes. A supernode is a lite member of Hazelcast.
Supernodes are members with no storage: they join the cluster as "lite members", not as "data partition" (no data on these nodes), and get super fast access to the cluster just like any regular member does. These nodes are used for the Web Application (running on Apache Tomcat,[5] as well as on any other application server).
2.2. Status
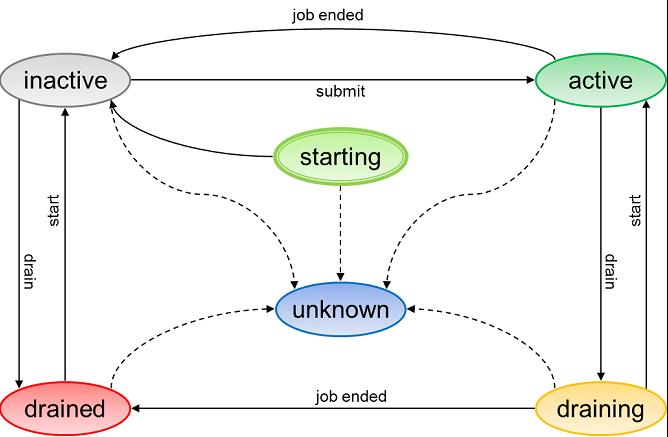
Here is a diagram of the various nodes' statuses:
| Node type | Status | Description |
|---|---|---|
| NODE | STARTING | in start up phase, node registers itself with this status |
| INACTIVE | it's ready to take JCL to execute | |
| ACTIVE | the job is running and the node is managing it | |
| DRAINING | operators perform drain command to node, to block any processing, but the node was ACTIVE and a job is still running | |
| DRAINED | operators block any processing of this node | |
| UNKNOWN | when a node is no longer joined to cluster and its status is unknown | |
| SUPERNODE | ACTIVE | supernodes are always active. Not possible to drain and start them |
| UNKNOWN | when a node is no longer joined to cluster and its status is unknown |
2.3. Execution Environment
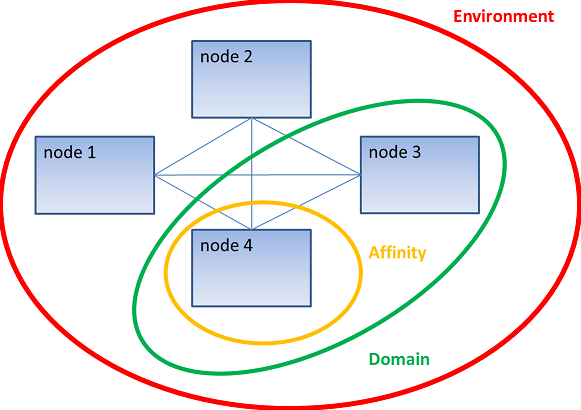
The Execution Environment is a set of logical definition related to cluster which must be used to address the job to the right member to be executed. JEM implements 3 kinds of coordinates, used as tags, named:
- Environment: the name of the cluster jobs must be run on. It must be the same of Hazelcast group name.
- Domain: a subset of nodes (identified by a tag) jobs must be run on (i.e. have a domain for application code).
- Affinity: a subset of nodes of a domain (by one or more tags) jobs must be run on.
Each node belongs to:
- one (and only one) Environment
- zero or one Domain
- zero or more Affinities
Each JCL can be defined to be run on:
- one (and only one) Environment
- zero or one Domain
- zero or more Affinities
2.4. Queues and Job Life-Cycle
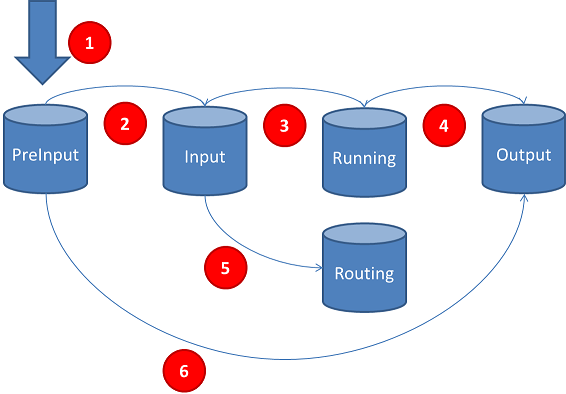
JEM manages several queues used to maintain the life-cycle of a job: the queues are implemented using Hazelcast data sharing.
Here is the explanation:
- when a job is submitted for execution by a submitter, it's moved to preinput queue: while there, JCL is validated (JCL validation is done by a cluster's node)
- after successful JCL validation, job is moved to input queue, waiting for job execution
- according to Domain and Affinity tags, job is run on an appropriate node and moved to running queue
- after job ends, it is moved to output queue
- according to Environment tag, a job can be moved from the input queue to the routing queue, waiting for another JEM cluster which will fetch and execute it
- if JCL validation is unsuccessful, job is moved into output queue
When a job is moved into output queue, the submitter will receive a "job ended" notification (via topic).
2.6. File-Systems
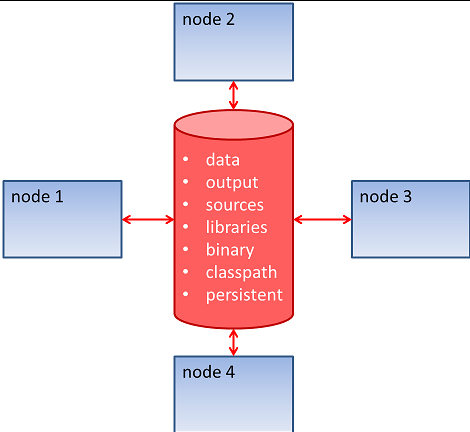
In addition to a memory data sharing, one of the most important requirements for JEM is to use a global file system (GFS[6]). The main goal is to be able to store data on a common file system so that all jobs could manage them (reading and writing). Nevertheless, a GFS is not mandatory, if you desire to have all data spread on all machines and configuring JEM to have separate Environment, by specific Domains and Affinities.
Anyway, a GFS is suggested to be used to put the keys and keystores for encryption and licenses used by JEM.
Following folders should be configured:
- data path where all datasets will be stored
- output path where JEM nodes will store all output produced by job, during its execution (see next section about output management)
- sources path where JCL sources are stored. This is necessary for usual import and include statements of JCL
- library path where all native system libraries (like .dll, .so) that are needed by the executable files present in the binary folder should be stored
- binary path where all the executable files (like .exe, .cmd, .sh ) that are called by the JCL should be stored
- classpath path where all the library (like jar, zip), needed at runtime to accomplished a JCL, should be stored
- persistence path where keys, keystores and licenses, used by JEM node, must be stored
Each of these paths should be mount in a shared file system (may be different shared file systems, one for each path if needed) so that all the nodes in the cluster will refers to files in the same way, will avoid redundancy and will always be up to date relative to the libraries versions, binary versions etc...
In this documentation, when we referred to the JEM GFS (global file system) we are referring to these paths.
References
- IBM Corporation. Mainframes working after hours: Batch processing Mainframe concepts. Retrieved March 26, 2014. http://publib.boulder.ibm.com/infocenter/zos/basics/index.jsp?topic=/com.ibm.zos.zmainframe/zconc_batchproc.htm
- Effect of Job Size Characteristics on Job Scheduling Performance http://www.cs.huji.ac.il/~feit/parsched/jsspp00/p-00-1.pdf
- cluster definition http://www.techterms.com/definition/cluster
- Hazelcast web site http://www.hazelcast.com
- apache tomcat http://tomcat.apache.org/
- GFS Project Page https://www.sourceware.org/cluster/gfs/