Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | George A. Papakostas | + 2586 word(s) | 2586 | 2021-05-18 08:09:43 | | | |
| 2 | Vicky Zhou | Meta information modification | 2586 | 2021-05-19 04:12:36 | | | | |
| 3 | Vicky Zhou | -2 word(s) | 2584 | 2021-05-19 04:13:05 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Papakostas, G. Finger-Vein-Based Identity Recognition. Encyclopedia. Available online: https://encyclopedia.pub/entry/9806 (accessed on 24 July 2026).
Papakostas G. Finger-Vein-Based Identity Recognition. Encyclopedia. Available at: https://encyclopedia.pub/entry/9806. Accessed July 24, 2026.
Papakostas, George. "Finger-Vein-Based Identity Recognition" Encyclopedia, https://encyclopedia.pub/entry/9806 (accessed July 24, 2026).
Papakostas, G. (2021, May 18). Finger-Vein-Based Identity Recognition. In Encyclopedia. https://encyclopedia.pub/entry/9806
Papakostas, George. "Finger-Vein-Based Identity Recognition." Encyclopedia. Web. 18 May, 2021.
Copy Citation
Finger vein recognition is a relatively new method of biometric authentication. It matches the vascular pattern in an individual’s finger to previously obtained data.
biometrics
finger vein recognition
identity recognition
feature extraction
deep learning
1. Introduction
Identity verification has become an integral part of people’s daily life. Logging into computers or electronic accounts, using ATMs (Automated Teller Machines), and being given entrance permission to a bank or an area generally are just some of the most common cases where identity verification is needed. There are many ways to verify someone’s identity. The usage of a password is the most popular, but it tends to be obsolete, as biometrics seem to be the key to the person identification problem.
Biometrics refers to metrics related to human characteristics. Biometric identifiers are the distinctive, measurable characteristics used to label and describe individuals. They are usually divided into two categories: (1) behavioral, such as typing rhythm, gait, and voice; and (2) physiological, e.g., fingerprints, face, iris, and finger vein. Each category has both advantages and disadvantages and some of them are already being used extensively.
Finger vein biometrics is a field that is currently in the spotlight. Because it is rather new compared with other biometric fields, the information in addition to the conducted studies is poor. The advantages of using the veins of the fingers as biometrics are fair enough and constitute the main motivation for applying this technology. Firstly, it is a biometric trait that is difficult to forge, as the main functionality is to emit infrared light in the finger and capture via a camera the shape of the finger’s veins. It is well known that the shape of the finger vein is unique in humans, which makes a finger vein a very good means of identification. Other advantages of the unique identification the finger vein offers are that it is achievable through any finger of a human and the vein patterns are permanent, meaning that they remain unchanged over time and can be measured without subjecting the human to a painful process. The finger vein trait satisfies in some degree the seven factors [1] that define the suitability of a biometric trait in order to be useful for identity authentication: (1) Universality, (2) Uniqueness, (3) Permanence, (4) Measurability, (5) Performance, (6) Acceptability, and (7) Circumvention. As a result, finger vein biometrics has gained ground due to all these advantages and raises the interest for most researchers to conduct studies in this field.
The standard method used to acquire finger vein images includes the position of a CCD or CMOS camera opposite to a near-infrared (NIR) light source (LED), with the finger inserted between them. Due to the property of the hemoglobin having a lower absorbance to the NIR wavelengths than the visible ones, the camera can capture an image containing the finger veins. Of course, the wavelength of the used LED source affects the representation quality of the vein patterns. The captured vein patterns are compared with prototype veins stored in a smart card. The images that are taken include not only vein patterns but also irregular shading and noise due to the varying thickness of finger bones and muscles. Therefore, the most challenging part of the whole process is to use the right method to extract the finger vein features.
Figure 1 shows a flowchart that describes the steps a typical finger vein recognition algorithm follows. The finger images are usually taken by using a camera and a separate illumination source emitting near-infrared light. Image preprocessing usually includes denoising (such as image smoothing, blurring, etc.), image thresholding, image enhancement, and skeletonization. The next step, known as feature extraction, is the one that is going to be studied in the following sections thoroughly. Finally, in the last step, the extracted features are used as inputs in a matching/recognition model.
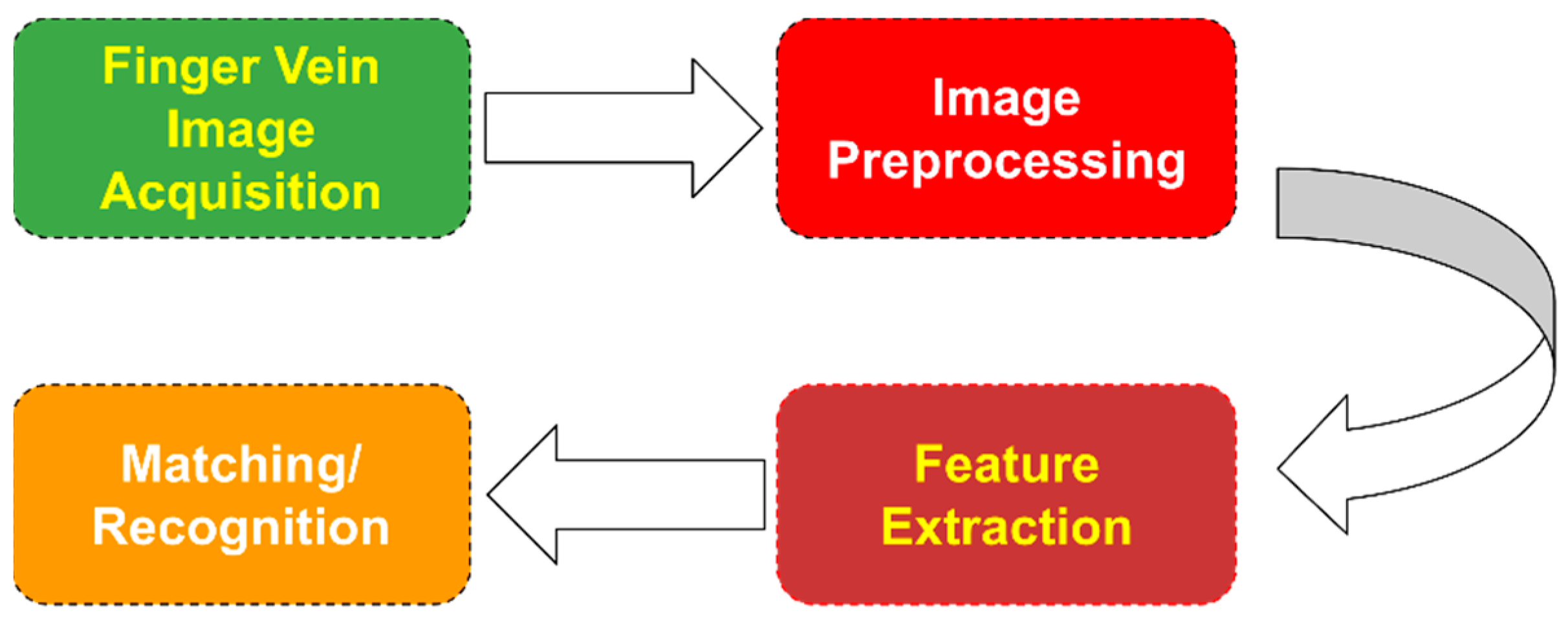 Figure 1. Finger vein feature extraction flowchart.
Figure 1. Finger vein feature extraction flowchart.A plethora of methods have been proposed so far for feature extraction, including the usage of, e.g., templates, transformations, minutiae, line tracking, binary feature extraction, histogram analysis, and mathematical procedures. This work aims to contribute in three distinct directions: (1) it systematically reviews the feature extraction methods proposed in the literature in the last several years; (2) it identifies the shortcomings of the state-of-the-art methods; and (3) it sheds light on the current challenges that need to be addressed by the scientific community towards the development of more efficient finger vein recognition systems.
2. Feature Extraction vs Feature Learning
The feature extraction methods presented in the previous section share the same property of being inspired by the prior knowledge of some application experts. The designers of such feature extraction algorithms need to have knowledge of finger vein anatomy as well as information coding/representation and computer vision skills. This requirement of prior knowledge makes the design of these methods a difficult and demanding task.
One of the reasons for the rise of deep learning is the automation and optimization of the feature extraction procedure. For example, Convolutional Neural Networks (CNNs), which are the most popular deep learning models for computer vision applications, consist of several feature extraction layers before the final decision layers. The feature extraction layers learn to extract optimized feature representations (convolutional kernels) from the training images. In this context, the process of using prior knowledge to extract the useful features from an image has been transformed into a feature learning task based on a massive number of training images.
The first attempt to deploy deep learning models in finger vein biometrics was by Radzi et al. [2] in 2016. In this work, a preprocessing procedure was first applied to the finger vein image in order to extract a ROI of 55 × 67 pixels in size. Then, the image was fed to a customized four-layer CNN with a 5–13–50–50 architecture. The performance of this method for an in-house finger vein dataset was very promising. The same methodology was also adopted by Itqan et al. [3] to develop a user authentication application in MATLAB IDE.
In 2017, Hong et al. [4] proposed the application of the pre-trained VGGNet-16 [5] CNN model, which consists of 13 convolutional layers, 5 pooling layers, and 3 fully connected layers (FCLs). Initially, an ROI of 224 × 224 pixels in size that includes the finger vein is detected using the method described in [6] and the difference between the input image and the enrolled image is fed to the CNN for recognition.
The following year, the number of attempts to apply deep learning models increased significantly. More precisely, Yang et al. [7] used stacked the Extreme Learning Machine (ELM) deep learning model and Canonical Correlation Analysis (CCA) [8] to build a multi-modal biometric system, called the S-E-C model, based on face and finger vein biometrics. Firstly, a stacked ELM is used to produce a hidden-layer representation of the finger vein images (along with the face images). Then, the CCA method is used to convert the representation produced by the stacked ELM to a feature vector, which is finally passed through to an ELM classifier.
Kim et al. [9] proposed a multi-modal biometric methodology utilizing the finger shape and finger vein patterns for authentication purposes. The introduced method includes a preprocessing stage for compensating for the in-plane rotation and extracting the ROI of the finger vein. Moreover, this method makes use of an ensemble model consisting of two CNNs, based on the ResNet-50 and ResNet-101 architectures, without the output layer. Hu et al. [10] proposed a customized CNN architecture, called FV-Net, that uses the first seven layers of the pre-trained VGGFace-Net [11] model and the addition of three more convolutional layers that learn the specific vein-like features.
Fairuz et al. [12] proposed a CNN architecture of five convolutional and four fully connected layers, while the input images should be 227 × 227 × 3 pixels in size. They evaluated their model using an in-house dataset of 1560 images. In the same year, Das et al. [13] also used a customized CNN consisting of five convolutional layers, three max-pooling layers, one ReLU, and a Softmax layer. The reported advantage of this model is the ability of the CNN to handle non-square images since the input image has a size of 65 × 153 × 1 pixels and the used kernels are of an optimized size.
In 2019, Xie and Kumar [14] used a Siamese CNN model after image preprocessing, enhancement, and supervised discrete hashing [15] for finger vein identification. They compared the results of different configurations of the Light CNN (LCNN) and the VGG-16 models. On the other hand, Lu et al. [16] presented the CNN competitive order (CNN-CO) local descriptor, which is generated by using a CNN that is pre-trained on ImageNet. After selecting the effective CNN filters from the first layer of the network, the CNN-CO computes the CNN-filtered images, builds the competitive order image, and, lastly, generates the CNN-CO pyramid histogram. Song et al. [17] proposed a modified version of the DenseNet-161 [18] model, which is applied after image preprocessing, restoring of the empty regions, and constructing composite and difference images using the enrolled and input images. Finally, Li and Fang [19] proposed an end-to-end Graph Neural Network (GNN), called FVGNN, consisting of the EmbedNet CNN for feature extraction and the EdgeNet. The authors examined three different types of CNNs for the case of the EmbedNet: VGG-based, ResNet-based, and Inception-based networks.
The next year, Kuzu and Maiorana [20] introduced an ad hoc acquisition architecture comprised of CNNs and RNNs. A CNN was used to extract features from images of four finger veins, which were then fed to a Long-Short Term Memory (LSTM) model, as a sequence, for classification. Noh et al. [21] used both texture images and finger vein shape images to train two CNN models. After stacking the enrolled and input images onto a three-channel image, they fed them into the corresponding CNNs. Each CNN outputs a matching score between the images, which is then corrected with a shift matching algorithm. Lastly, the two scores are fused together to provide the final decision. Cherrat et al. [22], in their finger vein system, used a CNN as a feature extractor combined with a Random Forest model for the classification, while Zhao et al. [23] used a lightweight CNN for the classification and focused on the loss function by using the center loss function and dynamic regularization. Hao et al. [24] proposed a multi-tasking neural network that performs both ROI and feature extraction sequentially, through two branches. The model is similar to the Faster RCNN and makes use of the SmoothL1 loss function for the ROI detection branch and the ArcFace loss functions for the feature extraction branch. Lastly, Kuzu et al. [25] investigated the application of transfer learning by using pre-trained CNN models trained on the ImageNet dataset, with satisfactory results.
It is worth mentioning that the incorporation of deep learning models into finger vein recognition systems is mainly focused on the substitution of the manual feature extraction with an automatic feature learning approach. However, the main disadvantage of these approaches is the need for large datasets, which at this moment are not available, a weakness that is managed by incorporating data augmentation techniques. Studies have made use of transfer learning methodologies without achieving results as good as those from some of the methodologies mentioned in the previous sections. The reason for this is the nature of the images captured from the device, as these types of images have unique characteristics compared with the images included in the ImageNet dataset (which most pre-trained models have been trained on). Despite that, CNNs have been shown to achieve very good results if a large amount of data exists to train them on. Table 1 summarizes the studies mentioned in this category.
Table 1. Characteristics of the feature-learning-based methodologies.
| Ref. | Key Features | Advantages | Disadvantages |
|---|---|---|---|
| [22] | Application of a reduced complexity CNN with convolutional subsampling | Fast with very high accuracy (99.27%), does not require segmentation or noise filtering | More testing is required |
| [3] | Application of the smaller LeNet-5 | Not reported | Small dataset, low accuracy (96.00%) |
| [4] | Usage of a difference image as input to VGG-16 | Robust to environmental changes, a low EER (0.396%) | Performance heavily depends on image quality |
| [7] | Application of stacked ELMs and CCA | Does not require iterative fine tuning, efficient, and flexible | Slow with low accuracy (95.58%) |
| [9] | Application of an ensemble model of ResNet50 and ResNet101 |
Better performance than other CNN-based models, a low EER (0.80%) | Performance depends on correct ROI extraction |
| [10] | Application of FV-Net | Extracts spatial information, a low EER (0.04%) | Performance varies per dataset |
| [12] | Application of a customized CNN | Very high accuracy (99.17%) | Performance depends on training/testing set size, more testing is required |
| [13] | Application of a customized CNN | Evaluated in four popular datasets | Low accuracy (95.00%), illumination and lighting affect performance |
| [14] | Application of a Siamese network with supervised discrete hashing | Smaller template size | A larger dataset is needed, a high EER (8.00%) |
| [16] | Application of CNN-CO | Exploits discriminative features, does not require a large-scale dataset, a low EER (0.93%) | Performance varies per dataset |
| [17] | Stacking of ROI images into a three-channel image as input to a modified DenseNet-161 | Robust against noisy images, a low EER (0.44%) | Depends heavily on correct alignment and clear capturing |
| [19] | Application of FVGNN | Does not require parameter tuning or preprocessing, very high accuracy (99.98%) | More testing is required |
| [20] | Combination of a V-CNN and LSTM | Ad hoc image acquisition, high accuracy (99.13%) | High complexity |
| [21] | Stacking of both texture and vein images, application of CNNs to extract matching scores | Robust to noise, a low EER (0.76%) | Model is heavy, long processing time |
| [22] | Combination of a CNN, Softmax, and RF | High accuracy (99.73%) | Small dataset |
| [23] | Application of a lightweight CNN with a center loss function and dynamic regularization | Robust against a bad-quality sensor, faster convergence, and a low EER (0.50%) | The customized CNN needs improvement |
| [24] | Application of a multi-task CNCN for ROI and feature extraction | Efficient, interpretable results | Performance varies per dataset |
| [25] | Transfer learning on a modified DenseNet161 | Low EER (0.006%), does not require building a network from scratch | Performance varies per dataset |
3. Conclusions
The field feature extraction methods proposed for finger vein biometrics is currently in the spotlight and there is not as much information as on other biometrics, for example, fingerprints, that can guarantee a low error rate, it could be used as a starting point for newcomers who want to make a breakthrough in the field. Moreover, despite the fact that finger veins have a lower accuracy than other biometric traits, they are worth investigating because they have a number of advantages, such as being very difficult to forge, and a human has more than one finger, which can be used for authentication purposes.
In the past several years, authentication based on finger vein images has seen an improvement as far as the performance goes. The best performance can be seen in the methodologies of feature learning, where deep learning is employed. Those have the best performance on average, with many methodologies achieving over 99% of accuracy, despite the small (for deep learning) datasets available.
We conclude that most of the studies, especially in the early years, did not evaluate the proposed methodology on publicly available datasets. This is mainly attributed to the fact that some of the currently available datasets only became available later on. Moreover, the chosen metric for the performance evaluation varies across studies, with most of the studies presenting the EER, RR, or ROC scores.
As future work, for comparative reasons, it is highly recommended that researchers present their proposed methodology’s performance using the same and more interpretable metrics. Additionally, the splitting of the training and testing set sizes, for those methodologies that apply any type of learning procedure, has to be the same too. In this context, the design of large-scale datasets (big data) that will permit the training and validation of customized CNN models from scratch is of paramount importance towards the development of more reliable finger vein biometric systems.
References
- Jain, A.K.; Ross, A.; Prabhakar, S. An Introduction to Biometric Recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20.
- Ahmad Radzi, S.; Khalil-Hani, M.; Bakhteri, R. Finger-Vein Biometric Identification Using Convolutional Neural Network. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 1863–1878.
- Itqan, K.S.; Syafeeza, A.R.; Gong, F.G.; Mustafa, N.; Wong, Y.C.; Ibrahim, M.M. User Identification System Based on Finger-Vein Patterns Using Convolutional Neural Network. ARPN J. Eng. Appl. Sci. 2016, 11, 3316–3319.
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors 2017, 17, 1297.
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556.
- Pham, T.; Park, Y.; Nguyen, D.; Kwon, S.; Park, K. Nonintrusive Finger-Vein Recognition System Using NIR Image Sensor and Accuracy Analyses According to Various Factors. Sensors 2015, 15, 16866–16894.
- Yang, J.; Sun, W.; Liu, N.; Chen, Y.; Wang, Y.; Han, S. A Novel Multimodal Biometrics Recognition Model Based on Stacked ELM and CCA Methods. Symmetry 2018, 10, 96.
- Hotelling, H. Relations between Two Sets of Variates. Biometrika 1936, 28, 321.
- Kim, W.; Song, J.M.; Park, K.R. Multimodal Biometric Recognition Based on Convolutional Neural Network by the Fusion of Finger-Vein and Finger Shape Using near-Infrared (NIR) Camera Sensor. Sensors 2018, 18, 2296.
- Hu, H.; Kang, W.; Lu, Y.; Fang, Y.; Liu, H.; Zhao, J.; Deng, F. FV-Net: Learning a Finger-Vein Feature Representation Based on a CNN. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 3489–3494.
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association: Swansea, UK, 2015; pp. 41.1–41.12.
- Fairuz, S.; Habaebi, M.H.; Elsheikh, E.M.A.; Chebil, A.J. Convolutional Neural Network-Based Finger Vein Recognition Using Near Infrared Images. In Proceedings of the 2018 7th International Conference on Computer and Communication Engineering, ICCCE 2018, Kuala Lumpur, Malaysia, 19–20 September 2018; pp. 453–458.
- Das, R.; Piciucco, E.; Maiorana, E.; Campisi, P. Convolutional Neural Network for Finger-Vein-Based Biometric Identification. IEEE Trans. Inf. Forensics Secur. 2018, 14, 360–373.
- Xie, C.; Kumar, A. Finger Vein Identification Using Convolutional Neural Network and Supervised Discrete Hashing. Pattern Recognit. Lett. 2019, 119, 148–156.
- Shen, F.; Shen, C.; Liu, W.; Shen, H.T. Supervised Discrete Hashing. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 37–45.
- Lu, Y.; Xie, S.; Wu, S. Exploring Competitive Features Using Deep Convolutional Neural Network for Finger Vein Recognition. IEEE Access 2019, 7, 35113–35123.
- Song, J.M.; Kim, W.; Park, K.R. Finger-Vein Recognition Based on Deep DenseNet Using Composite Image. IEEE Access 2019, 7, 66845–66863.
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708.
- Li, J.; Fang, P. FVGNN: A Novel GNN to Finger Vein Recognition from Limited Training Data. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC 2019), Chongqing, China, 24–26 May 2019; pp. 144–148.
- Kuzu, R.S.; Piciucco, E.; Maiorana, E.; Campisi, P. On-the-Fly Finger-Vein-Based Biometric Recognition Using Deep Neural Networks. IEEE Trans. Inf. Forensic Secur. 2020, 15, 2641–2654.
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-Vein Recognition Based on Densely Connected Convolutional Network Using Score-Level Fusion with Shape and Texture Images. IEEE Access 2020, 8, 96748–96766.
- Cherrat, E.; Alaoui, R.; Bouzahir, H. Convolutional Neural Networks Approach for Multimodal Biometric Identification System Using the Fusion of Fingerprint, Finger-Vein and Face Images. PeerJ Comput. Sci. 2020, 6, e248.
- Zhao, D.; Ma, H.; Yang, Z.; Li, J.; Tian, W. Finger Vein Recognition Based on Lightweight CNN Combining Center Loss and Dynamic Regularization. Infrared Phys. Technol. 2020, 105, 103221.
- Hao, Z.; Fang, P.; Yang, H. Finger Vein Recognition Based on Multi-Task Learning. In Proceedings of the 2020 5th International Conference on Mathematics and Artificial Intelligence, Chengdu, China, 10–13 April 2020; pp. 133–140.
- Kuzu, R.S.; Maiorana, E.; Campisi, P. Vein-Based Biometric Verification Using Transfer Learning. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; pp. 403–409.
More
Information
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.5K
Revisions:
3 times
(View History)
Update Date:
19 May 2021
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No