 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Thushantha Lakmal Betti Pillippuge | -- | 1388 | 2025-03-07 01:43:28 |
Video Upload Options
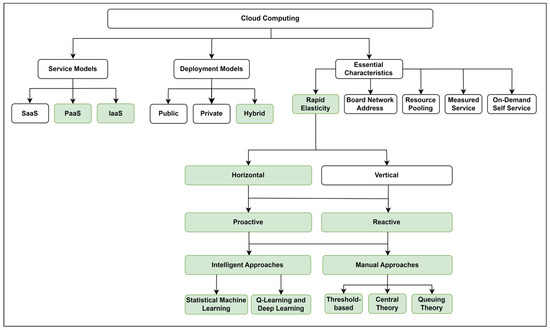
The deployment of virtual machines (VMs) within the Infrastructure as a Service (IaaS) layer across public, private, or hybrid cloud infrastructures is prevalent in various organisational settings for hosting essential business services. However, achieving rapid elasticity, or autoscaling, and ensuring quality of service amidst fluctuating service demands and available computing resources present significant challenges. Unlike the Platform as a Service (PaaS) and Software as a Service (SaaS) layers, where cloud providers offer managed elasticity features, the VMs at the IaaS layer often lack such capabilities. This paper scrutinises the constraints surrounding the rapid elasticity of VMs within single and hybrid cloud environments at the IaaS layer. It provides a critical analysis of the existing research gaps, emphasising the necessity for the horizontal elasticity of VMs extended across hybrid clouds, coupled with predictive capabilities integrated into the elasticity mechanism. This paper’s focus is particularly beneficial in scenarios where workloads require VM provisioning from multiple clouds to eliminate vendor lock-in and enhance quality of service (QoS) assurances, especially in instances of platform failures. Through critical examination, several research challenges are identified, delineating the existing research gap and outlining future research directions. This paper contributes to the research challenges of VM elasticity in complex cloud environments and underscores the imperative for innovative solutions to address these challenges effectively.
Motivation and Scope of the Paper
-
Precisely forecasting the future demand by analysing the historical trends with anomaly detection.
-
Accurate autoscaling decision execution to address the VM provisioning or boot time delays (cold start).
-
More flexibility in cloud native VM autoscaling solutions, where the VM autoscaling can be extended across hybrid clouds.
-
Greater versatility in defining custom autoscaling policies using more user-defined and workload-specific autoscaling metrics.
-
Reviewing the current research work related to VM autoscaling to identify the research directions and gaps in proactive autoscaling and hybrid cloud autoscaling.
-
Identifying how proactive autoscaling and workload classification are introduced for container autoscaling using ML-based technologies.
-
Performing a comparison of the autoscaling offerings of three major public cloud platforms and one open-source cloud platform to identify the current gaps and issues.
-
Define future research directions to address the gaps identified in this review.
Structure of the Paper
|
Section |
Section Heading |
Brief Description |
|---|---|---|
|
Section 2 |
Rapid elasticity for VMs in Cloud Platforms and current challenges |
Discusses the commonly used autoscaling techniques in cloud computing within both the reactive and proactive autoscaling categories. |
|
Section 3 |
Autoscaling in Clouds—Previous Work |
Provides an overview of the selected papers, discussing the strengths and weaknesses of each work. |
|
Section 4 |
Methods and Materials |
Outlines the methodology used for the systematic review. |
|
Section 5 |
Classification of Autoscaling Techniques |
Offers a classification of commonly employed autoscaling techniques, along with a brief description of each method. |
|
Section 6 |
Commercial Autoscaling Approaches in Public Cloud Environments |
Discusses the autoscaling approaches used in three widely used commercial public cloud providers and one open-source-based cloud platform. |
|
Section 7 |
What are the Challenges to Achieve Autoscaling at IaaS Layer? |
Summarises the challenges from the review of commercial deployments (Section 5) and autoscaling approaches proposed in the reviewed papers (Section 6). |
|
Section 8 |
Conclusions and future research directions |
Concludes and offers future research directions are presented in this section. |
References
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in cloud computing: State of the art and research challenges. IEEE Trans. Serv. Comput. 2018, 11, 430–447.
- De Assuncao, M.D.; Cardonha, C.H.; Netto, M.A.; Cunha, R.L. Impact of user patience on auto-scaling resource capacity for cloud services. Future Gener. Comput. Syst. 2016, 55, 41–50.
- Qu, C.; Calheiros, R.N.; Buyya, R. Auto-scaling web applications in clouds: A taxonomy and survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–33.
- Mell, P.; Grance, T. The NISTDefinition of Cloud Computing Recommendations of the National Institute of Standards Technology , NIST. 2011. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf (accessed on 10 December 2023).



