Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Nicollas Oliveira | -- | 3831 | 2024-02-16 21:30:59 | | | |
| 2 | Lindsay Dong | + 3 word(s) | 3834 | 2024-02-18 02:22:19 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Oliveira, N.R.D.; Santos, Y.D.R.D.; Mendes, A.C.R.; Barbosa, G.N.N.; Oliveira, M.T.D.; Valle, R.; Medeiros, D.S.V.; Mattos, D.M.F. Standards for Health Data Systems. Encyclopedia. Available online: https://encyclopedia.pub/entry/55098 (accessed on 27 July 2026).
Oliveira NRD, Santos YDRD, Mendes ACR, Barbosa GNN, Oliveira MTD, Valle R, et al. Standards for Health Data Systems. Encyclopedia. Available at: https://encyclopedia.pub/entry/55098. Accessed July 27, 2026.
Oliveira, Nicollas Rodrigues De, Yago De Rezende Dos Santos, Ana Carolina Rocha Mendes, Guilherme Nunes Nasseh Barbosa, Marcela Tuler De Oliveira, Rafael Valle, Dianne Scherly Varela Medeiros, Diogo M. F. Mattos. "Standards for Health Data Systems" Encyclopedia, https://encyclopedia.pub/entry/55098 (accessed July 27, 2026).
Oliveira, N.R.D., Santos, Y.D.R.D., Mendes, A.C.R., Barbosa, G.N.N., Oliveira, M.T.D., Valle, R., Medeiros, D.S.V., & Mattos, D.M.F. (2024, February 16). Standards for Health Data Systems. In Encyclopedia. https://encyclopedia.pub/entry/55098
Oliveira, Nicollas Rodrigues De, et al. "Standards for Health Data Systems." Encyclopedia. Web. 16 February, 2024.
Copy Citation
The COVID-19 pandemic has highlighted the necessity for agile health services that enable reliable and secure information exchange, but achieving proper, private, and secure sharing of electronic medical records (EMRs) remains a challenge due to diverse data formats and fragmented records across multiple data silos, resulting in hindered coordination between healthcare teams, potential medical errors, and delays in patient care.
healthcare standards
health data systems
electronic medical records systems
1. Introduction
The healthcare sector is a typical example where sharing personal data between organizations is essential, and access to these data is intrinsically distributed. Healthcare professionals in many organizations need to analyze patient data to perform their tasks. However, these data are typically stored in silos in distinct locations and different formats, making it difficult to share. Thus, the complexity of the medical system prevents the patient’s entire medical history from being easily accessed when needed. In this way, much information is lost or exhaustively repeated, making the diagnosis and treatment of the patient difficult and harming the patient’s journey.
According to research from the Johns Hopkins American Hospital, medical errors rank as the third leading cause of death in the United States, often stemming from systemic issues like poorly coordinated care [1]. Overcoming the challenge of coordinating patient care can be achieved through secure and accurate sharing of patients’ data, granting healthcare teams access to comprehensive health histories, facilitating early diagnosis, and improving treatment efficacy. Achieving these benefits is made possible through standardized electronic medical records (EMRs) stored in computerized healthcare environments, containing vital personal information like diagnoses and treatments, distributed among hospitals and clinics where the patient received treatment. EMRs streamline patient data monitoring and access, enabling seamless care integration between medical teams and health facilities, thus providing patients with various levels of care with pertinent medical information. While sharing these data benefits the patient, leading to more accurate diagnoses and appropriate treatments, it poses a significant challenge concerning privacy and security, given the highly sensitive nature of the information stored in EMRs. Often, patient data are shared without explicit consent among untrusted entities such as healthcare professionals, pharmacies, patient families, and other physicians [2]. Although efforts are made to share patient data through secure institutional medical systems, non-institutionalized and insecure means of communication are sometimes used for simplicity and immediacy. During the COVID-19 pandemic, there has been a notable emphasis on streamlining consultations and enhancing information exchange among patients, healthcare providers, and health organizations. Consequently, patient records have gained increased importance in public health [3], as they offer valuable data on diagnoses and prescribed medications, enabling identifying individuals belonging to COVID-19 risk groups, among other applications. The broader availability of patient data in electronic formats has significant implications for decision making and continuity of care in both the public and private sectors, fostering seamless data exchange between these realms. Timely data regarding disease outbreaks is crucial in effectively coordinating national-level public health policies and prevention strategies.
The significance and relevance of data availability have been steadily increasing, with numerous establishments implementing this accessibility. In 2019, for instance, there was a notable rise in patient information in electronic format. Key improvements compared to 2018 included patient registration data (89% compared to 79%), the primary reasons for patient consultations (64% compared to 50%), and admission, transfer, and discharge records (56% compared to 43%) [4]. Notably, electronic systems in public establishments have seen remarkable growth in functionalities in recent years, particularly concerning the listing of all laboratory test results (from 17% in 2016 to 41% in 2019), patients using specific medications (from 18% in 2016 to 40% in 2019), and having medical prescriptions (from 29% to 51%) [4]. These improvements indicate an evolution in the level and complexity of adopted electronic systems, leading to reduced fragmentation in care provision, thus enhancing quality efficiency and minimizing gaps in care [5]. However, as data digitization practices advance and sensitive data generation increases significantly, the systems must address many challenges.
EMR systems predominantly rely on centralized client–server architectures, where a central authority holds full access to the entire system. However, this architecture brings forth particular challenges concerning privacy and security. System vulnerabilities can lead to failures and create opportunities for cyber attackers to breach patient data [6]. Managing these systems becomes a delicate task, requiring preserving privacy while ensuring data accessibility for authorized entities. Moreover, records are frequently stored in fragmented formats within local databases, hindering patients from accessing a comprehensive, consolidated electronic medical record [7].
Data format standardization is fundamental for achieving interoperability within the healthcare sector, entailing a unified language for exchanging and interpreting medical data and enabling diverse systems to communicate seamlessly. However, attaining such standardization presents notable challenges due to the escalating number of healthcare applications, EMRs, and medical devices, which have led to a rapid proliferation of varied data formats. This fragmentation poses substantial hurdles for healthcare professionals, researchers, and policymakers aiming to harness the power of data to enhance patient care, advance research endeavors, and facilitate evidence-based decision making.
Blockchain technology is emerging as a promising avenue for standardizing and achieving interoperability in EMRs. It aims to facilitate the verification and registration of EMRs through a consensus among peers participating in a peer-to-peer network. This approach ensures reliable execution of data access policies, thereby upholding data integrity, accountability, and non-repudiation [8]. Blockchain technology becomes particularly appealing for applications requiring input from multiple stakeholders, where trust is challenging to establish using conventional technologies.


2. Standards for Health Data Systems
Standards governing health data systems encompass a comprehensive set of norms, specifications, and guidelines designed to parameterize the collection, storage, processing, and sharing of clinical and administrative information within healthcare systems. Alongside standards for health systems, specific organizations contribute to standardizing communication methods between systems and structural norms for storing and representing clinical data, resulting in a diverse array of medical system standards worldwide.
Several global initiatives have pioneered these efforts to establish standards and guidelines that transcend borders and sectors. The Observational Medical Outcomes Partnership (OMOP) (available at https://www.ohdsi.org/data-standardization/ (accessed on 24 September 2023)) initiative focuses on standardizing observational health data. By creating a common framework for representing population health data, OMOP enables more consistent and comparative analyses, providing valuable insights into medical outcomes. Another influential global initiative is Integrating the Healthcare Enterprise (IHE) (available at https://www.ihe.net/ (accessed on 24 September 2023)), which aims to promote interoperability among healthcare information systems. By defining integration profiles based on established standards, IHE facilitates harmonizing diverse systems, enhancing collaboration and data exchange among healthcare entities.
2.1. Standards for Electronic Medical Record Systems
Standards for electronic medical records systems are centrally focused on promoting interoperability between different health systems and applications, allowing the sharing and exchanging of health information securely, efficiently, and accurately. Such standards support the formulation of reference models aligned with laws and regulations and dedicated to developing new health applications.
The Open Electronic Health Record (openEHR) is an organization dedicated to developing and maintaining software system specifications and standards for EMRs. While it proposes health system models, it does not create its applications. Instead, its primary contributions consist of two reference architectures designed to integrate health software solutions. openEHR specifies various system components alongside the architectures, encompassing communication, storage, integration, and data representation (available at https://openehr.org/developers (accessed on 24 September 2023)). One distinctive feature of the openEHR specifications is the adoption of a role-based approach, delegating healthcare professionals to define procedures and the initial level of data representation in the model, referred to as “archetypes”, which adapt to specific contexts.
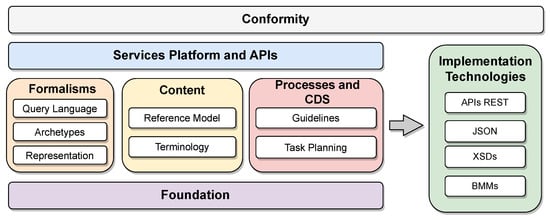
openEHR first specifies a general model organized into components. Each component and its specificities are detailed in the standard definitions. The two reference architectures specified by openEHR are particularizations of this general model. Figure 1 shows the organization of the specifications into functional blocks of the general model proposed by openEHR (available at https://specifications.openehr.org/releases/BASE/latest/architecture_overview.html (accessed on 24 September 2023)). These blocks are organized as follows:
Figure 1. Organization of the components of the openEHR reference model specifications.
openEHR’s initial reference architecture serves as a generic medical information system, providing a foundational framework for developing applications with assured interoperability. This achievement is made possible by defining all components based on standards established by openEHR and other groups like the HL7 organization, which sets communication and structure standards.
2.2. Content and Structure Standards
Content and structure standards play a crucial role in determining the structure of electronic documents and the types of data they should contain within the healthcare domain. Content standards focus on specifying the patient data to be stored and how they relate to the steps of care. Such standards add semantic meaning to documents and generate historical information for continuous treatment. In contrast, structure standards aim to ensure data sharing between systems and enhance interoperability among healthcare facilities without prescribing the specific transmission format of these documents.
Expressed in XML format, the Clinical Document Architecture (CDA) is a notable standard that contains patient data and care context. Developed and maintained by the HL7 organization, a leading standards group for medical systems, the CDA standard consolidates various historical variations and defines the implementation standard for CDA documents [9]. The CDA is tailored both in terms of content and structure, and it is organized into templates based on specific use cases, making it less generic but suitable for scenarios requiring a hierarchical approach. As a result, the CDA standard is organized into use-case-based templates, currently having 12 different specifications. The implementation is object-oriented, contains all the features of this paradigm, and is suitable for cases requiring hierarchy.
Being the next-generation standards framework developed by HL7, Fast Healthcare Interoperability Resources (FHIR) focuses on standardizing electronic medical records’ data representation and transactions. It is a set of rules and specifications based on key functionalities of traditional HL7 standards, including HL7 Version 2 (HL7 V2), HL7 Version 3 (HL7 V3), and the CDA. FHIR utilizes a building block called “resource” to represent interchangea ble data (available at https://www.hl7.org/fhir/structuredefinition.html (accessed on 24 September 2023)). Each resource follows a consistent format and contains various types of patient information, such as demographics, diagnoses, medications, allergies, and care plans. Resources are organized into sections and must include essential information, such as the type, an identifier, metadata, human-readable XHTML data summarizing the document, a reference to the document type in the system documentation, and standardized patient or examination data. FHIR allows representation in XML, JSON, and RDF formats, and it differs from the CDA as it is not limited to clinical information and does not require templates for interoperability. Instead, data interpretation is based on resource definitions, ensuring adequate data sharing.
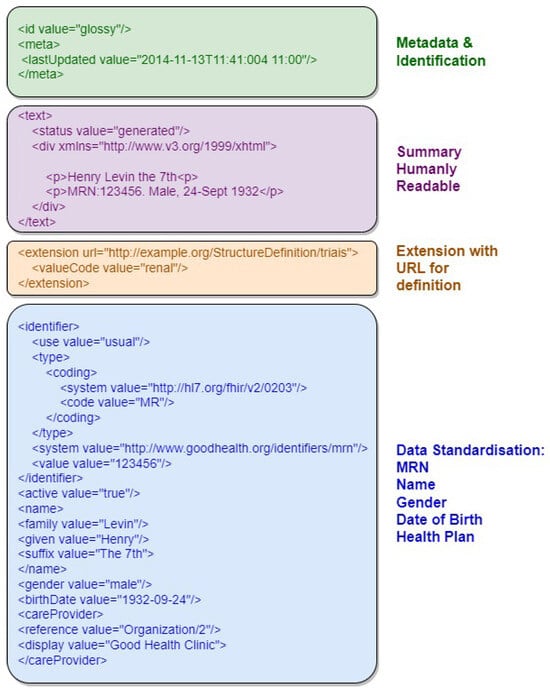
Figure 2 provides an example of an FHIR resource in XML format, highlighting its document structure sections, including resource identifier, version information, resource information in XHTML, and Uniform Resource Locator representation. The first section, in green, contains metadata and resource identification information. The following section, in purple, contains the human-readable summary, represented in XHTML format. The third section, in orange, contains additional information outside the basic definition of the Resource type. The last section, in blue, contains the record data.
Figure 2. Example of an FHIR resource with the document structure sections highlighted.
Digital Imaging and Communications in Medicine (DICOM) is an international standard for the communication, storage, and representation of medical images and data derived from computed tomography, magnetic resonance imaging, and radiography, among other imaging examinations [10]. As traditional image file formats (JPEG, TIFF, BMP) are insufficient for accurate diagnosis, the standard adds information to the files necessary for diagnostic purposes. This information includes demographic data about the patient, acquisition parameters for the imaging study, image dimensions, color space, and a host of additional information to correctly display the image on the computer.
The standard has been developed by a committee formed by the American College of Radiology (ACR) and the National Electrical Manufacturers Association (NEMA) and focuses on facilitating interoperability between medical imaging equipment. The committee specifies the network protocols for communication that equipment must use to transport data, the syntax and semantics of commands associated with data exchange in the context of medical imaging, a set of definitions for media storage services, and the specification of a proprietary file format and a standard for the structure of storage directories. All these specifications and definitions comprise the scope of the DICOM standard, which are expressed in service–object pair (SOP) classes. These classes represent services, such as storage using network, media, or web, operating on types of information objects, such as CT or MRI images.
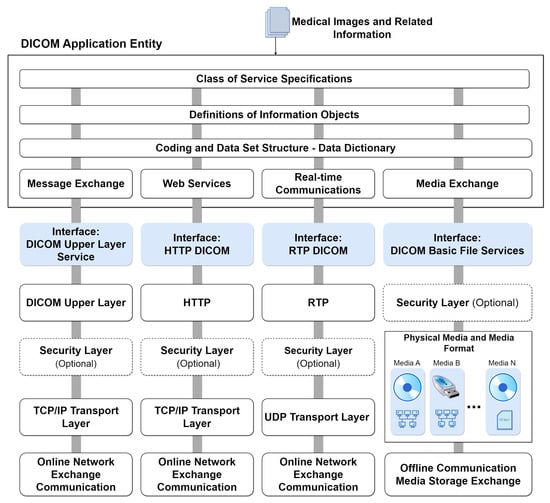
Figure 3 illustrates the comprehensive model of DICOM services and functions, specifying their roles in transporting image data, associated information, real-time communication, and direct file access. The general service model encompasses functionalities for storing, providing access to, and processing DICOM images. This includes transactions of DICOM documents with outputs for message exchange, web services (REST API), real-time transmission, and file export to physical media. These functions are part of the DICOM application and are usually made available on an online server. At the bottom of the figure, the communication and transport protocols tailored for each service type are depicted. These protocols form the foundation for integrating systems that consume data from the DICOM application. This integrated approach ensures seamless interaction and interoperability across various DICOM services.
Figure 3. DICOM services model with integrated protocols.
2.3. Communication Standards
FHIR was designed to focus on flexible implementation, taking advantage of established web communication conventions, such as data representation using JSON, XML, and data exchange through HTTP-based RESTful APIs. The standard supports exchanging messages and documents in decoupled systems or with service-oriented architectures, generally meeting more modern trends for software development. Resources defined by FHIR are optimized for performing stateless transactions through RESTful APIs. Transactions of this type are the only ones currently defined by the FHIR specification. Transactions follow a simple “request” and “response” pattern. Requests and responses can occur to obtain an individual or batch payload. The payload is composed of a header and the content of interest.
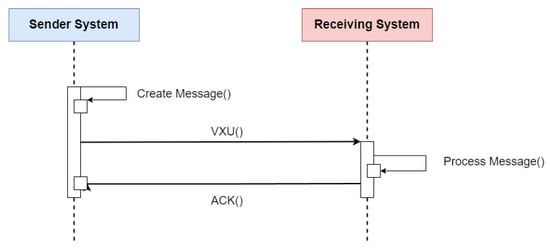
HL7 V2 (available at https://www.hl7.org/implement/standards/product_section.cfm?section=13 (accessed on)) is a standard for exchanging messages in the context of medical applications, whose main function is to define standards for the content or body of messages, a protocol for sending and receiving messages and defining different context requests, such as history requests and demographic data, among others. The HL7 V2 messaging framework is based on an event-based messaging paradigm. HL7 V2 defines the communication syntax at a low level, without worrying that messages are human-readable, by enclosing the entire message content in a string of characters. Figure 4 depicts the message content based on the HL7 V2 standard (available at https://www.ringholm.com/docs/04300_en.htm (accessed on 24 September 2023)), showing that a vertical bar sign separates data “|”, wherein the data identifier is on the left side while the value is on the right. However, recent HL7 V2 versions use XML as an alternative encoding format. Thus, the choice of which data and values must be in the message depends on the context of the request and its respective flow. Figure 5 shows the message flow for transferring immunization information from one health information system to another. The issuing system could be an EMR system, an immunization information system (IIS), or another type of health information system. An event such as an update or new record inserted in the issuing system initiates the creation and sending of a VXU message (vaccination update) containing an updated immunization record. The receiving system processes the message according to the used profile, applying local business rules.
Figure 4. Example of a glucose test result message in HL7 V2 standard.
Figure 5. Sequence diagram of the flow specification for updating a patient’s immunization history using the HL7 V2 standard. Adapted from [11].
The HL7 V3 (available at https://www.hl7.org/implement/standards/product_brief.cfm?product_id=186 (accessed on 24 September 2023)) differs from HL7 V2 by incorporating a reference information model (RIM) to configure the message format in object-oriented modeling. In HL7 V3, messages are encoded into a mapping of classes of information needed for the context of medical applications. Each class receives its unique object identifier (OID) to ensure the universality of the specification of each object in its context.
All the flows, communication protocols, and terminologies adopted for HL7 V2 form the basis for HL7 V3, which focuses on specifying the encoding of messages using XML and its syntax. In this way, the pattern becomes more intelligible and easier to implement. Figure 6 presents an excerpt of the same message (available at https://www.ringholm.com/docs/04300_en.htm (accessed on 24 September 2023)) shown in Figure 4, but structured according to the HL7 V3 standard. The example shows a patient’s glucose test result and additional information that adds semantics to the data hierarchically.
Figure 6. Example of a patient glucose test result message in the HL7 V3 standard.
To standardize image representation, DICOM specifies a protocol for exchanging messages. The protocol provides a communication framework for DICOM services and is compatible with TCP and IP protocols. This compatibility enables communication over the internet between different applications that implement the DICOM standard. The DICOM communication protocol was developed based on the model open systems interconnection (OSI) reference model and implements functionalities of the application, presentation, and session layers (available at https://docs.oracle.com/cd/E57425_01/121/IMDCM/ch_intro.htm#IMDCM13799 (accessed on 24 September 2023)). An application that uses the DICOM protocol is called an application entity (AE). Each AE can request or provide one of the services of the DICOM protocol, called classes of services. Each service class consists of data and a function related to those data. Each service class consists of data and a function related to those data.
2.4. Terminology Standards
Terminology standards are crucial in ensuring clarity and consistency of medical information across various systems, promoting interoperability among medical record systems. These standards establish a comprehensive set of codes and classification systems to represent health concepts, aiming to achieve a unified and standardized form of representation [12].
In Brazil, the ANS collaborated with the Brazilian Medical Association (Associação de Magistrados Brasileiros—AMB) and the Coordination of Information Systems for Health (Comitê de Padronização das Informações em Saúde Suplementar—COPISS) (note from ANS http://www.ans.gov.br/images/stories/Plano_de_saude_e_Operadoras/Area_do_consumidor/nota13_geas_ggras_dipro_17012013.pdf (accessed on 24 September 2023 )) to develop the Unified Terminology for Supplementary Health (Terminologia Unificada da Saúde Suplementar—TUSS), which serves as a coding standard for medical procedures used in private health plans. The TUSS table defines medical procedures’ nomenclature and corresponding identifier codes, groups, and subgroups. To facilitate seamless integration of this standard into healthcare provider systems, the ANS has made the TUSS standard available as a spreadsheet in xlsx format (available at https://www.gov.br/ans/pt-br/arquivos/assuntos/consumidor/o-que-seu-plano-deve-cobrir/correlacaotuss-rol_2021_site.xlsx (accessed on 24 September 2023)). By providing the terminology in this format, TUSS enables users to swiftly search for procedure codes, utilizing the standardized procedure names and available tools within electronic spreadsheet software. Moreover, the table format expedites the incorporation of new standard updates into databases, enabling integrated systems to stay up to date quickly.
The Systematized Nomenclature of Medicine—Clinical Terms (SNOMED CT) (available at https://www.snomed.org/five-step-briefing (accessed on 24 September 2023)) is a multilingual clinical terminology standard used to represent medical concepts in healthcare systems, with a focus on integrating terminologies from multiple countries. The standard has a broad scope, with more than 350,000 medical concepts specified in its terminology. To organize this vast collection of concepts, the standard organizes terms into three components:
-
Concepts: Unique and computable identifier, used to guarantee the uniqueness of each term;
-
Descriptions: Description of a uniquely and completely captured clinical idea called a fully specified name—(FSN), together with a set of synonyms that store the term name information in the multiple languages supported by the standard;
-
Relationships: Records relationships between concepts, which can be of different types specified by the pattern. Relationships can represent a hierarchy between concepts, so that a concept always has at least one “is a” relationship, which defines its type.
In addition to specifying terminology, SNOMED CT specifies implementation forms for storing terminology data in systems, also serving as a basis for aiding in developing medical applications. Despite being a non-profit foundation, SNOMED charges a fee for membership in the organization and access to terminology if the user comes from a region without federated bodies to the foundation (available at https://www.snomed.org/get-snomed (accessed on 24 September 2023)).
The Logical Observation Identifiers Names and Codes (LOINC) aims to eliminate ambiguity in the clinical records’ observation fields, proposes a comprehensive terminology for various types of observations related to exam and laboratory test results. It has emerged as a widely used database for categorizing and identifying observations from laboratory tests and clinical data, encompassing clinical observations, questionnaires, and other health assessments. This standard establishes a set of numerical codes and standardized names, facilitating efficient communication and data sharing between different healthcare systems. In contrast to other terminologies, LOINC’s primary objective is to create distinct codes for each type of test, exam, and observation to be utilized in the observation fields of communication standards, such as HL7 V2.
To achieve its goal, LOINC employs a logical framework consisting of six specification dimensions: (i) component (or analyte), representing the substance or entity being measured or observed; (ii) property, representing the characteristic or attribute of the analyte; (iii) time, representing the time interval during which an observation was made; (iv) system, representing the specimen or substance on which the observation was performed; (v) scale, defining the quantification or expression of the observation value; and (vi) method (optional), representing a high-level classification of how the observation was conducted, generally employed when the technique influences the clinical interpretation of results. This systematic categorization ensures clarity and consistency in defining and communicating various observations, contributing to seamless data exchange and enhanced interoperability in the healthcare domain.
The World Health Organization (WHO) has developed the International Classification of Diseases (ICD), now in its 11th edition, known as ICD-11, to enhance the statistical survey of causes of death and morbidity worldwide. This classification system plays a pivotal role in large-scale decision-making processes, intelligently influencing government planning and resource allocation. Consequently, data-driven planning significantly improves the quality of health services provided to the population [13]. The ICD-11 constitutes a systematically organized database, offering categories for diseases, disorders, health-related conditions, external causes of illness or death, anatomical details, environmental factors, activities, medications, vaccines, and other health-influencing information. Each classification level within the base is precisely specified according to its respective categories and assigned unique and sequential alphanumeric identification codes, establishing a hierarchy of related diseases [14].
For queries in the ICD-11 database, WHO provides three main components: a REST API over HTTP, a web graphical user interface (available at https://icd.who.int/browse11/l-m/en (accessed on 24 September 2023)), and a coding tool where users can assemble the correct ICD-11 code for a disease and its additional information. The tool is helpful for testing and validating software that uses the ICD-11 coding system.
References
- Makary, M.A.; Daniel, M. Medical error—The third leading cause of death in the US. BMJ 2016, 353, i2139.
- Dubovitskaya, A.; Xu, Z.; Ryu, S.; Schumacher, M.; Wang, F. Secure and trustable electronic medical records sharing using blockchain. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Bethesda, MD, USA, 2017; Volume 2017, p. 650.
- Stoeger, K.; Schmidhuber, M. The use of data from electronic health records in times of a pandemic—A legal and ethical assessment. J. Law Biosci. 2020, 7, lsaa041.
- Cetic.br. Pesquisa Sobre o uso das Tecnologias de Informação e Comunicação nos Estabelecimentos de Saúde Brasileiros: TIC Saúde 2019; Núcleo de Informação e Coordenação do Ponto BR (NIC.br): Sao Paulo, Brazil, 2020.
- Janett, R.S.; Yeracaris, P.P. Electronic Medical Records in the American Health System: Challenges and lessons learned. Cienc. Saude Coletiva 2020, 25, 1293–1304.
- Tanwar, S.; Parekh, K.; Evans, R. Blockchain-based electronic healthcare record system for healthcare 4.0 applications. J. Inf. Secur. Appl. 2020, 50, 102407.
- Mettler, M. Blockchain technology in healthcare: The revolution starts here. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–17 September 2016; pp. 1–3.
- Christidis, K.; Devetsikiotis, M. Blockchains and smart contracts for the internet of things. IEEE Access 2016, 4, 2292–2303.
- Health Level Seven International. HL7 Implementation Guide for CDA® Release 2: Consolidated CDA Templates for Clinical Notes (US Realm) Draft Standard for Trial Use Release 2.1; Technical Report; Health Level Seven International: Ann Arbor, MI, USA, 2015.
- DICOM Standards Committee. DICOM PS3.1 2023b. Technical Report; 2023. Available online: https://dicom.nema.org/medical/dicom/2023b/output/pdf/part01_changes.pdf (accessed on 24 September 2023).
- Savage, R. HL7 Version 2.5.1, Implementation Guide for Immunization Messaging; Technical Report; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2014.
- Massad, E.; Marin, H.d.F.; Azevedo Neto, R.S.d. (Eds.) O Prontuário Eletrônico do Paciente na Assistência, Informação e Conhecimento Médico; USP: São Paulo, Brazil, 2003.
- Harrison, J.E.; Weber, S.; Jakob, R.; Chute, C.G. ICD-11: An international classification of diseases for the twenty-first century. BMC Med. Inform. Decis. Mak. 2021, 21, 206.
- World Health Organization. International Classification of Diseases, Eleventh Revision ICD-11; Technical Report; World Health Organization: Geneva, Switzerland, 2022.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
803
Revisions:
2 times
(View History)
Update Date:
18 Feb 2024
Table of Contents



Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No