Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Charat Thongprayoon | -- | 2857 | 2024-01-16 12:52:36 | | | |
| 2 | Camila Xu | Meta information modification | 2857 | 2024-01-17 02:29:26 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Radhakrishnan, Y.; Cheungpasitporn, W. Large Language Models and Application in Nephrology. Encyclopedia. Available online: https://encyclopedia.pub/entry/53896 (accessed on 28 July 2026).
Miao J, Thongprayoon C, Suppadungsuk S, Krisanapan P, Radhakrishnan Y, Cheungpasitporn W. Large Language Models and Application in Nephrology. Encyclopedia. Available at: https://encyclopedia.pub/entry/53896. Accessed July 28, 2026.
Miao, Jing, Charat Thongprayoon, Supawadee Suppadungsuk, Pajaree Krisanapan, Yeshwanter Radhakrishnan, Wisit Cheungpasitporn. "Large Language Models and Application in Nephrology" Encyclopedia, https://encyclopedia.pub/entry/53896 (accessed July 28, 2026).
Miao, J., Thongprayoon, C., Suppadungsuk, S., Krisanapan, P., Radhakrishnan, Y., & Cheungpasitporn, W. (2024, January 16). Large Language Models and Application in Nephrology. In Encyclopedia. https://encyclopedia.pub/entry/53896
Miao, Jing, et al. "Large Language Models and Application in Nephrology." Encyclopedia. Web. 16 January, 2024.
Copy Citation
Large language models (LLMs), such as GPT-4, are an emergent technology that uses machine learning to process and analyze human language. Initially designed to improve natural language understanding and generation, LLMs have begun to extend their applicability beyond text-based tasks like translation, summarization, or conversational agents. Chain-of-thought prompting can enhance the problem-solving capabilities of AI models, particularly in complex and nuanced fields like medicine.
artificial intelligence
chain-of-thought prompting
large language models (LLMs)
enhanced care
1. Introduction
Large language models (LLMs), such as GPT-4, are an emergent technology that uses machine learning to process and analyze human language [1]. Initially designed to improve natural language understanding and generation, LLMs have begun to extend their applicability beyond text-based tasks like translation, summarization, or conversational agents [2]. The huge volume of data they can analyze and the quality of insight they can offer have made them valuable across a wide array of fields, from legal studies to astrophysics [2]. However, it is the field of medicine, particularly nephrology, that has seen a unique confluence of interests and technological capabilities through the deployment of these advanced LLMs [3].
LLMs are powered by deep neural networks, consisting of millions or even billions of parameters, trained on extensive datasets [2]. They have been used for sentiment analysis in marketing [4], automating document review in legal practices [5], and predicting protein folding in biochemistry [6]. With advancements in their underlying algorithms and computational power, LLMs have gained the capability to process and analyze context-rich data, paving the way for more nuanced applications. Given their multifaceted capabilities, LLMs can provide actionable insights based on patterns undetectable by human analysis alone, thereby becoming an invaluable tool in diverse disciplines [2].
Nephrology, the branch of medicine dedicated to studying kidney function, diagnosing kidney diseases, and treating conditions like chronic kidney disease, acute kidney injury, and end-stage renal disease, has its own set of intricate challenges. These range from early and accurate diagnosis to developing personalized treatment plans and managing comorbid conditions like diabetes or hypertension. The complexities often lie in the multifactorial nature of renal diseases, where genetics, lifestyle, and other health conditions play a synergistic role in influencing the course and prognosis of the disease. The integration of LLMs with nephrology is an emerging area, but initial studies and trials are showing promising results in various aspects. These include improving patient management in critical care nephrology [7], enhancing kidney transplant care [8], supporting renal diet planning [9], responding to patient inquiries [10][11][12][13], identifying pertinent nephrology literature [14][15][16], personalizing hemodialysis treatments [17], and aiding in scientific writing [18]. Utilizing the capabilities of large language models, medical professionals have the opportunity to enhance their diagnostic and treatment processes, as well as access in-depth data analyses and interpretations previously beyond reach.
Chain-of-thought prompting, a method that encourages LLMs to explain their reasoning process, acts as a catalytic function, amplifying the innate capabilities of LLMs [19][20]. By enhancing the precision and contextual comprehension of these models, it not only broadens their scope of application and increases their efficiency but also aligns them more intricately with human cognitive complexity and decision making. This approach, with its capacity to manage complex scenarios, focus on logical and sequential reasoning, and suitability for ethical and contextual judgments, becomes an invaluable asset for healthcare professionals. Its impact on improving the quality of medical care and research is anticipated to expand further.
2. Prompting Mechanisms in Large Language Models
LLMs like GPT-4 primarily function by comprehending human language, enabling them to handle a spectrum of tasks from basic text creation to intricate problem solving [21]. The versatility of LLMs can be significantly enhanced through the use of specialized prompting methods. Broadly, these prompting methods fall into three categories: zero-shot, few-shot, and chain-of-thought prompting (Figure 1) [22].
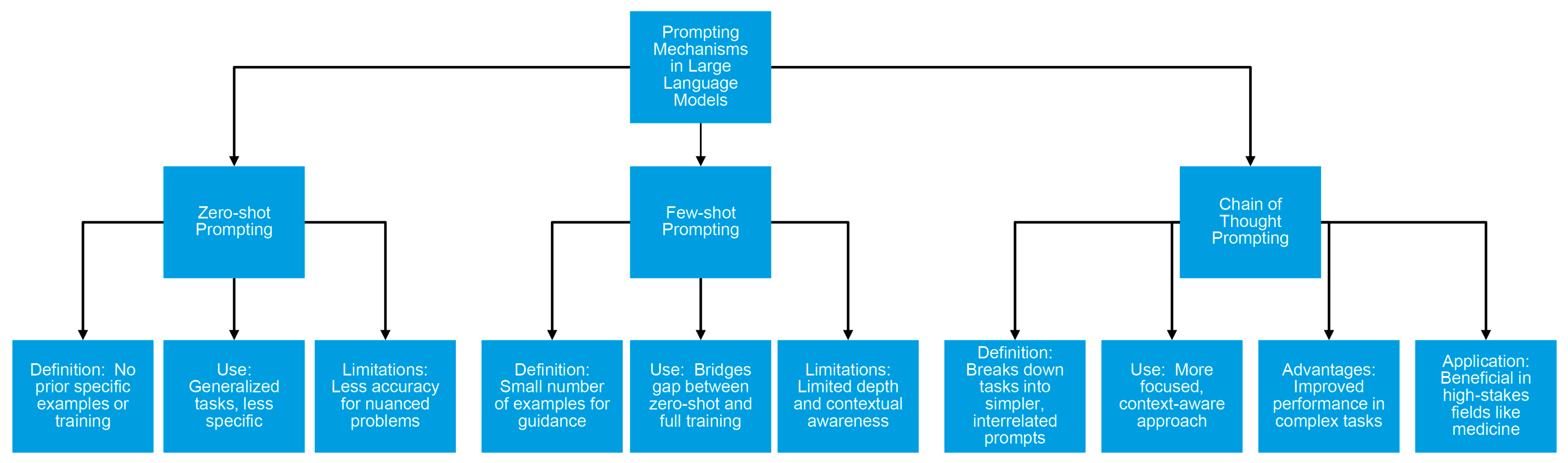
Figure 1. Prompting mechanisms in large language models.
2.1. Zero-Shot Prompting
Zero-shot prompting refers to a technique used with machine learning models, especially LLMs, in which the model is asked to perform a task without any prior specific examples or training on that specific task [23]. Essentially, the model uses its pre-existing knowledge, acquired during its extensive training on a diverse dataset, to infer how to handle the new task. This ability allows the model to generate responses or solve problems in situations it has not explicitly been trained for, showcasing its generalization capabilities [24]. Recent research has validated the effectiveness of zero-shot learning across a range of standard natural language understanding tasks [25]. While zero-shot prompting is useful for generalized tasks, it often lacks the specificity and accuracy required for more nuanced or specialized problems.
2.2. Few-Shot Prompting
This mechanism provides the model with a small number of examples (usually just a few) to guide its understanding of a task before presenting the main query [23]. By showing the model how similar problems were solved in the past, it is prompted to solve new but related challenges. This method bridges the gap between zero-shot learning, where no examples are provided, and full-scale training.
Few-shot prompting offers more efficient in-context learning than zero-shot learning, leading to more generalized and task-specific outcomes [26]. Research indicates that performance improvement, particularly in controlling hallucinations, tends to plateau after introducing three examples in a few-shot learning scenario. Additionally, the way prompts are framed is critical; clear and straightforward prompts tend to result in higher accuracy in task execution than those that are vague or overly detailed [27]. By showing the model a few instances of the desired output, it can more effectively generalize and perform the task with limited guidance. This approach leverages the model’s pretrained knowledge and adapts it to specific tasks with minimal examples. Few-shot prompting improves task-specific performance but can still suffer from limitations in terms of depth and contextual awareness.
2.3. Chain-of-Thought Prompting
Chain-of-thought prompting is a strategy employed to make LLMs work in a more focused, context-aware manner [19]. Traditionally, LLMs work by predicting the next word in a sequence based on the context of the words that came before it. While they can handle quite complex queries and prompts, these models may lack the granularity to reason through intricate problems or questions, sometimes failing to maintain the semantic thread of the conversation or analysis. To overcome this limitation, chain-of-thought prompting breaks down a complex task or query into a sequence of simpler, interrelated prompts [28]. Each prompt is designed to build upon the last, thereby guiding the LLM to think “step by step” through a problem. Essentially, you are creating a “chain” of thoughts that the model follows, much like a human would when approaching a multifaceted issue. In simple terms, it is about guiding the AI to “think aloud” as it approaches a problem. This method can effectively draw out the reasoning capabilities of LLMs and shows substantial improvements in performance on math problem-solving tasks [28][29][30]. This allows for a more nuanced and contextually relevant output, which is vital for applications requiring precision and depth.
The algorithmic implementation of chain-of-thought prompting generally includes explicit prompts, training for reasoning, and sequential processing [23][31]. Initially, the model is given prompts that explicitly ask it to show its working or reasoning steps. For instance, in a math problem, instead of directly providing the answer, the model is prompted to show each step of the calculation. Training for a reasoning process might involve fine tuning the model on datasets in which the answers are accompanied by step-by-step explanations. It is notable that the model processes the problem in a sequential manner, considering one aspect of the problem at a time, much like how a human would logically break down a complex problem.
The core architecture of LLMs like ChatGPT is based on the transformer architecture [1][21]. This design is particularly adept at handling sequential data, which is essential for the step-by-step reasoning required in chain-of-thought prompting. A key feature of this architecture is its attention mechanism, allowing the model to focus on different parts of the input sequence when generating each part of the output. This is crucial for maintaining coherence in multistep reasoning. In addition, the models consist of multiple layers of transformer blocks. Each layer contributes to the model’s ability to process and generate complex sequences of text. For instance, GPT-3 has 96 layers. Finally, a high parameter count (e.g., 175 billion in GPT-3 and 1.76 trillion in GPT-4) enables the model to store and recall a vast amount of information, which is essential for the broad knowledge base required in chain-of-thought reasoning [21].
The training data for these LLMs are primarily web-based, providing a rich and varied set of texts that cover an extensive range of topics, styles, and structures [21]. This diversity helps the model to develop a broad understanding of language and context. For chain-of-thought prompting, the relevance and quality of the training data are critical. The data must include examples that demonstrate logical reasoning and step-by-step problem solving. Moreover, before training, the data undergo significant preprocessing to remove noise, correct formatting issues, and ensure they are suitable for training a high-performing model.
While a single direct prompt can sometimes yield results similar to a chain-of-thought prompt, the latter often provides more consistent, detailed, and transparent responses for complex problems [19][24][32]. It is important to note that the effectiveness of a single direct prompt versus a chain-of-thought prompt can vary depending on several factors, such as the complexity of the task; the clarity and depth of the response; the model’s training and capabilities; the predictability and consistency; and the user intent and model interpretation, as well as application-specific considerations. In certain applications, like medical decision making or technical problem solving, the step-by-step reasoning provided by chain-of-thought prompts can be particularly valuable not just for the end answer but for understanding the rationale behind it. The choice between the two approaches should be guided by the specific task at hand, the desired depth of response, and the capabilities of the LLM being used.
2.4. Benchmark Responses for the Comparisons of Responses across Different Prompt Approaches
When evaluating the performance of AI models such as ChatGPT in diverse learning contexts, metrics including accuracy, fluency, and coherence are commonly employed to compare the models’ responses with the established ground truth [33]. For benchmarking, researchers often use specific datasets and tasks to evaluate the performance of language models across these different approaches. The benchmark responses are usually task specific [33]. For example, a common benchmark might involve question-answering tasks, where the model’s responses are compared against a set of predefined correct answers. Ground truth refers to the accurate, real-world information or the correct answer against which the model’s output is compared. In the context of language models, ground truth is typically a set of responses or data that are known to be true or correct. These are used to evaluate the accuracy and reliability of the model’s responses. It is worth noting that these benchmarks can vary significantly based on the specific tasks, the complexity of the questions, and the domain of knowledge being tested. Additionally, the performance of a model can be influenced by its training data, architecture, and the specific techniques used for training and prompting. Each of these prompt mechanisms has its advantages and disadvantages, but for applications in high-stakes fields like medicine, chain-of-thought prompting is emerging as particularly beneficial [34].
3. Significance of Chain-of-Thought Prompting in Medicine
Chain-of-thought prompting can enhance the problem-solving capabilities of AI models, particularly in complex and nuanced fields like medicine. By guiding AI through a logical sequence of thoughts or steps, much like a human would think through a problem, it helps the model to process and analyze medical data more effectively. This can lead to more accurate diagnoses, better understanding of patient symptoms, and tailored treatment plans. Additionally, this approach can improve the AI’s ability to analyze and understand complex medical literature and research, thereby aiding medical professionals in keeping up to date with the latest findings and treatments. The significance of chain-of-thought prompting in medical applications extends to several key aspects (Figure 2), including those shown below.
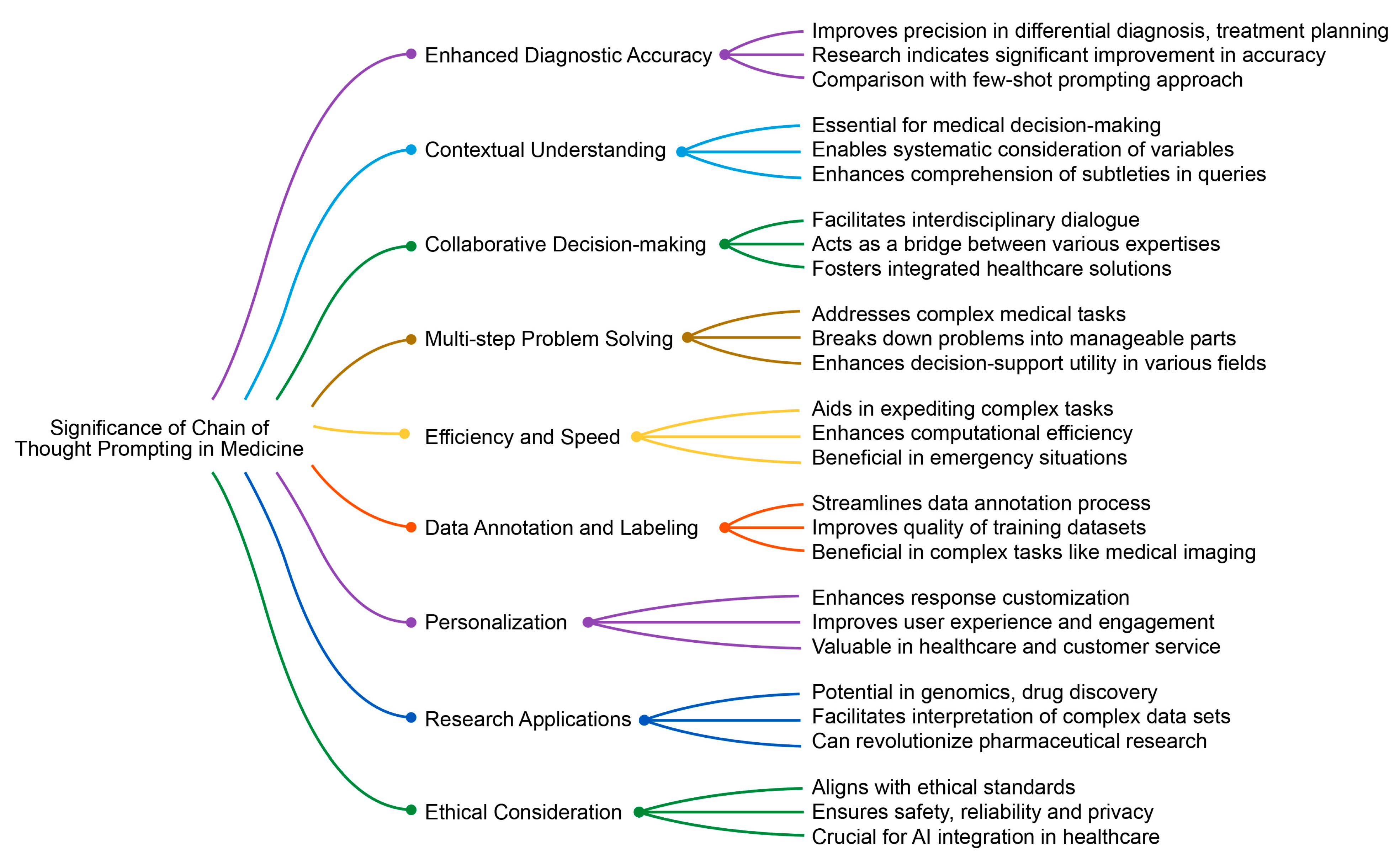
Figure 2. Significance of chain-of-thought prompting in medicine.
3.1. Enhanced Diagnostic Accuracy
In the medical field, where the scope for error is extremely narrow and errors can have critical consequences, chain-of-thought prompting is vital for ensuring high accuracy. By guiding an LLM through a series of logical, step-by-step reasonings [32], it enhances the model’s precision, which is particularly beneficial in areas like differential diagnosis, treatment planning, and complex data interpretation. Research has shown that this method of prompting can significantly improve diagnostic accuracy [35][36], with one study indicating a 15% increase in accuracy compared to standard prompting methods [36]. However, a different study revealed that chain-of-thought prompting did not significantly outperform the few-shot prompting approach in medical question-answering tasks [26].
3.2. Contextual Understanding
Medical decision making relies on a deep understanding of a patient’s medical history, current conditions, and various other factors. AI strives to mimic human cognitive processes, and chain-of-thought prompting is pivotal in this context. It enables LLMs to systematically consider a range of variables, providing healthcare professionals with contextually appropriate recommendations or solutions [20][26][28]. This approach is crucial for enhancing LLMs’ ability to comprehend the subtleties of a query or problem, particularly in areas like natural language inference, machine translation, and ethical decision-making algorithms, where the context can significantly influence the outcome.
3.3. Collaborative Decision Making
Medical decision making frequently requires the collaboration of experts from different fields. Chain-of-thought prompting enhances this collaborative process by empowering LLMs to create sequences of thoughts or questions that steer interdisciplinary dialogue. This method transforms an LLM into a valuable instrument for facilitating complex discussions, ensuring comprehensive consideration of all pertinent aspects. It acts as a bridge between various types of expertise, aiding in synthesizing diverse perspectives and fostering a more integrated approach to healthcare solutions. By highlighting key points and prompting relevant questions, it helps maintain focus on critical issues, ensuring that all significant factors in patient care are addressed.
3.4. Multistep Problem Solving
Many medical tasks, such as formulating treatment plans or planning surgical procedures, require multistep reasoning. Traditional LLMs often face limitations in addressing complex problems that demand such reasoning. Chain-of-thought prompting addresses this by enabling the model to break down problems into smaller, manageable parts, process each part, and then synthesize them into a comprehensive solution [34][36]. This approach, where the problem is deconstructed into a sequence of interlinked prompts, allows the model to offer thorough solutions that encompass every phase of a medical procedure or treatment strategy. The implications of this extend beyond healthcare, finding relevance in scientific research, engineering, and complex strategy-based activities like chess, where foresight and multistep planning are key. This method not only improves the accuracy and relevance of the solutions provided but also enhances the model’s utility as a decision support tool in various fields requiring intricate, step-wise analysis.
3.5. Efficiency and Speed
In medical environments, where quick decision making is crucial, chain-of-thought prompting can be a valuable asset. It aids in expediting complex tasks like differential diagnosis or treatment planning, particularly benefiting less experienced clinicians or those working in settings with limited resources. Furthermore, AI algorithms can be resource intensive. By decomposing tasks into simpler components, chain-of-thought prompting enhances the computational efficiency [28]. This feature is especially beneficial in scenarios requiring rapid responses, such as in emergency medical situations or autonomous driving, where the ability to make swift, accurate decisions is paramount.
3.6. Data Annotation and Labeling
In the realm of supervised learning, the process of data annotation is notably laborious and time-consuming. Chain-of-thought prompting offers a solution to this challenge by directing LLMs to produce contextually precise annotations or labels [28][37]. This can substantially quicken the training of other machine learning models by providing them with accurately labeled datasets more efficiently. Expanding this approach, it can be particularly beneficial in situations where data are voluminous or complex, such as in medical imaging or natural language processing tasks, where a nuanced understanding is crucial. By automating and refining the annotation process, chain-of-thought prompting not only saves valuable time and resources but also enhances the quality of training datasets, potentially leading to more accurate and robust machine learning models.
3.7. Personalization
Chain-of-thought prompting enhances the ability to grasp the nuances of specific contexts, leading to more personalized responses [34][38]. This is particularly valuable in user-centric applications. Customizing responses to align with individual preferences or needs can significantly enhance the user experience and engagement. In fields such as customer service, healthcare, or education, where personalization is key, this approach enables the development of AI systems that are more responsive and attuned to the unique circumstances or requirements of each user. By delivering more targeted and relevant interactions, this not only improves satisfaction but also fosters a deeper connection and trust between the user and the AI system.
3.8. Research Applications
Chain-of-thought prompting holds immense potential in medical research, particularly in specialized areas like genomics, drug discovery, and epidemiological modeling. It can steer LLMs to not only generate innovative research hypotheses but also interpret complex datasets more efficiently, thus fast-tracking the advancement of medical science. This method of prompting facilitates deep, complex reasoning in LLMs, which can revolutionize areas such as pharmaceutical research [31][39]. For example, in the synthesis of new drugs, chain-of-thought prompting could guide LLMs through the intricate steps of molecule synthesis. This approach not only brings a fresh perspective to drug discovery but also significantly enhances the process, potentially leading to breakthroughs in the creation of new medications and treatments.
References
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 11 November 2023).
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and Applications of Large Language Models. arXiv 2023, arXiv:2307.10169.
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.N.; Laleh, N.G.; Loffler, C.M.L.; Schwarzkopf, S.C.; Unger, M.; Veldhuizen, G.P.; et al. The future landscape of large language models in medicine. Commun. Med. 2023, 3, 141.
- Khawaja, R. 2023 Sentiment Analysis: Marketing with Large Language Models (LLMs). Available online: https://datasciencedojo.com/blog/sentiment-analysis-in-llm/# (accessed on 12 September 2023).
- Sydorenko, P. Top 5 Applications Of Large Language Models (Llms) in Legal Practice. Available online: https://medium.com/jurdep/top-5-applications-of-large-language-models-llms-in-legal-practice-d29cde9c38ef (accessed on 22 August 2023).
- Perez, R.; Li, X.; Giannakoulias, S.; Petersson, E.J. AggBERT: Best in Class Prediction of Hexapeptide Amyloidogenesis with a Semi-Supervised ProtBERT Model. J. Chem. Inf. Model. 2023, 63, 5727–5733.
- Suppadungsuk, S.; Thongprayoon, C.; Miao, J.; Krisanapan, P.; Qureshi, F.; Kashani, K.; Cheungpasitporn, W. Exploring the Potential of Chatbots in Critical Care Nephrology. Medicines 2023, 10, 58.
- Garcia Valencia, O.A.; Thongprayoon, C.; Jadlowiec, C.C.; Mao, S.A.; Miao, J.; Cheungpasitporn, W. Enhancing Kidney Transplant Care through the Integration of Chatbot. Healthcare 2023, 11, 2518.
- Qarajeh, A.; Tangpanithandee, S.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Aiumtrakul, N.; Garcia Valencia, O.A.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. AI-Powered Renal Diet Support: Performance of ChatGPT, Bard AI, and Bing Chat. Clin. Pract. 2023, 13, 1160–1172.
- Miao, J.; Thongprayoon, C.; Garcia Valencia, O.A.; Krisanapan, P.; Sheikh, M.S.; Davis, P.W.; Mekraksakit, P.; Suarez, M.G.; Craici, I.M.; Cheungpasitporn, W. Performance of ChatGPT on Nephrology Test Questions. Clin. J. Am. Soc. Nephrol. 2024, 19, 35–43.
- Miao, J.; Thongprayoon, C.; Cheungpasitporn, W. Assessing the Accuracy of ChatGPT on Core Questions in Glomerular Disease. Kidney Int. Rep. 2023, 8, 1657–1659.
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596.
- Yano, Y.; Nishiyama, A.; Suzuki, Y.; Morimoto, S.; Morikawa, T.; Gohda, T.; Kanegae, H.; Nakashima, N. Relevance of ChatGPT’s Responses to Common Hypertension-Related Patient Inquiries. Hypertension 2023, 81, e1–e4.
- Suppadungsuk, S.; Thongprayoon, C.; Krisanapan, P.; Tangpanithandee, S.; Garcia Valencia, O.; Miao, J.; Mekraksakit, P.; Kashani, K.; Cheungpasitporn, W. Examining the Validity of ChatGPT in Identifying Relevant Nephrology Literature: Findings and Implications. J. Clin. Med. 2023, 12, 5550.
- Aiumtrakul, N.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches. J. Pers. Med. 2023, 13, 1457.
- Lemley, K.V. Does ChatGPT Help Us Understand the Medical Literature? J. Am. Soc. Nephrol. 2023, 10–1681.
- Hueso, M.; Alvarez, R.; Mari, D.; Ribas-Ripoll, V.; Lekadir, K.; Vellido, A. Is generative artificial intelligence the next step toward a personalized hemodialysis? Rev. Invest. Clin. 2023, 75, 309–317.
- Daugirdas, J.T. OpenAI’s ChatGPT and Its Potential Impact on Narrative and Scientific Writing in Nephrology. Am. J. Kidney Dis. 2023, 82, A13–A14.
- Mayo, M. Unraveling the Power of Chain-of-Thought Prompting in Large Language Models. Available online: https://www.kdnuggets.com/2023/07/power-chain-thought-prompting-large-language-models.html (accessed on 13 November 2023).
- Ott, S.; Hebenstreit, K.; Lievin, V.; Hother, C.E.; Moradi, M.; Mayrhauser, M.; Praas, R.; Winther, O.; Samwald, M. ThoughtSource: A central hub for large language model reasoning data. Sci. Data 2023, 10, 528.
- Ecoffet, A. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774.
- Wolff, T. How to Craft Prompts for Maximum Effectiveness. Available online: https://medium.com/mlearning-ai/from-zero-shot-to-chain-of-thought-prompt-engineering-choosing-the-right-prompt-types-88800f242137 (accessed on 14 November 2023).
- Ramlochan, S. Master Prompting Concepts: Zero-Shot and Few-Shot Prompting. Available online: https://promptengineering.org/master-prompting-concepts-zero-shot-and-few-shot-prompting/ (accessed on 25 April 2023).
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayshi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. CM Comput. Surv. 2023, 55, 1–35.
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Tao, D. Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT. arXiv 2023, arXiv:2302.10198.
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180.
- Pal, A.; Umapathi, L.K.; Sankarasubbu, M. Med-HALT: Medical Domain Hallucination Test for Large Language Models. arXiv 2023, arXiv:2307.15343.
- Wei, J.; Wang, X.; Schuurmans, D.; DBosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903.
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168.
- Wadhwa, S.; Amir, S.; Wallace, B.C. Revisiting Relation Extraction in the era of Large Language Models. Proc. Conf. Assoc. Comput. Linguist. Meet. 2023, 2023, 15566–15589.
- Shin, E.; Ramanathan, M. Evaluation of prompt engineering strategies for pharmacokinetic data analysis with the ChatGPT large language model. J. Pharmacokinet. Pharmacodyn. 2023, 1–8.
- Oeze, C. The Importance of Chain-of-Thought Prompting. Available online: https://medium.com/@CameronO/the-importance-of-chain-of-thought-prompting-97fbbe39d753 (accessed on 17 May 2023).
- Fu, C.; Chen, P.; Shen, Y.; Qin, Y.; Zhang, M.; Lin, X.; Yang, J.; Zheng, X.; Li, K.; Sun, X.; et al. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. arXiv 2023, arXiv:2306.13394.
- Yu, P.; Xu, H.; Hu, X.; Deng, C. Leveraging Generative AI and Large Language Models: A Comprehensive Roadmap for Healthcare Integration. Healthcare 2023, 11, 2776.
- Buckley, T.; Diao, J.A.; Adam, R.; Manrai, A.K. Accuracy of a Vision-Language Model on Challenging Medical Cases. arXiv 2023, arXiv:2311.05591.
- Wu, C.-K.; Chen, W.-L.; Chen, H.-H. Large Language Models Perform Diagnostic Reasoning. Available online: https://arxiv.org/abs/2307.08922 (accessed on 18 July 2023).
- Shum, K.; Diao, S.; Zhang, T. Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data. arXiv 2023, arXiv:2302.12822.
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.W.; Liu, N. Large language models in health care: Development, applications, and challenges. Healthc. Sci. 2023, 2, 255–263.
- Eisenstein, M. AI-enhanced protein design makes proteins that have never existed. Nat. Biotechnol. 2023, 41, 303–305.
More
Information
Subjects:
Medical Informatics
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
766
Revisions:
2 times
(View History)
Update Date:
17 Jan 2024
Table of Contents



Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No