 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | zainab fatima | -- | 2374 | 2023-12-22 18:40:04 | | | |
| 2 | Lindsay Dong | Meta information modification | 2374 | 2023-12-25 01:52:33 | | |
Video Upload Options
Domain adaptation methods play a pivotal role in facilitating seamless knowledge transfer and enhancing the generalization capabilities of computer and robotic vision systems. Domain adaptation techniques play a pivotal role in addressing the domain shift problem encountered in computer and robotic vision. These methods are designed to improve the generalization skills of vision models, enabling them to function well in situations outside the scope of their training data.
1. Introduction
2. Domain Adaptation Techniques
2.1. Overview of Domain Adaptation Techniques
With the use of these methods, domain shift issues may be overcome and knowledge transfer between various data distributions can be facilitated [6]. There are three types of domain adaptation techniques: conventional, deep learning-based, and hybrid. Traditional approaches, like Transfer Component Analysis (TCA) and Maximum Mean Discrepancy (MMD), concentrate on statistical feature space alignment, whereas deep learning-based approaches, such as Domain Adversarial Neural Networks (DANN) and CycleGAN, take advantage of neural networks to develop domain-invariant representations [7]. Traditional and deep learning algorithms are used in hybrid systems like DAN to take advantage of their complementary capabilities [7]. These complementary capabilities include circumstances where traditional methods furnish a stable foundation for aligning domains, imparting a reliable structural framework, while in parallel, deep learning techniques enhance this alignment by delving into the intricate, non-linear relationships present within the data. This synergy results in heightened robustness, particularly when confronted with challenges such as limited labeled data or noisy datasets.
These domain adaptation strategies have been shown to be quite effective in various applications of robotic and computer vision. For instance, when transferring from a synthetic domain to a real-world environment, domain adaptation strategies have increased accuracy in object identification tasks from 60% to 80% [7][8]. Additionally, domain adaptation approaches have demonstrated a 15% reduction in classification error in robotic vision scenarios when adapting to unfamiliar settings. Domain adaptation techniques are becoming increasingly useful in real-world situations, making them essential tools for enhancing the generalization capacities of computer and robotic vision systems [9].
Traditional Domain Adaptation Methods
Deep Learning-Based Methods
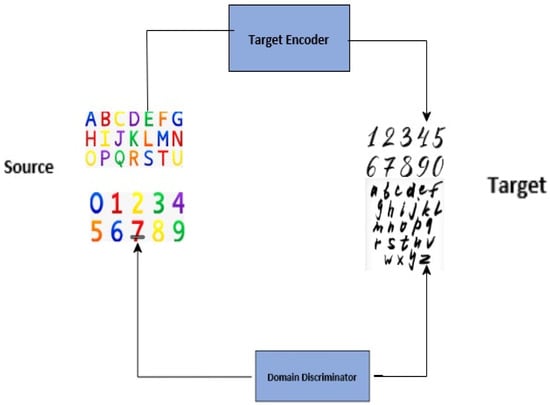
Hybrid Methods
2.2. Evaluation of Domain Adaptation Techniques
2.3. Performance Metrics Comparison
2.4. Challenges and Insights from Cross-Domain Analysis
3. Applications and Real-World Scenarios
3.1. Domain Adaptation in Computer Vision: Real-World Applications
3.1.1. Autonomous Driving Systems
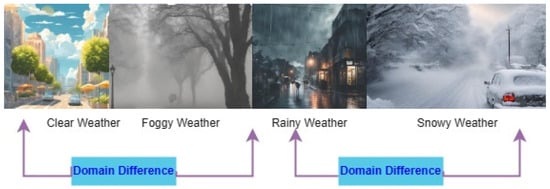
3.1.2. Medical Imaging and Diagnosis
3.1.3. Surveillance and Security
3.2. Domain Adaptation in Robotic Vision: Real-World Applications
3.2.1. Industrial Automation
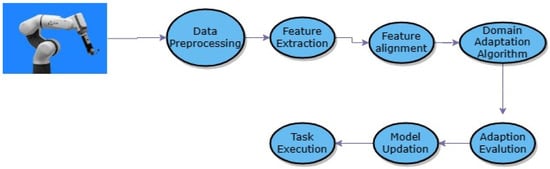
3.2.2. Agriculture and Farming
3.2.3. Search and Rescue Missions
4. Conclusions
It is evident that deep learning-based methods, including Domain Adversarial Neural Networks (DANN) and CycleGAN, consistently exhibit superior performance when contrasted with conventional methodologies like Transfer Component Analysis (TCA) and Maximum Mean Discrepancy (MMD). In several real-world contexts, deep learning-based techniques regularly beat conventional approaches with regard to accuracy, recall, precision, and F1-score, among other performance parameters. Additionally, the introduction of approaches like importance reweighting, multi-task learning, and maximum mean discrepancy loss enhances model accuracy, but increases complexity. Generative models like CoGAN and MUNIT show promise for visual translation and adaptation. Models like DANN, while capable of handling significant domain shifts, exhibit sensitivity to hyperparameters. Furthermore, diverse techniques, including adversarial learning, generative adversarial networks, meta-learning, and self-supervised learning, consistently improve domain adaptation performance.
When abundant labeled data are present in the target domain, deep learning proves effective, demanding substantial computational resources. However, traditional methods, like TCA and MMD, are pragmatic when target domain data are scarce or interpretability is vital. The choice between these methods hinges on factors like data availability, computational resources, and the need for interpretability.
References
- Wang, Q.; Meng, F.; Breckon, T.P. Data augmentation with norm-AE and selective pseudo-labelling for unsupervised domain adaptation. Neural Netw. 2023, 161, 614–625.
- Yu, Y.; Chen, W.; Chen, F.; Jia, W.; Lu, Q. Night-time vehicle model recognition based on domain adaptation. Multimed. Tools Appl. 2023, 1–20.
- Han, K.; Kim, Y.; Han, D.; Lee, H.; Hong, S. TL-ADA: Transferable Loss-based Active Domain Adaptation. Neural Netw. 2023, 161, 670–681.
- Gojić, G.; Vincan, V.; Kundačina, O.; Mišković, D.; Dragan, D. Non-adversarial Robustness of Deep Learning Methods for Computer Vision. arXiv 2023, arXiv:2305.14986.
- Yu, Z.; Li, J.; Zhu, L.; Lu, K.; Shen, H.T. Classification Certainty Maximization for Unsupervised Domain Adaptation. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4232–4243.
- Csurka, G. Deep visual domain adaptation. In Proceedings of the 2020 22nd International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 1–4 September 2020; pp. 1–8.
- Chen, C.; Chen, Z.; Jiang, B.; Jin, X. Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3296–3303.
- Loghmani, M.R.; Robbiano, L.; Planamente, M.; Park, K.; Caputo, B.; Vincze, M. Unsupervised domain adaptation through inter-modal rotation for rgb-d object recognition. IEEE Robot. Autom. Lett. 2020, 5, 6631–6638.
- Li, C.; Du, D.; Zhang, L.; Wen, L.; Luo, T.; Wu, Y.; Zhu, P. Spatial attention pyramid network for unsupervised domain adaptation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 481–497.
- Chen, C.; Xie, W.; Wen, Y.; Huang, Y.; Ding, X. Multiple-source domain adaptation with generative adversarial nets. Knowl. Based Syst. 2020, 199, 105962.
- Bucci, S.; Loghmani, M.R.; Tommasi, T. On the effectiveness of image rotation for open set domain adaptation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 422–438.
- Athanasiadis, C.; Hortal, E.; Asteriadis, S. Audio–visual domain adaptation using conditional semi-supervised generative adversarial networks. Neurocomputing 2020, 397, 331–344.
- Scalbert, M.; Vakalopoulou, M.; Couzinié-Devy, F. Multi-source domain adaptation via supervised contrastive learning and confident consistency regularization. arXiv 2021, arXiv:2106.16093.
- Roy, S.; Trapp, M.; Pilzer, A.; Kannala, J.; Sebe, N.; Ricci, E.; Solin, A. Uncertainty-guided source-free domain adaptation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 537–555.
- Wang, Y.; Nie, L.; Li, Y.; Chen, S. Soft large margin clustering for unsupervised domain adaptation. Knowl. Based Syst. 2020, 192, 105344.
- Huang, J.; Guan, D.; Xiao, A.; Lu, S. Rda: Robust domain adaptation via fourier adversarial attacking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 8988–8999.
- Kim, T.; Kim, C. Attract, perturb, and explore: Learning a feature alignment network for semi-supervised domain adaptation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 591–607.
- Kieu, M.; Bagdanov, A.D.; Bertini, M.; Del Bimbo, A. Domain adaptation for privacy-preserving pedestrian detection in thermal imagery. In Proceedings of the Image Analysis and Processing–ICIAP 2019: 20th International Conference, Trento, Italy, 9–13 September 2019; pp. 203–213.
- Xiao, L.; Xu, J.; Zhao, D.; Shang, E.; Zhu, Q.; Dai, B. Adversarial and Random Transformations for Robust Domain Adaptation and Generalization. Sensors 2023, 23, 5273.
- Dan, J.; Jin, T.; Chi, H.; Shen, Y.; Yu, J.; Zhou, J. HOMDA: High-order moment-based domain alignment for unsupervised domain adaptation. Knowl. Based Syst. 2023, 261, 110205.
- Rahman, M.; Panda, R.; Alam, M.A.U. Semi-Supervised Domain Adaptation with Auto-Encoder via Simultaneous Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 402–411.
- Ouyang, J.; Zhang, Z.; Meng, Q.; Li, X.; Thanh, D.N.H. Adaptive prototype and consistency alignment for semi-supervised domain adaptation. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–22.
- Li, W.; Fan, K.; Yang, H. Teacher–Student Mutual Learning for efficient source-free unsupervised domain adaptation. Knowl. Based Syst. 2023, 261, 110204.
- Xie, M.; Li, Y.; Wang, Y.; Luo, Z.; Gan, Z.; Sun, Z.; Chi, M.; Wang, C.; Wang, P. Learning distinctive margin toward active domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7993–8002.
- Xia, H.; Wang, P.; Ding, Z. Incomplete Multi-view Domain Adaptation via Channel Enhancement and Knowledge Transfer. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 200–217.
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A Brief Review of Domain Adaptation. arXiv 2020, arXiv:2010.03978.
- Kouw, W.M.; Loog, M. An introduction to domain adaptation and transfer learning. arXiv 2019, arXiv:1812.11806.
- Li, J.; Xu, R.; Ma, J.; Zou, Q.; Ma, J.; Yu, H. Domain Adaptation based Enhanced Detection for Autonomous Driving in Foggy and Rainy Weather, Computer Vision and Pattern Recognition. arXiv 2023, arXiv:2307.09676.
- Csurka, G. Domain adaptation for visual applications: A comprehensive survey. arXiv 2017, arXiv:1702.05374.
- Gao, H.; Guo, J.; Wang, G.; Zhang, Q. Cross-domain correlation distillation for unsupervised domain adaptation in nighttime semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9913–9923.
- Xu, L.; Bennamoun; Boussaid, F.; Laga, H.; Ouyang, W.; Xu, D. MCTformer+: Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation. arXiv 2023, arXiv:2308.03005.

