Resilience, characterized by the ability to withstand, absorb, and quickly recover from natural disasters and human-induced disruptions, has become paramount in ensuring the stability and dependability of critical infrastructure. The linkage between Deep Reinforcement Learning (DRL) and power system resilience is forged through a systematic classification of DRL applications into five pivotal dimensions: dynamic response, recovery and restoration, energy management and control, communications and cybersecurity, and resilience planning and metrics development. This structured categorization facilitates a methodical exploration of how DRL methodologies can effectively tackle critical challenges within the domain of power and energy system resilience.
1. Introduction
The growing influence of global warming, exemplified by the increasing prevalence of hurricanes and other natural disasters, has heightened the importance of power and energy system resilience. While power infrastructure has historically focused on reliability, aiming to withstand known threats and ensure uninterrupted power supply, the rise in extreme weather events presents a significant challenge [1]. Between 2003 and 2012, approximately 679 large-scale power outages in the United States were attributed to extreme weather, each affecting a minimum of 50,000 customers and resulting in an annual economic loss exceeding USD 18 billion [2]. These recurring and disruptive events underscore the limitations of current power facilities in effectively mitigating their impact [3]. While the likelihood of extreme natural events may be relatively low, the severity of their impact is indisputable. Consequently, there is an urgent need to enhance power and energy systems’ resilience to withstand and recover from such events.
Within power and energy systems, Deep Reinforcement Learning (DRL), a combination of reinforcement learning (RL) and deep learning, has emerged as an attractive alternative for conventional analytical and heuristic methods, offering solutions to their inherent shortcomings. Similar to other learning-driven methodologies, DRL makes use of past experiences to inform decision making. In [4], a real-time dynamic optimal energy management system for microgrids utilized DRL, specifically the proximal policy optimization (PPO) technique, to enhance efficiency and stability while integrating renewable energy sources. This approach showcased superior computational accuracy and efficiency compared to conventional mathematical programming or heuristic strategies. Additionally, in [5], a new energy management approach employed DRL within a Markov decision process (MDP) framework to minimize daily operating costs without the need for explicit uncertainty prediction, highlighting its effectiveness with real power-grid data. Furthermore, an innovative DRL-based Volt-VAR control and optimization method was introduced in [6], showcasing its effectiveness in improving voltage profiles, reducing power losses, and optimizing operational costs on various test cases. References [7][8] implemented Volt-VAR optimization in distribution grids with high DER penetration and volt-VAR control in active distribution systems, respectively, both leveraging DRL for efficient reactive power management. A DRL-based trusted collaborative computing has been proposed and analyzed in [9] for intelligent vehicle networks. A federated DRL-based approach for wind power forecasting has been proposed in [10], which is supposed to handle data sharing and privacy concerns.
2. Deep Reinforcement Learning Foundations
2.1. Reinforcement Learning (RL)
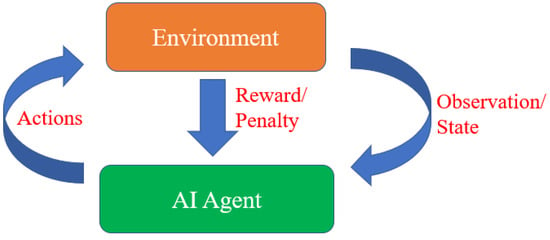
RL is characterized as a notable and dynamic machine learning paradigm in which an agent interacts continuously with its designated environment. The typical RL framework, depicted in
Figure 1, consists of two main components: an artificial intelligence (AI) agent and the environment, engaging in reciprocal interactions until the agent achieves a learned state. In this context, it is typical to represent the environment as a Markov decision process (MDP), a common framework employed by numerous RL algorithms in this field by leveraging dynamic programming, as discussed in recent work by Xiang et al.
[11]. A fundamental differentiator between classical dynamic programming techniques and RL algorithms is that the latter do not require precise knowledge of a mathematical model of the MDP. Instead, they focus on addressing large MDPs, where exact methods become impractical.
Figure 1. Typical framework of reinforcement learning.
Within the realm of RL, the agent assumes the role of an autonomous decision-maker, persistently seeking choices that maximize a cumulative reward signal over an extended timeframe while navigating the intricacies of the environment
[12]. This iterative process unfolds over discrete time steps, showcasing the agent’s decision-making capabilities. At each time step, the agent observes the current state of the environment, assimilating vital information that guides its future actions. Empowered with this knowledge, the agent makes deliberate decisions that impact not only its immediate actions but also have the potential to influence subsequent states and rewards within the environment.
Fundamental to the entire RL framework is the core objective of establishing optimal policies, serving as clearly defined action-selection strategies. These optimal policies are central in the RL journey, directing the agent towards decisions that hold the promise of the highest expected cumulative reward
[13]. The agent navigates its course through the environment using this expected cumulative reward, which is frequently expressed as the expected return. In RL, learning is an ongoing process of exploration and improvement that uses a trial-and-error approach. The agent’s actions are carefully chosen to best serve its long-term goals and are not random. Through a continuous feedback loop with the environment, this strategic decision making continuously evolves. The environment provides feedback to the agent after each action in the form of rewards or penalties. These evaluative indications give the agent essential information about the effects of its earlier actions, allowing it to gradually modify and improve its decision-making approach over time
[14].
2.2. Deep Learning
Deep learning, a subset of machine learning, makes use of deep neural networks, which are artificial neural networks with several layers. In order to provide output predictions, these networks methodically process input data through a series of complex transformations, forming an interconnected web of layers made up of neurons. The field of deep learning has produced amazing results in a variety of fields, including speech recognition, computer vision, natural language processing, and power systems. A transformative era and a significant advancement in the state of the art in a variety of tasks, including object detection, speech recognition, language translation, and power systems modeling, have been brought in by the emergence of deep learning
[15].
One of the most compelling attributes of deep learning lies in its innate ability to automatically unearth concise, low-dimensional representations, commonly referred to as features, from high-dimensional datasets—ranging from images to text and audio. By incorporating inductive biases into the architectural design of neural networks, particularly through the concept of hierarchical representations, practitioners in the realm of machine learning have made significant strides in combating the notorious curse of dimensionality
[16].
2.3. Deep Reinforcement Learning (DRL)
As outlined earlier, DRL marks the convergence of two influential domains: RL and deep learning. Within the realm of DRL, the utilization of neural networks, often extending into deep neural networks, plays a pivotal role in approximating the agent’s policy or value functions
[17]. This fusion empowers DRL with the ability to tackle complex decision-making tasks within high-dimensional state spaces, extending its applicability to a wide array of intricate challenges.
The foundation of deep learning predominantly rests on the capabilities of multilayer neural networks, where neurons serve as the fundamental building blocks
[18]. The perceptron
[19], one of the earliest neural network prototypes, initially surfaced as a single-layer neural network devoid of hidden layers. Its competence, however, was limited to straightforward linear classification tasks, rendering it incapable of resolving complex problems such as the XOR problem
[20]. The ascent of multilayer perceptrons, characterized by an increased number of neurons and layers, brought forth remarkable nonlinear approximation capabilities.
Two major success stories have emerged in the developing field of DRL, each of which marks a paradigm shift. The first, which served as the catalyst for the DRL revolution, was the creation of an algorithm capable of learning a wide variety of Atari 2600 video games at a superhuman level, straight from the raw image pixels
[21]. By demonstrating that RL agents may be trained successfully using only a reward signal, even when faced with unprocessed, high-dimensional observations, this innovation resolved the long-standing instability challenges related to function approximation techniques in RL.
The development of AlphaGo, a hybrid DRL system that defeated a human world champion in the challenging game of Go, was the second significant accomplishment
[22]. This success is comparable to IBM’s victory over Deep Blue in the chess tournament two decades earlier
[23]. Contrary to conventional rule-based chess systems, AlphaGo utilized the strength of neural networks trained using both supervised learning and RL, along with a standard heuristic search approach
[24].
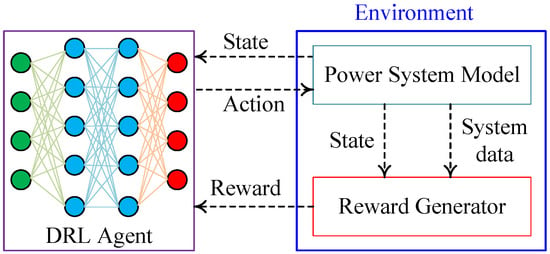
In the context of power and energy systems, a typical framework for training a DRL agent is illustrated in Figure 2. The DRL agent typically comprises multilayer neural networks, with an internal mechanism for continually updating the neural network weights. The environment generally includes a power system model and a reward generator, as depicted in the figure. The reward generator may employ system data and states obtained from the power system model to incentivize or penalize the DRL agent using rewards or penalties. The DRL agent takes the state from the power system model and provides actions to the power system model, in return for which it receives rewards or penalties. The figure represents a generic training framework for a DRL agent, and specific cases may involve some variations. It is important to note that during the implementation of the trained model, an actual power system may be used instead of a power system model.
Figure 2. DRL training framework.
2.4. DRL Methods
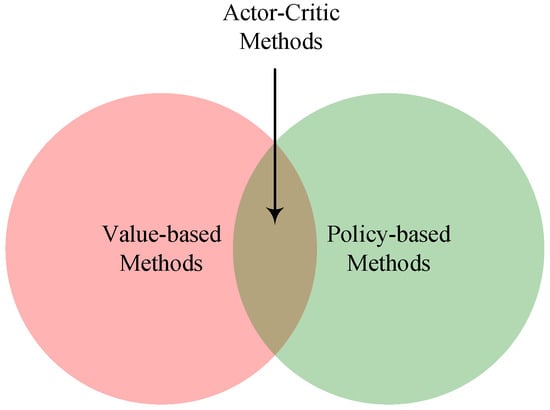
In the realm of DRL, methodologies can be broadly classified into three primary categories: value-based, policy-based, and actor–critic methods, as categorized in
[11] and as shown in
Figure 3. Each of these categories will be briefly introduced in this subsection.
Figure 3. Different categories of DRL methods.
2.4.1. Value-Based Methods
Value-based DRL is regarded as a fundamental class of DRL methodologies, where the emphasis is placed on the representation of the value function and the determination of the optimal value function
[17]. Within this category, the core objective is to capture and model the value function, a pivotal component that significantly influences the agent’s decision-making processes.
The value function in value-based DRL serves as a critical guiding force for the agent. It provides insights into the expected cumulative rewards associated with taking various actions in specific states, aiding the agent in making informed choices. This methodological approach is characterized by its ability to approximate and optimize the value function, enabling the agent to navigate complex decision spaces effectively.
(a) Q-learning: Q-learning is a classic RL that focuses on estimating the quality, represented by Q-values, of taking a particular action in a given state within an environment
[25]. Finding optimal Q-values is the main goal of Q-learning since they form an essential basis for directing the choice of actions in a way that maximizes cumulative rewards over time.
(b) SARSA: An on-policy reinforcement learning technique referred to as SARSA, or “state–action–reward–state–action”, shares similarities with Q-learning. It differs from Q-learning, though, in that it adopts an on-policy methodology. When updating the Q-values for a certain state–action combination, SARSA chooses a new action based on the existing policy and then updates the Q-values using the reward of the new action and the state that results from it
[26]. In contrast, regardless of the policy being followed, Q-learning chooses the action with the highest anticipated reward for the subsequent state to update its Q-values. SARSA is ideally suited for situations where you wish to learn and enhance the policy being used to interact with the environment during training. This is because it has an on-policy capability.
2.4.2. Policy-Based Methods
A policy-based method is an approach to RL/DRL where the agent learns a policy that directly maps states to actions. Unlike value-based DRL methods, which estimate the value of being in a particular state or taking a specific action, policy-based methods aim to find the optimal policy itself, which is a strategy for selecting actions in different states to maximize the expected cumulative reward.
(a) Vanilla policy gradient (VPG): The VPG algorithm is an RL method used to optimize policies in order to maximize the expected cumulative reward
[26]. It focuses on comprehending the relative advantage of performing a particular action in a particular state versus choosing an action at random under the current policy.
(b) Trust region policy optimization (TRPO): TRPO is a policy gradient algorithm introduced by Schulman et al.
[27] in 2015. TRPO is renowned for its role in preserving the consistency of agent training for DRL. Its main goal is to stop excessive policy modifications that could otherwise cause performance to collapse. TRPO runs in a predetermined trust region, which denotes a particular parameter space where updating policies is thought to be safe. Its main goal is to find policy changes that uphold this trust region constraint while maximizing predicted rewards.
(c) Proximal policy optimization (PPO): PPO is an RL algorithm that was developed as a more straightforward substitute for TRPO. In terms of stability and sample effectiveness, PPO and TRPO are comparable, although PPO is easier to execute. Unlike TRPO, PPO uses a particular clipping method in its goal function rather than a KL-divergence restriction to make sure that the new policy stays close to the old policy
[28].
2.4.3. Actor–Critic Methods
Actor–critic is a popular RL method that combines aspects of both value-based and policy-based RL approaches
[29]. In the actor–critic framework, an RL agent consists of two primary components: actor and critic. The actor is responsible for selecting actions in the environment. In regard to a particular state, it learns a policy that specifies the probability distribution over possible actions. The actor’s job is to investigate and choose the best course of action to maximize anticipated rewards. The critic, however, assesses the actor’s behavior. It gains knowledge of the value function, which calculates the potential returns from a given state or state–action pair. By evaluating the effectiveness of the actor’s performance, the critic offers the actor feedback.
Utilizing the value judgments of the critic to inform and enhance the actor’s policy is the core idea behind actor–critic methods. Gradient ascent is a common technique for accomplishing this, in which the actor modifies its policy in a way that raises the expected return as determined by the critic.
(a) Deep deterministic policy gradient (DDPG): DDPG is an RL algorithm designed for solving tasks with continuous action spaces
[30]. By extending the actor–critic design to deep neural networks, it makes it possible to simultaneously learn a policy (the actor) and a value function (the critic). A neural network acts as the actor, taking the current state as input and generating a continuous action. It gains knowledge of a deterministic strategy that directly links states and actions. In other words, it calculates the best course of action in a particular situation. As in conventional actor–critic systems, the critic, on the other hand, is a different neural network that accepts a state–action pair as input and calculates the expected cumulative reward (Q-value) linked to performing that action in the given state. The critic’s job is to offer feedback on the quality of actions chosen by the actor.
(b) Twin delayed deep deterministic policy gradients (TD3): TD3
[31] is an advanced RL algorithm that builds upon the foundation of the DDPG algorithm. TD3 was developed to address some of the key challenges associated with training DRL agents, particularly in tasks with continuous action spaces. The critic network’s tendency to overestimate Q-values in DDPG and other comparable algorithms is a key problem that can cause training instability and poor performance. By using twin critics—basically, two distinct Q-value estimation networks—TD3 tackles this problem. It takes the minimum of the Q-values provided by these twin critics as the target value during the learning process. This helps in reducing the overestimation bias and leads to more accurate value estimates.
(c) Soft actor–critic (SAC): SAC
[32] is an advanced RL algorithm designed for tasks with continuous action spaces. In SAC, the actor–critic framework is improved, and entropy regularization is incorporated to promote exploration and improve stochastic policies. SAC is renowned for its ability to handle challenging continuous control problems and produce improved action space exploration.
3. Deep Reinforcement Learning Applications in Different Aspects of Resilient Power and Energy Systems
Power and energy system resilience refers to the capacity of a power and energy infrastructure to endure, absorb, and promptly recover from various disruptions, including natural disasters and man-made events, while maintaining the continuity and reliability of power supply to end consumers
[33]. This concept acknowledges the increasing challenges posed by extreme weather events, cyber-attacks, climate change, and the need for adaptive responses in the power sector. Evaluating the resilience of a complex system, particularly in the context of power and energy systems, necessitates a comprehensive and systematic approach. The Disturbance and Impact Resilience Evaluation (DIRE) methodology offers precisely such a framework for assessing and enhancing resilience
[34].
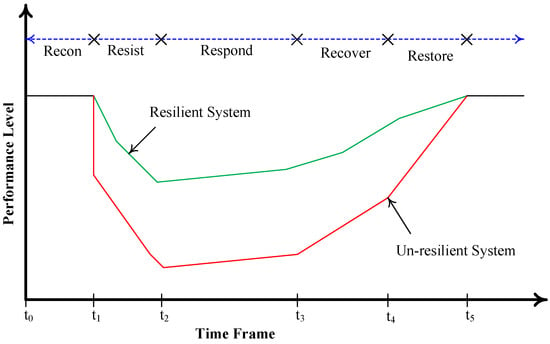
In Figure 4, the various stages within the DIRE approach are illustrated, each of which plays a critical role in resilience assessment and evaluation. The DIRE framework consists of five distinct stages, namely, reconnaissance (recon), resist, respond, recover, and restore. These stages are integral in assessing a system’s ability to endure and adapt to disruptions. DRL emerges as a powerful tool that finds applications across all of these resilience stages. DRL offers the capacity to adapt, optimize, and enhance system behavior in response to evolving conditions and disturbances, making it a valuable asset in the pursuit of resilience.
Figure 4. The DIRE curve showing different stages of resilience.
Figure 4 not only depicts the stages but also showcases typical DIRE curves for both resilient and unresilient systems. These curves offer a visual representation of how system performance evolves over time in the face of extreme events and disturbances. It is clear from the figure that after an extreme event occurs, at time 𝑡1, the performance level of the system undergoes a deterioration. This decline in performance persists throughout the “resist” stage until reaching time 𝑡2. However, the “respond” stage, which extends to 𝑡3 , marks the onset of a slow but steady performance improvement. Subsequently, as the system enters the “recover” and “restore” stages, its performance continues to improve, ultimately returning to pre-disturbance levels.
Power and energy system resilience encompasses a spectrum of research areas and methodologies, including the development of resilience metrics, resilience planning, and operational resilience enhancement, each addressing critical aspects of ensuring the robustness of power and energy systems.
Figure 5 shows five different aspect categories of resilient power and energy systems. Understanding these aspects of resilient power and energy systems is critical for devising comprehensive strategies to ensure the reliability and robustness of power and energy infrastructure in the face of evolving challenges and disruptions. Each aspect contributes to a holistic approach aimed at enhancing the resilience of power and energy systems and safeguarding the uninterrupted supply of electricity to end consumers.
Figure 5. Different aspects of resilient power and energy systems.
3.1. Dynamic Response
Dynamic response consists of adaptive measures and strategies aimed at addressing and mitigating the consequences of unforeseen and critical events or disasters, whether natural or human-made. These events may include hurricanes, earthquakes, floods, wildfires, cyber-attacks, industrial accidents, or acts of terrorism. Dynamic response can operate proactively, linking situational awareness with resilience enhancement and ensuring effective and efficient responses in both preventive and emergency contexts
[35]. The primary objectives of emergency response in the context of power and energy systems resilience include ensuring the integrity and functionality of critical infrastructure, minimizing downtime, and restoring operations swiftly and effectively.
3.2. Recovery and Restoration
The phases of recovery and restoration are of utmost importance in the context of power and energy system resilience. These phases cover the plans and methods used to restore order to the power and energy system after a disruptive event. Recovery and restoration are intrinsically linked to dynamic response methods, with subsequent recovery efforts being made easier by the initial response phase.
Recovery entails a diverse strategy aimed at determining the degree of damage, stabilizing the power and energy system, and starting the restoration and repair operations. This step comprises a thorough assessment of the state of the power system, including the identification of crucial elements that might have been jeopardized during the incident
[36]. Critical loads quickly regain access to power due to recovery mechanisms that prioritize the restoration of key services.
On the other hand, restoration concentrates on the systematic approach of returning the entire power and energy system to its pre-disruption state
[37]. In this phase, damaged infrastructure is coordinately repaired and reconnected, system integrity is tested and verified, and non-essential services are gradually brought back online. The goal of restoration efforts is to bring the power and energy system back to full functionality so that it can efficiently meet consumer needs
[38].
This subsection examines the application of DRL approaches to speed up recovery and restoration procedures in power and energy systems. In-depth discussion is provided regarding how DRL may improve prioritizing, resource allocation, and decision making during these crucial times, thereby improving the overall resilience and dependability of the power and energy system.
3.3. Energy Management and Control
Energy management (EM) and adaptive control within the context of resilient power and energy systems are integral strategies and methodologies employed to enhance the reliability, efficiency, and robustness of energy distribution and consumption. Energy management encompasses a range of practices that involve monitoring, optimizing, and controlling various aspects of energy usage, generation, and distribution. These practices aim to achieve multiple objectives, including minimizing energy costs, reducing peak loads, maintaining a balance between electricity supply and demand, and ensuring the stable operation of energy systems. EM plays a crucial role in enhancing resilience by allowing for proactive responses to disruptions, optimizing resource allocation, and minimizing the impact of unforeseen events
[39]. Adaptive control, on the other hand, refers to the ability of an energy system to autonomously adjust its operation in real time based on changing conditions and requirements. It involves the use of feedback mechanisms, data analytics, and control algorithms to continuously monitor system performance, detect anomalies or faults, and make rapid and informed decisions to maintain system stability and reliability. Adaptive control is essential in resilient energy systems as it enables them to self-regulate, adapt to dynamic situations, and recover quickly from disturbances or failures
[40]. Together, energy management and adaptive control form a dynamic framework that ensures the efficient use of energy resources, maintains grid stability, and responds effectively to various challenges, including load variations, demand fluctuations, cyber threats, equipment faults, and other disruptions. These strategies are critical for enhancing the resilience and sustainability of power and energy systems in the face of evolving complexities and uncertainties.
3.4. Communications and Cybersecurity
The rise of smart grid technologies and the integration of advanced communication systems within power and energy networks have led to cybersecurity becoming a paramount concern for these systems’ operators
[41]. Within this context, the security of critical elements such as data availability, data integrity, and data confidentiality is seen as crucial for ensuring cyber resiliency. These fundamental elements are strategically targeted by cyber adversaries, with the aim of compromising the integrity and reliability of data transmitted across the communication networks of the power grid. The objectives pursued by these adversaries encompass a range of disruptive actions, including tampering with grid operations, the interruption of the secure functioning of power systems, financial exploitation, and the potential infliction of physical damage to the grid infrastructure. To counteract these threats, extensive research efforts have been devoted to the development of preventive measures within the realm of communications and cybersecurity. These measures are designed to deter cyber intruders from infiltrating network devices and databases
[42]. The overarching goal of these preventative measures is to enhance the security posture of power and energy systems by safeguarding their communication channels and the associated cyber assets.
3.5. Resilience Planning and Metric Development
Resilience planning in the context of power and energy systems involves planning efforts to develop comprehensive strategies for fortifying electricity infrastructure to withstand and recover from potential extreme events in the future
[43]. It primarily focuses on identifying and prioritizing investments in the electricity grid to ensure the reliable and resilient supply of power to end-use customers. These planning-based strategies may encompass initiatives such as the installation of underground cables, strategic energy storage planning, and other infrastructure enhancements aimed at reinforcing the system’s ability to deliver uninterrupted electricity
[44]. On the other hand, metric development within the realm of power and energy system resilience is a foundational component for quantifying and evaluating a power and energy system’s ability to endure and rebound from disruptions. These metrics serve as precise and measurable indicators, offering a quantitative means to assess the performance of a power system concerning its resilience. They provide valuable insights into how the system operates under normal conditions and its ability to withstand stressors or adverse situations. Metric development plays a crucial role in systematically gauging and enhancing the resilience of power systems, allowing for informed decision making and the optimization of infrastructure investments.
 +1 credit
+1 credit