Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Enrique Nava Baro | -- | 1114 | 2023-11-30 14:10:06 | | | |
| 2 | Rita Xu | -3 word(s) | 1111 | 2023-12-01 03:14:16 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Moreno-Torres, I.; Lozano, A.; Bermúdez, R.; Pino, J.; Méndez, M.D.G.; Nava, E. Assess Hypernasality. Encyclopedia. Available online: https://encyclopedia.pub/entry/52234 (accessed on 25 June 2026).
Moreno-Torres I, Lozano A, Bermúdez R, Pino J, Méndez MDG, Nava E. Assess Hypernasality. Encyclopedia. Available at: https://encyclopedia.pub/entry/52234. Accessed June 25, 2026.
Moreno-Torres, Ignacio, Andrés Lozano, Rosa Bermúdez, Josué Pino, María Dolores García Méndez, Enrique Nava. "Assess Hypernasality" Encyclopedia, https://encyclopedia.pub/entry/52234 (accessed June 25, 2026).
Moreno-Torres, I., Lozano, A., Bermúdez, R., Pino, J., Méndez, M.D.G., & Nava, E. (2023, November 30). Assess Hypernasality. In Encyclopedia. https://encyclopedia.pub/entry/52234
Moreno-Torres, Ignacio, et al. "Assess Hypernasality." Encyclopedia. Web. 30 November, 2023.
Copy Citation
Automatic evaluation of hypernasality has been traditionally computed using monophonic signals (i.e., combining nose and mouth signals).
deep neural networks
hypernasality
speech assessment
1. Introduction
Hypernasality is a speech condition in which the speaker produces nasal sounds while attempting to produce oral ones [1]. Hypernasality may occur due to anatomic malformations (e.g., cleft palate) that let the air in the mouth cavity scape towards the nose cavity, or due to the lack of precise motor skills that result in patients failing to lower the velum [2]. Evaluating hypernasality is most relevant because it may guide the rehabilitation process, particularly in the case of cleft palate patients [3].
Traditionally, hypernasality evaluation was carried out by human experts, who produced a perceptual subjective measure of the degree of nasality. Despite its subjective, and hence variable, nature, this approach continues to be considered the golden standard to evaluate hypernasality [4]. In the last quarter of the 20th century, one acoustic instrument, the Nasometer, was proposed to supplement human judgments [5]. The Nasometer records the nose and mouth acoustic signals separately, which makes it possible to compute the nasalance, which is defined as the ratio of nasal acoustic energy to the sum of oral and nasal. The Nasometer has had relative success in clinical practice [4][6]. However, the reliability of this instrument is unclear; studies comparing the nasalance scores and perceptual scores have obtained correlations ranging from non-significant to strong (for a review see [7]).
2. Acoustics Contrast between Oral and Nasal Sounds
Phonetic and speech processing textbooks [8][9] typically describe nasal sounds (e.g., /m, ẽ…/) by showing how the addition of the nasal resonance modifies the resonance of the corresponding oral sound (e.g., /b, e/). These modifications include, among others, the addition of an extra nasal formant around 250 Hz, increased spectral flatness, and reduced first formant amplitude.
While nose and mouth signals have been recorded in many nasalance studies in the past, not much attention has been paid to nasal/oral contrast in each signal. However, as noted above, perceptual experiments carried out in the lab indicate that the contrast is more pronounced with the nose signals than with the mouth signals. Perceptual impressions can be confirmed through spectrographic analysis. Figure 1 the Long-Term Average Spectrum (LTAS) of an oral vowel /e/ and its nasalized counterpart /ẽ/. The two vowels were recorded simultaneously with a standard monophonic microphone and a Nasometer device (with a nose and a mouth microphone). Note that, in Figure 1, the black and red lines are notably close to each other in the case of the mouth and monophonic microphones; in contrast, the two lines do not overlap in the nose microphone. This suggests that the nasal/oral contrast might be easier to recognize in the nose signal. However, this is just one example, for which a more detailed analysis is needed. One possible approach to compare pairs of speech sounds (e.g., e/ẽ) is computing the Euclidean distance based on some acoustic features.
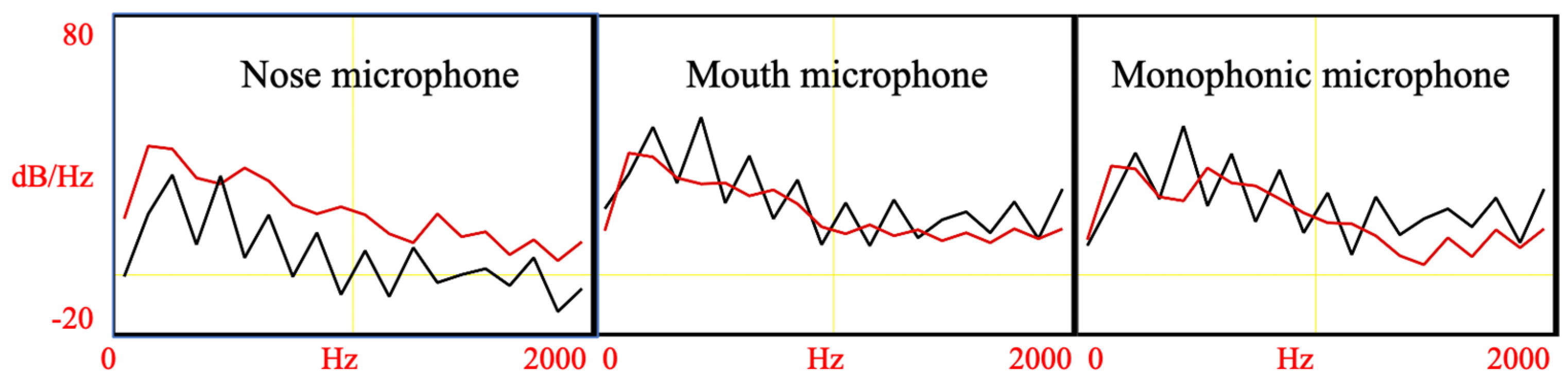
Figure 1. Long-term Average Spectrum of nasalized vowel /ẽ/ (red lines) and oral vowel /e/ (black lines), recorded simultaneously with three microphones.
3. Phonetics
While the spectral distance may provide valuable information, it is not sufficient to confirm that two signals differ in their effectiveness in encoding phonetically relevant information (e.g., nasality). This is because speech encodes simultaneously multiple types of phonetically relevant information (e.g., nasality, voicing, place of articulation, intonation, sociolinguistic information, and emotional content [9]). Thus, it is necessary to examine the extent listeners (humans or machines) discriminate sound types with different signals.
In order to clarify the phonetic content of speech signals, researchers have analyzed the errors produced by listeners (humans or computers) when attempting to classify sounds [10][11]. Commonly, the target sounds and the responses of the speakers are tabulated in confusion matrixes from which various information can be obtained (e.g., error biases).
4. Automatic Assessment of Hypernasal Speech
Many proposals have been made to evaluate hypernasality automatically, both in terms of the acoustic features used to process the speech signal and in terms of the automatic classification method. As for the features, these include spectral poles and zeros, increased spectral flatness, formant amplitude, the voice low-to-high tone ratio, and MFCCs [12][13][14][15][16][17]. While the classifiers include Support Vector Machines (SVMs), Gaussian mixture models (GMMS), and Deep Neural Networks (DNNs) [15][16][18][19]. Most studies have trained their classifiers using samples of healthy and hypernasal speech. However, this approach has two important limitations: (1) the size of the training database is relatively small (i.e., up to one or two hundred speakers producing a small number of utterances in most cases) and (2) most studies processed only sustained vowels [20][21] or vowel fragments that had been annotated manually in words or sentences [22][23][24][25]; this approach is not compatible with clinical protocols that emphasize the need to use diverse speech samples (e.g., running speech [26]).
Recently, Mathad et al. [27] proposed an innovative approach (see Figure 2) that overcomes the two above-mentioned limitations. In their model, training was carried out with speech samples from healthy speakers, which allowed them to use one freely available large database to train a DNN model. Specifically, they used 100 h from the Librispeech corpus [28]. To train the system, the speech samples were divided into short windows from which MFCCs are computed and based on phonetic transcriptions, classified into one of four classes: oral consonant (OC), oral vowel (OV), nasal consonant (NC), and nasal vowel (NV). During the testing phase, the system was fed with new MFFC vectors, which are classified as belonging to one of the four classes. This allows computing the severity of nasality as the number of frames that are nasal divided by the total number of frames (per speaker or utterance). The results showed that the correlation between the scores of the DNN and those produced by Speech and Language Pathology (SLP) experts was very high (r = 0.80).
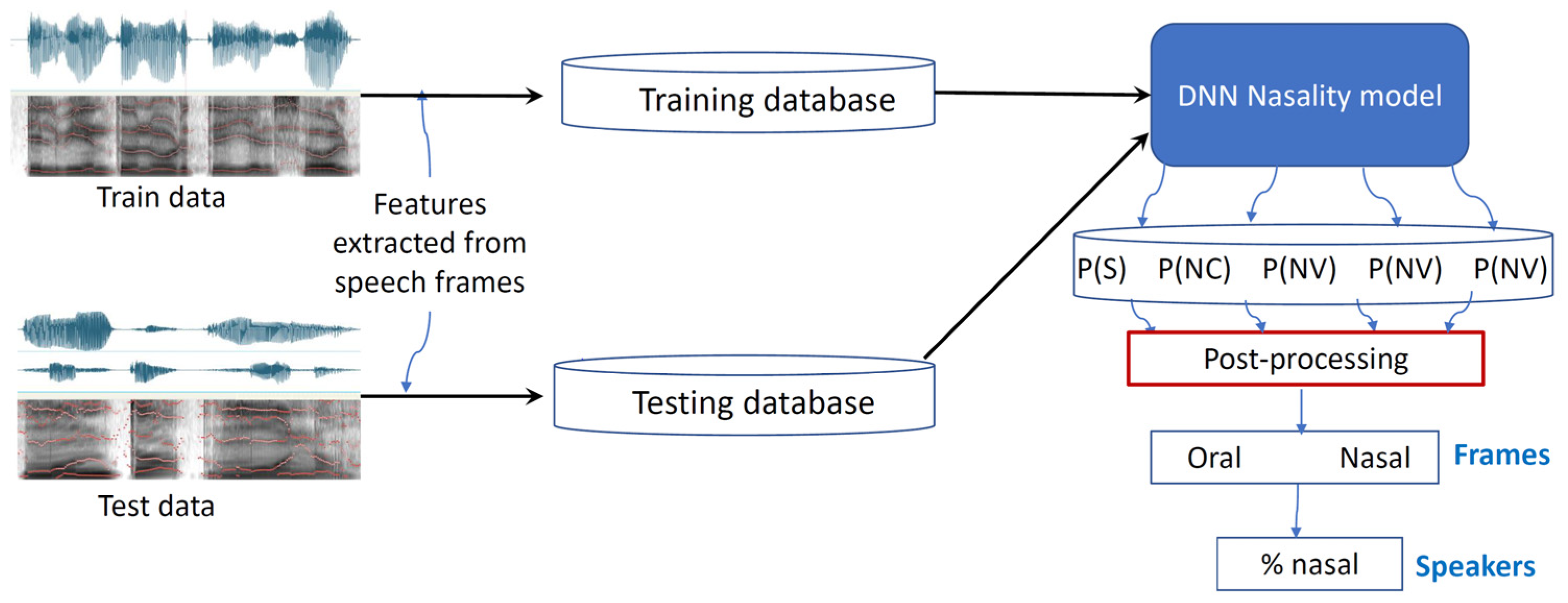
Figure 2. Overview of DNN model used to assess hypernasal speech.
One practical limitation of this approach is that to train their DNN, the authors used a large amount of training data (>100 h), and such large databases are available only for a very small number of languages. Despite such a limitation, it is relevant to compare their results with nasalance studies (as these also evaluate hypernasality based on running speech). By selecting only nasalance studies with a number of participants large enough to compute the Pearson correlation, researchers find that one study obtained a very high correlation of 0.88 [29], but in all other studies, the correlation is notably lower: 0.74 [30], 0.59 [31], and 0.55 [32]. Thus, it seems that the above-described DNN model might be a good alternative to the Nasometer. However, more studies are needed to confirm the reliability of this DNN model. It is also relevant to explore if the results are optimal using nose signals.
References
- Mossey, P.A.; Catilla, E.E. Global Registry and Database on Craniofacial Anomalies: Report of a WHO Registry Meeting on Craniofacial Anomalies; WHO: Geneva, Switzerland, 2003.
- Kummer, A.W. Disorders of Resonance and Airflow Secondary to Cleft Palate and/or Velopharyngeal Dysfunction. In Seminars in Speech and Language; Thieme Medical Publishers: New York, NY, USA, 2011.
- Howard, S.; Lohmander, A. Cleft Palate Speech: Assessment and Intervention; John Wiley & Sons: Hoboken, NJ, USA, 2011.
- Bettens, K.; Wuyts, F.L.; Van Lierde, K.M. Instrumental assessment of velopharyngeal function and resonance: A review. J. Commun. Disord. 2014, 52, 170–183.
- Fletcher, S.G.; Sooudi, I.; Frost, S.D. Quantitative and graphic analysis of prosthetic treatment for “nasalance” in speech. J. Prosthet. Dent. 1974, 32, 284–291.
- Gildersleeve-Neumann, C.E.; Dalston, R.M. Nasalance scores in noncleft individuals: Why not zero? Cleft Palate-Craniofacial J. 2001, 38, 106–111.
- Liu, Y.; Lee, S.A.S.; Chen, W. The correlation between perceptual ratings and nasalance scores in resonance disorders: A systematic review. J. Speech Lang. Hear. Res. 2022, 65, 2215–2234.
- Rabiner, L.; Schafer, R. Theory and Applications of Digital Speech Processing; Prentice Hall Press: Hoboken, NJ, USA, 2010.
- Stevens, K.N. Acoustic Phonetics; MIT Press: Cambridge, MA, USA, 2000; Volume 30.
- Miller, G.A.; Nicely, P.E. An analysis of perceptual confusions among some English consonants. J. Acoust. Soc. Am. 1955, 27, 338–352.
- Tejedor-García, C.; Cardeñoso-Payo, V.; Escudero-Mancebo, D. Automatic speech recognition (ASR) systems applied to pronunciation assessment of L2 Spanish for Japanese speakers. Appl. Sci. 2021, 11, 6695.
- Kummer, A.W. Evaluation of Speech and Resonance for Children with Craniofacial Anomalies. Facial Plast. Surg. Clin. N. Am. 2016, 24, 445–451.
- Grunwell, P.; Brondsted, K.; Henningsson, G.; Jansonius, K.; Karling, J.; Meijer, M.; Ording, U.; Wyatt, R.; Vermeij-Zieverink, E.; Sell, D. A six-centre international study of the outcome of treatment in patients with clefts of the lip and palate: The results of a cross-linguistic investigation of cleft palate speech. Scand. J. Plast. Reconstr. Surg. Hand Surg. 2000, 34, 219–229.
- Henningsson, G.; Kuehn, D.P.; Sell, D.; Sweeney, T.; Trost-Cardamone, J.E.; Whitehill, T.L. Universal parameters for reporting speech outcomes in individuals with cleft palate. Cleft Palate-Craniofacial J. 2008, 45, 1–17.
- Sell, D.; John, A.; Harding-Bell, A.; Sweeney, T.; Hegarty, F.; Freeman, J. Cleft Audit Protocol for Speech (CAPS-A): A comprehensive training package for speech analysis. Int. J. Lang. Commun. Disord. 2009, 44, 529–548.
- Spruijt, N.E.; Beenakker, M.B.; Verbeek, M.B.; Heinze, Z.C.B.; Breugem, C.C.; van der Molen, A.B.M. Reliability of the Dutch cleft speech evaluation test and conversion to the proposed universal scale. J. Craniofacial Surg. 2018, 29, 390–395.
- Orozco-Arroyave, J.R.; Arias-Londoño, J.D.; Vargas-Bonilla, J.F.; Nöth, E. Automatic detection of hypernasal speech signals using nonlinear and entropy measurements. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012.
- Golabbakhsh, M.; Abnavi, F.; Elyaderani, M.K.; Derakhshandeh, F.; Khanlar, F.; Rong, P.; Kuehn, D.P. Automatic identification of hypernasality in normal and cleft lip and palate patients with acoustic analysis of speech. J. Acoust. Soc. Am. 2017, 141, 929–935.
- Vikram, C.M.; Tripathi, A.; Kalita, S.; Prasanna, S.R.M. Estimation of Hypernasality Scores from Cleft Lip and Palate Speech. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018.
- Lee, G.-S.; Wang, C.-P.; Yang, C.; Kuo, T. Voice low tone to high tone ratio: A potential quantitative index for vowel and its nasalization. IEEE Trans. Biomed. Eng. 2006, 53, 1437–1439.
- He, L.; Zhang, J.; Liu, Q.; Yin, H.; Lech, M.; Huang, Y. Automatic evaluation of hypernasality based on a cleft palate speech database. J. Med. Syst. 2015, 39, 61.
- Vali, M.; Akafi, E.; Moradi, N.; Baghban, K. Assessment of hypernasality for children with cleft palate based on cepstrum analysis. J. Med. Signals Sens. 2013, 3, 209.
- Mirzaei, A.; Vali, M. Detection of hypernasality from speech signal using group delay and wavelet transform. In Proceedings of the 2016 6th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 13–14 October 2016; IEEE: Piscataway, NJ, USA, 2016.
- Dubey, A.K.; Tripathi, A.; Prasanna, S.R.M.; Dandapat, S. Detection of hypernasality based on vowel space area. J. Acoust. Soc. Am. 2018, 143, EL412–EL417.
- Wang, X.; Yang, S.; Tang, M.; Yin, H.; Huang, H.; He, L. HypernasalityNet: Deep recurrent neural network for automatic hypernasality detection. Int. J. Med. Inform. 2019, 129, 1–12.
- John, A.; Sell, D.; Sweeney, T.; Harding-Bell, A.; Williams, A. The cleft audit protocol for speech—Augmented: A validated and reliable measure for auditing cleft speech. Cleft Palate-Craniofacial J. 2006, 43, 272–288.
- Mathad, V.C.; Scherer, N.; Chapman, K.; Liss, J.M.; Berisha, V. A deep learning algorithm for objective assessment of hypernasality in children with cleft palate. IEEE Trans. Biomed. Eng. 2021, 68, 2986–2996.
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015.
- Khwaileh, F.A.; Alfwaress, F.S.D.; Kummer, A.W.; Alrawashdeh, M. Validity of test stimuli for nasalance measurement in speakers of Jordanian Arabic. Logop. Phoniatr. Vocology 2018, 43, 93–100.
- Sweeney, T.; Sell, D. Relationship between perceptual ratings of nasality and nasometry in children/adolescents with cleft palate and/or velopharyngeal dysfunction. Int. J. Lang. Commun. Disord. 2008, 43, 265–282.
- Brancamp, T.U.; Lewis, K.E.; Watterson, T. The relationship between nasalance scores and nasality ratings obtained with equal appearing interval and direct magnitude estimation scaling methods. Cleft Palate-Craniofacial J. 2010, 47, 631–637.
- Keuning, K.H.; Wieneke, G.H.; Van Wijngaarden, H.A.; Dejonckere, P.H. The correlation between nasalance and a differentiated perceptual rating of speech in Dutch patients with velopharyngeal insufficiency. Cleft Palate-Craniofacial J. 2002, 39, 277–284.
More
Information
Subjects:
Telecommunications
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
752
Revisions:
2 times
(View History)
Update Date:
01 Dec 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No