Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Anton Kovantsev | -- | 3877 | 2023-11-21 11:46:42 | | | |
| 2 | Fanny Huang | Meta information modification | 3877 | 2023-11-22 06:18:53 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Bezbochina, A.; Stavinova, E.; Kovantsev, A.; Chunaev, P. Predictability Measures. Encyclopedia. Available online: https://encyclopedia.pub/entry/51851 (accessed on 23 June 2026).
Bezbochina A, Stavinova E, Kovantsev A, Chunaev P. Predictability Measures. Encyclopedia. Available at: https://encyclopedia.pub/entry/51851. Accessed June 23, 2026.
Bezbochina, Alexandra, Elizaveta Stavinova, Anton Kovantsev, Petr Chunaev. "Predictability Measures" Encyclopedia, https://encyclopedia.pub/entry/51851 (accessed June 23, 2026).
Bezbochina, A., Stavinova, E., Kovantsev, A., & Chunaev, P. (2023, November 21). Predictability Measures. In Encyclopedia. https://encyclopedia.pub/entry/51851
Bezbochina, Alexandra, et al. "Predictability Measures." Encyclopedia. Web. 21 November, 2023.
Copy Citation
The task of forecasting is a crucial topic with wide-range applications and significance in various fields. In fact, forecasting provides valuable insights into the future, helping individuals, organizations, and societies plan and adapt in a dynamic and uncertain world. Time series and network link are among the most significant and extensively investigated objects that have been the focus of forecasting efforts.
predictability measures
intrinsic predictability
realized predictability
1. Introduction
Nowadays, the task of forecasting is a crucial topic with wide-range applications and significance in various fields. In fact, forecasting provides valuable insights into the future, helping individuals, organizations, and societies plan and adapt in a dynamic and uncertain world. Time series [1][2] and network link [3][4] are among the most significant and extensively investigated objects that have been the focus of forecasting efforts. The range of developed forecasting models is wide, starting from regression models [5] to neural networks [6] for time series forecasting, and from well-established classification methods [7] to random walks [8] for network links prediction.
Despite the extensive range of developed forecasting methods, researchers rarely address questions concerning the overall predictability of an object and its upper bound. Nevertheless, there are studies that delve into this matter, and the predictability measures they propose encompass a wide range, reflecting diverse viewpoints from various scientific domains, including dynamical systems [9] and information theory [10].
The concept of predictability is usually regarded from two sides [11]: with respect to a chosen forecasting model (realized predictability) and as a data property not depending on a certain model (intrinsic predictability).
2. Overview of Predictability Measures
The task of predicting the future has become a fundamental practice for many scientists across various disciplines. As a result, a multitude of forecasting methods have been devised, catering to a diverse array of objects and phenomena. This extensive range of objects has led researchers to explore predictive techniques in fields as varied as economics, climate science, medicine, social sciences, and more.
Among the various entities whose behaviors have been subject to prediction, time series [1][2] and network links [3][4] stand out as some of the most prominent and extensively studied. Time series, which represent a sequence of data points indexed by time intervals, find applications in fields such as finance [12], meteorology [13], and stock market analysis [14], where forecasting future values based on past observations is of paramount importance. Network links, on the other hand, are crucial in understanding and modeling the relationships and interactions among entities in complex systems, such as social networks [15], transportation networks [16], and biological systems [17].
Researchers can highlight certain methods that are widely utilized across diverse fields. Among these, linear and nonlinear regression models stand out as some of the most straightforward techniques. What makes them particularly appealing is their simplicity, as they do not demand significant computational resources and can be constructed without reliance on specialized tools or software. Regression models continue to find applications in research and practice, as evidenced by studies such as [5][18][19].
The autoregressive model ranks among the most popular forecasting methodologies, largely due to its well-defined algorithmic framework for model construction and parameter selection [20]. The research has seen extensive adoption of various autoregressive models, such as ARMA, ARIMA, ARCH, GARCH, and others, to predict a wide range of phenomena, such as market prices [14][21][22][23], network traffic [24][25][26], and social processes [27][28][29]. Oftentimes, hybrid autoregressive models that combine multiple forecasting techniques are used [30][31][32][33]. By combining the strengths of different methodologies, these hybrid approaches seek to harness the complementary predictive capabilities of various models, yielding more accurate and robust forecasts.
Neural networks represent a specific type of nonlinear functional architecture that involves iteratively processing linear combinations of inputs through nonlinear functions [34]. Artificial neural networks have found extensive application in various domains, demonstrating their efficacy in predicting stock prices and indices [6][35][36], addressing industrial challenges [37][38][39], facilitating medical forecasts [40][41][42][43][44], enhancing weather forecasts [45][46][47][48], and tackling a myriad of other challenges [49][50][51].
Well-established classification methods, including decision trees, k-Nearest Neighbors (k-NN), and Support Vector Machines (SVM), among others, have demonstrated their applicability in predicting links within a network [7], achieving competitive levels of accuracy. The utilization of these methods in link prediction tasks allows researchers to harness their robustness and adaptability to different datasets and graph structures. In the work of [52], a comparative analysis is conducted on various node similarity measures, encompassing both node-dependent indices and path-dependent indices. These measures serve as essential components in link prediction, aiding in quantifying the potential connections between nodes and guiding the predictive modeling process. Beyond these widespread techniques, there exist link prediction methods that leverage concepts such as random walks [8][53], matrix factorization [54][55], and others [56][57][58]. These methods are based on diverse mathematical frameworks to capture complex patterns within the network’s topology and provide valuable insights into the potential links between nodes.
The approaches discussed in the referenced papers are oriented towards the development of methods capable of making predictions with the desired level of quality on test datasets. However, it has been observed that authors often overlook certain questions: What is the overall predictability of this object? Can a model be devised that exhibits superior performance on this dataset?
To validate this concept, researchers introduce a citation network comprised of the regarded papers focused on forecasting and predictability assessment methods for various objects, such as time series and network links. The network and its connections are depicted in Figure 1. Notably, the figure illustrates that research studies aimed at enhancing forecast accuracy are rarely linked to predictability studies.
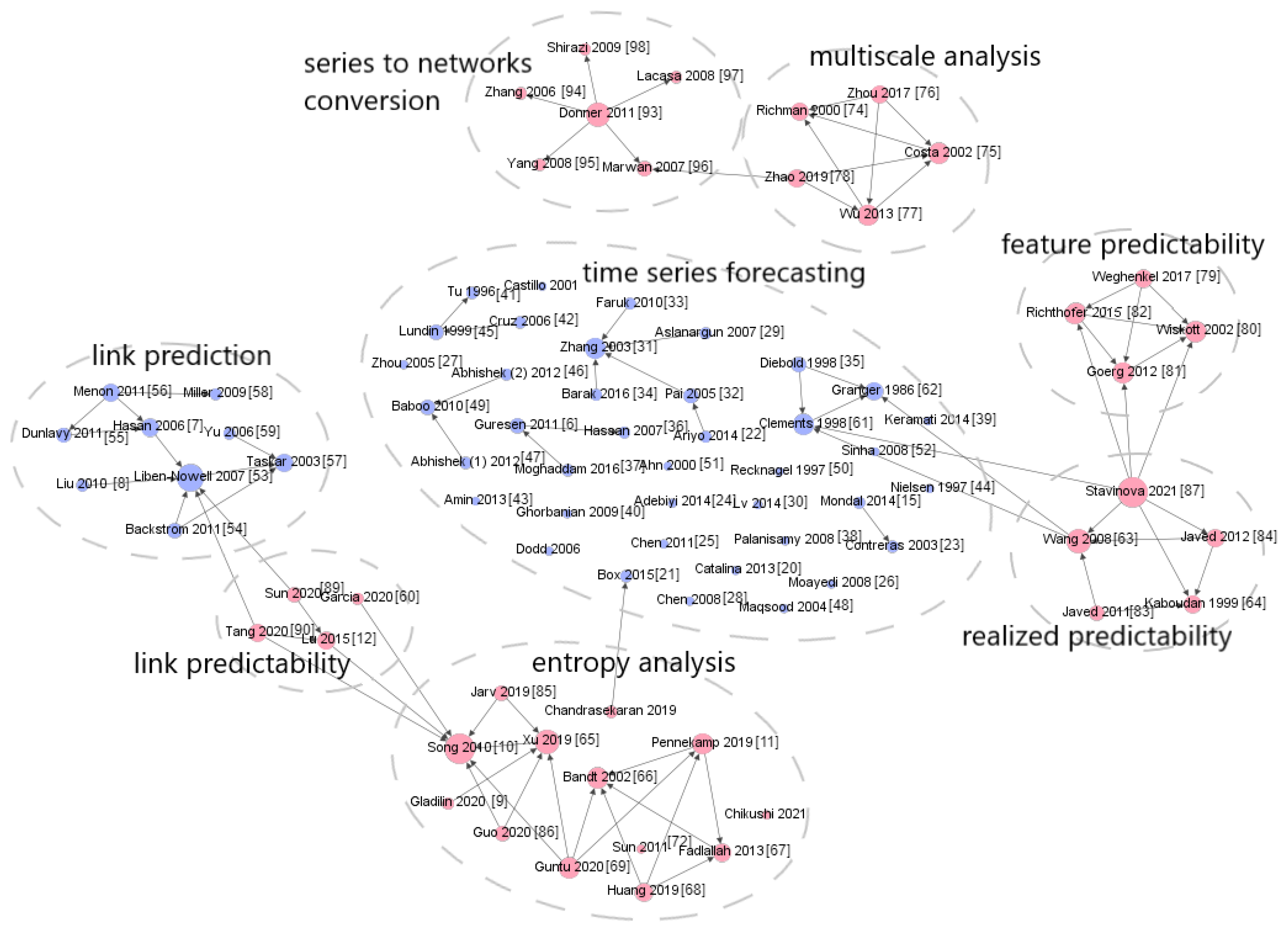
Figure 1. The citation network consisting of papers dedicated to forecasting and predictability assessment methods for different objects (time series, network links).
2.1. General Predictability Concepts
To evaluate the quality of predictive models on data, methods of predictability analysis for the modeling object can be employed. According to [11], the concept of object predictability should be divided into two components: realized predictability (RPr) and intrinsic predictability (IPr). The first type of predictability, realized predictability, is a function that depends on the forecasting model employed:
where m is the forecasting model and S is the object or class of objects. For example, different forecast quality metrics, such as MSE, MASE, RMSE, etc., are nothing but realized predictability measures. The second type, intrinsic predictability, is independent of the model used:
where S is the object or class of objects. Calculating theoretical estimates of intrinsic predictability for objects can be challenging, even in the case of simple data classes [59]. Therefore, the upper bound of realized predictability, which represents the predictability achieved by an optimal model, is used to estimate intrinsic predictability:
Low values of realized predictability could indicate not only the inherent complexity of the modeled object but also potentially inadequate quality of the selected model. Conversely, intrinsic predictability is independent of the forecasting model and can, therefore, be utilized to assess the data quality.
One of the central questions that motivated the experimental aspect of this study is how to establish a connection between quality measures (RPr), 𝜌𝑅, and a measure of intrinsic predictability, 𝜌𝐼. While researchers possess distinct tools for predictability estimation, the fundamental question is: do they truly have a meaningful relationship with each other?
Researchers have developed various approaches to measure the predictability of diverse objects, including univariate and multivariate time series, categorical time series (event sequences), network links, and more. It is important to note that there is not a singular methodological approach in this field, as different researchers approach this issue from the perspectives of various scientific domains, such as information theory, dynamical system theory, approximation theory, and others.
2.2. Time Series Predictability
Prior to discussing time series predictability measures, the notion of intrinsic unpredictability (IPr) concerning a random variable is focused on. The definition of an unpredictable random variable was introduced in reference [60]. A random variable 𝜉𝑡 is deemed unpredictable with respect to an information set Ω𝑡−1 if the conditional distribution 𝐹𝜉𝑡(𝜉𝑡|Ω𝑡−1) aligns with the unconditional distribution 𝐹𝜉𝑡(𝜉𝑡) of 𝜉𝑡, that is:
Specifically, when Ω𝑡−1 comprises past realizations of 𝜉𝑡, Equation (4) suggests that having knowledge about these past realizations does not enhance the predictive accuracy of 𝜉𝑡. It is important to note that this form of unpredictability in 𝜉𝑡 is an inherent attribute, unrelated to any prediction algorithm.
2.2.1. Univariate Time Series
Methods for estimating univariate time series predictability can be categorized into two groups: methods for estimating sample predictability and methods for estimating intrinsic predictability. The first group of methods aims to evaluate realized predictability (RPr) and encompasses measures that analyze forecast quality. The second group comprises intrinsic predictability (IPr) estimation methods, which are often rooted in information theory approaches, particularly those involving Shannon entropy.
The starting point for developing sample predictability measures is the work of [61], in which the predictability of a time series generated by a wide-sense stationary process is proposed to be evaluated as the ratio of the theoretical optimal forecast and the original time series variances. Consequently, computing predictability values requires knowledge of the optimal forecast, which is challenging to obtain for real-world time series. Therefore, coefficients for the sample predictability estimation (RPr), based on the approach from [61], are developed [62]. The approach from [61] assesses predictability as the ratio of the optimal forecast and the original series variances, but instead of using the optimal forecast error, while the proposed approach from [62] employs the forecast error shown by a specific model. Thus, the coefficient of efficiency (CE) indicates the ratio of the sample variance of the model’s forecast error to the sample variance of the time series, measured over the entire observation period. The seasonally adjusted coefficient of efficiency (SACE) differs from CE in that the series variance is considered within a specific season. The SACE coefficient is useful for time series where the mean value changes based on the season.
Furthermore, this group includes the work [63], which introduces a metric of realized predictability based on the ratio of two values: the sum of squared errors in the case of forecasting the original time series and the case of forecasting the same series after random shuffling. It is evident that measuring the predictability of a series using the three mentioned measures is entirely dependent on the model’s performance, and therefore, does not provide insight into the intrinsic predictability of the data.
The second group of methods for analyzing the predictability of univariate time series is based on (but not limited to) estimating various forms of entropy for the series, thereby allowing the assessment of data properties rather than models. This group of methods, in turn, is further divided into two subgroups: methods for assessing the predictability of the entire series and methods for assessing predictability on specific scales. Different scales of the series refer to series obtained from the original by retaining only those values that occur at specific intervals of time. Investigating the predictability of the series at different scales can provide valuable information about long-term correlations in the data, which can subsequently be utilized in training predictive models.
2.2.2. Multivariate Time Series
The goal of assessing the predictability of components within a multivariate time series (also referred to as features) is to select a set of features that best describe the behavior of the object and enable the model to make forecasts of the desired quality. In fact, there may be situations where using a particular feature as a predictor does not improve the forecast quality, complicating the search for patterns in the data. When dealing with large volumes of input data, there arises a need to match the original features with a specific subset of smaller-sized features that can make the model’s forecasts more stable and effective. However, standard dimensionality reduction methods are focused on preserving data properties unrelated to predictability, which introduces the risk of losing important information contained within the data [64].
There is an entire group of methods [64][65][66][67] in the field of extracting predictable features from multivariate time series. All works within this group share a similar algorithm. The input consists of multivariate time series, and the objective is to find a mapping from a space whose dimension equals the number of series components to a lower-dimensional space. The principle of dimensionality reduction may vary depending on the algorithm, yet all methods boil down to an optimization problem. The approach [67] is aimed at theoretically assessing realized predictability, while the other works within this group deal with the intrinsic predictability of features.
Indeed, in [65], a method for extracting slowly changing (or invariant) features, known as Slow Feature Analysis (SFA), is proposed. This method is utilized to analyze multivariate time series containing sensor data. The principle of feature extraction for creating a lower-dimensional space involves retaining those features that change over time as slowly as possible. Ultimately, the dimensionality reduction task is reduced to a variational calculus optimization problem.
The Forecastable Component Analysis (ForeCA) method [66] also addresses the task of feature selection, in this case, forecastable features. The work introduces a measure of predictability for time series generated by stationary random processes. The calculation of this measure employs the entropy of the process, which, in turn, is determined using spectral density. The ultimate task of finding features is reduced to maximizing this predictability measure.
A similar task of finding a set of features is considered in [67] (Predictable Feature Analysis, PFA), with the distinction that feature selection is carried out considering a specific model (i.e., the features that are well predicted by it). A criterion is derived that the model must adhere to in order to be used with PFA. It is worth noting that despite analyzing a specific model, this method examines theoretical predictability without utilizing forecast results. The advantage of this approach is the knowledge of a certain model that is able to make the predictions of the desired quality. However, the optimization problem is more challenging than in SFA: the forecasting optimization problem is embedded within the optimization problem of searching for predictable features.
The method from [64] (Graph-based Predictable Feature Analysis, GPFA) is based on interpreting predictability as a situation where the variance of a time series in the next time step is small given that the current value of the series is known. The dimensionality reduction task is formulated as the search for an orthogonal transformation of the original series. The term graph in the method’s name is mentioned simply because it is used as an auxiliary tool to search for the columns of the orthogonal transformation matrix. Additionally, the predictable components of a multivariate series can be seen as neighboring nodes on a specific graph, connected by an edge.
All the methods discussed (apart from [67] that theoretically assesses realized predictability) are aimed at estimating intrinsic feature predictability. Additionally, there exists a straightforward approach to estimate realized feature predictability [68][69]. This approach identifies the most useful features for predicting the remaining time of system performance. The predictability measure is defined as a function dependent on the prediction horizon, model class, model parameters, and the required accuracy threshold. The proposed predictability measure combines the threshold and the accuracy achieved by the model into a single value ranging from 0 to 1. Subsequently, pairs (a set of features and a model) with a favorable predictability value are selected through brute force.
2.2.3. Categorical Time Series
In practice, these time series can be referred to as events or event sequences. For instance, in [70], sequences composed of items viewed or purchased by users during a single session on a retailer’s website are considered. Predictability in this context refers to the probability of correctly determining the next element in the sequence (i.e., the purchase of a specific item), given the session’s start and the user’s session history. The authors provide an estimation of the maximum theoretical predictability of the sequence, expressed using entropy as formulated in [10]. Furthermore, the theoretical predictability realized by specific algorithms (RPr) is assessed by analyzing potential algorithm outcomes and selecting the result with the best forecasting quality. For instance, in the case of a Markov chain model, predictability is evaluated as the proportion of observations where the most likely transition from one state to another occurred. Thus, theoretical predictability can only be assessed for explicit models. Estimating the theoretical predictability for black-box models using this approach is not feasible.
In Reference [71], the authors consider the problem of forecasting the next point in a trajectory (the category of the point, not its coordinates). Similar to [71], the maximum theoretical predictability of the sequence is assessed using the entropy formula from [10]. Additionally, two statistics are introduced to measure the gap between theoretical predictability (IPr) and the maximum prediction accuracy achieved using a set of models (3).
In [72][73], the authors assess the realized predictability (RPr) of client’s transactional sequences by employing a coefficient based on the mean absolute error of the selected predictive model for each sequence. Subsequently, they categorize all sequences into predictability classes based on the values of the predictability measure. This approach can be utilized to gauge the predictability level of a sequence prior to forecasting, by utilizing a form of meta-classifier that assigns categorical time series to their corresponding predictability classes. Experiments demonstrated the efficiency of this approach, as the estimated predictability classes consistently align with those obtained through the application of a prediction model. The further development of this concept is done in [Koshkareva, 2023], which shows that customer separation by predictability levels helps to improve the forecasting quality of the whole population due to the decomposition of all clients’ time series, and that forecasting failures caused by environmental instability, like pandemics or military action, can be leveled out by means of this approach.
2.3. Network Link Predictability
Most of the studies on network link predictability discussed are focused on assessing intrinsic predictability. In Reference [74], a network is considered predictable if the removal or addition of a small number of randomly chosen nodes preserves its fundamental structural characteristics. Such networks are referred to as structurally consistent. The proposed measure is the Universal Structural Consistency Index, which is based on perturbing the adjacency matrix and evaluates the corresponding changes in network structural features. Through conducted experiments, a strong correlation is revealed between link prediction accuracy and the structural consistency index in various real-world networks, demonstrating the applicability of network structural consistency as a link predictability assessment. Moreover, this index can be used in tasks of missing links prediction. Such experiments with networks constructed using the Erdos–Renyi model indicate, as expected from the networks’ construction, that this type of networks is poorly predictable.
Furthermore, to assess the predictability of network structure, the normalized shortest compression length of the network structure can be employed [75]. Any network can be transformed into a binary string through compression. The length of the string increases as the randomness in the network structure grows. The authors compared their proposed predictability measure with the accuracy of the best available link prediction algorithm (as an approximation of the optimal algorithm) estimated via performance entropy and find a strong correlation.
Another work focusing on the assessment of the intrinsic predictability of network links is [59]. By considering ensembles of well-known network models, the authors analytically demonstrated that even the best possible link prediction methods provide limited accuracy, quantitatively dependent on the ensemble’s topological properties such as degree heterogeneity, clustering, and community structure. This fact implies an inherent limitation on predicting missing links in real-world networks due to uncertainty arising from the random nature of link formation processes. The authors show that the predictability limit can be estimated in real-world networks and propose a method to approximate this limit for real-world networks with missing links. The predictability limit serves as a benchmark for evaluating the quality of link prediction methods in real-world networks. Additionally, the authors conducted experiments comparing their proposed predictability measure with the structural consistency index from [74].
The authors of [76] assessed the predictability of links in temporal networks. The temporal nature of links in many real-world networks is not random, but predicting them is complicated due to the intertwining of topological and temporal link patterns. The paper introduces an approach based on Entropy rate, which combines both topological and temporal patterns to quantitatively assess the predictability of any temporal network (in previous works, only temporal aspects were considered). To examine both topological and temporal properties of the network, the sequence of adjacency matrices is treated as realizations of a random process. The subsequent procedure is similar to the one in [10] for trajectory predictability estimation: the entropy rate and theoretical upper bound of intrinsic predictability are derived, and then applying the Lempel–Ziv–Welch data compression algorithm yields an expression for the approximate entropy value. It is noted that for most real-world temporal networks, despite the increased complexity of predictability estimation, the upper bound of combined topological-temporal predictability is higher than that of temporal predictability.
Furthermore, there are two studies [77][78] focusing on the realized predictability of network links; specifically, the predictability observed through a selected feature-based link prediction model. The authors evaluate link predictability by assessing the error of the chosen model and divide the links within a small portion of the network into high and low predictability classes based on the error value. Subsequently, they train a meta-classifier on this subset of the network to estimate the predictability class using certain link features. This meta-classifier can then be applied to the entire network to estimate link predictability without the time-consuming process of training a link prediction model.
Moreover, there are methods that involve converting time series into networks. These methods can be categorized into three classes based on the type of resulting network [79]: (a) proximity networks; (b) visibility networks; (c) transition networks. The first category of methods constructs networks by utilizing information about the mutual proximity of various segments within time series. Mutual proximity can be measured in various ways, such as through the correlation between time series cycles (resulting in a cycle network [80]), the correlation between time series segments (resulting in a correlation network [81]), or the closeness of time series segments in phase space (resulting in a recurrence network [82]). The second category, known as visibility network methods, generates networks based on the convexity of consecutive observations in series [83]. Lastly, the class of methods producing transition networks constructs networks by considering the transition probabilities between groups of aggregated values from series [84].
However, there is only one study [85] that analyzed predictability under such transformations. The authors utilized the transition network approach to convert time series into networks. They then calculated network characteristics and employ them for clustering time series into two groups. By measuring the forecasting errors obtained by various models on time series from these clusters, they concluded that these clusters can be considered as classes of high and low predictability, as the mean forecasting error in one class is significantly lower than in the other.
2.4. Overview Summary
To assess the predictability of data, there is a multitude of measures that allow working with various objects: univariate and multivariate time series, categorical time series (sequences of events), and network links. In the case of time series, measures are developed to evaluate the predictability of the series as a whole, as well as at specific scales. The diversity of measures presented in the studies is due to researchers expressing their perspectives on predictability assessment from various scientific domains, such as information theory, dynamical systems, approximation theory, and so on. However, despite the variety of existing predictability measures, the challenge of proper analysis of connection between intrinsic and realized predictability remains unresolved.
References
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209.
- Mahalakshmi, G.; Sridevi, S.; Rajaram, S. A survey on forecasting of time series data. In Proceedings of the 2016 International Conference on Computing Technologies and Intelligent Data Engineering (ICCTIDE’16), Kovilpatti, India, 7–9 January 2016; pp. 1–8.
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Appl. 2020, 553, 124289.
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. 2016, 49, 1–33.
- Shaikh, S.; Gala, J.; Jain, A.; Advani, S.; Jaidhara, S.; Edinburgh, M.R. Analysis and prediction of COVID-19 using regression models and time series forecasting. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 989–995.
- Guresen, E.; Kayakutlu, G.; Daim, T.U. Using artificial neural network models in stock market index prediction. Expert Syst. Appl. 2011, 38, 10389–10397.
- Al Hasan, M.; Chaoji, V.; Salem, S.; Zaki, M. Link prediction using supervised learning. In Proceedings of the SDM06: Workshop on Link Analysis, Counter-Terrorism and Security, Bethesda, MD, USA, 20 April 2006; Volume 30, pp. 798–805.
- Liu, W.; Lü, L. Link prediction based on local random walk. Europhys. Lett. 2010, 89, 58007.
- Kovantsev, A.; Gladilin, P. Analysis of multivariate time series predictability based on their features. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 348–355.
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021.
- Pennekamp, F.; Iles, A.C.; Garland, J.; Brennan, G.; Brose, U.; Gaedke, U.; Jacob, U.; Kratina, P.; Matthews, B.; Munch, S.; et al. The intrinsic predictability of ecological time series and its potential to guide forecasting. Ecol. Monogr. 2019, 89, e01359.
- Krollner, B.; Vanstone, B.; Finnie, G. Financial time series forecasting with machine learning techniques: A survey. In Proceedings of the European Symposium on Artificial Neural Networks: Computational Intelligence and Machine Learning, Bruges, Belgium, 28–30 April 2010; pp. 25–30.
- Caillault, É.P.; Bigand, A. Comparative study on univariate forecasting methods for meteorological time series. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2380–2384.
- Mondal, P.; Shit, L.; Goswami, S. Study of effectiveness of time series modeling (ARIMA) in forecasting stock prices. Int. J. Comput. Sci. Eng. Appl. 2014, 4, 13.
- Daud, N.N.; Ab Hamid, S.H.; Saadoon, M.; Sahran, F.; Anuar, N.B. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716.
- Gu, S.; Li, K.; Liang, Y.; Yan, D. A transportation network evolution model based on link prediction. Int. J. Mod. Phys. B 2021, 35, 2150316.
- Coşkun, M.; Koyutürk, M. Node similarity-based graph convolution for link prediction in biological networks. Bioinformatics 2021, 37, 4501–4508.
- Imai, C.; Hashizume, M. A systematic review of methodology: Time series regression analysis for environmental factors and infectious diseases. Trop. Med. Health 2015, 43, 1–9.
- Catalina, T.; Iordache, V.; Caracaleanu, B. Multiple regression model for fast prediction of the heating energy demand. Energy Build. 2013, 57, 302–312.
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015.
- Ariyo, A.A.; Adewumi, A.O.; Ayo, C.K. Stock price prediction using the ARIMA model. In Proceedings of the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014; pp. 106–112.
- Contreras, J.; Espinola, R.; Nogales, F.J.; Conejo, A.J. ARIMA models to predict next-day electricity prices. IEEE Trans. Power Syst. 2003, 18, 1014–1020.
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C.K. Comparison of ARIMA and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 2014.
- Chen, C.; Hu, J.; Meng, Q.; Zhang, Y. Short-time traffic flow prediction with ARIMA-GARCH model. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 607–612.
- Moayedi, H.Z.; Masnadi-Shirazi, M. Arima model for network traffic prediction and anomaly detection. In Proceedings of the 2008 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008; Volume 4, pp. 1–6.
- Zhou, B.; He, D.; Sun, Z.; Ng, W.H. Network traffic modeling and prediction with ARIMA/GARCH. In Proceedings of the HET-NETs Conference, Ilkley, UK, 18–20 July 2005; pp. 1–10.
- Chen, P.; Yuan, H.; Shu, X. Forecasting crime using the arima model. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008; Volume 5, pp. 627–630.
- Aslanargun, A.; Mammadov, M.; Yazici, B.; Yolacan, S. Comparison of ARIMA, neural networks and hybrid models in time series: Tourist arrival forecasting. J. Stat. Comput. Simul. 2007, 77, 29–53.
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873.
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175.
- Pai, P.F.; Lin, C.S. A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 2005, 33, 497–505.
- Faruk, D.Ö. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell. 2010, 23, 586–594.
- Barak, S.; Sadegh, S.S. Forecasting energy consumption using ensemble ARIMA–ANFIS hybrid algorithm. Int. J. Electr. Power Energy Syst. 2016, 82, 92–104.
- Diebold, F.X. Elements of Forecasting; Citeseer: State College, PA, USA, 1998.
- Hassan, M.R.; Nath, B.; Kirley, M. A fusion model of HMM, ANN and GA for stock market forecasting. Expert Syst. Appl. 2007, 33, 171–180.
- Moghaddam, A.H.; Moghaddam, M.H.; Esfandyari, M. Stock market index prediction using artificial neural network. J. Econ. Financ. Adm. Sci. 2016, 21, 89–93.
- Palanisamy, P.; Rajendran, I.; Shanmugasundaram, S. Prediction of tool wear using regression and ANN models in end-milling operation. Int. J. Adv. Manuf. Technol. 2008, 37, 29–41.
- Keramati, A.; Jafari-Marandi, R.; Aliannejadi, M.; Ahmadian, I.; Mozaffari, M.; Abbasi, U. Improved churn prediction in telecommunication industry using data mining techniques. Appl. Soft Comput. 2014, 24, 994–1012.
- Ghorbanian, K.; Gholamrezaei, M. An artificial neural network approach to compressor performance prediction. Appl. Energy 2009, 86, 1210–1221.
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231.
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2, 117693510600200030.
- Amin, S.U.; Agarwal, K.; Beg, R. Genetic neural network based data mining in prediction of heart disease using risk factors. In Proceedings of the 2013 IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–12 April 2013; pp. 1227–1231.
- Nielsen, H.; Engelbrecht, J.; Brunak, S.; von Heijne, G. Identification of prokaryotic and eukaryotic signal peptides and prediction of their cleavage sites. Protein Eng. 1997, 10, 1–6.
- Lundin, M.; Lundin, J.; Burke, H.; Toikkanen, S.; Pylkkänen, L.; Joensuu, H. Artificial neural networks applied to survival prediction in breast cancer. Oncology 1999, 57, 281–286.
- Abhishek, K.; Kumar, A.; Ranjan, R.; Kumar, S. A rainfall prediction model using artificial neural network. In Proceedings of the 2012 IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 16–17 July 2012; pp. 82–87.
- Abhishek, K.; Singh, M.; Ghosh, S.; Anand, A. Weather forecasting model using artificial neural network. Procedia Technol. 2012, 4, 311–318.
- Maqsood, I.; Khan, M.R.; Abraham, A. An ensemble of neural networks for weather forecasting. Neural Comput. Appl. 2004, 13, 112–122.
- Baboo, S.S.; Shereef, I.K. An efficient weather forecasting system using artificial neural network. Int. J. Environ. Sci. Dev. 2010, 1, 321.
- Recknagel, F.; French, M.; Harkonen, P.; Yabunaka, K.I. Artificial neural network approach for modelling and prediction of algal blooms. Ecol. Model. 1997, 96, 11–28.
- Ahn, B.S.; Cho, S.; Kim, C. The integrated methodology of rough set theory and artificial neural network for business failure prediction. Expert Syst. Appl. 2000, 18, 65–74.
- Sinha, S.K.; Wang, M.C. Artificial neural network prediction models for soil compaction and permeability. Geotech. Geol. Eng. 2008, 26, 47–64.
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031.
- Backstrom, L.; Leskovec, J. Supervised random walks: Predicting and recommending links in social networks. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 635–644.
- Dunlavy, D.M.; Kolda, T.G.; Acar, E. Temporal link prediction using matrix and tensor factorizations. ACM Trans. Knowl. Discov. Data 2011, 5, 1–27.
- Menon, A.K.; Elkan, C. Link prediction via matrix factorization. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; pp. 437–452.
- Taskar, B.; Wong, M.F.; Abbeel, P.; Koller, D. Link prediction in relational data. Adv. Neural Inf. Process. Syst. 2003, 16, 659–666.
- Miller, K.; Jordan, M.; Griffiths, T. Nonparametric latent feature models for link prediction. Adv. Neural Inf. Process. Syst. 2009, 22, 1276–1284.
- Yu, K.; Chu, W.; Yu, S.; Tresp, V.; Xu, Z. Stochastic relational models for discriminative link prediction. In Proceedings of the NIPS, Vancouver, BC, Canada, 4–7 December 2006; Voume 6, pp. 1553–1560.
- García-Pérez, G.; Aliakbarisani, R.; Ghasemi, A.; Serrano, M.Á. Precision as a measure of predictability of missing links in real networks. Phys. Rev. E 2020, 101, 052318.
- Clements, M.; Hendry, D. Forecasting Economic Time Series; Cambridge University Press: Cambridge, UK, 1998.
- Granger, C.; Newbold, P. Forecasting Economic Time Series; Technical Report; Elsevier: Amsterdam, The Netherlands, 1986.
- Wang, W.; Van Gelder, P.H.; Vrijling, J. Measuring predictability of daily streamflow processes based on univariate time series model. In Proceedings of the iEMSs 2008 Conference, Barcelona, Spain, 7–10 July 2008.
- Kaboudan, M. A measure of time series’ predictability using genetic programming applied to stock returns. J. Forecast. 1999, 18, 345–357.
- Weghenkel, B.; Fischer, A.; Wiskott, L. Graph-based predictable feature analysis. Mach. Learn. 2017, 106, 1359–1380.
- Wiskott, L.; Sejnowski, T.J. Slow feature analysis: Unsupervised learning of invariances. Neural Comput. 2002, 14, 715–770.
- Goerg, G.M. Forecastable component analysis (ForeCA). arXiv 2012, arXiv:1205.4591.
- Richthofer, S.; Wiskott, L. Predictable feature analysis. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 190–196.
- Javed, K.; Gouriveau, R.; Zemouri, R.; Zerhouni, N. Improving data-driven prognostics by assessing predictability of features. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, PHM’11, Montreal, QC, Canada, 25–29 September 2011; pp. 555–560.
- Javed, K.; Gouriveau, R.; Zemouri, R.; Zerhouni, N. Features selection procedure for prognostics: An approach based on predictability. IFAC Proc. Vol. 2012, 45, 25–30.
- Järv, P. Predictability limits in session-based next item recommendation. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 146–150.
- Guo, J.; Zhang, S.; Zhu, J.; Ni, R. Measuring the Gap Between the Maximum Predictability and Prediction Accuracy of Human Mobility. IEEE Access 2020, 8, 131859–131869.
- Stavinova, E.; Bochenina, K.; Chunaev, P. Predictability classes for forecasting clients behavior by transactional data. In Proceedings of the International Conference on Computational Science, Krakov, Poland, 16–18 June 2021; pp. 187–199.
- Bezbochina, A.; Stavinova, E.; Kovantsev, A.; Chunaev, P. Dynamic Classification of Bank Clients by the Predictability of Their Transactional Behavior. In Proceedings of the International Conference on Computational Science, London, UK, 21–23 June 2022; pp. 502–515.
- Lü, L.; Pan, L.; Zhou, T.; Zhang, Y.C.; Stanley, H.E. Toward link predictability of complex networks. Proc. Natl. Acad. Sci. USA 2015, 112, 2325–2330.
- Sun, J.; Feng, L.; Xie, J.; Ma, X.; Wang, D.; Hu, Y. Revealing the predictability of intrinsic structure in complex networks. Nat. Commun. 2020, 11, 1–10.
- Tang, D.; Du, W.; Shekhtman, L.; Wang, Y.; Havlin, S.; Cao, X.; Yan, G. Predictability of real temporal networks. Natl. Sci. Rev. 2020, 7, 929–937.
- Stavinova, E.; Evmenova, E.; Antonov, A.; Chunaev, P. Link predictability classes in complex networks. In Proceedings of the Complex Networks & Their Applications X: Volume 1, Madrid, Spain, 30 November–2 December 2022; pp. 376–387.
- Antonov, A.; Stavinova, E.; Evmenova, E.; Chunaev, P. Link predictability classes in large node-attributed networks. Soc. Netw. Anal. Min. 2022, 12, 81.
- Donner, R.V.; Small, M.; Donges, J.F.; Marwan, N.; Zou, Y.; Xiang, R.; Kurths, J. Recurrence-based time series analysis by means of complex network methods. Int. J. Bifurc. Chaos 2011, 21, 1019–1046.
- Zhang, J.; Luo, X.; Small, M. Detecting chaos in pseudoperiodic time series without embedding. Phys. Rev. E 2006, 73, 016216.
- Yang, Y.; Yang, H. Complex network-based time series analysis. Phys. A Stat. Mech. Appl. 2008, 387, 1381–1386.
- Marwan, N.; Romano, M.C.; Thiel, M.; Kurths, J. Recurrence plots for the analysis of complex systems. Phys. Rep. 2007, 438, 237–329.
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuno, J.C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975.
- Shirazi, A.; Jafari, G.R.; Davoudi, J.; Peinke, J.; Tabar, M.R.R.; Sahimi, M. Mapping stochastic processes onto complex networks. J. Stat. Mech. Theory Exp. 2009, 2009, P07046.
- Kovantsev, A.; Chunaev, P.; Bochenina, K. Evaluating time series predictability via transition graph analysis. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 1039–1046.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
700
Revisions:
2 times
(View History)
Update Date:
22 Nov 2023
Table of Contents



Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No